DQN 模型无法正确得出预期分数
pytorch 257
原文标题 :The DQN model cannot correctly come out the expected scores
我正在做一个游戏“CartPole-v1”的DQN训练模型。在这个模型中,系统没有在终端提示任何错误信息。但是,结果评估变得更糟了。这是输出数据:
episode: 85 score: 18 avarage score: 20.21 epsilon: 0.66
episode: 86 score: 10 avarage score: 20.09 epsilon: 0.66
episode: 87 score: 9 avarage score: 19.97 epsilon: 0.66
episode: 88 score: 14 avarage score: 19.90 epsilon: 0.65
episode: 89 score: 9 avarage score: 19.78 epsilon: 0.65
episode: 90 score: 10 avarage score: 19.67 epsilon: 0.65
episode: 91 score: 14 avarage score: 19.60 epsilon: 0.64
episode: 92 score: 13 avarage score: 19.53 epsilon: 0.64
episode: 93 score: 17 avarage score: 19.51 epsilon: 0.64
episode: 94 score: 10 avarage score: 19.40 epsilon: 0.63
episode: 95 score: 16 avarage score: 19.37 epsilon: 0.63
episode: 96 score: 16 avarage score: 19.33 epsilon: 0.63
episode: 97 score: 10 avarage score: 19.24 epsilon: 0.62
episode: 98 score: 13 avarage score: 19.17 epsilon: 0.62
episode: 99 score: 12 avarage score: 19.10 epsilon: 0.62
episode: 100 score: 11 avarage score: 19.02 epsilon: 0.61
episode: 101 score: 17 avarage score: 19.00 epsilon: 0.61
episode: 102 score: 11 avarage score: 18.92 epsilon: 0.61
episode: 103 score: 9 avarage score: 18.83 epsilon: 0.61
我将在这里展示我的代码。首先我构建了一个神经网络:
import random
from torch.autograd import Variable
import torch as th
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
import gym
from collections import deque
# construct a neuron network (prepare for step1, step3.2 and 3.3)
class DQN(nn.Module):
def __init__(self, s_space, a_space) -> None:
# inherit from DQN class in pytorch
super(DQN, self).__init__()
self.fc1 = nn.Linear(s_space, 360)
self.fc2 = nn.Linear(360, 360)
self.fc3 = nn.Linear(360, a_space)
# DNN operation architecture
def forward(self, input):
out = self.fc1(input)
out = F.relu(out)
out = self.fc2(out)
out = F.relu(out)
out = self.fc3(out)
return out
我没有新建一个agent类,而是直接创建了select函数,用于根据epsilon选择对应的动作,全局梯度反向传播函数:
# define the action selection according to epsilon using neuron network (prepare for step3.2)
def select(net, epsilon, env, state):
# randomly select an action if not greedy
if(np.random.rand() <= epsilon):
action = env.action_space.sample()
return action
# select the maximum reward action by NN and the given state if greedy
else:
actions = net(Variable(th.Tensor(state))).detach().numpy()
action = np.argmax(actions[0])
return action
这是反向传播函数和 epsilon 的递减:
# using loss function to improve neuron network (prepare for step3.3)
def backprbgt(net, store, batch_size, gamma, learning_rate):
# step1: create loss function and Adam optimizer
loss_F = nn.MSELoss()
opt = th.optim.Adam(net.parameters(),lr=learning_rate)
# step2: extract the sample in memory
materials = random.sample(store, batch_size)
# step3: Calculate arguments of loss function:
for t in materials:
Q_value = net(Variable(th.Tensor(t[0])))
# step3.1 Calculate tgt_Q_value in terms of greedy:
reward = t[3]
if(t[4] == True):
tgt = reward
else:
tgt = reward + gamma * np.amax(net(Variable(th.Tensor(t[2]))).detach().numpy()[0])
# print(tgt)
# tgt_Q_value = Variable(th.Tensor([[float(tgt)]]), requires_grad=True)
# print("Q_value:",Q_value)
Q_value[0][t[1]] = tgt
tgt_Q_value = Variable(th.Tensor(Q_value))
# print("tgt:",tgt_Q_value)
# step3.2 Calculate evlt_Q_value
# index = th.tensor([[t[1]]])
# evlt_Q_value = Q_value.gather(1,index) # gather tgt into the corresponding action
evlt_Q_value = net(Variable(th.Tensor(t[0])))
# print("evlt:",evlt_Q_value)
# step4: backward and optimization
loss = loss_F(evlt_Q_value, tgt_Q_value)
# print(loss)
opt.zero_grad()
loss.backward()
opt.step()
# step5: decrease epsilon for exploitation
def decrease(epsilon, min_epsilon, decrease_rate):
if(epsilon > min_epsilon):
epsilon *= decrease_rate
之后,参数和训练进度是这样的:
# training process
# step 1: set parameters and NN
episode = 1500
epsilon = 1.0
min_epsilon = 0.01
dr = 0.995
gamma = 0.9
lr = 0.001
batch_size = 40
memory_store = deque(maxlen=1500)
# step 2: define game category and associated states and actions
env = gym.make("CartPole-v1")
s_space = env.observation_space.shape[0]
a_space = env.action_space.n
net = DQN(s_space, a_space)
score = 0
# step 3: trainning
for e in range(0, episode):
# step3.1: at the start of each episode, the current result should be refreshed
# set initial state matrix
s = env.reset().reshape(-1, s_space)
# step3.2: iterate the state and action
for run in range(500):
# select action and get the next state according to current state "s"
a = select(net, epsilon, env, s)
obs, reward, done, info = env.step(a)
next_s = obs.reshape(-1,s_space)
s = next_s
score += 1
if(done == True):
reward = -10.0
memory_store.append((s,a,next_s,reward,done))
avs = score / (e+1)
print("episode:", e+1, "score:", run+1, "avarage score: {:.2f}".format(avs), "epsilon: {:.2}".format(epsilon))
break
# safe sample data
memory_store.append((s, a, next_s, reward, done))
if(run == 499):
print("episode:", e+1, "score:", run+1, "avarage score:", avs)
# step3.3 whenever the episode reach the integer time of batch size,
# we should backward to implore the NN
if(len(memory_store) > batch_size):
backprbgt(net, memory_store, batch_size, gamma, lr) # here we need a backprbgt function to backward
if(epsilon > min_epsilon):
epsilon = epsilon * dr
在整个训练过程中,没有出现错误或异常提示。然而,该模型并没有增加分数,而是在后面的步骤中执行了较低的分数。我认为这个模型的理论是正确的,但是虽然我尝试了很多改进我的代码的方法,但找不到错误出现的地方,包括重新检查网络的输入参数,修改损失函数的两个参数的数据结构等。我粘贴了我的代码在这里,希望能得到一些关于如何修复它的帮助。谢谢!
回复
我来回复-
 draw 评论
draw 评论该回答已被采纳!
查看代码。对于大多数部分,它与上面的片段相同,但有一些变化:
- for step in replay buffer(在代码 memory_store 中调用)namedtuple 被使用,并且在更新中它更容易阅读 t.reward ,而不是查看每个索引在步骤 t 中所做的事情
- 类 DQN 有方法 update ,最好将优化器保留为类的属性,而不是每次调用函数 backprbgt 时都创建它
- 在这里使用 torch.autograd.Variable 是不必要的,所以它也被拿走了
- 每批次更新 backprbgt
- 将隐藏层的大小从 360 减少到 32,同时将批量大小从 40 增加到 128
- 每 10 集更新一次网络,但在回放缓冲区中的 10 个批次
- 基于最后 10 集的平均分数每 50 集打印一次
- 添加种子
同样对于RL来说,学习任何东西都需要很长时间,所以希望在100集之后它会接近100分是有点乐观的。对于链接中的代码,平均 5 次运行会导致以下动态
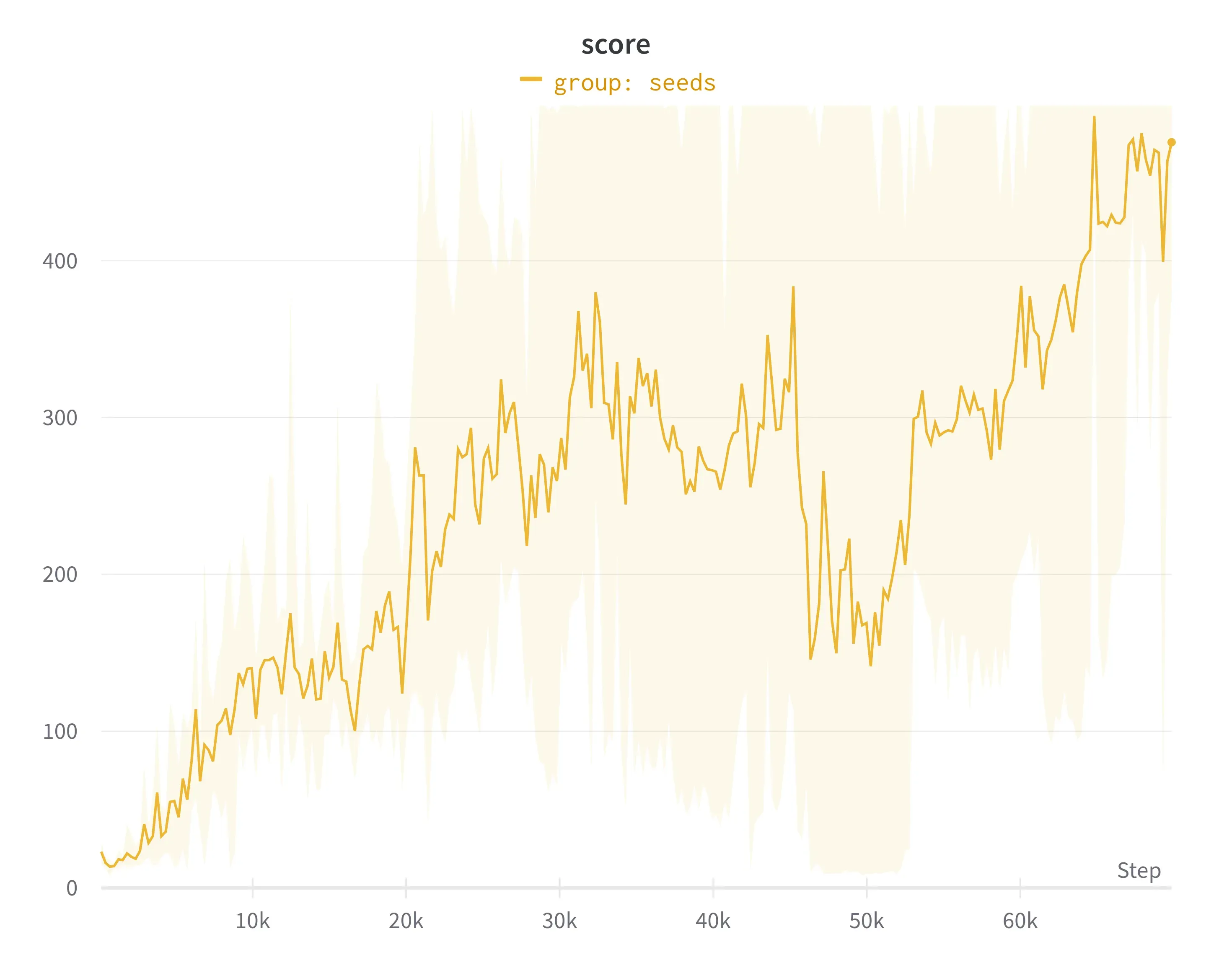
X 轴 – 集数(是的,70 K,但它就像 20 分钟的实时)
Y 轴 – 剧集中的步数
可以看出,在 70K 集后,算法获得了与此环境中可能最高的奖励(最高 – 500)相当的奖励。通过调整超参数可以实现更快的速率,但还要记住它是 DQN,无需任何修改。
2年前