Pensieve
第一步:利用setup.py 配置环境的文件
Install prerequisites (tested with Ubuntu 16.04, Tensorflow v1.1.0, TFLearn v0.3.1 and Selenium v2.39.0)
import os
start_dir = os.getcwd()
# mahimahi
print ('mahimahi begin')
os.system("sudo sysctl -w net.ipv4.ip_forward=1")
#os.system("sudo add-apt-repository -y ppa:keithw/mahimahi") 这句话不重要,跑不了的话可以不跑
os.system("sudo apt-get -y update")
os.system("sudo apt-get -y install mahimahi")
print ('mahimahi finish')
# apache server
os.system("sudo apt-get -y install apache2")
# selenium
print('selenium begin')
#os.system("wget 'https://pypi.python.org/packages/source/s/selenium/selenium-2.39.0.tar.gz'") #下载不下来的话可以在windows里面下好了传给服务器,然后再pensieve文件夹下面继续setup.py,解压缩等
#os.system("sudo apt-get -y install python-setuptools python-pip xvfb xserver-xephyr tightvncserver unzip") #我的环境已经有了,不需要重新下载
os.system("tar xvzf selenium-2.39.0.tar.gz")
selenium_dir = start_dir + "/selenium-2.39.0"
os.chdir( selenium_dir )
os.system("sudo python setup.py install" )
os.system("sudo sh -c \"echo 'DBUS_SESSION_BUS_ADDRESS=/dev/null' > /etc/init.d/selenium\"")
print('selenium finish')
# py virtual display
print('pyvirtualdisplay begin')
os.chdir( start_dir )
os.system("pip install pyvirtualdisplay")
os.system("wget 'https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb' ") #和上面的gz文件同理,先下载下来,然后再传到pensieve文件夹下继续跑setup.py。
os.system("sudo dpkg -i google-chrome-stable_current_amd64.deb")
os.system("sudo apt-get -f -y install")
print('pyvirtualdisplay finish')
#####下面这些之前就有#####
# tensorflow
#os.system("sudo apt-get -y install python-pip python-dev")
#os.system("sudo pip install tensorflow")
# tflearn
#os.system("sudo pip install tflearn")
#os.system("sudo apt-get -y install python-h5py")
#os.system("sudo apt-get -y install python-scipy")
# matplotlib
# os.system("sudo apt-get -y install python-matplotlib")
# copy the webpage files to /var/www/html
print('copying')
os.chdir( start_dir )
os.system("sudo cp video_server/myindex_*.html /var/www/html")
os.system("sudo cp video_server/dash.all.min.js /var/www/html")
os.system("sudo cp -r video_server/video* /var/www/html")
os.system("sudo cp video_server/Manifest.mpd /var/www/html")
# make results directory
print('making dir')
os.system("mkdir cooked_traces")
os.system("mkdir rl_server/results")
os.system("mkdir run_exp/results")
os.system("mkdir real_exp/results")
# need to copy the trace and pre-trained NN model
print ("Need to put trace files in 'pensieve/cooked_traces'.")
print ("Need to put pre-trained NN model in 'pensieve/rl_server/results'.")
print('finish')
第 2 步:下载数据集
数据集1:[PiTree 清华数据集][https://transys.io/pitree-dataset/traces/index.html]、FCC18、HSR、Ghent、Lab(都可以在清华的这个网站找到)
PiTree 数据集的动机是自适应视频流中现有数据集的不足。许多现有的仿真数据集,例如Pensieve或Oboe是多年前收集的,平均带宽约为 1Mbps。然而,随着最近通信技术(例如,5G)的发展,现在的互联网通常提供超过10Mbps的更高带宽。因此,我们认为有必要在视频和网络轨迹上构建一个新的数据集,以忠实地评估比特率自适应算法的性能。
- FCC18 is the measurement results of the broadband network in 2018 provided by FCC, with a median bandwidth improvement by 4.04x compared to 2016. ( origin )
- HSR . We adopt the 4G measurements on high-speed rails in 2018 to construct a scenario with violently fluctuating 4G bandwidths. ( origin )
- Ghent . We use the 4G measurements on foot, bicycle, bus, tram, train, and car in 2016 by Ghent University, which are moderately fluctuating 4G bandwidths. ( origin )
- Lab . Finally, we also measure the indoor 4G bandwidth during the period of 2019-07-02 to 2019-08-15. To ensure the comprehensiveness of the dataset, we interchangeably use four congestion control algorithms (BBR, Cubic, Vegas, and HighSpeed). The indoor traces construct a scenario with gently fluctuating 4G bandwidths.
#单个转换
python sim2mahimahi.py -i hd_sim/ghent/ -o hd_mahimahi/ghent/
#批量转换
python setup_sim2mahimahi.py -i hd_sim
数据集2
pensieve/traces/README.md中讲的很详细
- To download the raw data, follow
```
# FCC broadband dataset
$ wget http://data.fcc.gov/download/measuring-broadband-america/2016/data-raw-2016-jun.tar.gz
$ tar -xvzf data-raw-2016-jun.tar.gz -C fcc
# Norway HSDPA bandwidth logs
$ wget -r --no-parent --reject "index.html*" http://home.ifi.uio.no/paalh/dataset/hsdpa-tcp-logs/
# Belgium 4G/LTE bandwidth logs (bonus)
$ wget http://users.ugent.be/~jvdrhoof/dataset-4g/logs/logs_all.zip
$ unzip logs_all.zip -d belgium
```
- For actual video streaming over Mahimahi (http://mahimahi.mit.edu), the format of the traces should be converted to the following
```
Each line gives a timestamp in milliseconds (from the beginning of the
trace) and represents an opportunity for one 1500-byte packet to be
drained from the bottleneck queue and cross the link. If more than one
MTU-sized packet can be transmitted in a particular millisecond, the
same timestamp is repeated on multiple lines.
```
An example mahimahi trace `run_exp/12mbps` depicts 12Mbit/sec bandwidth. More details of mahimahi trace file requirements can be found in https://github.com/ravinet/mahimahi/tree/master/traces. In our case, the script `convert_mahimahi_format.py` in `traces/norway/` and `traces/fcc/` can be used. Some samples of preprocessed data can be downloaded in `cooked_traces` from https://www.dropbox.com/sh/ss0zs1lc4cklu3u/AAB-8WC3cHD4PTtYT0E4M19Ja?dl=0.
- For simulations, the format should be `[time_stamp (sec), throughput (Mbit/sec)]`. Some sample can be downloaded in `train_sim_traces` and `test_sim_traces` from https://www.dropbox.com/sh/ss0zs1lc4cklu3u/AAB-8WC3cHD4PTtYT0E4M19Ja?dl=0.
数据集3
在#issue134中作者放入了原始训练数据集(https://github.com/hongzimao/pensieve/issues/134)
第三步:在虚拟环境下训练RL
1) python get_video_sizes.py
2) python multi_agent.py
- 现在的temsorflow1.15跑代码会有很多的warning,在文档开头加入下面的代码块即可不显示
- 我的是python3,所以把所有xrange改成range,‘wb’改成‘w’,‘rb’改成‘r’
import os
import warnings
warnings.filterwarnings('ignore')
import logging
logging.disable(logging.WARNING)
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3"
- 由于作者是在CPU上跑的代码,并且说[CPU和GPU的性能速度效果差不多][https://github.com/hongzimao/pensieve/issues/14]。对于要在GPU上面跑这个代码没有给出详细的说明而且会报错,因此在这里先用CPU运行。
- 观测RL训练是否收敛的[问题][https://github.com/hongzimao/pensieve/issues/76]
- https 😕/people.csail.mit.edu/hongzi/var-website/index.html
- td_loss(策略梯度损失)有很大的方差可能是由于多种原因;一个重要的问题是输入过程中的随机性(在这种情况下是网络跟踪),要观测
验证数据集中的奖励是否有所改善
. - 只训练一个视频
- 论文使用的数据比 repo 中的要多。小数据集是为了让其他人快速重现一阶结果并获得学习方法的感觉。
- 熵需要通过训练衰减。
- 要对多个视频进行训练的话要用https://github.com/hongzimao/pensieve/tree/master/multi_video_sim的代码
第四步:验证模型效果
将test cooked traces 复制:
import os
os.system('cp -r ./cooked_test_traces ../test/cooked_traces' )
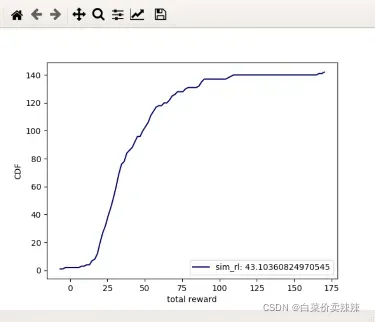
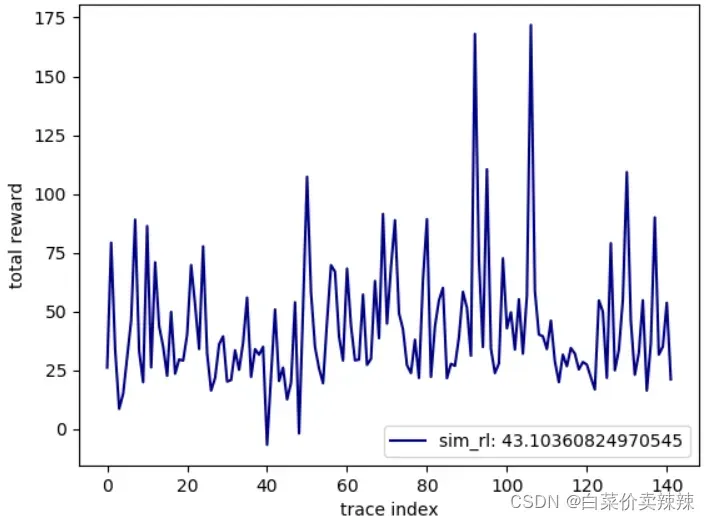
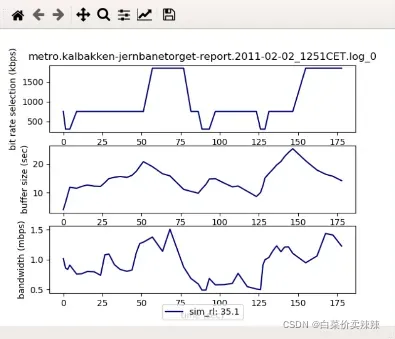
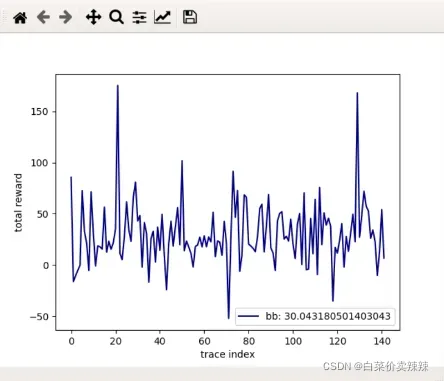
BB模型
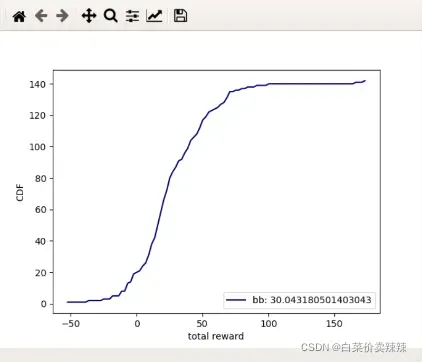
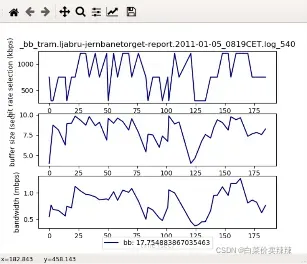
- 运行mpc.py的时候会报错是因为88-91行少了一个输出

改成
正好
- 原作者说dp.py和dp.cc是最简单的说明这是一个optimal question的模型,因此,这部分代码没有跑
- 还有一个要注意的点是绘制图像的时候,要注意SCHEMES中只能输入一个参数(‘sim_rl’,‘bb’,‘mpc’中的一个),如果要看对比的话,要自己改一下下面的代码。
- 以下是mpc的结果
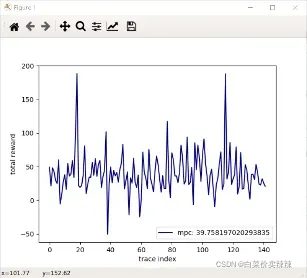
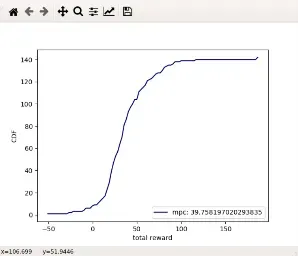
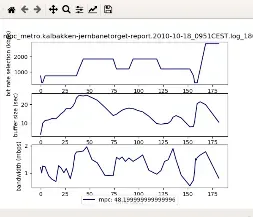
第五步:MahiMahi网络仿真
第 6 步:实际平台测试
5和6以及一些其他的问题下次再更新
文章出处登录后可见!
已经登录?立即刷新