朴素贝叶斯
大意:
Naive(特征相互独立)+贝叶斯算法
优势:
1. 对缺失数据不太敏感,算法也比较简单,常用于文本分类。
2. 分类准确度高,速度快。
3. 朴素贝叶斯模型发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率。
缺点:
由于样本属性独立的假设,如果特征属性相关,则效果不佳。
使用场景:文本分类、垃圾文本过滤、情感判别、多分类实现预测、推荐系统
scikit-learn中的3种不同类型的朴素贝叶斯
1. 高斯分布型 GaussianNB
用于分类问题,假定属性/特征是服从正态分布的。
2. 多项式型 MultinomialNB
适用于离散变量,其假设各个特征xi在各个类别y下是服从多项式分布的,故每个特征值不能是负数。
3. 伯努利型 BernoulliNB
与多项式模型一样,伯努利模型适用于离散特征的情况,所不同的是,伯努利模型中每个特征的取值只能是1和0(以文本分类为例,某个单词在文档中出现过,则其特征值为1,否则为0).
API
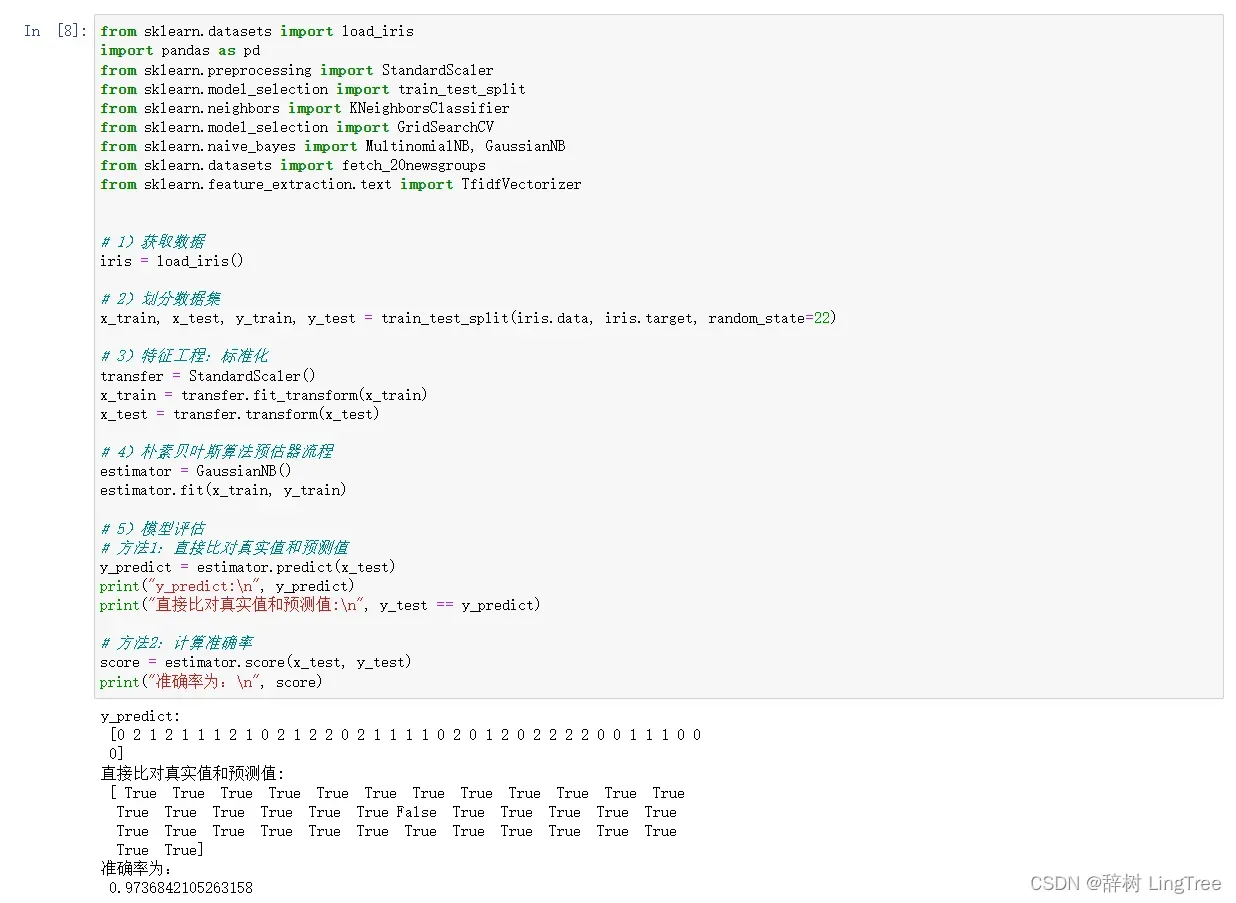
from sklearn.naive_bayes import MultinomialNB, GaussianNB, BernoulliNB示例 1:在 iris 数据集上进行分类预测的高斯朴素贝叶斯
from sklearn.datasets import load_iris
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.naive_bayes import MultinomialNB, GaussianNB, BernoulliNB
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
# 1)获取数据
iris = load_iris()
# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
# 3)特征工程:标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4)朴素贝叶斯算法预估器流程
estimator = BernoulliNB()
estimator.fit(x_train, y_train)
# 5)模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
实例二:多项式朴素贝叶斯对20类新闻分类
"""
用朴素贝叶斯算法对新闻进行分类
:return:
"""
# 1)获取数据
news = fetch_20newsgroups(subset="all")
# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target)
# 3)特征工程:文本特征抽取-tfidf
transfer = TfidfVectorizer()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4)朴素贝叶斯算法预估器流程
estimator = MultinomialNB()
estimator.fit(x_train, y_train)
# 5)模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)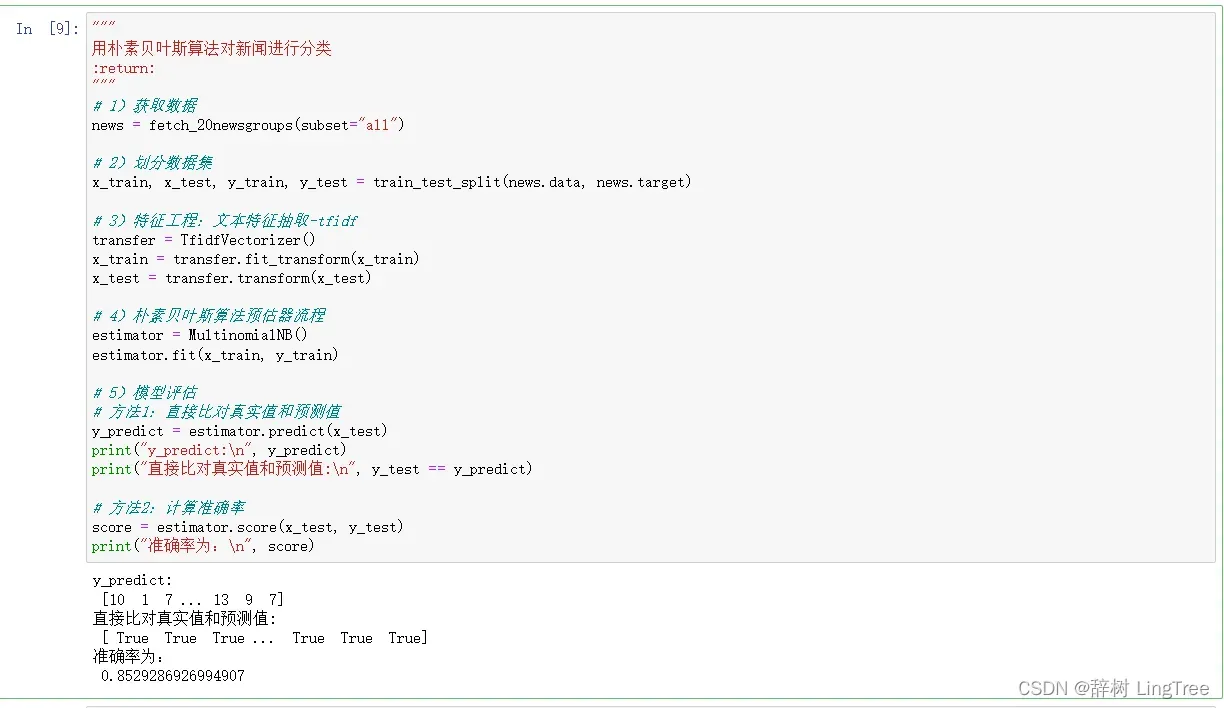
文章出处登录后可见!
已经登录?立即刷新