Pseudo-LiDAR From Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving
该论文是康奈尔大学2018年在CVPR发表的一篇论文,时间虽然有点久远,但算得上单目3D检测中“视觉伪点云流派”的开山鼻祖了,虽然文中有些地方存在争议,但依旧是篇值得一读的经典论文。
- 论文链接: https://arxiv.org/abs/1812.07179
- 论文源码: https://github.com/mileyan/pseudo_lidar
1. 论文动机
在2018年时,主流方法都是激光3D目标检测,对于视觉3D关注还比较少,顶多是利用图像来辅助激光。比如Liang等人通过LV融合的方法将KITTI小车类别的AP从66%提升至73%,而同期的纯图像方法小车类别的AP只有10%左右。
激光和纯图像方法之间存在巨大的性能鸿沟,当时比较流行的解释是——基于图像的深度估计性能较差,因为图形的几何特性导致深度误差会随着距离增加而指数上升,而激光ToF(Time-of-Flight)的检测误差是线性增长的。但是作者将视觉深度估计的点云和激光叠加后发现,二者并不存在过大的性能差距,如图1所示,右侧图像中黄色表示激光点云,蓝色表示视觉深度点云。据此,作者提出了论文的核心观点:视觉和激光3D检测方法性能差距大的原因不是深度准确性的差异,而是当前视觉方法对3D信息特征表达方式不恰当导致的。
 图1 激光点云(黄色)和伪点云(蓝色)对比
图1 激光点云(黄色)和伪点云(蓝色)对比激光信号通常以两种方式表征:3D点云或鸟瞰图(BEV),然后在此基础上再进行特征提取和目标检测。目标激光点云的形状和尺寸不会随着深度变化而变化。但在图像深度估计中需要逐像素进行预测,深度往往是用额外的特征通道表征,考虑到图像存在近大远小的特点,越远的目标占据的图像像素就越少,预测难度就越大。远处一大块3D空间在图像上可能就只有几个像素点大小,而且由于目标边缘的存在,相邻的两个像素点在实际3D空间中可能差的非常远,这些因素使得基于2D卷积的CNN难以准确在3D空间中对目标进行定位。总的来说就是:2D图像每个像素包含的信息密度是不一致的,但2D卷积将整张图一视同仁,这必然会导致信息的损失。
关于这一点作者也通过一个简单的实验进行了论证,如图2所示。左上方是原始的深度图,左下方是深度在BEV的投影效果,并用颜色将车辆的点云单独标记出来。现在使用大小卷积核对左上方深度图进行卷积(等价于5层卷积核大小为
的卷积层),卷积核的权重均匀分布,可以认为是一个均值滤波器。经过卷积后可以看到,右上方的深度图目标的轮廓变得模糊,在BEV上的投影也变得发散。个人觉得这个实验不是很严谨,毕竟使用一个均值滤波核去对深度图进行卷积,必然会导致深度的发散。但结合作者在论文方法那一章的解释,我大概能理解作者想要表达的意思——尽管CNN可以学习到不同的卷积核,但卷积运算局部连接和共享权重的固有特性会导致计算得到的深度出现失真。举两个简单的例子,比如在物理上相邻的两个像素,可能位于远近不同的目标上,那么这两个像素在3D空间中深度的差距可能非常大,而卷积本质上是对一块邻域进行加权平均,那么这两个像素经由卷积之后深度特征难免发生偏差。另一个例子是,图像存在近大远小的特点,同一个像素在图像不同位置对应的3D尺度信息是不同的,使用同一个卷积核对不同图像区域进行深度特征提取的方式肯定是不恰当的,不过可以利用FPN多尺度特征的方式进行一定缓解,但无法从根本上解决该问题。
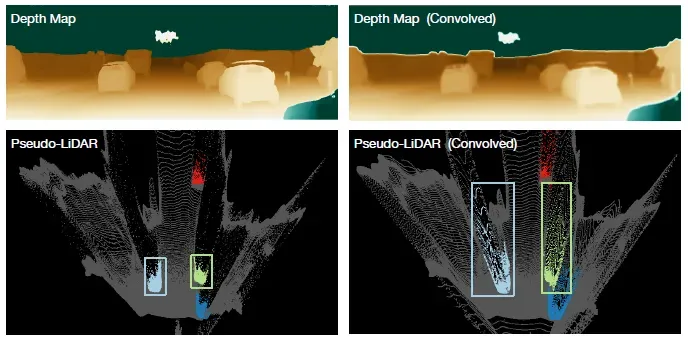 图2 2D卷积对深度的影响
图2 2D卷积对深度的影响所以作者提议视觉3D检测也在3D空间或BEV空间进行,将视觉深度估计预测的点云视为激光点云,并称之为“伪点云”,然后使用激光3D检测的方法在伪点云上进行目标检测。
这里发表一点个人看法,作者主张当前视觉3D检测方法性能差是深度信息表征方式不恰当导致的,使得2D图像特征到3D空间的学习变得非常不稳定,如果按照这个理论,视觉深度估计性能也应该很差才对(因为深度估计的输入也只是相机图像),但实际上作者却提出“当前视觉伪点云质量媲美激光,所以可以在伪点云上进行目标检测”,感觉有点自相矛盾。作者没有解释清楚的一个问题是,同样是利用图像特征,为什么视觉点云质量可以达到那么好,但是视觉3D目标检测性能就这么差。毕竟,目标检测任务涉及的信息复杂度远不及深度估计,深度估计能做好理论上目标检测也能做好。
2. 方法介绍
如果对激光3D检测有一定了解,就很容易理解论文提出的方法,简单来说就是把视觉深度估计和激光3D检测两个任务拼起来,是一个两阶段任务。首先利用深度估计从图像预测“伪点云”,然后把“伪点云”完全当做激光点云处理,后续就可以完全沿用现有激光3D检测方法了,甚至LV融合也可以加进来,如图3所示。该论文方法基本上就是沿用激光3D检测的Pipeline,只不过点云输入不是通过激光检测获得,而是通过深度估计获得,这也是为什么称之为“伪点云”。
 图3 方法框架图
图3 方法框架图首先使用视觉深度估计方法(双目视差或单目深度)得到深度图,然后通过相机内参将深度图转换为伪点云:其中
为像素值,
为预测深度,
是相机坐标下的坐标,即伪点云坐标。为了使伪点云与激光点云尽可能相似,作者还去掉了高度值较大的伪点云(如天空)。
3. 实验结果
作者对比了Mono3D、MLF、3DOP方法的性能,其中Mono3D是单目方法,MLF是双目方法,但公布了单目和双目配置下的性能,分别对应表格中的MLF-MONO和MLF-STEREO。作者自己则使用了PSMNET和DISPNET来进行双目深度估计,其中DISPNET有两个版本,区别是否是包含correlations layers,分别用DISPNET-S和DISPNET-C表示。然后使用了PointNet(F-POINTNET)和AVOD方法在伪点云上进行3D目标检测。作者还实验了单目深度估计方法DORN,尽管DORN的训练集比PSMNET大10倍以上,性能仍然是PSMNET较优,所以论文后续实验都是用双目视差的方法来估计深度。
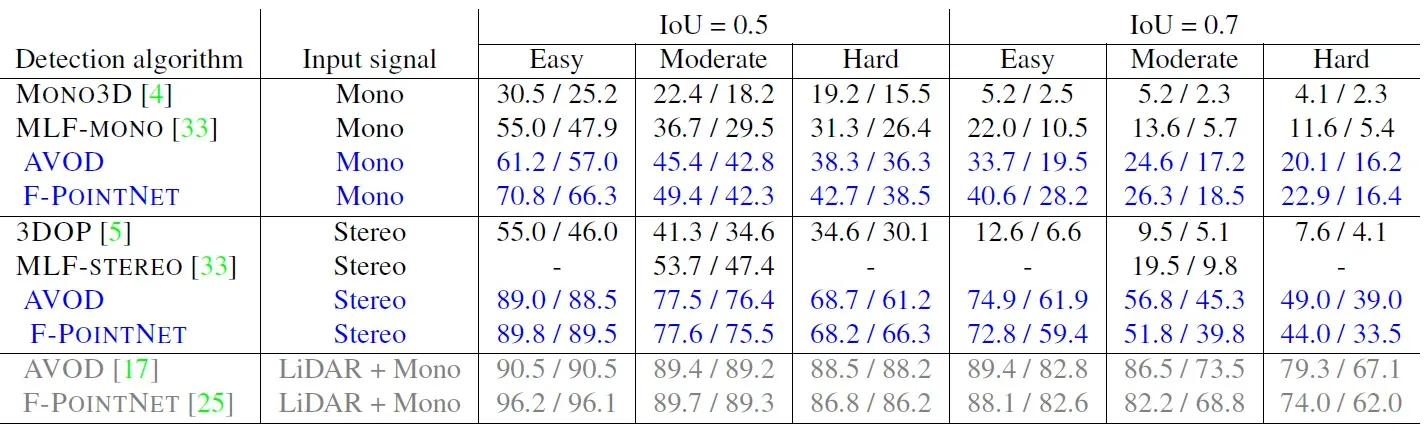 表1 KITTI验证集性能(标蓝的为论文方法)
表1 KITTI验证集性能(标蓝的为论文方法)为了说明数据表征方式对性能的影响,作者还进行了2组消融实验,如表2所示。MLF方法将像素深度映射到3D空间坐标系,然后再把3D坐标以特征通道的方式concat在图像RGB通道之后,最后使用定制化的Faster-RCNN进行3D目标检测,从表格中的数据可以看出(前3行),该方式的性能远不及在伪点云上进行检测。但这一组实验存在一个问题,就是没有排除检测头对于最终性能的影响,毕竟AVOD是针对3D任务的检测头,而Faster-RCNN是针对2D任务的检测头。
所以为了进一步排除干扰因素,作者进行了另一组实验,结果见表2的倒数两行。作者首先利用PSMNET生成像素的3D世界坐标、视差以及到相机的欧氏距离,一共5张前视图的特征图,然后将其concat到图像RGB通道之后,然后修改AVOD方法,在不修改模型框架的前提下,使其训练完全依赖于前视图分支,不考虑BEV分支的信息,最终性能依旧不如伪点云检测方案。所以即使前视图特征包含了足够的3D信息,却依然获取不到准确的目标深度,作者认为这再次印证了观点:将深度相距很远的像素放到一起进行卷积,难以进行准确的定位。
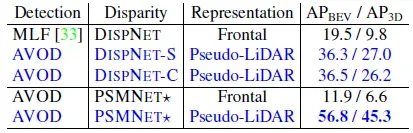 表2 数据表征方式的消融实验
表2 数据表征方式的消融实验文章出处登录后可见!