FastChat开放,媲美ChatGPT的90%能力——从下载到安装、部署
- 前言
- 两个前置软件
- 创建FastChat虚拟环境
- 安装PyTorch
- 安装 FastChat
- 下载 LLaMA,并转换
- 生成FastChat对应的模型Vicuna
- 启动FastChat的命令行交互
- 将模型部署为一个服务,提供Web GUI
前言
- 最近ChatGPT非常火,引爆了整个商业市场以及NLP学术界,但是ChatGPT很多东西都不开放,你也没法个人部署、研究
- 于是很多大语言模型横空出世,在开放的大语言模型中,最近我认为效果很不错的是FastChat,基于LLaMA做了二次调参训练,据官方称能达到ChatGPT的90%的能力。(具体能否达到这个值,可以直接去他们的Demo上试试)
- 相关链接
- GitHub地址: https://github.com/lm-sys/FastChat
- Demo地址: https://chat.lmsys.org/
- 博客与相关说明: https://vicuna.lmsys.org/
- 注意
- 安装教程时间为2023年4月8日,FastChat项目频繁更新,后续可能会有不一致的地方
两个前置软件
- Git: https://git-scm.com/
- 代码管理工具,用于等会从GitHub安装huggingface的transformers
- 直接安装即可,不用改配置
- Anaconda:https://www.anaconda.com/
- Python依赖管理工具,用于做Python依赖环境管理,你也可以用其他的管理工具
- 直接安装即可,不用改配置
创建FastChat虚拟环境
- 首先,利用Anaconda为FastChat创建一个虚拟环境,执行命令
$ conda create -n fastchat python=3.9- 如果是Windows系统,你需要先打开Anaconda Prompt
- 官网要求Python版本要
>= 3.8,注意不要安装错版本了 - 如果Anaconda下载新环境的依赖较慢的话,你可以切换下清华源,命令如下(按顺序)
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/pro conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2 conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/ conda config --set show_channel_urls yes - 切换到刚才创建好的
fastchat虚拟环境,执行$ conda activate fastchat - 这个时候你就切换到了我们为FastChat准备的Python虚拟环境了,接下来可以开始安装我们需要的一些依赖
安装PyTorch
- 由于FastChat使用的是PyTorch深度学习框架,建议提前安装好PyTorch的依赖
- 因为官方的源文件有申明PyTorch的依赖,虽然等下安装FastChat时会自动安装PyTorch,但是默认安装的不是带CUDA版本的,到时候重新弄麻烦
- 而且还能不能指定自己需要的PyTorch版本
- 具体怎么安装,请参考官方链接 https://pytorch.org/get-started/locally/
- 根据自己当前的情况选择,官方会给出安装命令
- 默认是最新的PyTorch2.0,但如果你想使用早一点的版本,请看这里 https://pytorch.org/get-started/previous-versions/
- 安装命令样例
- conda
$ conda install pytorch torchvision torchaudio cudatoolkit=11.6 -c pytorch -c conda-forge - conda
$ conda install pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.6 -c pytorch -c nvidia - Pip
$ pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117 - Pip
$ pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu116
- conda
- 安装完成后,建议进入Python命令行测试一下,下面是个样例
(base) PS C:\Users\alion> conda activate fastchat (fastchat) PS C:\Users\alion> python Python 3.9.16 (main, Mar 8 2023, 10:39:24) [MSC v.1916 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> import torch >>> print(torch.__version__) 1.13.1+cu116 >>> print(torch.version.cuda) 11.6 >>> >>> exit() (fastchat) PS C:\Users\alion>
安装 FastChat
- 官方有两种安装方式,
- 直接利用Pip安装
- 下载官方源码后安装
- 第二种方式可能会出错,建议先直接用第一种(不过你都可以试试,哈哈)
- 第二种的话,可以有更多的控制性,例如在
pyproject.toml文件中移除掉你认为不需要的依赖,或是源码中有错误需要修改 - 如果用源码装可能会出现错误
- 信息大概是这样
git clone --filter=blob:none --quiet https://github.com/huggingface/transformers.git ... exit code: 128 - 你先去fastchat项目下,打开
pyproject.toml文件,移除掉dependencies中的transformers,等下手动安装pip3 install git+https://github.com/huggingface/transformers - 当然这个也可能会卡住,多试几次吧😁
- 信息大概是这样
- 第二种的话,可以有更多的控制性,例如在
- 直接执行Pip命令
- 慢的话可以在Pip命令后面加个清华源
-i https://pypi.tuna.tsinghua.edu.cn/simple - 如果github没法访问,请记得开启你的专业工具
# 安装FastChat pip3 install fschat # 安装 huggingface/transformers pip3 install git+https://github.com/huggingface/transformers
- 慢的话可以在Pip命令后面加个清华源
- 请确保你已经安装好Git,并在命令行中能使用,否则安装huggingface/transformers时会报错
- 我已经安装好了,可以看看输出样例
(fastchat) PS C:\Users\alion> pip3 install fschat Requirement already satisfied: fschat in c:\programdata\anaconda3\envs\fastchat\lib\site-packages (0.1.8) Requirement already satisfied: tokenizers>=0.12.1 in c:\programdata\anaconda3\envs\fastchat\lib\site-packages (from fschat) (0.13.3) Requirement already satisfied: requests in c:\programdata\anaconda3\envs\fastchat\lib\site-packages (from fschat) (2.28.1) Requirement already satisfied: torch in c:\programdata\anaconda3\envs\fastchat\lib\site-packages (from fschat) (1.13.1+cu116) Requirement already satisfied: wandb in c:\programdata\anaconda3\envs\fastchat\lib\site-packages (from fschat) (0.14.2) Requirement already satisfied: uvicorn in c:\programdata\anaconda3\envs\fastchat\lib\site-packages (from fschat) (0.21.1) Requirement already satisfied: sentencepiece in c:\programdata\anaconda3\envs\fastchat\lib\site-packages (from fschat) (0.1.97) Requirement already satisfied: accelerate in c:\programdata\anaconda3\envs\fastchat\lib\site-packages (from fschat) (0.18.0) Requirement already satisfied: numpy in c:\programdata\anaconda3\envs\fastchat\lib\site-packages (from fschat) (1.24.1) Requirement already satisfied: fastapi in c:\programdata\anaconda3\envs\fastchat\lib\site-packages (from fschat) (0.95.0) Requirement already satisfied: gradio==3.23 in c:\programdata\anaconda3\envs\fastchat\lib\site-packages (from fschat) (3.23.0) Requirement already satisfied: markdown2[all] in c:\programdata\anaconda3\envs\fastchat\lib\site-packages (from fschat) (2.4.8) # 太多了,中间的我就省略了 Requirement already satisfied: fonttools>=4.22.0 in c:\programdata\anaconda3\envs\fastchat\lib\site-packages (from matplotlib->gradio==3.23->fschat) (4.39.3) Requirement already satisfied: kiwisolver>=1.0.1 in c:\programdata\anaconda3\envs\fastchat\lib\site-packages (from matplotlib->gradio==3.23->fschat) (1.4.4) Requirement already satisfied: svgwrite in c:\programdata\anaconda3\envs\fastchat\lib\site-packages (from wavedrom->markdown2[all]->fschat) (1.4.3) Requirement already satisfied: smmap<6,>=3.0.1 in c:\programdata\anaconda3\envs\fastchat\lib\site-packages (from gitdb<5,>=4.0.1->GitPython!=3.1.29,>=1.0.0->wandb->fschat) (5.0.0) Requirement already satisfied: zipp>=3.1.0 in c:\programdata\anaconda3\envs\fastchat\lib\site-packages (from importlib-resources>=3.2.0->matplotlib->gradio==3.23->fschat) (3.15.0) Requirement already satisfied: pyrsistent!=0.17.0,!=0.17.1,!=0.17.2,>=0.14.0 in c:\programdata\anaconda3\envs\fastchat\lib\site-packages (from jsonschema>=3.0->altair>=4.2.0->gradio==3.23->fschat) (0.19.3) Requirement already satisfied: uc-micro-py in c:\programdata\anaconda3\envs\fastchat\lib\site-packages (from linkify-it-py<3,>=1->markdown-it-py[linkify]>=2.0.0->gradio==3.23->fschat) (1.0.1) (fastchat) PS C:\Users\alion>
下载 LLaMA,并转换
- 由于FastChat基于LLaMA做的二次调参训练,所以我们需要先拿到LLaMA模型文件
- 官方的获取方式比较麻烦,需要你先填个表单,然后等他们回复,认为可以了才会给你文件
- hugging face对于LLaMA的说明 https://huggingface.co/docs/transformers/main/model_doc/llama
- Meta AI的表单填写地址 https://docs.google.com/forms/d/e/1FAIpQLSfqNECQnMkycAp2jP4Z9TFX0cGR4uf7b_fBxjY_OjhJILlKGA/viewform
- 不过幸运的是,国内有人共享了 LLaMA模型文件
- 百度PaddlePaddle(只找到个7B的模型) https://aistudio.baidu.com/aistudio/datasetdetail/203425/0
- 种子链接(包含7B/13B/30B/65B的模型)
magnet:?xt=urn:btih:cdee3052d85c697b84f4c1192f43a2276c0daea0&dn=LLaMA
- 下载后,关于解压或是保存文件的路径中 ,请记得不要有中文、特殊符号等
- 接下来,我们还需要转换一下LLaMA的文件,以便于构建FastChat对应的模型Vicuna(我资源不够,用的7B模型)
- 下载 huggingface/transformers 的源码
$ git clone https://github.com/huggingface/transformers.git - 进入到项目下
$ cd transformers - 利用
huggingface/transformers中的代码,完成对于LLaMA的转换,示例$ python src/transformers/models/llama/convert_llama_weights_to_hf.py --input_dir D:/code/model/LLaMA --model_size 7B --output_dir D:/code/model/transformer_model_7b- 参数:
--input_dir指定的是刚才你下载好的LLaMA文件地址,这个路径下有个tokenizer.model文件,请仔细核对一下 - 参数:
--model_size指定用哪个参数数量级的模型,7B代表的是70亿个参数的那个模型(如果你用的种子链接下载的话,还有13B/30B/65B的模型) - 参数:
--output_dir是转换后输出的路径,等下要用
- 参数:
- 下载 huggingface/transformers 的源码
生成FastChat对应的模型Vicuna
- 接下来我们需要生成Vicuna模型,将原始的LLaMA weights转为Vicuna weights
- 这个过程需要消耗大量的内存,CPU也是拉满😁,官方给出的参考值如下
- Vicuna-13B 需要大约60GB内存
- Vicuna-7B 需要大约30GB内存
- 确实需要这么多,请准备好足够的内存空间
- 命令样例如
python -m fastchat.model.apply_delta --base-model-path D:/code/model/transformer_model_7b --target-model-path D:/code/model/vicuna-7b --delta-path lmsys/vicuna-7b-delta-v0- 参数:
--base-model-path指定的是上一步,我们转换好的LLaMA 文件路径 - 参数:
--target-model-path是接下来生成的Vicuna文件要存放的位置,稍后启动FastChat要用 - 参数:
--delta-path不用改
- 参数:
- 上面的命令官方已更新(2023-04-13记录),最新安装的同学请换成下面这个:
python -m fastchat.model.apply_delta --base-model-path D:/code/model/transformer_model_7b --target-model-path D:/code/model/vicuna-7b --delta-path lmsys/vicuna-7b-delta-v1.1
- 这个过程较长,需要等下,下面是我的控制台打印信息样例
(fastchat) PS D:\code\transformers> python -m fastchat.model.apply_delta --base-model-path D:/code/model/transformer_model_7b --target-model-path D:/code/model/vicuna-7b --delta-path lmsys/vicuna-7b-delta-v0
Loading base model
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████| 2/2 [00:03<00:00, 1.63s/it]
Loading delta
Downloading (…)lve/main/config.json: 100%|█████████████████████████████████████████████| 619/619 [00:00<00:00, 103kB/s]
Downloading (…)model.bin.index.json: 100%|████████████████████████████████████████| 26.8k/26.8k [00:00<00:00, 1.30MB/s]
Downloading (…)l-00001-of-00002.bin: 100%|████████████████████████████████████████| 9.98G/9.98G [06:47<00:00, 24.5MB/s]
Downloading (…)l-00002-of-00002.bin: 100%|████████████████████████████████████████| 3.50G/3.50G [02:29<00:00, 23.4MB/s]
Downloading shards: 100%|███████████████████████████████████████████████████████████████| 2/2 [09:19<00:00, 279.81s/it]
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████| 2/2 [00:03<00:00, 1.68s/it]
Downloading (…)neration_config.json: 100%|████████████████████████████████████████████| 137/137 [00:00<00:00, 27.3kB/s]
Downloading (…)okenizer_config.json: 100%|█████████████████████████████████████████████| 727/727 [00:00<00:00, 121kB/s]
Downloading tokenizer.model: 100%|███████████████████████████████████████████████████| 500k/500k [00:01<00:00, 411kB/s]
Downloading (…)cial_tokens_map.json: 100%|█████████████████████████████████████████████| 411/411 [00:00<00:00, 103kB/s]
Applying delta
Applying delta: 100%|████████████████████████████████████████████████████████████████| 323/323 [00:22<00:00, 14.57it/s]
Saving target model
(fastchat) PS D:\code\transformers-main>
启动FastChat的命令行交互
- 前序工作我们已经准备好了,接下来可以和Vicuna进行命令行式的交流了
- 执行命令
$ pyhon -m fastchat.serve.cli --model-name D:\code\model\vicuna-7b- 如果显卡内存不够,你可以使用CPU
$ python -m fastchat.serve.cli --model-name D:\code\model\vicuna-7b --device cpu - 如果有多张显卡,可通过
--num-gpus 2来指定多张显卡 - 官方给出的参考值如下
- 使用显卡的情况下:Vicuna-13B大概需要28GB显存,Vicuna-7B大概需要14GB显存
- 使用CPU的情况下:Vicuna-13B大概需要60GB内存,Vicuna-7B大概需要30GB内存
- 如果显卡内存不够,你可以使用CPU
- 上面的命令官方已更新(2023-04-13记录),最新安装的同学请换成下面这个:
$ pyhon -m fastchat.serve.cli --model-path D:\code\model\vicuna-7b
- 稍等一会,就可以正式和Vicuna交流了
- 下面是一个样例
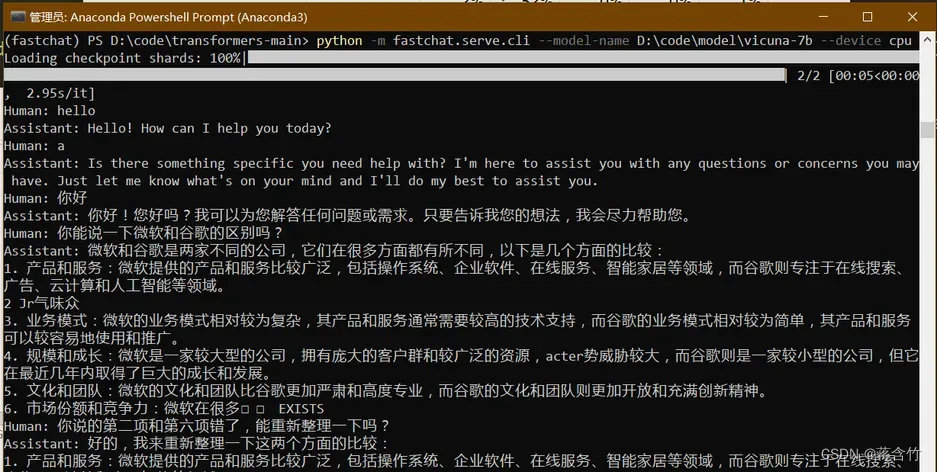
- 可以看出来7B模型还是有较大问题的,你可以到官方Demo地址中,拿这个问题问问13B模型
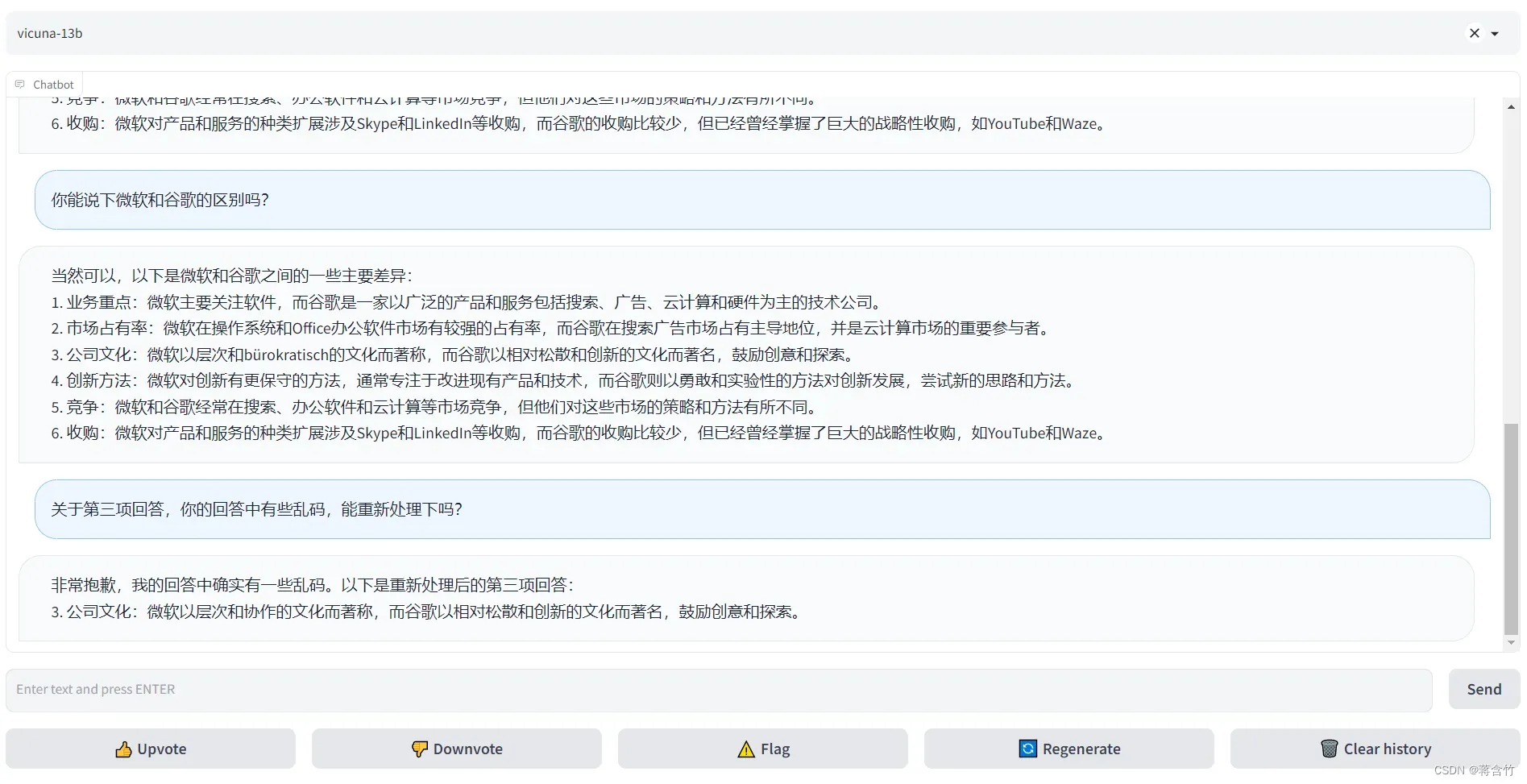
将模型部署为一个服务,提供Web GUI
- 启动 controller
- 新打开命令行,进入到fastchat环境
$ conda activate fastchat - 执行命令
$ python -m fastchat.serve.controller
- 新打开命令行,进入到fastchat环境
- 启动 model worker
- 新打开命令行,进入到fastchat环境
$ conda activate fastchat - 执行命令
$ python -m fastchat.serve.model_worker --model-path D:\code\model\vicuna-7b - 同样,如果你显卡内存不够,需要使用CPU,在后面加上参数
--device cpu
- 新打开命令行,进入到fastchat环境
- 关于controller和model worker的说明
- controller用来控制协调Webserver的请求,将具体的任务转给model worker
- model worker负责执行,可以部署多个,会自动链接到controller
- 启动前可以测试一下
- 新打开命令行,进入到fastchat环境
$ conda activate fastchat - 执行
$ python -m fastchat.serve.test_message --model-name vicuna-7b
- 新打开命令行,进入到fastchat环境
- 最后,启动 web server,执行
python -m fastchat.serve.gradio_web_server - 打开浏览器,访问地址 http://127.0.0.1:7860/

文章出处登录后可见!
已经登录?立即刷新