和生物界中生物的繁殖进化一样,遗传算法的过程主要包括:选择,交叉,变异,每次迭代都能生成比上一代更好的种群。并且,交叉应该是高概率,变异应该是低概率(维持物种稳定,并且能够进化)。
算法主要思想(无性繁殖,纯属个人见解):根据当前种群生成两份样本,第一份:用当代最好的一半样本直接变异,生成一份新的样本;第二份:从当代最好的一半样本中随机选择,构成新的另一半样本,不变异。(自然界中有无性繁殖,所以交叉这一步似乎可以省略,以下程序直接忽略交叉这一步)。注明:高概率交叉也是可行的(传统算法都是高概率交叉)。
第一代种群的个体可以随机生成,也可以先利用贪心算法,生成一个较优的路径(在初始种群中有一个优秀的个体),迭代循环刚开始时,就可以得到一个较优的路径,减少循环迭代的次数。若不使用贪心算法,迭代循环刚开始时,得到的路径较长。这一步有无对最后结果没有影响。
使用多线程,每个线程单独求解,最后汇总所有线程的结果,取最优的。计算密集型的程序,多核CPU不能让它闲着。
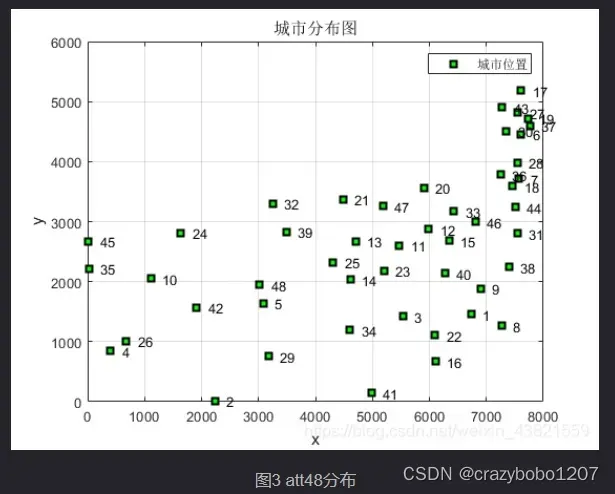
使用att48数据集作为测试,该数据集中包含了48座城市的坐标。
部分代码如下:
#include <vector>
#include <algorithm>
#include <execution>
#include <random>
#include <thread>
#include <iostream>
using namespace std;
const int city_num = 48;
const int population_size = 1000;
const int iteration_times = 2000;
const float crossover_chance = 0.5;
//const float mutation_chance = 0.02;
const int thread_num = 16;
const int best_solution = 10628;
class Point
{
public:
short int id;
short int x;
short int y;
public:
Point(short int _id = 0, short int _x = 0, short int _y = 0) :id(_id), x(_x), y(_y)
{
}
};
typedef vector<Point> Points;
typedef vector<Point> Individual;
typedef vector<Individual> Population;
int GetPointsFromFile(const char filename[], Points& points);
void GetDistanceMatrix(const Points& points);
int GetDistance(const Point& p1, const Point& p2);
int GetPathLength(int index[]);
void InitPopulation(Population& population, const Points& points);
void GreedyInitPath(const Points& points, Individual& indiv);//可有可无,差别不大
void Selection(const Population& population, Population& parents);
void CPX(const Individual& p1, const Individual& p2, Individual& children);//我是摆设
void Mutation(Individual& indiv);
bool Cmp(const Individual& indiv1, const Individual& indiv2);
int Tsp(const Points& points, int shorest_path_length_of_thread[], int tid);
int dis[city_num][city_num];
//略
int main()
{
clock_t t = clock();
const char filename[100] = "E:\\att48.txt";
Points points;
GetPointsFromFile(filename, points);
GetDistanceMatrix(points);
int shorest_path_length = INT_MAX;
int shorest_path_length_sum = 0;
int shorest_path_length_of_thread[thread_num];
int shortest_path_thread_id;
thread td[thread_num];
for (int i = 0; i < thread_num; i++)
{
td[i] = thread(&Tsp, points, shorest_path_length_of_thread, i);
}
for (int i = 0; i < thread_num; i++)
{
td[i].join();
}
for (int i = 0; i < thread_num; i++)
{
shorest_path_length_sum += shorest_path_length_of_thread[i];
if (shorest_path_length_of_thread[i] < shorest_path_length)
{
shorest_path_length = shorest_path_length_of_thread[i];
shortest_path_thread_id = i;
}
}
cout << "最短路径平均值: " << shorest_path_length_sum / thread_num;
cout << ", 和最优解之间的误差: " << fabs((float)(best_solution - shorest_path_length_sum / thread_num)) / (float)best_solution * 100.0 << "%" << endl;
cout << "第" << shortest_path_thread_id << "个线程得到最短路径的解最优, ";
cout << "路径长度: " << shorest_path_length;
cout << ", 和最优解之间的误差: " << fabs((float)(best_solution - shorest_path_length)) / (float)best_solution * 100.0 << "%" << endl;
cout << "用时" << ((double)clock() - (double)t) / CLOCKS_PER_SEC << "秒";
return 0;
}部分运行结果如下:
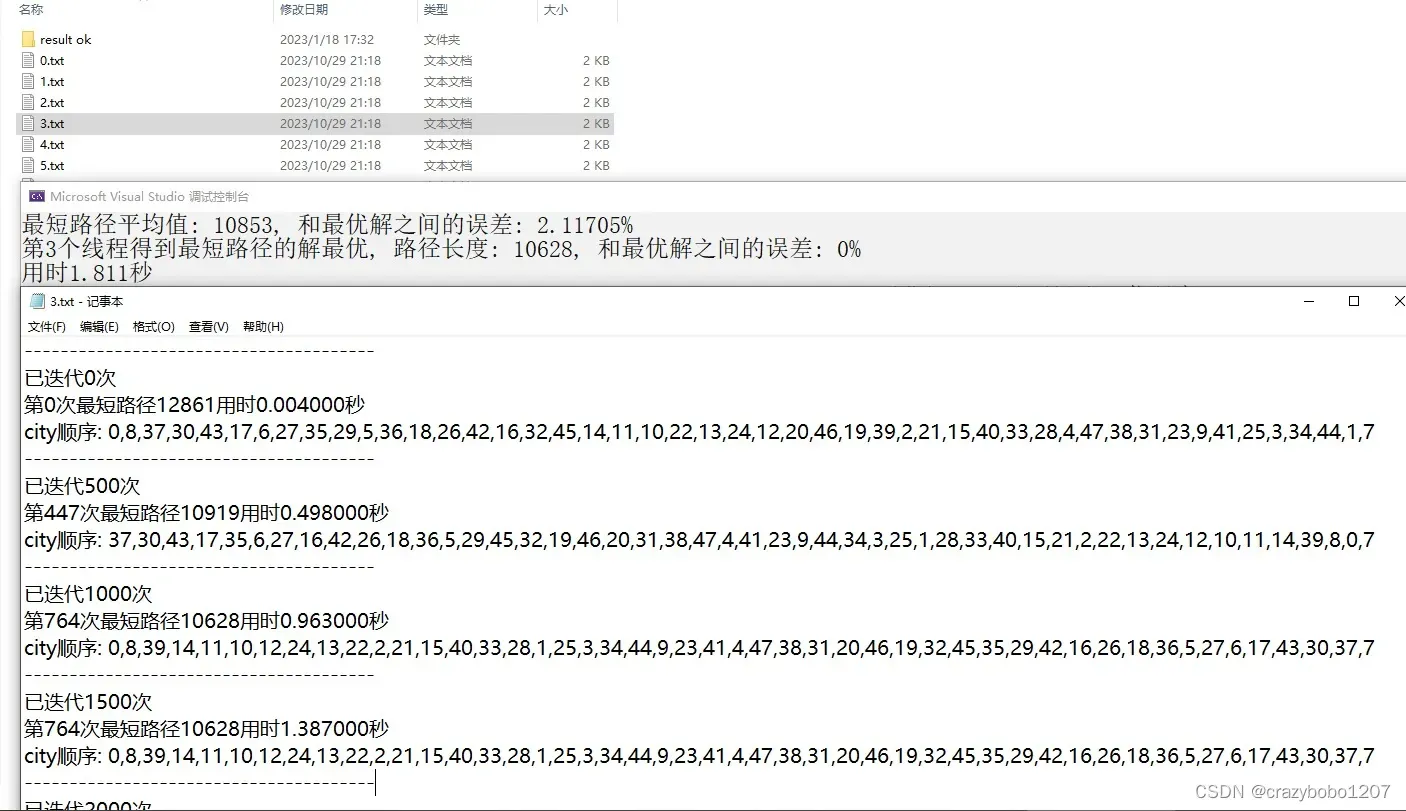
第3个线程迭代764次时,得到了最优解10628,用时不到1秒,速度还行,但还是有点慢,常见TSP数据集的最优解如下:
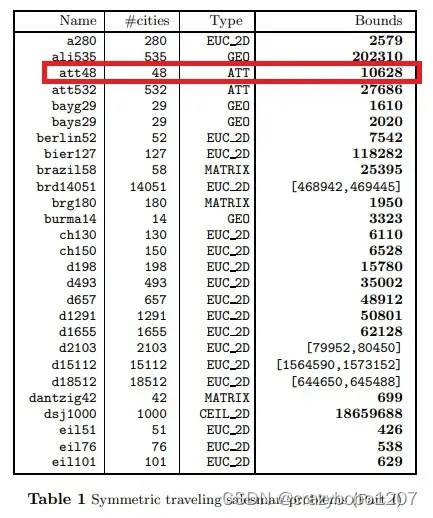
每个数据集的距离计算公式不一样,参见http://comopt.ifi.uni-heidelberg.de/software/TSPLIB95/tsp95.pdf
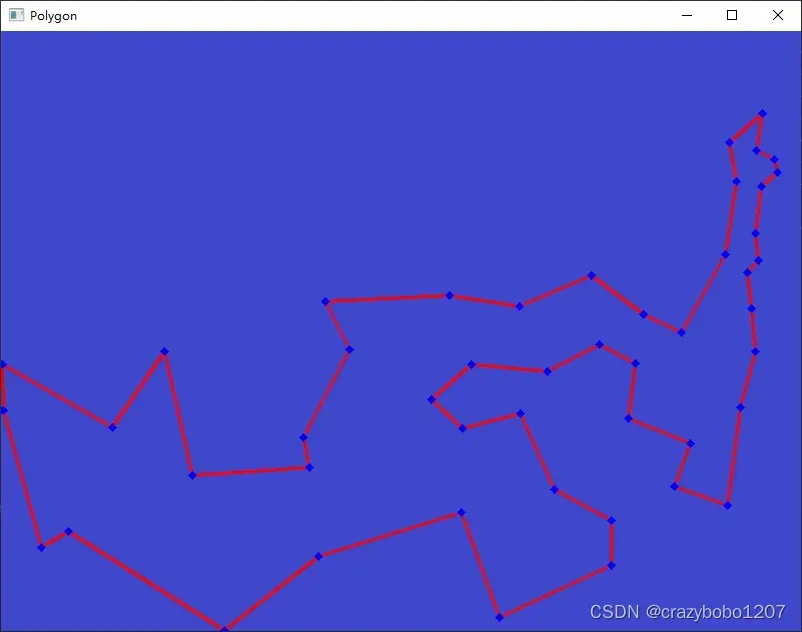
得到的最优路径用python绘制如下:
文章出处登录后可见!
已经登录?立即刷新