可视化在深度学习时代算是核心需求,借助可视化功能,研究者可以快速定位分析模型以及排查问题。在 OpenMMLab 2.0 时代,MMEngine 对常用的可视化需求进行了设计和实现,其具备如下功能:
- 提供丰富的开箱即用可视化功能,能够满足大部分计算机视觉可视化任务
- 高扩展性,可视化功能多样化,能够通过简单扩展实现定制需求
- 能够在训练和测试流程的任意点位进行可视化
- OpenMMLab 各个算法库具有统一可视化接口,利于用户理解和维护
系列文章概览
我们将开启可视化分析系列文章,结合 MMYOLO 中的 YOLOv5 算法,对 MMEngine 和 MMDetection 3.x 中实现的可视化功能进行全面解析。通过本系列文章你将能快速掌握常用的可视化使用方法和如何扩展等功能。
整个可视化分析系列文章一共分成 3 个部分,分别对应 Dataset 和测试过程中的可视化、训练过程中的可视化以及其余相关脚本可视化。其目录主结构为:
(1) 第一篇
-
MMEngine 可视化器和可视化后端介绍
-
Dataset 输出可视化
- 可视化 Dataset 输出
- 可视化绘制结果保存到 WandB
-
模型测试中的可视化
- GT 和预测分开可视化
- GT 和预测叠加可视化
- 可视化绘制结果保存到 Tensorboard
- 可视化 NMS 前后结果并将结果保存到 Tensorboard
- 可视化注意力模块并用 WandB 保存为表格格式
(2) 第二篇
-
模型训练中的可视化
- 训练 loss 和评估指标等标量可视化
- 追加自定义标量并存储到 WandB
- YOLOv5 训练中正样本可视化分析
- 配置文件存储和可视化
- Tensorboard 模型结构图可视化
- 参数梯度分布可视化
-
扩展可视化器和可视化后端
(3) 第三篇
- 图片推理结果可视化,包括大图推理
- 特征图可视化
- Grad-Based CAM 和 Grad-Free CAM 可视化
- COCO 数据集标注可视化
- 数据集分布可视化
由于 MMYOLO 中的可视化器是直接引用的 MMDetection 3.x 中,所以本文所述内容完全适用于 MMDetection 3.x,并且因为 MMEngine 中统一了可视化器,因此本文部分内容也同样适用于 OpenMMLab 2.0 的各个框架。
MMEngine 官方地址:
https://github.com/open-mmlab/mmengine
MMDetection 官方地址:
https://github.com/open-mmlab/mmdetection
MMYOLO 官方地址:
https://github.com/open-mmlab/mmyolo
本系列文章包括多位社区小伙伴的热情贡献, GitHub ID:@RangeKing @matrixgame2018 @PeterH0323,感谢大家!
本文是可视化的第一篇,如果大家对系列文章的规划有其他更好意见,欢迎留言给我们反馈!
MMEngine 可视化器和可视化后端介绍
总体介绍
MMEngine 引入了可视化对象 Visualizer 和多个可视化存储后端 VisBackend,如 LocalVisBackend、WandbVisBackend 和 TensorboardVisBackend 等。可视化对象 Visualizer 和可视化存储后端 VisBackend 的关系比较好理解:可视化对象负责绘制过程,而具体的存储交给可视化存储后端。可视化器绘制完成后,可以同时发给多个存储后端。
为了简化接口调用,大部分情况下用户不会直接操作可视化存储后端,而是由可视化器统一管理。可视化对象 Visualizer 具体功能详细说明如下:
- 支持基础绘图接口以及特征图可视化
- 支持本地, TensorBoard 以及 WandB 等多种后端,可以将训练状态例如 loss 、lr 或者性能评估指标以及可视化的结果写入指定的单一或多个后端
- 支持配置文件存储到多个后端,方便后续复现
- 允许在代码库任意位置调用,对任意位置的特征 、 图像 、 状态等进行可视化和存储
功能简介
为了方便不同层级的可视化需求,可视化器 Visualizer 提供了 3 大类 API 接口,分别是:
- 基础绘制接口,典型的如绘制 bbox、mask 和特征图
- OpenMMLab 数据流格式绘制接口 add_datasample,用于支持绘制 MMYOLO 或者其他 算法库 输出的格式
- 存储接口,将绘制后结果存到后端中
详细用法请阅读,本文不再赘述
- 用户文档:https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/advanced_tutorials/visualization.md
- 设计文档:https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/design/visualization.md
简单案例
下面我们给出两个简单例子,希望能提供更直观的体会。
-
叠加绘制多个对象
import torch
import mmcv
from mmengine.visualization import Visualizer
# 图片位于 https://github.com/open-mmlab/mmengine/blob/main/docs/en/_static/image/cat_and_dog.png
image = mmcv.imread('cat_and_dog.png', channel_order='rgb')
# 初始化可视化器
visualizer = Visualizer(image=image)
# 绘制多个检测框
visualizer.draw_bboxes(torch.tensor([[33, 120, 209, 220], [72, 13, 179, 147]]), line_styles='--')
# 绘制单个检测框, xyxy 格式
visualizer.draw_bboxes(torch.tensor([72, 13, 179, 147]), edge_colors='r', line_widths=3)
visualizer.show()
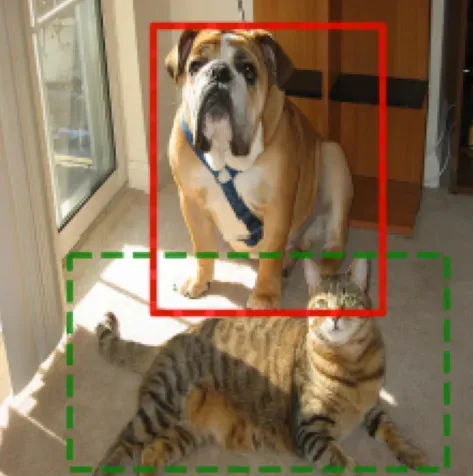
-
绘制内容并存储到多个后端
假设想将绘制的图片保存到本地和 Tensorboard,只需要给 vis_backends 传递多个后端存储对象即可。示例如下:
import torch
import mmcv
from mmengine.visualization import Visualizer
# 图片位于 https://github.com/open-mmlab/mmengine/blob/main/docs/en/_static/image/cat_and_dog.png
image = mmcv.imread('cat_and_dog.png', channel_order='rgb')
# 初始化可视化器
visualizer = Visualizer(image=image, vis_backends=[ dict ( type = 'LocalVisBackend' ), dict ( type = 'TensorboardVisBackend' )], save_dir='temp_dir')
# 绘制多个检测框
visualizer.draw_bboxes(torch.tensor([[33, 120, 209, 220], [72, 13, 179, 147]]), line_styles='--')
# 将图片存储到多个后端中
visualizer.add_image('demo', visualizer.get_image())
程序运行后会在 temp_dir/vis_data 文件夹下生成对应的图片和 Tensorboard 文件。
得益于可视化器的接口统一,你也可以轻松快速 地 扩展出你想要的可视化后端,后面我们将结合具体场景详细说明可视化器的各类用法。
Dataset 输出可视化
Dataset 输出可视化可以快速验证 dataset 和 pipeline 输出是否正确,可谓是一大神器。同时参考 MMClassfication 提供的对每个 pipeline 进行可视化的亮点功能,社区用户也在 MMYOLO 中进行了支持。功能脚本位于 https://github.com/open-mmlab/mmyolo/blob/main/tools/analysis_tools/browse_dataset.py
下面结合 YOLOv5 配置进行详细说明。首先 MMYOLO 中默认的可视化配置为:
vis_backends = [dict(type='LocalVisBackend')]
visualizer = dict(
type='mmdet.DetLocalVisualizer', # 使用 mmdet 的可视化器
vis_backends=vis_backends,
name='visualizer')
其使用了 MMDetection 中的 DetLocalVisualizer 可视化器,并且将结果保存到本地(默认不开启)。
注:本小节所用图片都来自 MS COCO2017 Val 数据集。
1 可视化 Dataset 输出
1.1 可视化 Dataset 输出结果
最常用的功能如下:
cd mmyolo
python tools/analysis_tools/browse_dataset.py configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py
其会每隔 3 秒在本地窗口显示一张图片和对应数据增强后的标注:

为了方便使用,该脚本还提供了: --out-dir (将结果保存到本地);--show-number (仅仅显示前 n 张图片)等功能。
1.2 可视化 pipeline 输出结果
python tools/analysis_tools/browse_dataset.py configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py --mode pipeline
结果如下所示:

其会显示每个 pipeline 运行后的效果图,也会显示当前图片的 shape 等信息。后续我们也会不断新增新功能。
2 可视化绘制结果保存到 WandB
MMEngine 已经支持了常用的 Tensorboard 和 WandB 后端,目前也在不断地新增其他后端。想切换为 WandB 后端,只需要修改配置即可,打开 configs/_base_/default_runtime.py,将 vis_backends 换掉即可:
vis_backends = [dict(type='WandbVisBackend')]
visualizer = dict(
type='mmdet.DetLocalVisualizer',
vis_backends=vis_backends,
name='visualizer',
save_dir='result') # 因为这个脚本没有用到 runner,因此必须要指定保存路径
运行命令为:
python tools/analysis_tools/browse_dataset.py configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py -- not -show
会在本地路径 result/vis_data/wandb 下生成 WandB 数据,在浏览器中打开对应地址就可以查看保存的数据。

其他后端也是一样的使用方式,非常便捷。
模型测试中的可视化
模型测试是通过 test.py 实现。
为了方便演示,我首先利用 extract_subcoco.py 脚本将完整的 coco 数据集切分为小数据集,读者也可以这样做快速验证功能。
注:本小节所用图片都来自 MS COCO2017 Val 数据集。
下面以 5 个不同需求来演示测试中的可视化实现方式。
1 GT 和预测分开可视化
想可视化预测结果,只需要指定 --show 即可,典型示例如下:
cd mmyolo
python tools/test.py configs/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth --show

上图左侧为 GT,右侧为预测结果。你也可以指定 --show-dir 将预测结果保存到本地。
2 GT 和预测叠加可视化
MMDetection 中可视化器默认情况下是左右图显示。为何不采用叠加到同一张图显示模式? 原因是存在 mask 或者其他更密集信息情况下叠加显示效果比较糟糕,在仅仅只有 bbox 标注情况下可能看不出来。
那么如何支持叠加显示?不好意思,在不改代码情况下暂时没有支持,为了能够实现这个需求,下面提供一种改代码的实现方式:
- 打开 mmdet/visualization/local_visualizer.py
- 在 https://github.com/open-mmlab/mmdetection/blob/3.x/mmdet/visualization/local_visualizer.py#L362 前面新增如下代码:
image = gt_img_data
- 在 https://github.com/open-mmlab/mmdetection/blob/3.x/mmdet/visualization/local_visualizer.py#L379 前面新增如下代码:
gt_img_data = None
就可以了。不过为了更好地区分预测框和 GT 框,我们最好需要改一下显示颜色
- 在 https://github.com/open-mmlab/mmdetection/blob/3.x/mmdet/visualization/local_visualizer.py#L133 前面新增如下代码:
if 'scores' in instances:
colors = (255, 0, 0) # 预测框红色
else:
colors = (0, 255, 0) # 标注框绿色
效果如下所示:

3 可视化绘制结果保存到 Tensorboard
用户只需要修改配置即可,打开 configs/_base_/default_runtime.py,将 vis_backends 换掉,同时还需要修改 default_hooks 参数。
vis_backends = [dict(type='TensorboardVisBackend')]
visualizer = dict(
type='mmdet.DetLocalVisualizer',
vis_backends=vis_backends,
name='visualizer' # 不需要指定保存路径
)
default_hooks = dict(
visualization= dict(type='mmdet.DetVisualizationHook',
interval=1, # 保存间隔改成 1,每张图片都保存
draw= True) # 重要!开启绘制和保存功能,默认不开启
)
python tools/test.py configs/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth
会在 work_dirs/yolov5_s-v61_syncbn_fast_8xb16-300e_coco/时间戳/vis_data 路径下生成 tf 文件,浏览器启动方式为:
tensorboard --logdir work_dirs
效果如下:

4 可视化 NMS 前后结果并将结果保存到 Tensorboard
为了验证可视化器支持在代码任意位置进行可视化,我 们 采用 YOLOv5 算法进行测试,并可视化 NMS 前后的效果,并且将对比图保存到 Tensorboard 中。
首先配置文件和第 3 小节一样修改即可,然后在 https://github.com/open-mmlab/mmyolo/blob/main/mmyolo/models/dense_heads/yolov5_head.py#L413 处修改为调用两次_bbox_post_process,其中一次为 nms 前,一次为 nms 后即可。将原先的:
results = self._bbox_post_process(
results=results,
cfg=cfg,
rescale=False,
with_nms=with_nms,
img_meta=img_meta)
替换为如下代码即可:
import mmcv
import numpy as np
from mmengine.visualization import Visualizer
from mmdet.structures import DetDataSample
# 获取可视化器
det_visualizer = Visualizer.get_current_instance()
# 获取原图
img = mmcv.imread(img_meta['img_path'])
img = mmcv.imconvert(img, 'bgr', 'rgb')
# 构建DataSample
pred_data_sample = DetDataSample()
# nms 前结果
results_pre_nms = self._bbox_post_process(
results=copy.deepcopy(results),
cfg=cfg,
rescale=False,
with_nms=False,
img_meta=img_meta)
pred_data_sample.pred_instances = results_pre_nms
# 绘制
det_visualizer.add_datasample(
'nms_or_not',
img,
draw_gt=False,
data_sample=pred_data_sample,
show=False,
wait_time=0,
pred_score_thr=0.3,
out_file=None)
# 获取 nms 前绘制结果
img_pre_nms = det_visualizer.get_image()
# nms 后结果
results = self._bbox_post_process(
results=results,
cfg=cfg,
rescale=False,
with_nms=with_nms,
img_meta=img_meta)
pred_data_sample.pred_instances = results
# 绘制
det_visualizer.add_datasample(
'nms_or_not',
img,
draw_gt=False,
data_sample=pred_data_sample,
show=False,
wait_time=0,
pred_score_thr=0.3,
out_file=None)
# 获取 nms 后绘制结果
img_post_nms = det_visualizer.get_image()
# 左右图显示
drawn_img = np.concatenate((img_pre_nms, img_post_nms), axis=1)
# 保存到后端
det_visualizer.add_image('pre_and_post_nms_results', drawn_img, step=self._step)
self._step += 1
注意: self._step = 0 需要在 ****YOLOv5Head 中初始化下。
会在 work_dirs/yolov5_s-v61_syncbn_fast_8xb16-300e_coco/时间戳/vis_data 路径下生成 tensorboard 文件,浏览器启动方式为:
tensorboard --logdir work_dirs
效果如下:

5 可视化注意力模块并用 WandB 保存为表格格式
注意力模块添加后是否有效的一个简单检测办法就是可视化注意力前后特征图变化。本小节采用 RTMDet 的骨干网络中通道注意力模块来作为演示案例。
为了突出可视化器的自定义功能,在绘制后采用 WandB 特有的表格存储格式进行说明。
在 MMYOLO 中 RTMDet backbone 的 stage 1 至 stage 4,一共 4 个 stage 的 CSPLayer 中嵌入了通道注意力,如下所示:
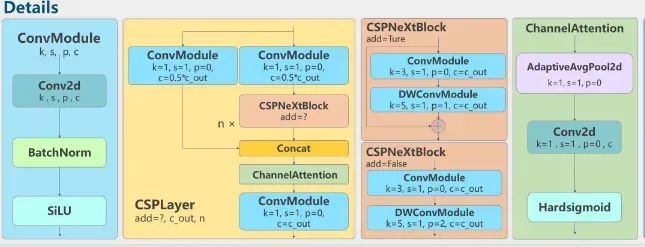
完整结构图见:https://github.com/open-mmlab/mmyolo/blob/main/docs/zh_cn/algorithm_descriptions/rtmdet_description.md
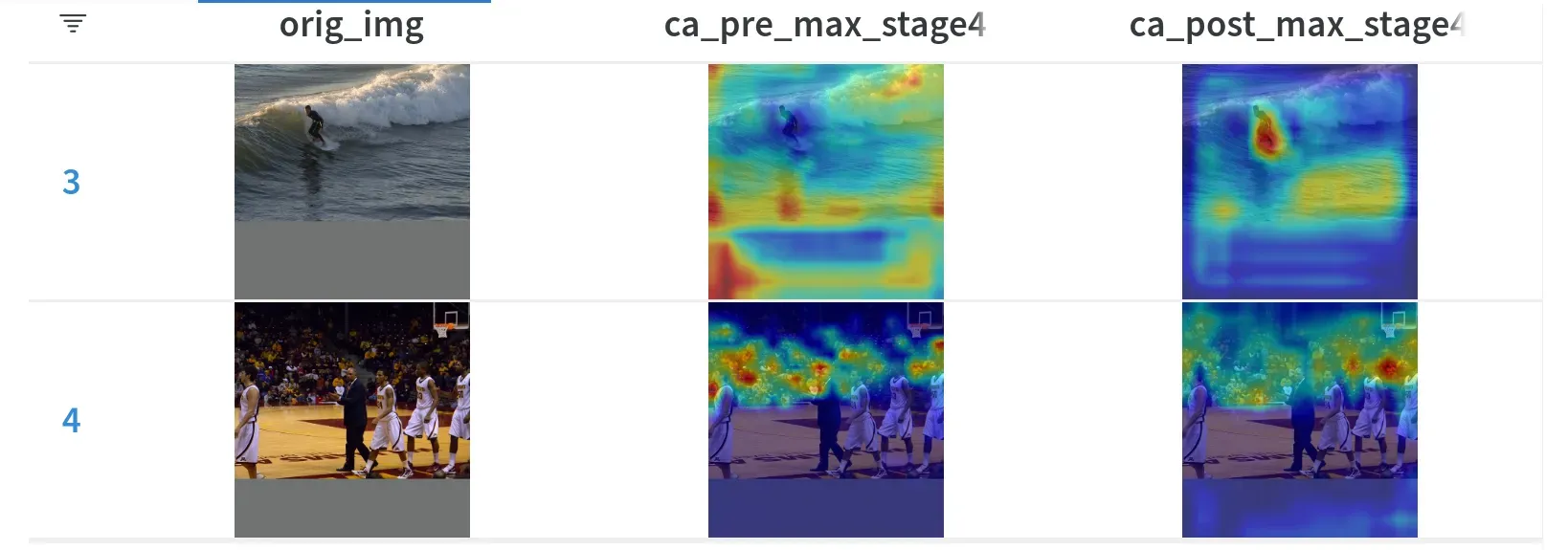
本文以 RTMDet-s 模型为例,对每个 stage 中嵌入的通道注意力计算前后的特征图进行可视化,验证注意力机制是否生效。最终效果如下所示:

以其中一种图片细节为例,stage 4 通道注意力运算前:

stage 4 通道注意力运算后:

总结来说:
- 一共 9 列,第 1 列显示原图,第 2~9 列分别是 4 个 stage 通道注意力运算前后的特征图
- 输出的每个特征图都是采用 MMEngine 中的
draw_featmap函数绘制,并采用了select_max通道压缩模式,你也可以换成其他显示模式 - 为了更容易对齐,采用原图叠加特征图显示模式
- 采用 WandB 特有的表格组织格式显示
下面是详细修改步骤。
(1) 修改 configs/base/default_runtime.py
将可视化后端修改为 WandB
vis_backends = [dict(type='WandbVisBackend')]
(2) 保存原图和 stage 信息
为了得到原图,需要修改 mmyolo/models/backbones/base_backbone.py 中的 forward 函数为如下:
def forward(self, x: torch.Tensor) -> tuple:
from mmengine import MessageHub
import numpy as np
message_hub = MessageHub.get_current_instance()
# 得到原图,并还原为归一化前的原图
orig_img = x[0].permute(1, 2, 0).cpu().numpy()
# 这里是 hard code
mean = np.array([103.53, 116.28, 123.675]).reshape((1, 1, 3))
std = np.array([57.375, 57.12, 58.395]).reshape((1, 1, 3))
orig_img = orig_img * std + mean
# bgr->rgb
orig_img = orig_img[..., ::-1].astype(np.uint8)
# 暂时保存起来
message_hub.update_info( 'orig_img' , orig_img)
outs = []
for i, layer_name in enumerate(self.layers):
layer = getattr(self, layer_name)
# stage 信息后面需要用到
message_hub.update_info('stage', i)
x = layer(x)
if i in self.out_indices:
outs.append(x)
return tuple(outs)
(3) 绘制注意力前后特征图
修改 mmdet/models/layers/csp_layer.py 中的 CSPLayer 的 forward 函数:
def forward(self, x: Tensor) -> Tensor:
x_short = self.short_conv(x)
x_main = self.main_conv(x)
x_main = self.blocks(x_main)
x_final = torch.cat((x_main, x_short), dim=1)
if self.channel_attention:
# 新增代码
from mmengine.visualization import Visualizer
from mmengine import MessageHub
message_hub = MessageHub.get_current_instance()
det_visualizer = Visualizer.get_current_instance()
data = []
# 绘制通道注意力前特征图并保存到 data
orig_img = message_hub.get_info('orig_img')
drawn_img = det_visualizer.draw_featmap(x_final[0], orig_img, channel_reduction='select_max')
data.append(drawn_img)
x_final = self.attention(x_final)
# 绘制通道注意力后特征图并保存到 data
drawn_img = det_visualizer.draw_featmap(x_final[0], orig_img, channel_reduction='select_max')
data.append(drawn_img)
# 将数据存储起来,在 hook 中获取并存储
message_hub.update_info('ca_attn'+str(message_hub.get_info('stage')), data)
return self.final_conv(x_final)
(4) 在 DetVisualizationHook 中处理并保存到 WandB
修改 mmdet/engine/hooks/visualization_hook.py 中的 after_test_iter 方法:
def after_test_iter(self, runner: Runner, batch_idx: int, data_batch: dict,
outputs: Sequence[DetDataSample]) -> None:
from mmengine import MessageHub
message_hub = MessageHub.get_current_instance()
# 获取原图
ca_attns = [message_hub.get_info('orig_img')]
# 获取 8 个特征图
for i in range(1, 5):
ca_attn = message_hub.get_info('ca_attn' + str(i))
ca_attns.extend(ca_attn)
# 获取 wandb 后端对象
wandb = self._visualizer.get_backend('WandbVisBackend').experiment
# 设置为 wandb 的 image 格式
for i, ca_attn in enumerate(ca_attns):
ca_attns[i] = wandb.Image(ca_attn)
self.ca_atten.append(ca_attns)
# 以下代码都不动
if self.draw is False:
return
由于 WandB 特点,还需要在程序运行完成后,将数据序列化并上传到 WandB:
def after_run(self, runner) -> None:
det_visualizer = Visualizer.get_current_instance()
# 获取后端
wandb = det_visualizer.get_backend('WandbVisBackend').experiment
columns = ['orig_img']
for i in range(1, 5):
columns.extend(['ca_pre_max_stage' + str(i), 'ca_post_max_stage' + str(i)])
# 保存为表格
wandb.log({'featmap': wandb.Table(columns=columns, data=self.ca_atten)})
可视化器的使用非常灵活,当目前接口无法满足你的需求时候,你可以通过 get_backend 直接获取到特定的后端,然后直接调用后端特定方法就行。这样就实现了在提供通用接口基础上还有无限扩展功能。
我们选择几张图片看一下注意力效果,看起来还是很有效的。

总结
本文以几个小例子演示了 MMEngine 的可视化器和可视化后端功能,并重点对 MMYOLO 中常用的测试过程可视化进行了详细的案例说明,从中可以看出可视化器具备灵活和便捷使用的特点。
MMYOLO 官方地址: https://github.com/open-mmlab/mmyolo
MMEngine 官方地址: https://github.com/open-mmlab/mmengine
欢迎大家体验,如果对你有帮助,就点个 star 吧~ 期待你的反馈!
文章出处登录后可见!