yolov5模型训练后的结果会保存到当前目录下的run文件夹下里面的train中
下面对训练结果做出分析
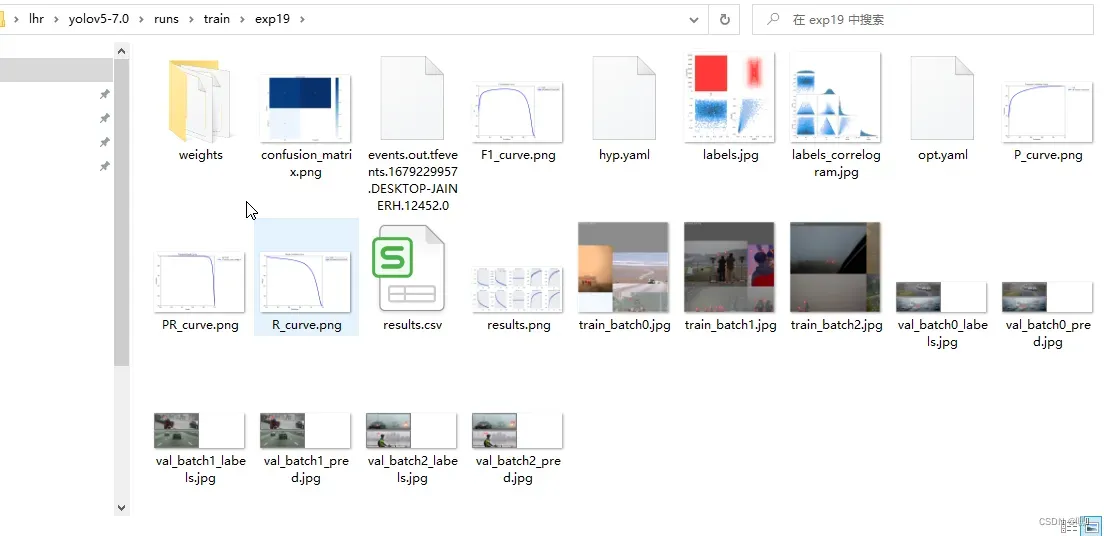
confusion_matrix.png(混淆矩阵)
在yolov5的训练结果中,confusion_matrix.png文件是一个混淆矩阵的可视化图像,用于展示模型在不同类别上的分类效果。混淆矩阵是一个n×n的矩阵,其中n为分类数目,矩阵的每一行代表一个真实类别,每一列代表一个预测类别,矩阵中的每一个元素表示真实类别为行对应的类别,而预测类别为列对应的类别的样本数。
在混淆矩阵的可视化图像中,对角线上的数值表示模型正确分类的样本数,而非对角线上的数值则表示模型错误分类的样本数。可以通过观察非对角线上的数值,了解模型在哪些类别上容易发生错误分类,进而对模型进行调整和改进。
具体来说,对于某一个类别 i,矩阵中的第 i 行表示所有实际标签为 i 的样本,而矩阵中的第 i 列表示所有预测标签为 i 的样本。那么,矩阵中第 (i, j) 个元素表示实际标签为 i,预测标签为 j 的样本数目。
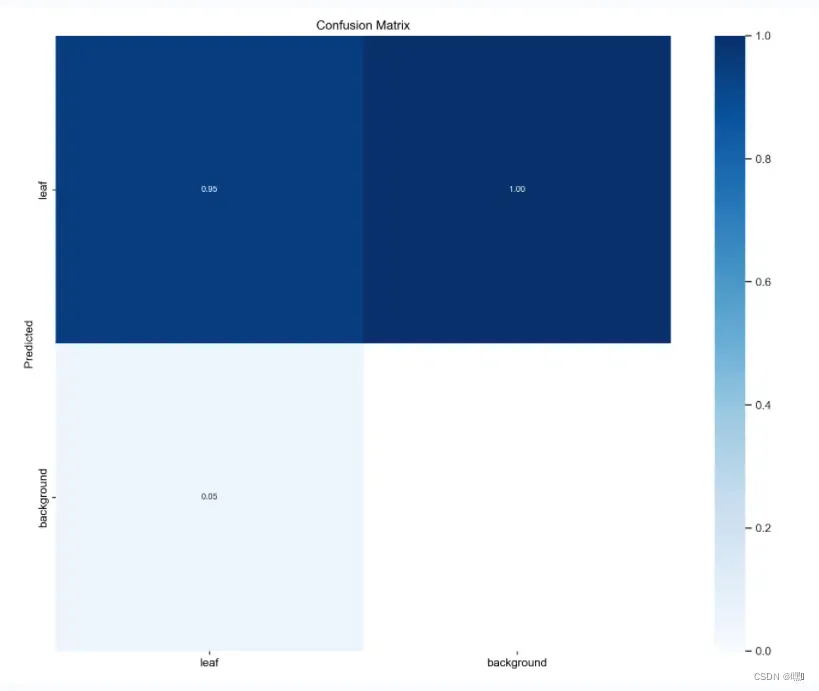
F1_curve.png(F1曲线)
置信度阈值
置信度阈值是目标检测中一个重要的参数,用于控制检测器对目标的识别要求。置信度阈值的设定影响着检测结果的精度和召回率。
在目标检测中,每个检测框都有一个置信度得分,表示该框中是否包含目标。当置信度得分超过设定的阈值时,认为该框中存在目标,否则认为该框中不存在目标。置信度阈值的设定需要结合具体任务和模型的性能来进行调整,通常需要在精度和召回率之间进行权衡。
如果将置信度阈值设定得太高,可能会漏掉一些真实存在的目标,导致召回率较低;而将置信度阈值设定得太低,则会引入一些误检测,导致精度较低。因此,需要根据具体应用场景和模型的性能来选择合适的置信度阈值。
准确率
准确率(Accuracy)是指模型分类正确的样本数占总样本数的比例
精确率
精确率(Precision)是指模型识别出的真正正样本数占所有被识别为正样本的样本数的比例
召回率
召回率(Recall)是指模型识别出的正样本数占真实正样本数的比例
F1分数与置信度阈值(x轴)之间的关系。F1分数是分类的一个衡量标准,是精确率和召回率的调和平均数,介于0,1之间。越大越好。
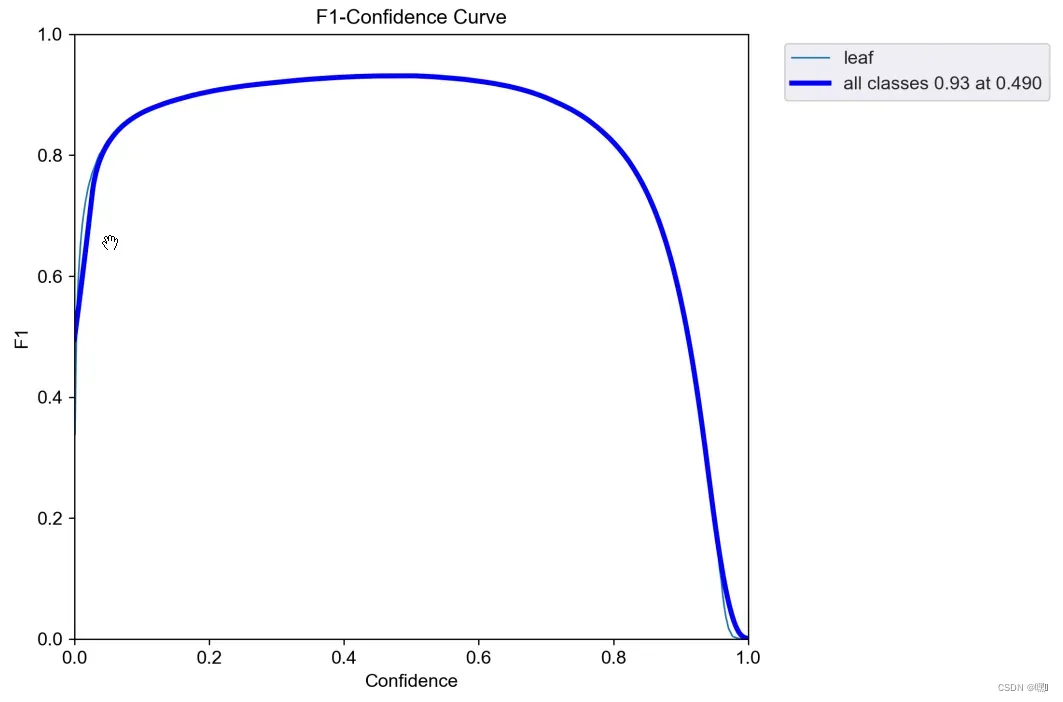
labels.jpg
“labels.jpg”通常是指包含训练数据集中所有类别标签的图像文件。
- 第一个图是训练集得数据量,每个类别有多少个;
- 第二个图是框的尺寸和数量;
- 第三个图是中心点相对于整幅图的位置;
- 第四个图是图中目标相对于整幅图的高宽比例;
labels_correlogram.jpg
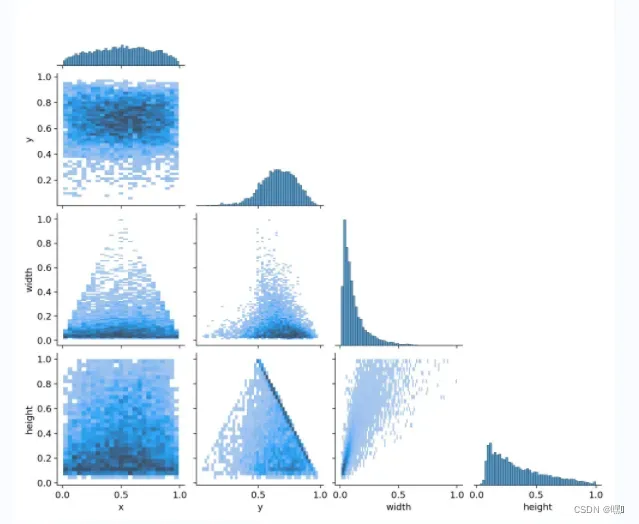
labels_correlogram.jpg是一张颜色矩阵图,它展示了目标检测算法在训练过程中预测标签之间的相关性。
矩阵的行列分别代表了模型训练时使用的标签(classes),而每个单元格则代表了对应标签的预测结果之间的相关性。
矩阵中的颜色越深,表示对应标签之间的相关性越强;颜色越浅,表示相关性越弱。对角线上的颜色表示每个标签的自身相关性,通常都是最深的。
通过这张图,我们可以看出哪些标签之间具有较强的相关性,从而有助于优化模型的训练和预测效果。例如,如果我们发现某些标签之间的相关性过强,可以考虑将它们合并成一个标签,从而简化模型并提高效率。
最上面的图(0,0)表明中心点横坐标x的分布情况;
(1,1)图表明中心点纵坐标y的分布情况;
(2,2)图表明框的宽的分布情况;
(3,3)图表明框的宽的分布情况
P_curve.png(信度阈值 – 准确率曲线图)
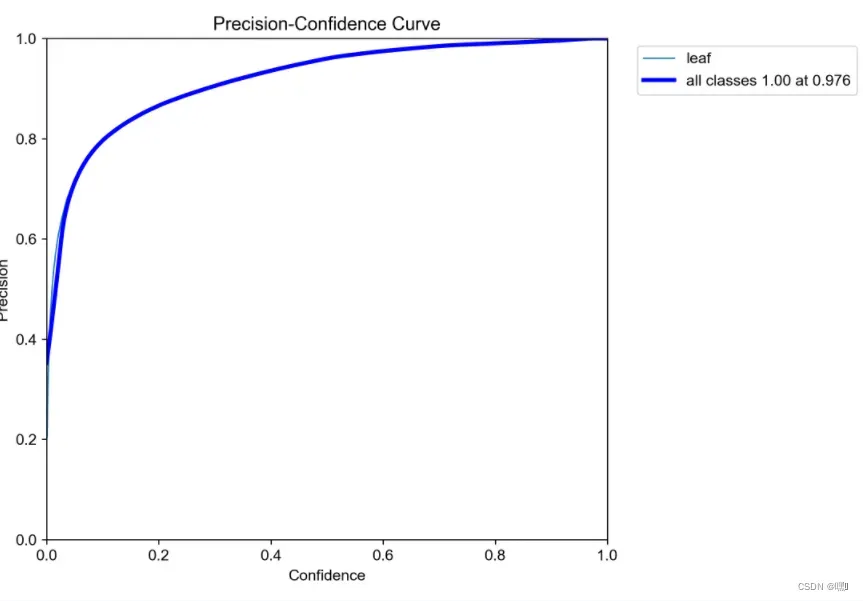
在P_curve.png中,橙色的线代表模型的P-R曲线,曲线下的面积是平均准确率(Average Precision, AP)。AP越大,模型的性能越好。蓝色的线代表Baseline模型的P-R曲线。可以看出,橙色的曲线比蓝色的曲线更接近左上角,AP也更大,说明训练出的模型比Baseline模型性能更好。
R_curve.png(信度阈值 – 召回率曲线图)
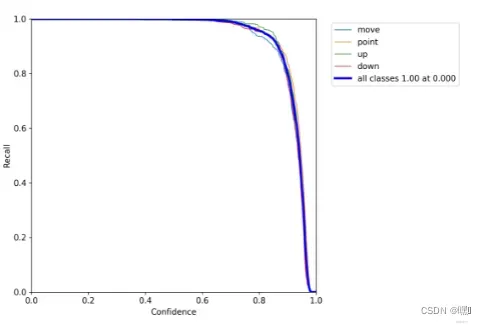
R_curve.png是yolov5模型训练结果中的一个图表,用于衡量模型在不同召回率下的精确度表现。在该图表中,X轴表示召回率,范围从0到1,Y轴表示精确度,范围也是从0到1。
在该图表中,曲线越靠近右上角,则表示模型的性能越好。当曲线接近图表的右上角时,意味着模型在保持高召回率的同时,也能够保持较高的精确度。因此,R_curve.png可以用于评估模型的整体表现和找到一个合适的阈值,来平衡模型的召回率和精确度。
PR_curve.png —— 精确率和召回率的关系图
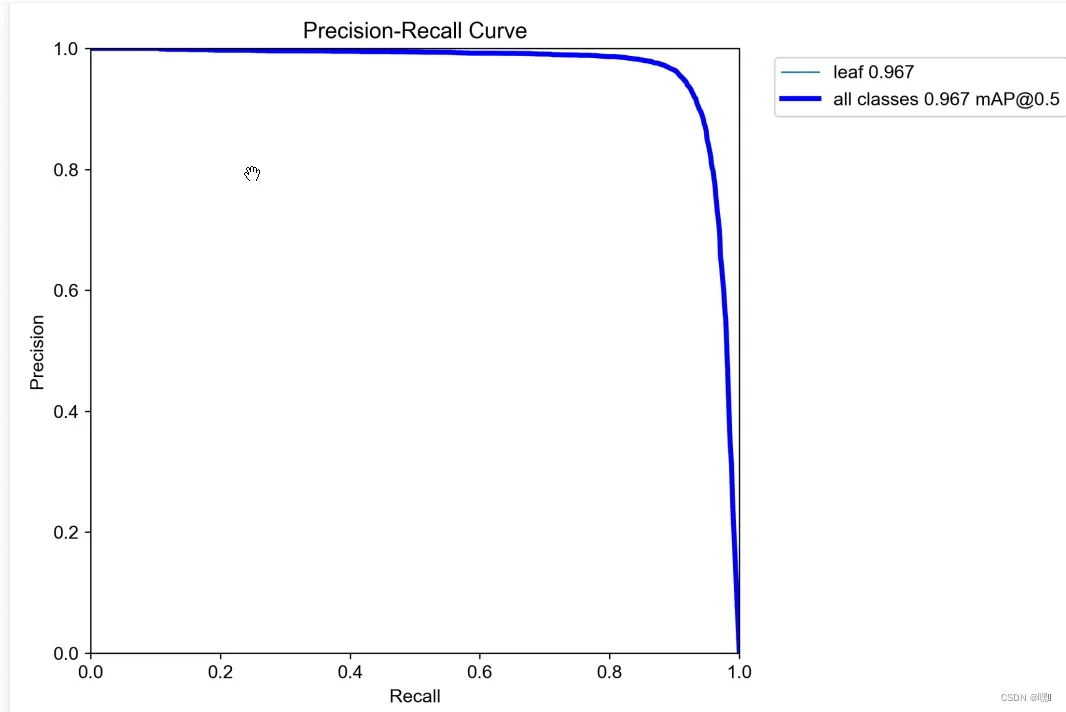
PR Curve是Precision-Recall Curve的缩写,表示的是在不同阈值下,精确率与召回率之间的关系曲线。其中精确率(Precision)表示预测为正例的样本中真正为正例的比例,召回率(Recall)表示真正为正例的样本中被预测为正例的比例。
在PR Curve中,横坐标为召回率,纵坐标为精确率。一般而言,当召回率较高时,精确率较低;当精确率较高时,召回率较低。而PR Curve则体现了这种“取舍”关系。当PR Curve越靠近右上角时,表示模型在预测时能够同时保证高的精确率和高的召回率,即预测结果较为准确。相反,当PR Curve越靠近左下角时,表示模型在预测时难以同时保证高的精确率和高的召回率,即预测结果较为不准确。
通常,PR Curve与ROC Curve(受试者工作特征曲线)一同使用,以更全面地评估分类模型的性能。
result.png
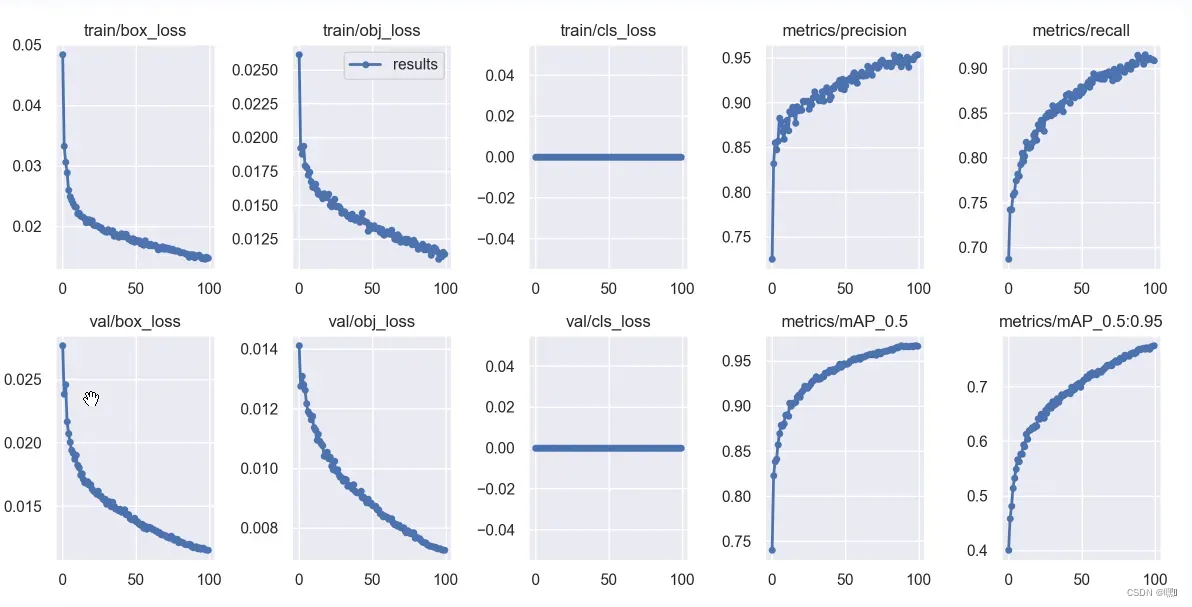 🌳定位损失box_loss:
🌳定位损失box_loss:
预测框与标定框之间的误差(CIoU),越小定位得越准;
🌳置信度损失obj_loss:
计算网络的置信度,越小判定为目标的能力越准;
🌳分类损失cls_loss:
计算锚框与对应的标定分类是否正确,越小分类得越准;
🌳mAP@0.5:0.95(mAP@[0.5:0.95])
表示在不同IoU阈值(从0.5到0.95,步长0.05)(0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95)上的平均mAP;
🌳mAP@0.5:
表示阈值大于0.5的平均mAP
文章出处登录后可见!