大型语言模型(LLM)的出现,让我们看到了 AI 在自然语言处理方面的潜力,它涌现出来的创造力和思维能力令人叹为观止,并在新一代人机交互领域释放了大量的想象空间。
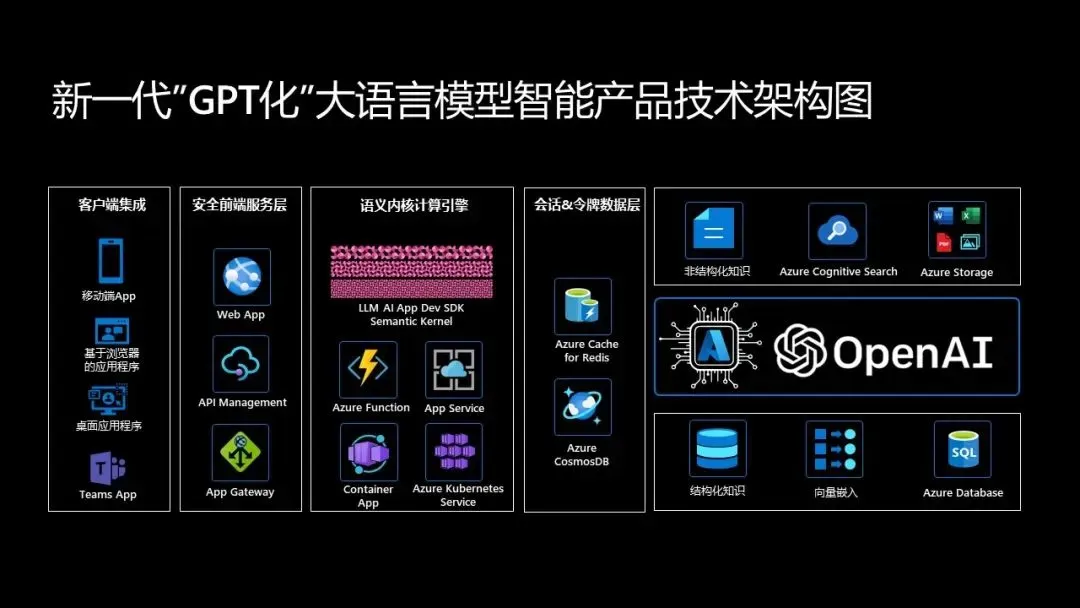
目前,决策者、产品负责人和开发者都在抢滩产品的「GPT化」。在微软,面向开发者的新一代开源大语言模型应用开发框架应时而生。
什么是大型语言模型
大型语言模型(LLM)是指可以从大量数据中生成自然语言文本的 AI 模型。它使用深度神经网络,从数十亿或数万亿个单词中学习,能够生成任何主题或领域的文本。它可以执行各种自然语言任务,如分类、总结、翻译、生成和对话。
大语言模型开发建立在4个核心思想上:
-
模型 – Models
-
提示词 – Prompts
-
令牌 – Tokens
-
嵌入 – Embeddings
▍模型 – Models
模型是指经过训练和微调的 LLM AI 的特定实例或版本,例如 GPT-3.5 或 GPT-4,它们已经在大量的文本或代码(针对 Codex 模型)上进行了训练,并可以通过 API 或平台进行访问和使用。OpenAI 和 Azure OpenAI 提供了各种模型,可以通过参数或选项进行定制和控制,并可应用于不同的领域和任务。
▍提示词 – Prompts
提示词是用户或程序向 LLM AI 提供的输入或查询,以引发模型的特定响应。提示可以是自然语言句子或问题,也可以是代码片段或命令,或者是任何文本或代码的组合,具体取决于领域和任务。提示也可以嵌套或链接在一起,这意味着一个提示的输出可以作为另一个提示的输入,从而创建与模型更为复杂和动态的交互。
创造性地设计 LLM AI 提示词是一个新兴的领域,被称为“提示设计”或“提示工程”。它涉及到制定有效和高效的提示的过程,以引发 LLM AI 模型所需的响应。主要的挑战包括选择正确的词语、短语、符号和格式,以指导模型生成高质量和相关性强的文本。人们还可以尝试不同的参数和设置,这些参数和设置可以影响模型的行为和性能,例如温度、top-k、top-p、penalty。
▍令牌 – Tokens
令牌是 LLM AI 用于处理和生成语言的文本或代码的基本单位,是模型的语言构建块。根据选择的分词方法或方案,令牌可以是单词、字符、子词或符号、代码,这取决于模型的类型和大小。令牌被赋予数字值或标识符,并按序列或向量排列,最终被输入模型或进行输出。
令牌化是将输入和输出文本分割成较小的单位,以便 LLM AI 模型处理的过程。分词可以帮助模型处理不同的语言、词汇和格式,并减少计算和存储成本。分词还可以通过影响令牌的含义和上下文来影响生成的文本的质量和多样性。分词可以使用不同的方法进行,例如基于规则、统计或神经网络,这取决于文本的复杂性和变异性。
▍嵌入 – Embeddings
嵌入是令牌(如句子、段落或文档)在高维向量空间中的表示或编码,其中每个维度对应于语言的一个学习特征或属性。嵌入是模型捕捉和存储语言的含义和关系的方式,也是模型比较和对比不同令牌或语言单位的方式。对于模型来说,嵌入是离散和连续、符号和数字两个方面之间的桥梁。
嵌入是表示模型处理和生成的令牌的含义和上下文的数字向量或数组。嵌入是从模型的参数或权重派生出来的,并用于对输入和输出文本进行编码和解码。嵌入可以帮助模型理解令牌之间的语义和句法关系,并生成更相关和连贯的文本。嵌入还可以使模型处理多模态任务,例如图像和代码生成,通过将不同类型的数据转换为共同的表示形式。嵌入是 GPT 模型使用的 Transformer 架构的重要组成部分,其大小和维度取决于模型和任务的不同。
新一代开源大语言模型应用开发框架 – Semantic Kernel
Semantic Kernel (SK) 是一种轻量级的软件开发工具包 (SDK),可将人工智能大型语言模型 (LLM) 与传统编程语言集成。SK 可扩展的编程模型将自然语言语义函数、传统本机本地函数和基于嵌入式记忆的技术相结合,从而为应用程序增加价值并开启新的潜力。
SK 支持开箱即用的提示词模板、函数链式编程、向量化内存和智能计划能力。

Semantic Kernel 被设计为支持和封装最新的人工智能研究中的多种设计模式,使开发人员可以将复杂技能(如提示链式编程、递归推理、摘要生成、零/少样本学习、上下文记忆、长期记忆、嵌入式技术、语义索引、计划和访问外部知识库以及自己的数据)注入到他们的应用程序中。
使用 SK,开发人员可以通过设计更快地构建以人工智能为先的应用程序,同时还可以目睹 SDK 的构建过程。SK 已经开源发布,以便更多先锋开发人员可以加入我们,共同塑造计算历史上里程碑时刻的未来。
SK 能够灵活地将大语言模型集成到现有应用程序中。使用 SK,可以更轻松地加速创新上市时间,并在长期运行中实现可靠性和性能管理。
随着它们越来越能够理解复杂意图,大语言模型正在推动更加“目标导向”的问题解决方法。因此,SK 被创建时就以“ASK”为出发点。ASK 通过内核的编排能力驱动到动态通知的结果。从用户的提问到获得想要的结果,可以表示为一系列连接部件的流程:
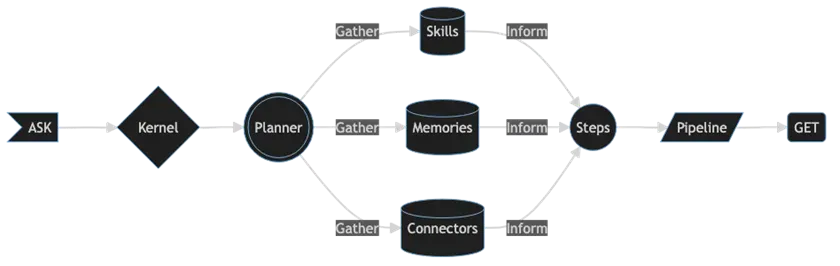
Semantic Kernel 的相关组件
▍Kernel
在 Semantic Kernel(SK)中,内核(Kernel)是用户提问的协调器。内核利用其可用的技能、记忆和连接器来实现用户期望的目标。内核的关键特征有助于加快开发速度,包括:
-
技能:将最有用的提示打包成完全可重用的组件。
-
混合开发:流畅地将 AI 提示与传统本地代码混合使用。
-
协调:通过完全控制来管理复杂的 LLM AI 提示。
-
未来可靠性:使用多个 LLM AI 模型和配置来实现特定目标。
内核旨在鼓励“功能组合”,这使得开发人员可以将技能的输入和输出组合成单个流水线。
▍Planner
Planner 从用户 ASK 提供的目标开始反向工作。

我们称这种方法为“面向目标的人工智能”,这让我们想起了早期人工智能研究人员渴望计算机能够击败世界棋王的时代。这个宏伟的目标最终被实现了,但由于新的 LLM AI 模型具有提供实现几乎任何目标的逐步指导的非凡能力,当合适的技能可用时,实现任何目标都变得可行。
由于 Planner 可以访问预定义的预制技能库和/或动态定义的技能集,它能够自信地满足 ASK 的需求。此外,Planner 利用记忆最佳地定位 ASK 的上下文,并调用连接器调用 API 并利用其他外部能力。
▍Skills
Skills 是指一种专业领域,可作为单个函数或与该技能相关的一组函数提供给内核使用。SK Skills 的设计优先考虑了开发人员的最大灵活性,使其既轻量化又可扩展。
▍Memories
Memories 是为 ASK 提供更广泛上下文的强大方式。在历史上,我们一直将 Memories 视为计算机工作的核心组件:就像您笔记本电脑中的 RAM 一样。Memories 是使计算与手头任务相关的因素。
我们用以下三种方式之一访问 Memories 以输入 SK,其中第三种方式最有趣:
-
常规键值对:就像您在 shell 中设置环境变量一样,使用 SK 时也可以这样做。查找是“常规”的,因为它是一个键和您的查询之间的一对一匹配。
-
常规本地存储:当您将信息保存到文件中时,可以使用文件名检索它。当您需要存储大量信息时,最好将其保存在磁盘上。
-
语义记忆搜索:您还可以将文本信息表示为长的数字向量,称为“嵌入”。这使您可以执行“语义”搜索,将查询与含义相匹配。
▍Connectors
Connectors 使应用能够连接到外部 API 和其他可以想象的内容,从技能外部获取数据。通过将自定义技能与一组自定义连接器相结合,开发人员可以构建完全利用实时数据的大模型智能应用程序功能,将其打造成完全可重用的“AI 就绪”组件,以添加到现有的所有的项目中。
微软新一代开源大语言模型应用开发框架将为企业应用「GPT化」释放无限的想象空间。行动起来吧,如需进一步了解如何将此框架在企业内部落地,请联系您的微软客户经理,申请 GPT App Innovation In A Day Workshop,由专家为您提供进一步的指导。

*本文来源 Microsoft Learn 技术文档,由微软大中华区数字化应用创新高级市场经理许豪整理发布
进一步学习和了解 Semantic Kernel,请访问:
文章出处登录后可见!