一、OCR概念及发展
OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,经过检测暗、亮的模式肯定其形状,而后用字符识别方法将形状翻译成计算机文字的过程;即,针对印刷体字符,采用光学的方式将纸质文档中的文字转换成为黑白点阵的图像文件,并经过识别软件将图像中的文字转换成文本格式,供文字处理软件进一步编辑加工的技术。如何除错或利用辅助信息提升识别正确率,是OCR最重要的课题,ICR(Intelligent Character Recognition)的名词也随之产生。
简单来说,OCR识别就是光学文字识别,是指通过图像处理和模式识别技术对光学的字符进行识别。**它是计算机视觉研究领域的分支之一,是计算机科学的重要组成部分。衡量一个OCR系统性能好坏的主要指标有:拒识率、误识率、识别速度、用户界面的友好性,产品的稳定性,易用性及可行性等。
二、OCR发展

OCR的概念是在1929年由德国科学家Tausheck最早提出来的,后来美国科学家Handel也提出了利用技术对文字进行识别的想法。而最先对印刷体汉字识别进行研究的是IBM公司的Casey和Nagy,1966年他们发表了第一篇关于汉字识别的文章,采用了模板匹配法识别了1000个印刷体汉字。
早在60、70年代,世界各国就开始有OCR的研究,而研究的初期,多以文字的识别方法研究为主,且识别的文字仅为0至9的数字。以一样拥有方块文字的日本为例,1960年左右开始研究OCR的基本识别理论,初期以数字为对象,直至1965至1970年之间开始有一些简单的产品,如印刷文字的邮政编码识别系统,识别邮件上的邮政编码,帮助邮局做区域分信的做业;也所以至今邮政编码一直是各国所倡导的地址书写方式。
20世纪70年代初,日本的学者开始研究汉字识别,并作了大量的工做。中国在OCR技术方面的研究工做起步较晚,在70年代才开始对数字、英文字母及符号的识别进行研究,70年代末开始进行汉字识别的研究,到1986年,我国提出“863”高新科技研究计划,汉字识别的研究进入一个实质性的阶段,清华大学的丁晓青教授和中科院分别开发研究,相继推出了中文OCR产品,现为中国最领先汉字OCR技术。早期的OCR软件,因为识别率及产品化等多方面的因素,未能达到实际要求。同时,因为硬件设备成本高,运行速度慢,也没有达到实用的程度。只有个别部门,如信息部门、新闻出版单位等使用OCR软件。进入20世纪90年代之后,随着平台式扫描仪的普遍应用,以及我国信息自动化和办公自动化的普及,大大推进了OCR技术的进一步发展,使OCR的识别正确率、识别速度知足了广大用户的要求。
三、OCR的应用场景
根据OCR的应用场景而言,我们可以大致分成识别特定场景下的专用OCR以及识别多种场景下的通用OCR。就前者而言,证件识别以及车牌识别就是专用OCR的典型案例。针对特定场景进行设计、优化以达到最好的特定场景下的效果展示。那通用的OCR就是使用在更多、更复杂的场景下,拥有比较好的泛性。在这个过程中由于场景的不确定性,比如:图片背景极其丰富、亮度不均衡、光照不均衡、残缺遮挡、文字扭曲、字体多样等等问题,会带来极大的挑战。
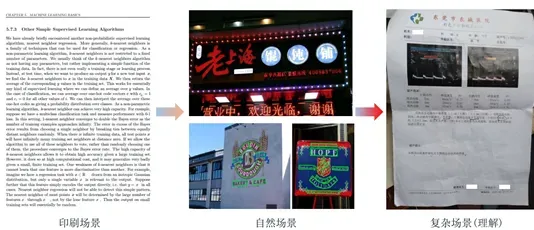
文件文本识别:可对图书馆、报刊、博物馆、档案馆等的纸质图书、报纸、杂志、历史文献档案等进行电子化管理,实现文件的准确保存。
自然场景文字识别:识别自然场景图像中的文字信息,如车牌、广告词、路牌等信息。识别车辆可实现停车场收费管理、交通流量控制指标测量、车辆定位、防盗、高速公路超速自动监管等功能。
票据文本识别:可对增值税发票、报销单、火车票等不同格式的票据进行文本识别,避免财务人员手动输入大量票据信息。现已广泛应用于财务管理、银行、金融等诸多领域。 .
证件识别:可快速识别身份证、银行卡、驾照等卡类信息,将证件文本信息直接转换为可编辑文本,可大大提高工作效率,降低人工成本,实时进行身份验证相关人员。 , 用于安全管理。
四、OCR的技术路线
典型的OCR技术路线如下图所示:
其中OCR识别的关键路径在于文字检测和文本识别部分,这也是深度学习技术可以充分发挥功效的地方。
(1)常用传统的OCR技术:
1、水平投影垂直投影
2、模板匹配
3、查找轮廓findcontours
(2)常用的文字检测框架:
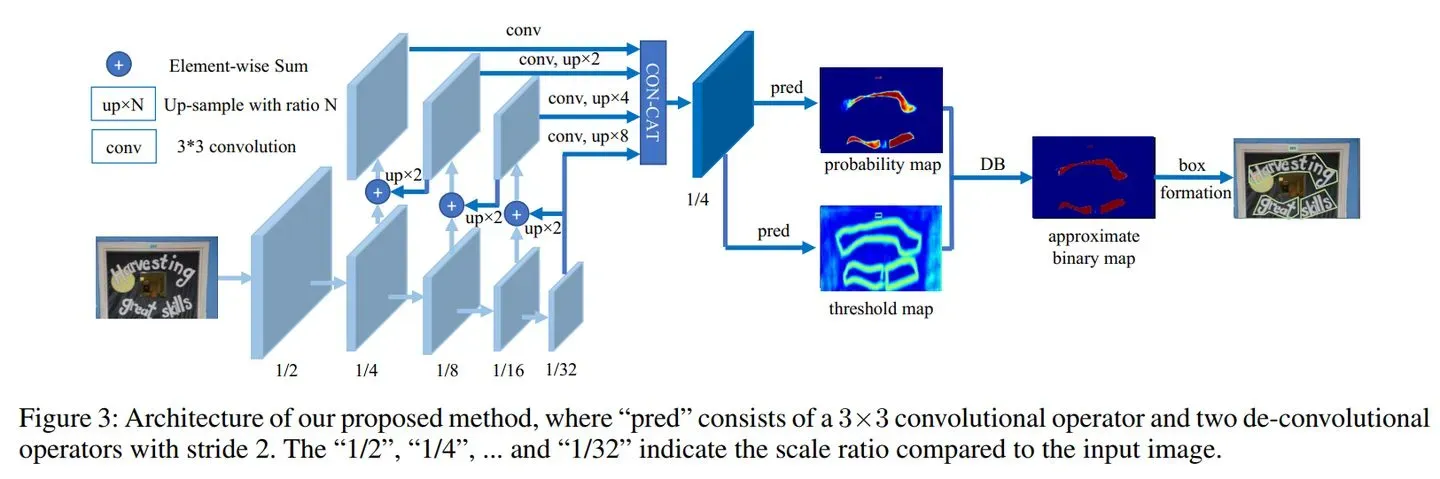
1、DBNet
首先,DB是一种基于分割的文本检测算法。在各种文本检测算法中,基于分割的检测算法可以更好地处理弯曲等不规则形状文本,因此往往能取得更好的检测效果。但分割法后处理步骤中将分割结果转化为检测框的流程复杂,耗时严重。因此作者提出一个可微的二值化模块(Differentiable
Binarization,简称DB),将二值化阈值加入训练中学习,可以获得更准确的检测边界,从而简化后处理流程。DB算法最终在5个数据集上达到了state-of-art的效果和性能。
参考论文:Real-time Scene Text Detection with Differentiable
Binarization
学习参考:https://zhuanlan.zhihu.com/p/94677957
2、CTPN
CTPN模型主要包括三个部分,分别是卷积层、Bi-LSTM层、全连接层,其结构如下图所示。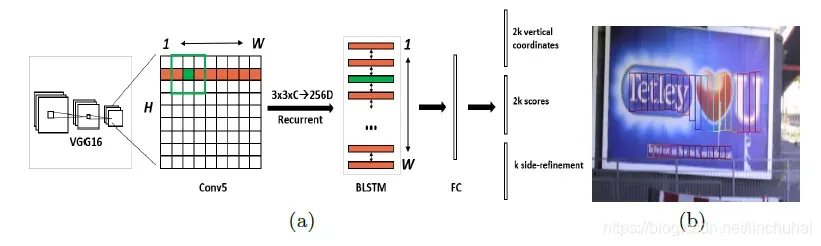
- 在卷积层部分,CTPN选取VGG16模型前5个conv5= stage得到feature maps作为图像最后的特征,假设此时feature maps的尺寸为 W *
H
* C;- 由于文本之间存在序列关系,因此,作者引入了递归神经网络,采用的是一层Bi-LSTM层,作者发现引入了递归神经网络对文本检测的效果有一个很大的提升,如下图所示,第一行是不采用递归神经网络的效果,第二行是采用了Bi-LSTM后的效果。具体的做法是采用一个的滑动窗口,提取feature
maps上每个点周围的区域作为该点的特征向量表示,此时,图像的尺度变为,然后将每一行作为序列的长度,高度作为batch_size,传入一个128维的Bi-LSTM,得到Bi-LSTM层的输出为;- 将Bi-LSTM的输出接入全连接层,在这一部分,作者引入了anchor的机制,即对每一个点用k个anchor进行预测,每个anchor就是一个盒子,其高度由[273,390,…,11]逐渐递减,每次除以0.7,总共有10个。作者采用的是三个全连接层分支。
学习参考:https://blog.csdn.net/linchuhai/article/details/84191406

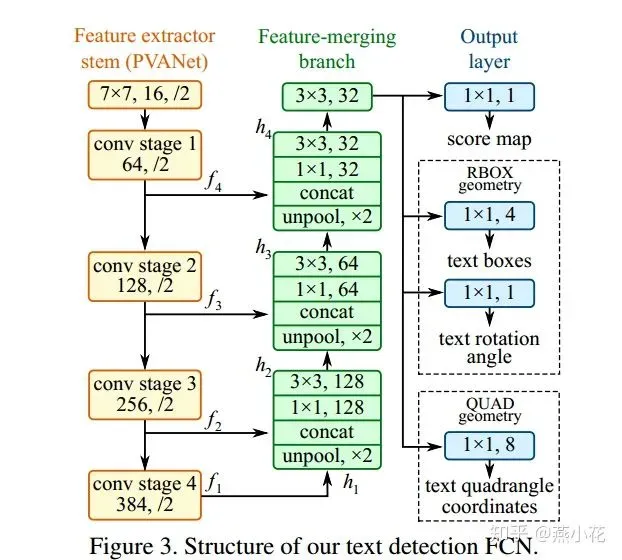
3、EAST
论文的思想非常简单,结合了DenseBox和Unet网络中的特性,具体流程如下:
- 先用一个通用的网络(论文中采用的是Pvanet,实际在使用的时候可以采用VGG16,Resnet等)作为base net ,用于特征提取
- 基于上述主干特征提取网络,抽取不同level的feature map,它们的尺寸分别是 W
H
C,这样可以得到不同尺度的特征图.目的是解决文本行尺度变换剧烈的问题,ealy stage可用于预测小的文本行,late-stage可用于预测大的文本行.- 特征合并层,将抽取的特征进行merge.这里合并的规则采用了U-net的方法,合并规则:从特征提取网络的顶部特征按照相应的规则向下进行合并,这里描述可能不太好理解,具体参见下述的网络结构图
- 网络输出层,包含文本得分和文本形状.根据不同文本形状(可分为RBOX和QUAD),输出也各不相同,具体参看网络结构图
学习参考:
https://blog.csdn.net/u010848594/article/details/105347154/
https://blog.csdn.net/u010848594/article/details/105347154/
(3)常用的文字识别框架:
- CRNN+CTC
- CRNN+Attention
CRNN网络架构: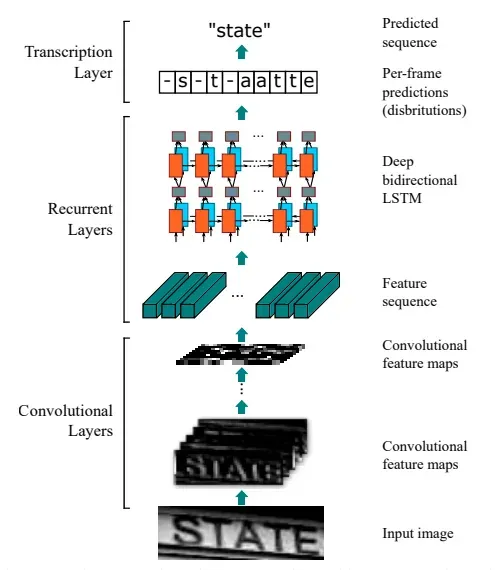
CRNN网络结构包含三部分,从下到上依次为:
1.卷积层,使用深度CNN,对输入图像提取特征。
2.循环层,使用双向RNN(BLSTM)对特征序列进预测,输出预测标签(真实值)分布。
3.转录层,使用 CTC 损失,把从循环层获取的一系列
标签分布被转化为最终的标签序列。
五、OCR文字识别方法发展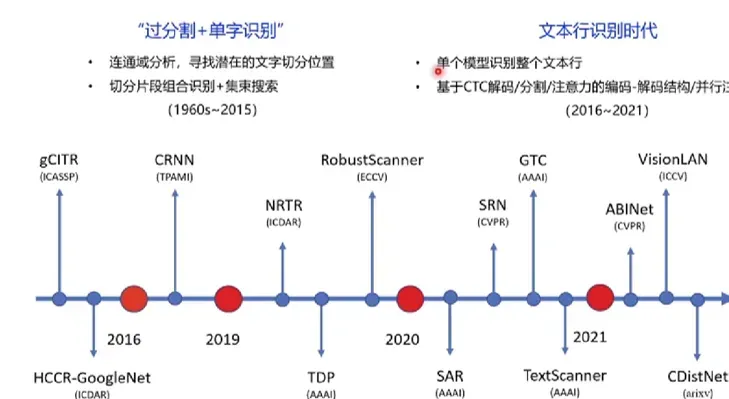
以上文字检测和文字识别部分将在后续文章中详细介绍,待更新!
六、OCR常用的数据集
在这个代码仓库里,提供了常用的OCR检测和识别中的通用公开数据集的下载链接。并且提供了json标签转成.txt标签的代码和转换好的.txt标签。
该项目的详细github地址如下:https://github.com/zcswdt/OCR_ICDAR_label_revise
数据集介绍
| 数据集 | 数据介绍 | 标注格式 | 下载地址 |
|---|---|---|---|
| ICDAR_2013 | 语言: 英文 train:229 test:233 | x1 y1 x2 y2 text | 下载链接1 . |
| ICDAR_2015 | 语言: 英文 train:1000 test:500 | x1,y1,x2,y2,x3,y3,x4,y4,text | 下载链接2 . |
| ICDAR2017-MLT | 语言: 混合 train:7200 test:1800 | x1,y1,x2,y2,x3,y3,x4,y4,text | 下载链接3 . 提取码: z9ey |
| ICDAR2017-RCTW | 语言: 混合 train:8034 test:4229 | x1,y1,x2,y2,x3,y3,x4,y4,<识别难易程度>,text | 下载链接4 |
| 天池比赛2018 | 语言: 混合 train:10000 test:10000 | x1,y1,x2,y2,x3,y3,x4,y4,text | 检测5 。 识别6 |
| ICDAR2019-MLT | 语言: 混合 train:10000 test:10000 | x1,y1,x2,y2,x3,y3,x4,y4,语言类别,text | 下载链接7 . 提取码: xofo |
| ICDAR2019-LSVT | 语言: 混合 train:30000 test:20000 | json格式标签 | 下载链接8 |
| ICDAR2019-ReCTS | 语言: 混合 train:20000 test:5000 | json格式标签 | 下载链接9 |
| ICDAR2019-ArT | 语言: 混合 train:5603 test:4563 | json格式标签 | 下载链接10 |
| Synth800k | 语言: 英文 80k | 基于字符标注 | 下载链接11 |
| 360万中文数据集 | 语言: 中文 360k | 每张图片由10个字符构成 | 下载链接12 . 提取码:lu7m |
| 中文街景数据集CTW | 语言:中文 32285 | 基于字符标注的中文街景图片 | 下载链接13 |
| 百度中文场景文字识别 | 语言: 混合 29万 | 下载链接14 |
数据集介绍参考:https://blog.csdn.net/jhsignal/article/details/107930105
常见的OCR识别平台:
- 使用谷歌开源OCR引擎– Tesseract
- 使用百度、阿里等开放平台– PaddleOCR
- 基于深度学习的CNN字符识别框架–后续文章继续详细介绍
文章出处登录后可见!