1.简介
最近在做分割任务,看了一篇《A ConvNet for the 2020s》里面提到一个upernet网络做分割任务,发现现在很多做分割的都基于mmsegmentation这个类似的工具箱做,所以我也尝试用它训练一下,也方便以后做对比实验。因为第一次使用mmsegmentation,所以不太熟练,经过几天努力终于跑通了,在这里记录和分享一下,免得以后自己忘记那个步骤,又跑不通了。
github的代码链接:https://github.com/open-mmlab/mmsegmentation
2.环境介绍
要根据自己的电脑或者服务器的配置(CUDA版本)来选择安装相应的pytorch版本。python我直接安装了3.7的版本(官方要求大于3.6就可以了)。
创建环境指令
conda create -n mmlab python=3.7
安装pytorch
pytorch的官网链接代码:https://pytorch.org/get-started/previous-versions
我电脑的cuda版本是10.2的,所以装的pytorch版本是1.5.1的(官方要求大于1.3的就可以了)。
# CUDA 10.2
conda install pytorch==1.5.1 torchvision==0.6.1 cudatoolkit=10.2 -c pytorch
我使用服务器的cuda版本是11.4的,所以装的1.7.1版本的pytorch。
# CUDA 11.0
conda install pytorch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2 cudatoolkit=11.0 -c pytorch
3.安装mmcv
建议安装mmcv前先安装一下opencv(从别的代码得到的经验),反正后面也要装。
opencv安装指令
pip install opencv-python
1)使用mim安装mmcv(跟官网一样)
pip install -U openmim
mim install mmcv-full
我默认安装的mmcv-full版本是1.7.1。安装其它版本的话可以将上面的第二条指令换成下面的。(1.x.x表示版本,如mmcv-full==1.5.1)
mim install mmcv-full==1.x.x
2)使用pip安装mmcv
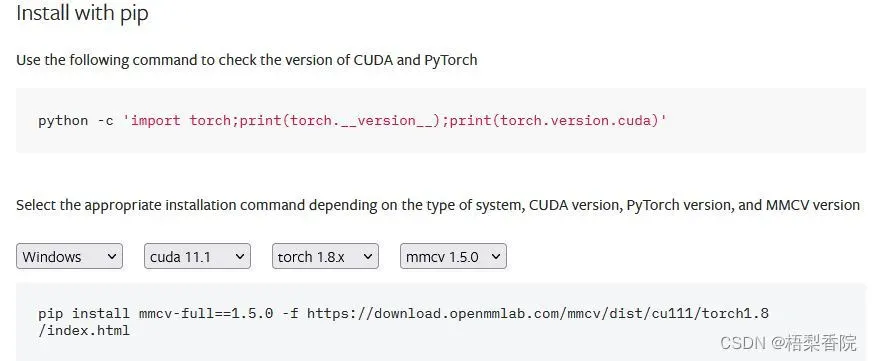
可以参考这个官方提供的网址:https://mmcv.readthedocs.io/en/latest/get_started/installation.html 这里面可以让你根据自己的系统,cuda版本,torch版本安装对应的mmcv-full版本。下面是一个例子:
pip install mmcv-full==1.5.0 -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.8/index.html
网址一点内容截图
4.安装mmsegmentation
我是源码安装的
从github上下载代码,然后解压到自己的文件夹下。
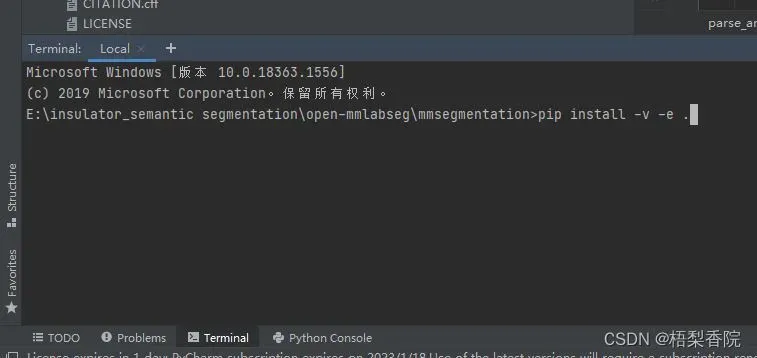
然后在mmsegmentation目录下执行以下指令(注意最后那个点也是指令的一部分):
pip install -v -e .
下面是我在自己电脑下采用pycharm编译器运行的方式:
 服务器上就更简单了,这里就不说了。
服务器上就更简单了,这里就不说了。
5.验证安装
这部分按照官网来就可以了,在windowsx下权重和配置的可能有点问题,我没下成功(我从服务器上下的)
验证推理那一步不想像官网那样需要将配置文件和权重的路径一起作为指令输入,可以按照下面方式改一下(其实就是把配置文件(configs),权重和输出的路径在代码中配置好,然后直接运行就可以了)。

6.按照voc格式准备自己的数据集。

7.使用自己的数据集训练upernet_convnext分割网络。
1)在mmsegmentation目录下的configs/base/datasets/下创建一个our_dataset.py文件。
我的our_dataset.py的文件内容如下(其实就是将mmsegmentation原有的pascal_voc12.py的内容复制过来,然后改一下dataset_type和data_root,懒的话可以直接在pascal_voc12.py上改):
# dataset settings
dataset_type = 'Our_Dataset'
data_root = '/semantic_Datasets/VOCdevkit/VOC2007'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
crop_size = (512, 512)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations'),
dict(type='Resize', img_scale=(2048, 512), ratio_range=(0.5, 2.0)),
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
dict(type='RandomFlip', prob=0.5),
dict(type='PhotoMetricDistortion'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_semantic_seg']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(2048, 512),
# img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
data = dict(
samples_per_gpu=4,
workers_per_gpu=4,
train=dict(
type=dataset_type,
data_root=data_root,
img_dir='JPEGImages',
ann_dir='SegmentationClass',
split='ImageSets/Segmentation/train.txt',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
data_root=data_root,
img_dir='JPEGImages',
ann_dir='SegmentationClass',
split='ImageSets/Segmentation/val.txt',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
data_root=data_root,
img_dir='JPEGImages',
ann_dir='SegmentationClass',
split='ImageSets/Segmentation/val.txt',
pipeline=test_pipeline))
2)在mmsegmentation目录下的mmseg/datasets/下创建一个our_dataset.py文件。
我的our_dataset.py的文件内容如下(其实就是将mmsegmentation原有的voc.py的内容复制过来,然后改一下class 类的名称,CLASSES和PALETTE,懒的话可以直接在voc.py上改):
# Copyright (c) OpenMMLab. All rights reserved.
import os.path as osp
from .builder import DATASETS
from .custom import CustomDataset
@DATASETS.register_module()
class Our_Dataset(CustomDataset):
"""Our_Dataset.
Args:
split (str): Split txt file for Pascal VOC.
"""
CLASSES = ('background', 'dusty1', 'dusty2', 'dusty3' )
PALETTE = [[0, 0, 0], [128, 0, 0], [0, 128, 0], [128, 128, 0]]
def __init__(self, split, **kwargs):
super(Our_Dataset, self).__init__(
img_suffix='.jpg', seg_map_suffix='.png', split=split, **kwargs)
assert osp.exists(self.img_dir) and self.split is not None
3)在mmsegmentation目录下的mmseg/datasets/init.py中注册自己的数据集。
就是 from .our_dataset import Our_Dataset 这条代码和__all__=[]最后的那个Our_Dataset。
# Copyright (c) OpenMMLab. All rights reserved.
from .ade import ADE20KDataset
from .builder import DATASETS, PIPELINES, build_dataloader, build_dataset
from .chase_db1 import ChaseDB1Dataset
from .cityscapes import CityscapesDataset
from .coco_stuff import COCOStuffDataset
from .custom import CustomDataset
from .dark_zurich import DarkZurichDataset
from .dataset_wrappers import (ConcatDataset, MultiImageMixDataset,
RepeatDataset)
from .drive import DRIVEDataset
from .face import FaceOccludedDataset
from .hrf import HRFDataset
from .isaid import iSAIDDataset
from .isprs import ISPRSDataset
from .loveda import LoveDADataset
from .night_driving import NightDrivingDataset
from .pascal_context import PascalContextDataset, PascalContextDataset59
from .potsdam import PotsdamDataset
from .stare import STAREDataset
from .voc import PascalVOCDataset
from .our_dataset import Our_Dataset # 自己加进来的
__all__ = [
'CustomDataset', 'build_dataloader', 'ConcatDataset', 'RepeatDataset',
'DATASETS', 'build_dataset', 'PIPELINES', 'CityscapesDataset',
'PascalVOCDataset', 'ADE20KDataset', 'PascalContextDataset',
'PascalContextDataset59', 'ChaseDB1Dataset', 'DRIVEDataset', 'HRFDataset',
'STAREDataset', 'DarkZurichDataset', 'NightDrivingDataset',
'COCOStuffDataset', 'LoveDADataset', 'MultiImageMixDataset',
'iSAIDDataset', 'ISPRSDataset', 'PotsdamDataset', 'FaceOccludedDataset',
'Our_Dataset'
]
4)在mmsegmentation目录下的mmseg/core/evaluation/class_names.py中加入自己数据集的记录。
因为我是voc格式的数据集,所以直接在voc后复制改一下。一共三处增加的地方,别漏了。
def voc_classes():
"""Pascal VOC class names for external use."""
return [
'background', 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus',
'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train',
'tvmonitor'
]
def our_dataset_classes():
"""our dataset class names for external use."""
return [
'background', 'dusty1', 'dusty2', 'dusty3'
]
def voc_palette():
"""Pascal VOC palette for external use."""
return [[0, 0, 0], [128, 0, 0], [0, 128, 0], [128, 128, 0], [0, 0, 128],
[128, 0, 128], [0, 128, 128], [128, 128, 128], [64, 0, 0],
[192, 0, 0], [64, 128, 0], [192, 128, 0], [64, 0, 128],
[192, 0, 128], [64, 128, 128], [192, 128, 128], [0, 64, 0],
[128, 64, 0], [0, 192, 0], [128, 192, 0], [0, 64, 128]]
def our_dataset_palette():
"""our dataset palette for external use."""
return [[0, 0, 0], [128, 0, 0], [0, 128, 0], [128, 128, 0]]
一开始我是漏了这个(就是加上 ‘our_dataset’: [‘our_dataset’] #自己的数据集),但好像不影响代码的训练。到这里关于自己数据集的事结束了。
dataset_aliases = {
'cityscapes': ['cityscapes'],
'ade': ['ade', 'ade20k'],
'voc': ['voc', 'pascal_voc', 'voc12', 'voc12aug'],
'loveda': ['loveda'],
'potsdam': ['potsdam'],
'vaihingen': ['vaihingen'],
'cocostuff': [
'cocostuff', 'cocostuff10k', 'cocostuff164k', 'coco-stuff',
'coco-stuff10k', 'coco-stuff164k', 'coco_stuff', 'coco_stuff10k',
'coco_stuff164k'
],
'isaid': ['isaid', 'iSAID'],
'stare': ['stare', 'STARE'],
'our_dataset': ['our_dataset'] #自己的数据集
}
5)修改tools文件夹下的train.py文件。
因为我不喜欢通过指令来输入配置文件的路径,所以改了一下。我训练时选用的配置文件是upernet_convnext_base_fp16_640x640_160k_ade20k.py,因为mmsegmentation没有提供voc12aug.py的配置文件,所以我只能选这个了(至于为啥不选upernet_convnext_base_fp16_512x512_160k_ade20k.py,是因为跑的时候报错了,也就没有再管)。一开始我对配置文件后缀(voc12aug.py,ade20k.py …)的理解是你的数据集格式必须和配置文件的后缀相一致才能跑(我怀疑这是upernet_convnext_base_fp16_512x512_160k_ade20k.py跑不通的原因),但upernet_convnext_base_fp16_640x640_160k_ade20k.py这个完全能跑,不需要将自己数据集格式转成ADE20K的数据集格式。

train.py中的work-dir可以随便设置
6)修改configs/convnext/文件夹下的upernet_convnext_base_fp16_640x640_160k_ade20k.py文件(可以将这个文件复制一份然后改成our_model.py在进行修改也行,不过train.py要相应修改)
我的upernet_convnext_base_fp16_640x640_160k_ade20k.py文件如下:
主要要修改的地方是_base_ = []中的’…/base/datasets/our_dataset.py’(原是’…/base/datasets/ade20k.py’改成’…/base/datasets/our_dataset.py’,),还有一处是num_classes,因为用的是voc格式的数据集,所以是num_classes=类别数+1(原num_classes=150)。
_base_ = [
'../_base_/models/upernet_convnext.py',
'../_base_/datasets/our_dataset.py', '../_base_/default_runtime.py',
'../_base_/schedules/schedule_160k.py'
]
crop_size = (640, 640)
checkpoint_file = 'https://download.openmmlab.com/mmclassification/v0/convnext/downstream/convnext-base_3rdparty_in21k_20220301-262fd037.pth' # noqa
model = dict(
backbone=dict(
type='mmcls.ConvNeXt',
arch='base',
out_indices=[0, 1, 2, 3],
drop_path_rate=0.4,
layer_scale_init_value=1.0,
gap_before_final_norm=False,
init_cfg=dict(
type='Pretrained', checkpoint=checkpoint_file,
prefix='backbone.')),
decode_head=dict(
in_channels=[128, 256, 512, 1024],
num_classes=4,
),
auxiliary_head=dict(in_channels=512, num_classes=4),
test_cfg=dict(mode='slide', crop_size=crop_size, stride=(426, 426)),
)
optimizer = dict(
constructor='LearningRateDecayOptimizerConstructor',
_delete_=True,
type='AdamW',
lr=0.0001,
betas=(0.9, 0.999),
weight_decay=0.05,
paramwise_cfg={
'decay_rate': 0.9,
'decay_type': 'stage_wise',
'num_layers': 12
})
lr_config = dict(
_delete_=True,
policy='poly',
warmup='linear',
warmup_iters=1500,
warmup_ratio=1e-6,
power=1.0,
min_lr=0.0,
by_epoch=False)
# By default, models are trained on 8 GPUs with 2 images per GPU
data = dict(samples_per_gpu=2)
# fp16 settings
optimizer_config = dict(type='Fp16OptimizerHook', loss_scale='dynamic')
# fp16 placeholder
fp16 = dict()
7)修改mmsegmentation目录下的configs/base/models/下的upernet_convnext.py文件(这个我自己没有修改着)。
因为SyncBN在cpu上是跑不了的,所以想用cpu跑的话需要将SyncBN改成BN(网上说的,我没实践过)。网上有人说需要改这里的 num_classes,我跑的时候发现不需要(可改可不改)。
norm_cfg = dict(type='SyncBN', requires_grad=True)
custom_imports = dict(imports='mmcls.models', allow_failed_imports=False)
checkpoint_file = 'https://download.openmmlab.com/mmclassification/v0/convnext/downstream/convnext-base_3rdparty_32xb128-noema_in1k_20220301-2a0ee547.pth' # noqa
model = dict(
type='EncoderDecoder',
pretrained=None,
backbone=dict(
type='mmcls.ConvNeXt',
arch='base',
out_indices=[0, 1, 2, 3],
drop_path_rate=0.4,
layer_scale_init_value=1.0,
gap_before_final_norm=False,
init_cfg=dict(
type='Pretrained', checkpoint=checkpoint_file,
prefix='backbone.')),
decode_head=dict(
type='UPerHead',
in_channels=[128, 256, 512, 1024],
in_index=[0, 1, 2, 3],
pool_scales=(1, 2, 3, 6),
channels=512,
dropout_ratio=0.1,
num_classes=19,
norm_cfg=norm_cfg,
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
auxiliary_head=dict(
type='FCNHead',
in_channels=384,
in_index=2,
channels=256,
num_convs=1,
concat_input=False,
dropout_ratio=0.1,
num_classes=19,
norm_cfg=norm_cfg,
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
# model training and testing settings
train_cfg=dict(),
test_cfg=dict(mode='whole'))
8)修改mmsegmentation目录下的configs/base/schedules/下的schedule_160k.py文件和configs/base/的default_runtime.py(这两个可改可不改)。里面都是一些训练的配置文件。
schedule_160k.py代码如下:
# optimizer
optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0005)
optimizer_config = dict()
# learning policy
lr_config = dict(policy='poly', power=0.9, min_lr=1e-4, by_epoch=False)
# runtime settings
runner = dict(type='IterBasedRunner', max_iters=160000)
checkpoint_config = dict(by_epoch=False, interval=16000)
evaluation = dict(interval=16000, metric='mIoU', pre_eval=True)
default_runtime.py代码如下:
# yapf:disable
log_config = dict(
interval=200,
hooks=[
dict(type='TextLoggerHook', by_epoch=False),
# dict(type='TensorboardLoggerHook')
# dict(type='PaviLoggerHook') # for internal services
])
# yapf:enable
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = None
resume_from = None
workflow = [('train', 1)]
cudnn_benchmark = True
9)对mmsegmentation进行重新编译
将自己的数据集Our_dataset加入注册器(也就是上面的3)步骤)后必须要对mmsegmentation进行重新编译,每增加个新的就需要重新编译一次。
重新编译指令如下:
python setup.py install
到这一步代码算是全部修改完了
10)最后一步直接运行tools下的train.py就可以了
服务器上的话,在tools目录下:
python train.py
8.在自己的数据集上进行分割结果的可视化。
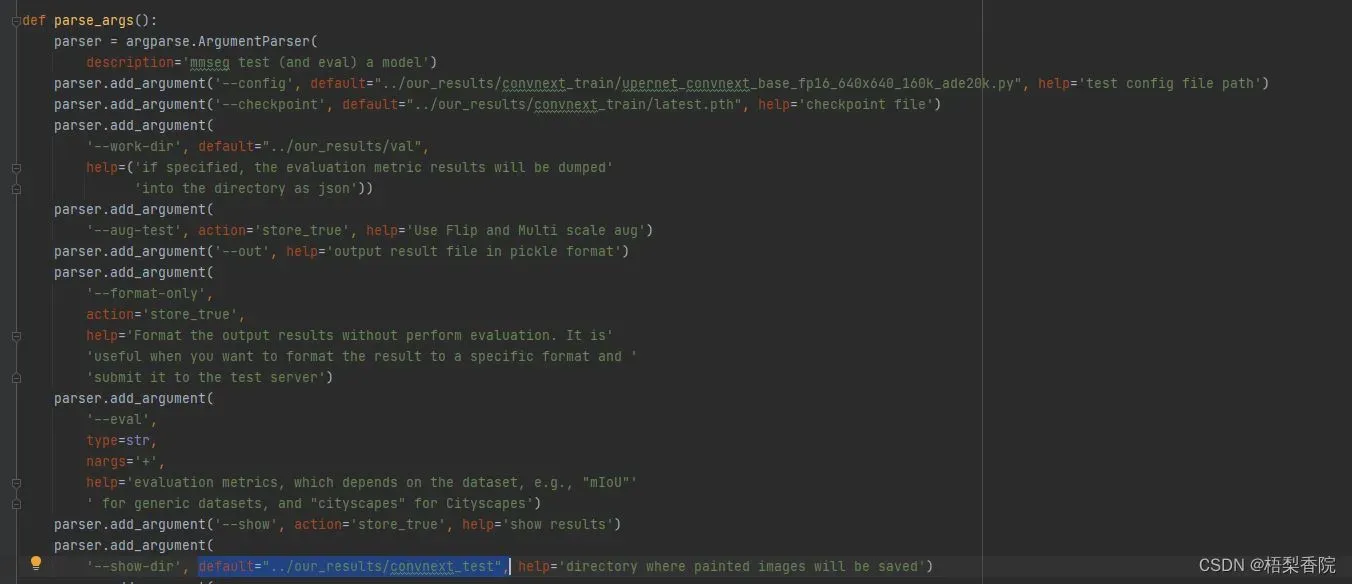
修改tools目录下的test.py文件,主要修改三个地方,分别是–config,–checkpoint和–show-dir。–config需要提供网络的配置文件,这个文件在你训练时设置保存权重的文件夹下,–checkpoint是需要提供训练好的权重,–show-dir是保存可视化结果的路径,自己设置。
完美结束!!!
本以为一小时就能写完,没想到整了三个小时。纯粹为了记录,我自己虽然用csdn很频繁,但很少留意信息什么的,如果有写错的地方欢迎大家指出,也希望能帮到大家。
——记于2023.01.18
文章出处登录后可见!