图嵌入方法学习(一)
(一)什么是图嵌入
- 图,如社交网络、词共存网络和通信网络,广泛存在于各种现实世界的应用中。通过他们的分析,我们可以洞察社会结构、语言和不同的交流方式,因此图一直是学术研究的热门话题。
- 真实的图(网络)往往是高维、难以处理的,20世纪初,研究人员发明了图形嵌入算法,图嵌入(Graph Embedding,也叫Network-
Embedding)是一种将图数据(通常为高维稠密的矩阵)映射为低微稠密向量的过程,能够很好地解决图数据难以高效输入机器学习算法的问题。 - 图嵌入是将属性图转换为向量或向量集。嵌入应该捕获图的拓扑结构、顶点到顶点的关系以及关于图、子图和顶点的其他相关信息。
(二)图嵌入方法
在介绍图嵌入之前,我们有必要了解Word2vec,这是理解图嵌入的基础。
1.Word2vec
- Word2vec,是一群用来产生词向量的相关模型。
- 假如我们有一系列样本(x,y),这里 x 是词语,y 是它们的词性,我们要构建 f(x)->y 的映射,但这里的数学模型f(比如神经网络、SVM)只接受数值型输入,但是 NLP里的词语,是人类发明的语言(比如中文、英文、拉丁文等等),机器读不懂,所以需要把他们转换成数值形式,或者说——嵌入到一个数学空间里,这种嵌入方式,就叫词嵌入(word-embedding)。
- 大部分的有监督机器学习模型,都可以归结为: f(x)->y
- 在 NLP 中,如果把 x 看做一个句子里的一个词语,y 是这个词语的上下文词语,那么这里的 f,便是 NLP中经常出现的『语言模型』(language -model),这个模型的目的,就是判断 (x,y)这个样本,是否符合自然语言的法则,更通俗点说就是:词语x和词语y放在一起,是不是人话。
- Word2vec 正是来源于这个思想,但它的最终目的,不是要把 f训练得多么完美,而是只关心模型训练完后的副产物——模型参数(这里特指神经网络的权重),并将这些参数,作为输入 x的某种向量化的表示,这个向量便叫做——词向量。
举例,如何用 Word2vec 寻找相似词:
- 对于一句话:『她们 夸 吴彦祖 帅 到 没朋友』,如果输入 x 是『吴彦祖』,那么 y 可以是『她们』、『夸』、『帅』、『没朋友』这些词
- 现有另一句话:『她们 夸 我 帅 到 没朋友』,如果输入 x 是『我』,那么不难发现,这里的上下文 y 跟上面一句话一样
- 从而 f(吴彦祖) = f(我) = y,所以大数据告诉我们:我 = 吴彦祖(完美的结论)
Skip-gram 和 CBOW 模型
- 如果是用一个词语作为输入,来预测它周围的上下文,那这个模型叫做『Skip-gram 模型』

- 而如果是拿一个词语的上下文作为输入,来预测这个词语本身,则是 『CBOW 模型』

Word2vec模型的学习方法
1.1 CBOW模型
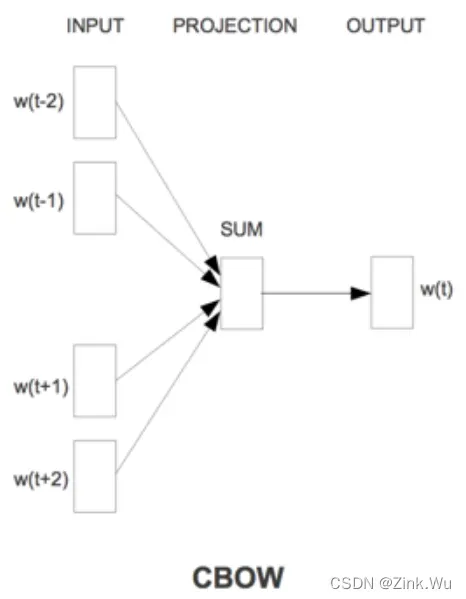
该模型主要根据上下文预测当前单词
根据上图,我们也将这个网络结构分为三层进行描述:
- 输入层:文本中自己设定的窗口中包含的词向量,这个词向量是one-hot表示的(即对于每个输入的词,其表示方式是one-hot),
- 投影层:可以理解为隐藏层,直接对输入向量进行累加求和(先进行线性变换,再求和)
- 输出层:输出层对应一个二叉树,它是以文本中出现过的词当做叶子结点,以各词出现的次数当做权值,来构建Huffman树,我们最终的w(t)实际也是一个one-hot表示,对于CBOW模型,它是一个中心值。
最终的稠密向量是如何得到的? —-> 没有别的,就是隐藏层的权重! !
那么使用Huffman树有什么好处呢?
首先,由于是二叉树,之前计算量为O(n),现在变成了O(log(n))。第二,由于使用霍夫曼树是高频的词靠近树根,这样高频词需要更少的时间会被找到。
1.2 Skip-Gram模型
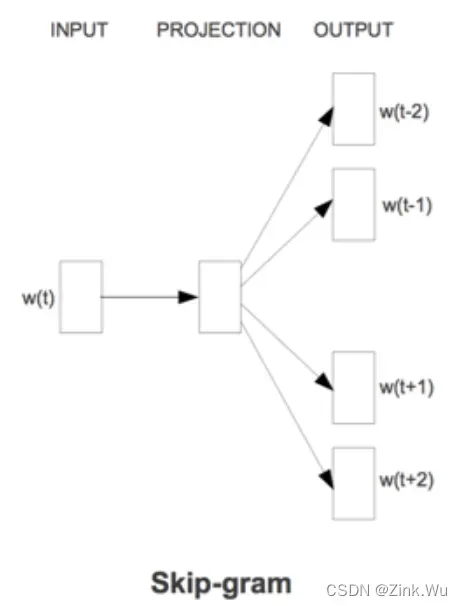
- Skip-Gram模型和CBOW的思路是反着来的,即输入是特定的一个词的词向量,输出层是一个softmax回归分类器,它的每个结点将会输出一个0-1之间的值(概率),这些所有输出层神经元结点的概率之和为1。
- 我们的输入是特定词,输出是softmax概率排前n的n个词,对应的Skip-Gram神经网络模型输入层有1个神经元,输出层有词汇表大小个神经元。隐藏层的神经元个数我们可以自己指定。
- Skip-gram模型的本质是计算输入word的input vector与目标word的output
vector之间的余弦相似度,并进行softmax归一化。
同样,我们最终需要的是经过训练的权重矩阵。
1.3 Hierarchical Softmax
其实模型的输出也可以也可以是softmax,但是对于类别较多时,softmax会对所有的词进行排序,然后取最大值,这样来做是及其耗时的,为了提升效率,我们采用了层次softmax来解决我们的问题,将复杂度有O(n)降为O(log(n))。
由于我们把之前所有要从输出softmax层的单词概率都变成了一颗二叉霍夫曼树,那么我们的softmax概率计算只需要沿着树形结构进行就可以了。如下图所示,我们可以沿着霍夫曼树从根节点一直走到我们的叶子节点的词w2。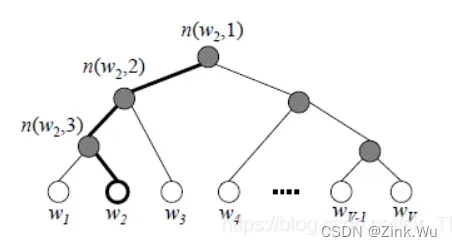
在word2vec中,我们采用了逻辑回归的方法:即规定沿着左子树走,那么就是负类(霍夫曼树编码1),沿着右子树走,那么就是正类(霍夫曼树编码0)。
层次softmax的缺点:
使用霍夫曼树来代替传统的神经网络,可以提高模型训练的效率。但是如果我们的训练样本里的中心词w是一个很生僻的词,那么就得在霍夫曼树中辛苦的向下走很久了。
1.4 negative sampling
负采样的基本思想是字典中出现频率高的词更容易被采样,不常见的词更不容易被采样,这就是加权采样的问题。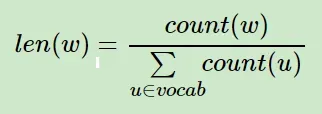
在word2vec中,分子和分母都取了3/4次幂如下: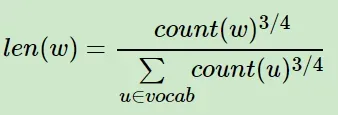
基本的思路就是对于长度为1的线段,根据词语的词频将其公平地分配给每个词语:
- 这样线段就被每个词平分了。然后我们将这段长度为1的线段划分成M等份,这里M>V,V表示词典中词的数量,接下来生成一个0-1之间的随机数,看落在那个那个等分的词线段中,就取出该词作为负样本即可。
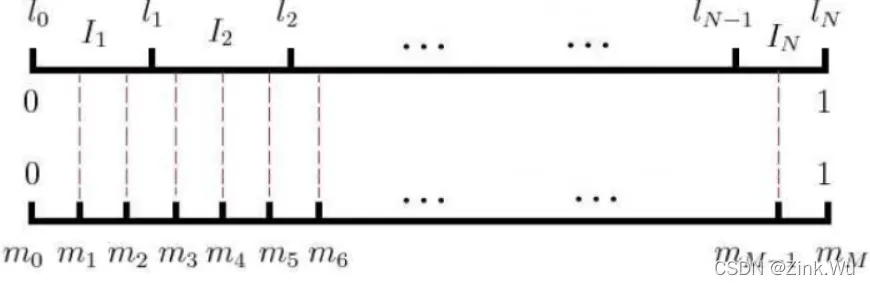
普遍认为Hierarchical Softmax对低频词效果较好;Negative Sampling对高频词效果较好,向量维度较低时效果更好。
https://zhuanlan.zhihu.com/p/26306795
https://easyai.tech/ai-definition/word2vec/
https://blog.csdn.net/sir_TI/article/details/89199084
文章出处登录后可见!