决策树原理
- 了解决策树
决策树思想的来源非常朴素,程序设计中的条件分支结构就是if-then结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法怎么理解这句话?通过一个对话例子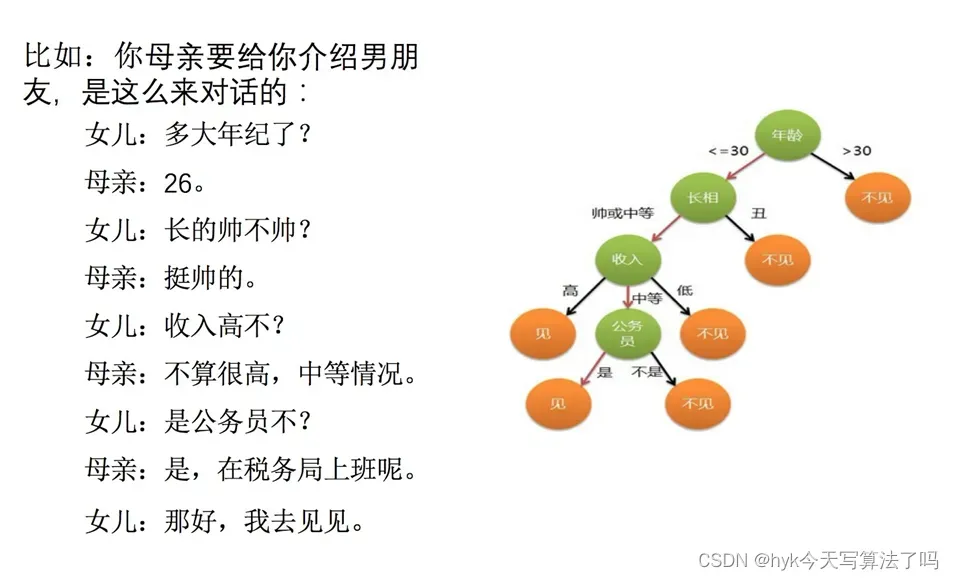
决策树如上图所示。它将每个功能分为两类。想想为什么这个女孩会把年龄放在评判的首位! ! - 1决策树分类原理详解
为了更好地理解决策树是如何分类的,我们来看一个问题的例子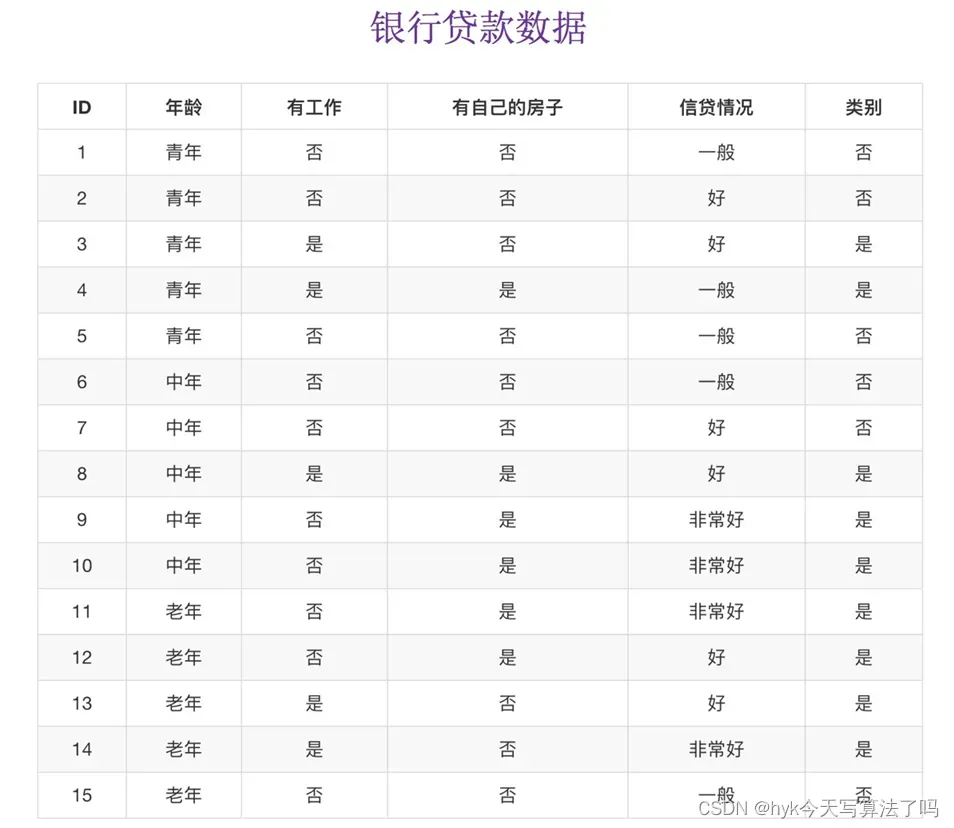
问题:如何对这些客户进行分类预测?你怎么分?
有可能你的部门是这样的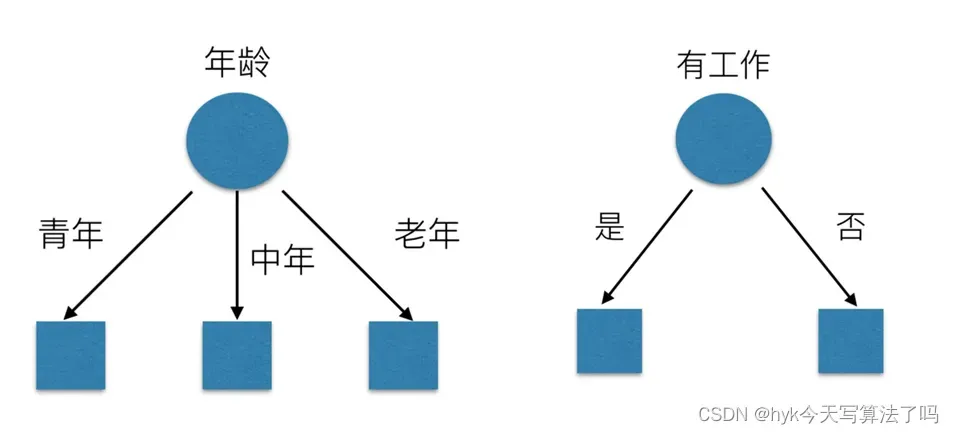
那么我们怎么知道这些特征中哪个更好放在上面呢,那么决策树的真正划分是这样的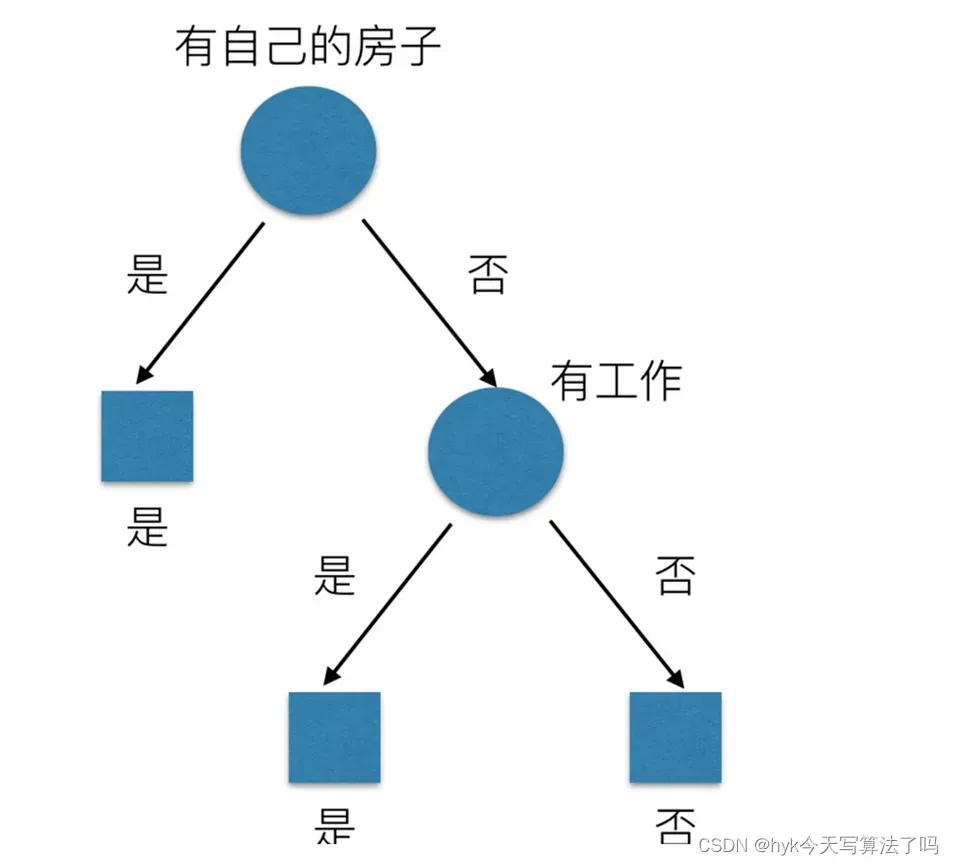
2.2信息熵
那来玩个猜测游戏,猜猜这32支球队那个是冠军。并且猜测错误付出代价。每猜错一次给一块钱,告诉我是否猜对了,那么我需要掏多少钱才能知道谁是冠军? (前提是:不知道任意球队的信息、历史比赛记录、实力等)

为了最小化成本,可以使用二分法猜测:
我可以把球编上号,从1到32,然后提问:冠 军在1-16号吗?依次询问,只需要五次,就可以知道结果。
我们来看看这个公式:
- 32支球队,log32=5比特
- 64支球队,log64=6比特

香农指出,它的准确信息量应该是,p为每个球队获胜的概率(假设概率相等,都为1/32),我们不用钱去衡量这个代价了,香浓指出用比特:
H = -(p1logp1 + p2logp2 + … + p32log32) = – log32
2.3信息熵的定义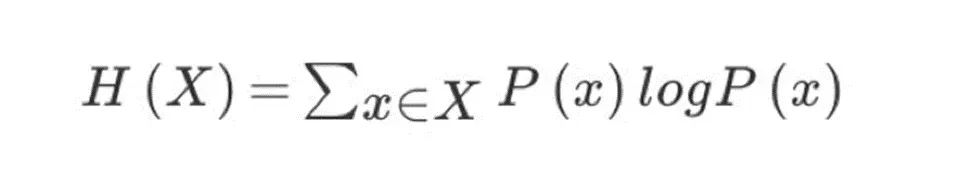
- H的专业术语称之为信息熵,单位为比特。
- “谁是世界杯冠军”的信息量应该比5比特少,特点(重要):
- 当这32支球队夺冠的几率相同时,对应的信息熵等于5比特只要概率发生任意变化,信息熵都比5比特大
2.4 决策树的划分依据之一——信息增益
定义和公式:
特征A对训练数据集D的信息增益g(D,A),定义为集合D的信息熵H(D)与特征A给定条件下D的信息条件熵
H(D|A)之差,即公式为: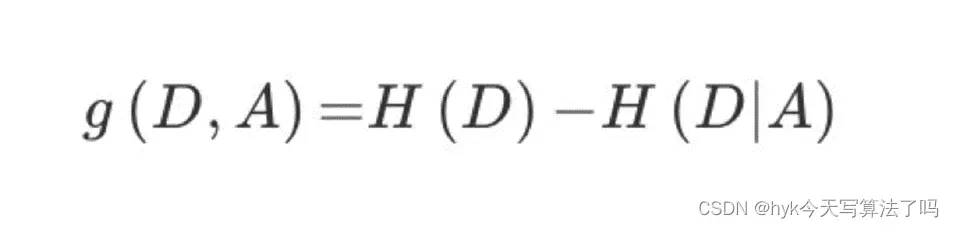
公式详解:
2.5 贷款特征重要计算
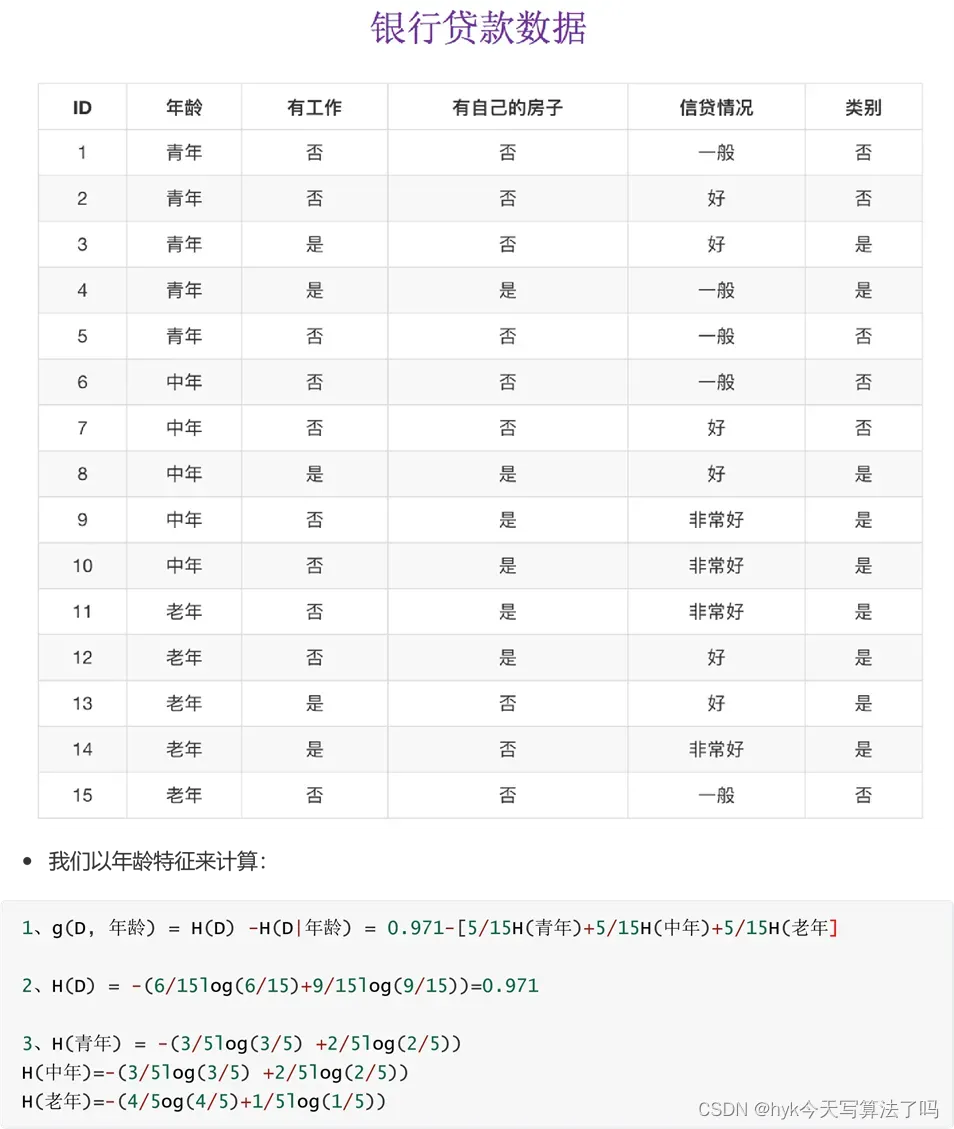
我们以A1、A2、A3、A4代表年龄、有工作、有自己的房子和贷款情况。最终计算的结果g(D, A1) =
0.313, g(D, A2) = 0.324, g(D, A3) = 0.420,g(D, A4) = 0.363。所以我们选择A3 作为划分的第一个特征。
所以我们可以慢慢建树
2.6 决策树的三种算法实现
当然,决策树的原理不仅仅是信息增益,还有其他方法。但原理类似,就不举例计算了。

二、决策树API
class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, max_depth=None,random_state=None)
决策树分类器:
criterion:默认是’gini’系数,也可以选择信息增益的熵’entropy’
max_depth:树的深度大小
random_state:随机数种子
其中会有些超参数:max_depth:树的深度大小
3. 案例研究:泰坦尼克号乘客生还预测
- 泰坦尼克号数据
在泰坦尼克号和titanic2数据帧描述泰坦尼克号上的个别乘客的生存状态。这里使用的数据集是由各种研究人员开始的。其中包括许多研究人员创建的旅客名单,由Michael A。Findlay编辑。我们提取的数据集中的特征是票的类别,存活,乘坐班,年龄,登陆,home.dest,房间,票,船和性别。
1、 乘坐班是指乘客班(1,2,3),是社会经济阶层的代表。
2、 其中age数据存在缺失。
数据:http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt
分析

- 选择我们认为重要的几个特征 [‘pclass’, ‘age’, ‘sex’]填充缺失值
- 特征中出现类别符号,需要进行one-hot编码处理(DictVectorizer)x.to_dict(orient=“records”)
需要将数组特征转换为字典数据数据集分区 - 决策树分类预测
代码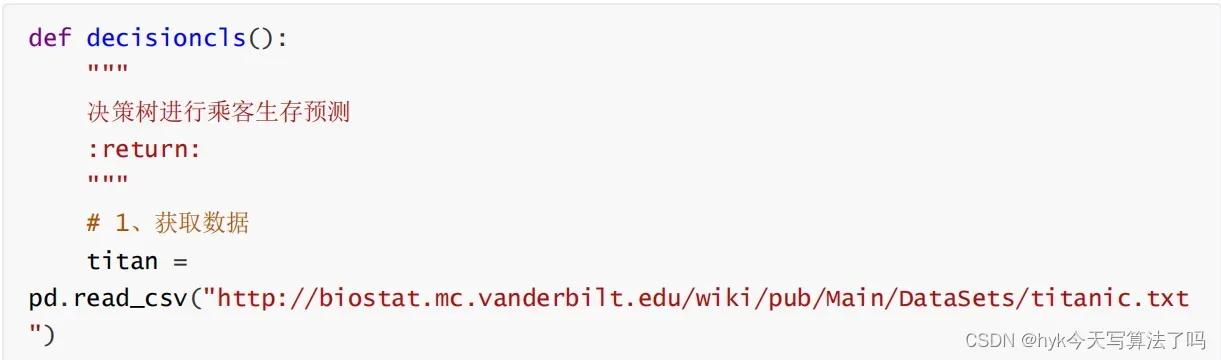

四、保存树的结构到dot文件
1、sklearn.tree.export_graphviz() 该函数能够导出DOT格式
tree.export_graphviz(estimator,out_file='tree.dot’,feature_names=[‘’,’’])
2、工具:(能够将dot文件转换为pdf、png)
- 安装graphviz
- ubuntu:sudo apt-get install graphviz Mac:brew install graphviz
3、运行命令
- 然后我们运行这个命令
- dot -Tpng tree.dot -o tree.png
export_graphviz(dc, out_file="./tree.dot", feature_names=['age', 'pclass=1st', 'pclass=2nd', 'pclass=3rd', '女性', '男性'])
四、决策树总结
优势:
- 易于理解和解释,树形可视化
缺点:
- 决策树学习器可以创建不能很好地泛化到数据的过于复杂的树,这被称为过度拟合。
提升:
- 减枝cart算法(决策树API当中已经实现,随机森林参数调优有相关介绍)
文章出处登录后可见!