本篇论文是发表在 CVPR_2019 上的一篇工作,提出了一个关于行人检测的新思路。
- 论文链接: https://openaccess.thecvf.com/content_CVPR_2019/papers/Liu_High-Level_Semantic_Feature_Detection_A_New_Perspective_for_Pedestrian_Detection_CVPR_2019_paper.pdf
- 代码链接: https://github.com/liuwei16/CSP
1. 动机
现有的目标检测算法大多是基于滑动窗口或者锚框(Anchor)的检测算法,这些方法都需要进行繁琐的设置,滑窗和锚框都需要精心的设计。文章提出一种新的视角:将目标检测看作高级语义特征检测任务。通过卷积操作将行人检测简化为行人中心和尺度预测任务。
2. 主要工作
2.1 模型结构
行人检测被简单地表述为一个简单的中心和尺度预测卷积,提出了基于中心和尺度预测 (CSP) 的检测模型。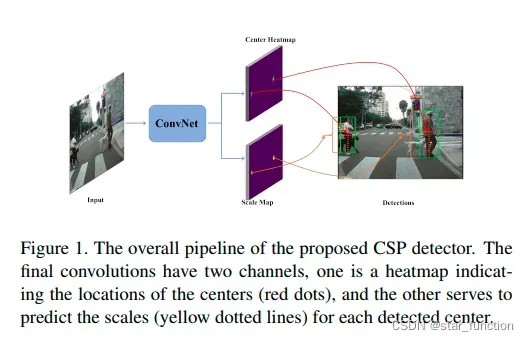
- 特征提取
较浅的特征图可以提供更精确的定位信息,而较粗的特征图随着感受野大小的增加包含更多的语义信息。 因此,用一种简单的方式将这些来自每个阶段的多尺度特征图融合为一个单一的特征图,即采用反卷积层使多尺度特征图具有相同分辨率,然后再进行连接。由于每个阶段的特征图具有不同的尺度,我们使用 L2 归一化将它们的范数重新缩放到 10。
**注:**反卷积(Transposed Convolution)也被称为转置卷积。通常被用来扩大图像尺寸,实现图像由小分辨率到大分辨率的映射的操作。反卷积的相关知识可以参考一篇知乎博文反卷积(Transposed Convolution)详细推导。
- 检测头
首先在 Φdet 上附加一个 3×3 Conv 层以减少其通道尺寸为 256,然后是两个同级 1×1 Conv层分别生成中心热图和比例图。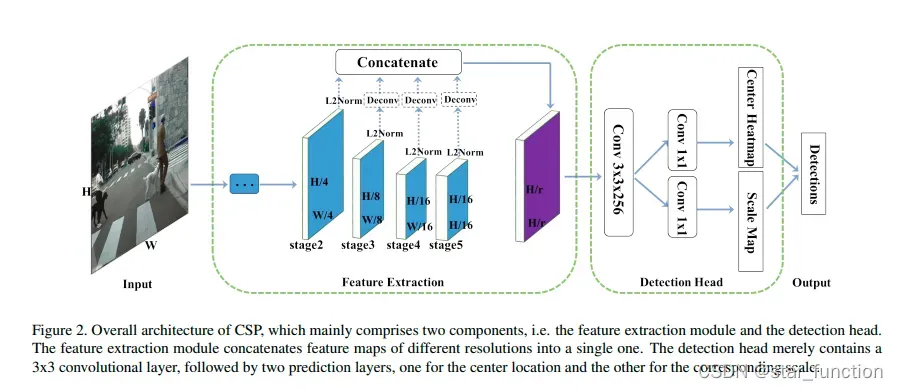
2.2 损失函数
- Ground Truth
对于中心 ground truth,所有对象中心点的位置都被指定为正,否则为负。
对于尺度 ground truth,第k个正位置被分配与第k个目标对应的log(hk)值。 为了减少歧义,log(hk) 也被分配给以正样本为中心半径为 2 内的负样本,而所有其他位置都被分配为零。行人边界框比例为 0.41,因此只预测行人高度,然后通过比例预测边界框。
中心和尺度 Ground Truth 如图 b 所示:
- 中心点预测分支(分类损失)
将行人中心点预测看作是一个分类问题,通过交叉熵损失(cross-entropy loss)进行计算。
由于行人中心点很难界定,因此高斯掩膜 2D Gaussian mask G(.) 来减少正样本附近负样本的模棱两可(将中心点周围的一些负样本也看作是正样本)。
在一张图片中有 K 个目标,(xk, yk, wk, hk) 是第 K 个目标的中心点 x,y 坐标,宽度和高度
高斯掩膜的方差 (σkw, σkh) 和目标的高度和宽度成正比。如果掩膜间有重叠,选择重叠位置的最大值。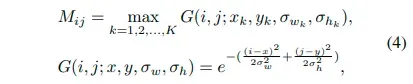
高斯掩码如下所示:
为了平衡正负样本,在难样本上使用 focal loss。最终的分类损失计算如下:
pij ∈ [0, 1] 指网络预测位置 (i , j) 是目标中心的可能性,yij ∈ {0, 1} 是 ground truth label,yij 为 1 代表正样本位置
αij 和 γ 是 focusing 的超参数,αij 根据高斯掩膜(Gaussian mask) M 来计算,用于减少正负样本间的模棱两可,β 用来控制总损失中的正负样本损失的惩罚项大小。
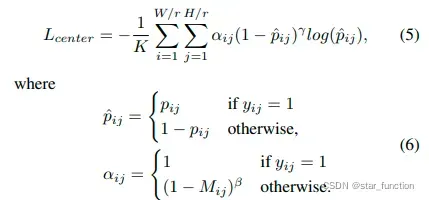
- 尺度预测分支(回归损失)
将尺度预测看作是一个回归任务,通过 smooth L1 loss 进行计算。
sk 指网络的预测输出, tk 指正样本的 ground truth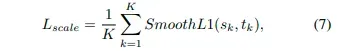
- 总体损耗
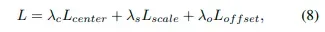
3. 实验
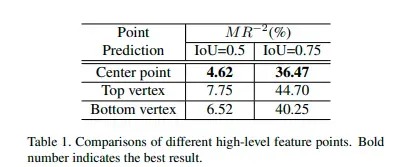
- 实验一:为什么要使用中心点
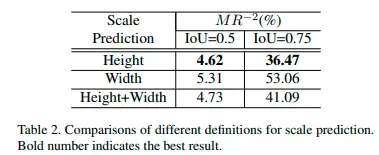
- 实验二:尺度预测有多重要
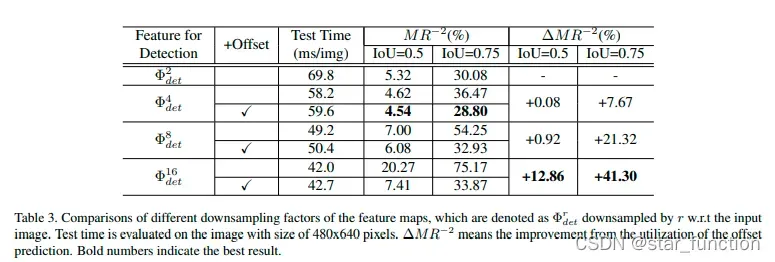
- 实验3:特征层下采样的分辨率
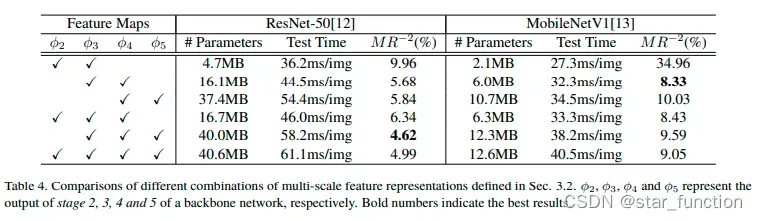
- 实验四:特征融合的卷积层选择
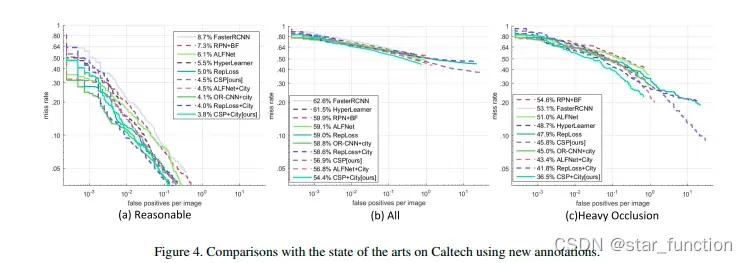
- 实验五:在 Caltech 数据集上使用新标注,和 SOTA 算法的对比
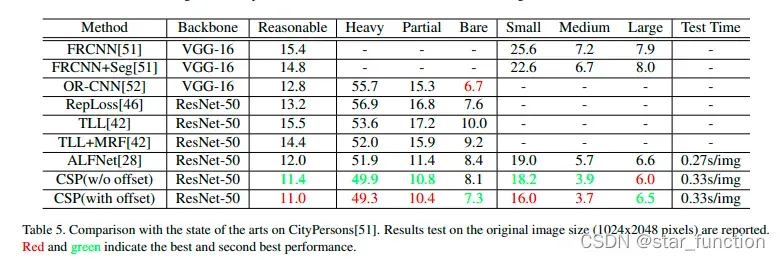
- 实验六:在 CityPersons 数据集上和 SOTA 算法的对比
相关链接
论文 CenterNet 和 CSP 有很多相似的观点,它们都受到了 CornerNet 网络的影响,感兴趣的小伙伴可以了解下CenterNet算法。下面给出了一篇写得很详细的解读 CenterNet 的文章链接。
- CenterNet算法详解
- 反卷积(Transposed Convolution)详细推导
文章出处登录后可见!