一、训练集、验证集与测试集
训练集(60%):用来训练模型
验证集(20%):确保模型没有过拟合,验证模型在新数据上的表现,同时通过调整参数,让模型处于最好的状态(验证集非必需,如无需调整超参数,则直接用测试集来评估效果)
主要作用:
- 评估模型效果,为了调整超参数而服务
- 调整超参数,使得模型在验证集上的效果最好
测试集(20%):用来评估模型效果
所有的评估指标都是围绕二元分类混淆矩阵的四种情况来计算的
混淆矩阵:在分类任务下,预测结果(Predicted Condition)与正确标记(True Condition)之间存在四种不同的组合,构成混淆矩阵(适用于多分类)
- 每一行代表了预测类别,每一行的总数表示预测为该类别的数据的数目
- 每一列代表了数据的真实归属类别,每一列的数据总数表示该类别的数据实例的数目
| 实际:1 | 实际:0 | |
| 预测:1 | TP | FP |
| 预测:0 | FN | TN |
TP(True Positive):真阳性,实际为1,且判断为1(正确)
FP(False Positive):假阳性,实际为0,但判断为1(错误)
FN(False Negative):假阴性,实际为1,但判断为0(错误)
TN(True Negative):真阴性,实际为0,且判断为0(正确)
二、分类问题评估指标
- 准确率(accuracy):预测正确的结果占总样本的百分比,准确率 =(TP+TN)/(TP+TN+FP+FN)
- 精确率(precision,差准率):所有被预测为正的样本中实际为正的样本的概率,精准率 =TP/(TP+FP)
- 召回率(recall,查全率):实际为正的样本中被预测为正样本的概率,召回率=TP/(TP+FN)
- F1分数(f1-score):综合精确率和召回率表现的平衡点,反映模型的稳健性,F1=(2×精确率×召回率)/(精确率+召回率),或
- ROC曲线:又称接受者操作特征曲线,最早应用于雷达信号检测领域,用于区分信号与噪声。后来人们将其用于评价模型的预测能力,ROC 曲线是基于混淆矩阵得出的,其主要的两个指标是真正率和假正率
- 真正率(TPR) = 灵敏度=召回率 = TP/(TP+FN),即所有实际类别为1的样本中,预测类别为1的比例
- 假正率(FPR) = 1- 特异度 = FP/(FP+TN),即所有实际类别为0的样本中,预测类别为1的比例
- ROC曲线的横轴就是FPRate,纵轴就是TPRate,当二者相等时,表示的意义则是:对于不论真实类别是1还是0的样本,分类器预测为1的概率是相等的,此时AUC为0.5,如下
-
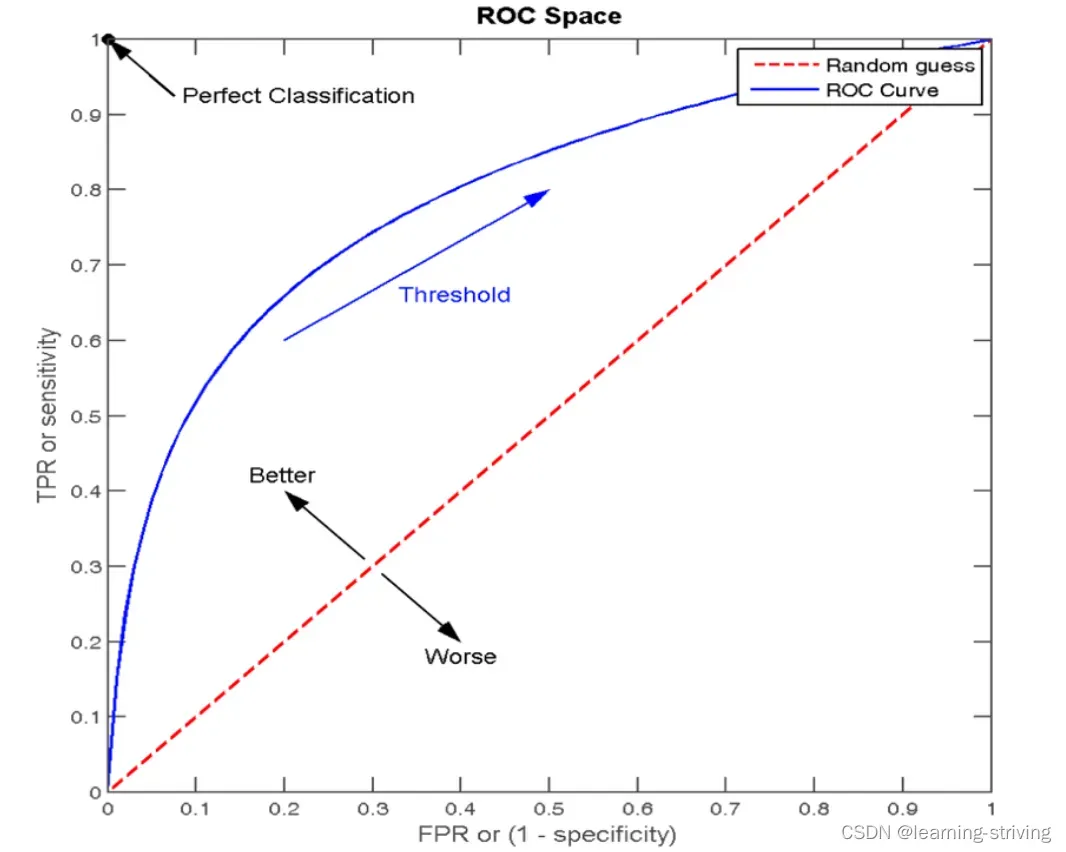
- AUC:又称曲线下面积,连接对角线,它的面积正好是 0.5,ROC 曲线越陡越好,所以理想值就是 1,一个正方形,而最差的随机判断都有 0.5,所以一般 AUC 的值是介于 0.5 到 1 之间的,AUC的概率意义是随机取一对正负样本,正样本得分大于负样本的概率,AUC只能用来评价二分类,非常适合评价样本不平衡中的分类器性能
-
AUC 的一般判断标准:
0.5 – 0.7: 效果较低,但用于预测股票已经很不错了
0.7 – 0.85: 效果一般
0.85 – 0.95: 效果很好
0.95 – 1: 效果非常好,但一般不太可能
三、回归问题评估指标
- MAE(平均绝对误差):是最简单的回归度量。它将每个实际值和预测值的差值相加,最后除以观察次数,是目标值和预测值之间的绝对差
- MSE(均方误差):MSE取每个实际值和预测值之间的差值,然后将差值平方并将它们相加,最后除以观测数量,它是实际值和预测值之间的平方差
- RMSE(均方根误差):RMSE取每个实际值和预测值之间的差值,然后将差值平方并将它们相加,最后除以观测数量。然后取结果的平方根,即RMSE 是 MSE 的平方根
- MSLE(均值平方对数误差):计算平方对数误差或损失的期望
- MAPE(平均绝对百分比误差):MAPE是计算对相对误差损失的预期。所谓相对误差,就是绝对误差和真值的百分比
MSE 会惩罚大错误,而 MAE 不会,随着 MSE 和 MAE 的值都降低,模型趋向于一条更好的拟合线
四、数据集划分方式:交叉验证法
- 留出法:按照固定比例将数据集静态的划分为训练集、验证集、测试集
- 留一法:每次的测试集都只有一个样本,要进行 m 次训练和预测。 这个方法用于训练的数据只比整体数据集少了一个样本,因此最接近原始样本的分布
- k 折交叉验证:一种动态验证的方式,这种方式可以降低数据划分带来的影响,具体步骤如下:
- 将数据集分为训练集和测试集,将测试集放在一边
- 将训练集分为 k 份
- 每次使用 k 份中的 1 份作为验证集,其他全部作为训练集
- 通过 k 次训练后,我们得到了 k 个不同的模型
- 评估 k 个模型的效果,从中挑选效果最好的超参数
- 使用最优的超参数,然后将 k 份数据全部作为训练集重新训练模型,得到最终模型
五、分类评估报告api
- sklearn.metrics.classification_report(y_true, y_pred, labels=[], target_names=None )
- y_true:真实目标值
- y_pred:估计器预测目标值
- labels:指定类别对应的数字
- target_names:目标类别名称
- return:每个类别精确率与召回率
续接案例:逻辑回归、激活函数sigmoid、损失及优化、案例代码实现_learning-striving的博客-CSDN博客
新增代码
from sklearn.metrics import classification_report
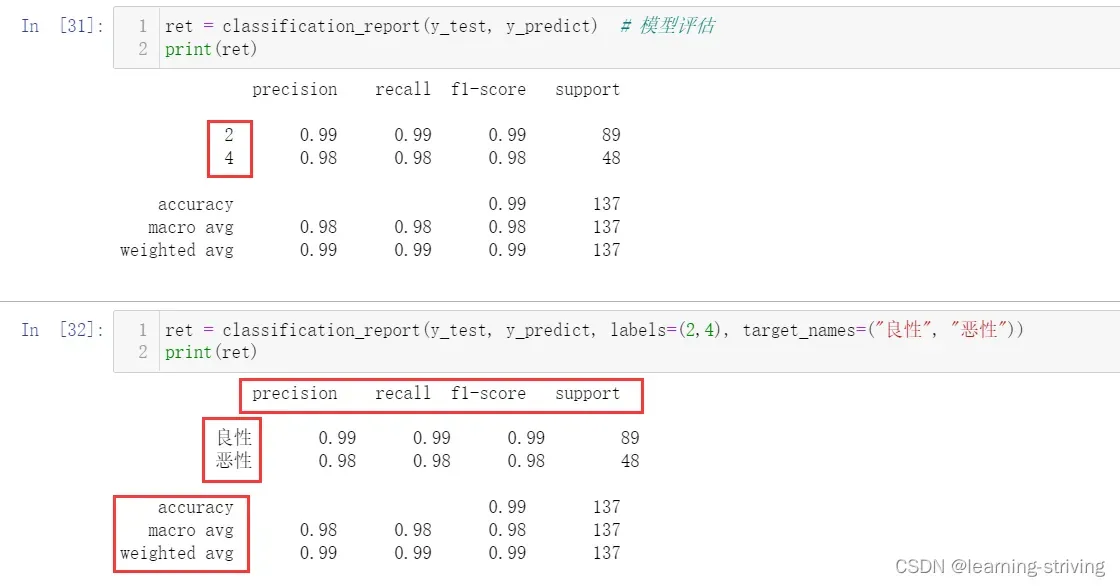
ret = classification_report(y_test, y_predict) # 模型评估
print(ret)
ret = classification_report(y_test, y_predict, labels=(2,4), target_names=("良性", "恶性"))
print(ret)- precision、recall、f1-score与accuracy前面已有介绍
- macro avg:宏平均,计算方式为每个类型的算术平均,我们以precision的macro avg为例,上述输出结果中precision的macro avg值的计算方式为:(0.99+0.98)/2
- weighted avg:加权平均,是用每个类型样本数量与对应权重相乘再除以所有类别的样本总数,以precision的weighted avg 计算方式为:(0.99×89+0.98×48)/(89+48),即(0.99×89+0.98×48)/137
- support:y_test中属于该分类的数量
六、AUC计算API
- from sklearn.metrics import roc_auc_score
- sklearn.metrics.roc_auc_score(y_true, y_score):计算ROC曲线面积,即AUC值
- y_score:预测得分,可以是正类的估计概率、置信值或者分类器方法的返回值
- y_true:每个样本的真实类别,必须为0(反例),1(正例)标记
from sklearn.metrics import roc_auc_score
# 0.5~1之间,越接近于1约好
y_test = np.where(y_test > 2.5, 1, 0)
print("AUC指标:",)
roc_auc_score(y_true=y_test, y_score=y_predict)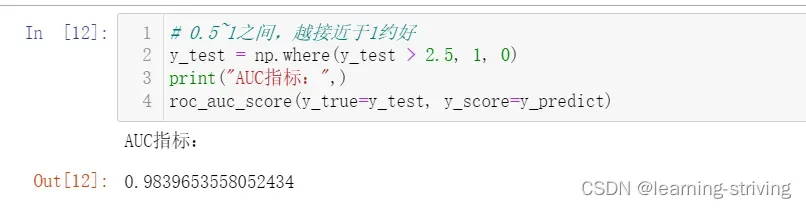
学习导航:http://xqnav.top/
文章出处登录后可见!
已经登录?立即刷新