
Word2vec
参考:
①Word2vec知其然知其所以然或者花书实战篇
②知乎-word2vec
③B站视频-word2vec
④Efficient Estimation of Word Representations in Vector Space
⑤Distributed Representations of Words and Phrases and their Compositionality
⑥word2vec Parameter Learning Explained
word2vec概念
Word2vec是一个将语料库中输入文本信息转换为向量格式的包,又名词嵌入。Word2vec由谷歌在2013年推出,其可以将每个词(Word)转换为向量(Vector)。
Note:
- 语料库相当于一本书。书中的句子、词、词很多,但是一个特定的语料库不可能包含所有的句子、词和词。
- 例如,“Thursday today”是语料库中的一个句子,“today”和“Thursday”是词。
词向量发展史

Note:
- One-hot独热向量:对于每个词都用[0, 0, …1, 0, 0]表示,每个词向量只有1个非零值1,其余均为0,这样的表示方法虽简单,但是当语料库很大的时候,one-hot会导致维度灾难。更难定的一点是,one-hot格式的词向量无法衡量词与词之间的关系,比如相似的两个词。
- SVD奇异值分解:SVD类似于特征分解。其中心思想是利用SVD来减小词向量维度。
SVD是个效率并不高的算法,在实际实现过程中,尤其是待分解矩阵比较大的时候,出结果的速度是很慢的,因此并不实用。 - 技术水平总是往上走的,词向量发展至今的结果就是Word2vec。Word2vec最大的好处在于它可以衡量两个向量之间的距离,比如相似的两个单词所对应的向量距离也很小。
语言模型
语言模型是计算句子是句子的概率的模型。
Note:
- 比如说,今天是星期四—-概率=90%;今天星期八—-概率=0.1%;今天四星期—-概率=0.001%。高的概率值往往需要满足语法正确以及语义符合。
怎么形容呢? — 通过条件概率将句子分解到单词的层次。
例如,一个句子由
个词
组成,那么语言模型可以描述为:
Note:
- 其中,
,连续的2个词的概率:
,故
- 在式(1)中,每个概率
都可以看成是一个分类任务。比如对于
来说,
相当于label标签,
相当于input输入。
But 这样是有问题的!
因为语料再大也不可能包罗万象,因此某个词可能不在语料中,但却是可观存在的,那么计算过程中,就会有,这样的话就会导致式(1)为0,这样显然是不对的。
如何解决?
加入平滑操作就是给那些没有出现过的词或词组一个相对较小的概率。
拉普拉斯平滑(加1平滑):每个词在原来的次数基础上加1次。
But 这样还是有问题的!
因为假设语料库中一共有个词,那么上述语言模型中的每个条件概率
都是需要训练的参数,即一个句子的参数可能达到
。
如何解决?
使用K阶层马尔科夫假设(RL是是使用一阶马尔科夫假设,即2-gram)。越大,则模型精度越高,但是参数空间也就越大。
K具体有以下几种取法:
例如:
语言模型评价指标:困惑度:
给定一个真实的句子:
Word2vec模型
如今比较著名的Word2vec模型就是CBOW和Skip-Gram模型,为了篇幅,我将此这篇Word2vec的论文笔记放在下面:CBOW&Skip-Gram。Word2vec的2个模型由于计算复杂度较高,在后续的发展中,出现了层次Softmax以及负采样的方式进行优化,为了篇幅,我将此文章的论文笔记放在下面:Word2Vec进阶。
Seq2Seq
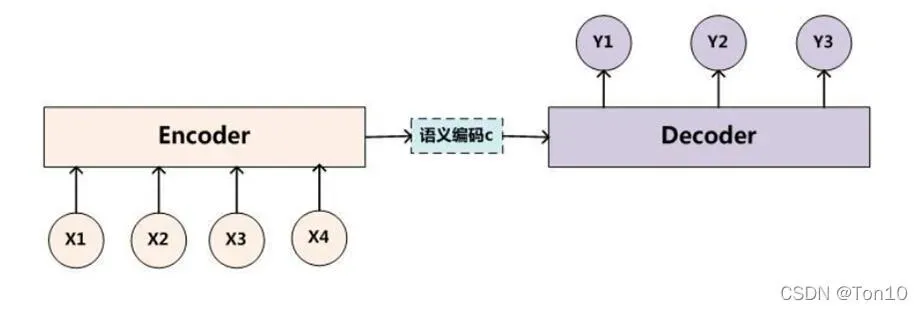
Seq2Seq,又称Encoder-Decoder结构,一般是一种基于RNN结构的将不定长的输入系列转换为不定长的输出序列的模型。
具体请看我的另一篇NLP之Seq2Seq。
Transformer
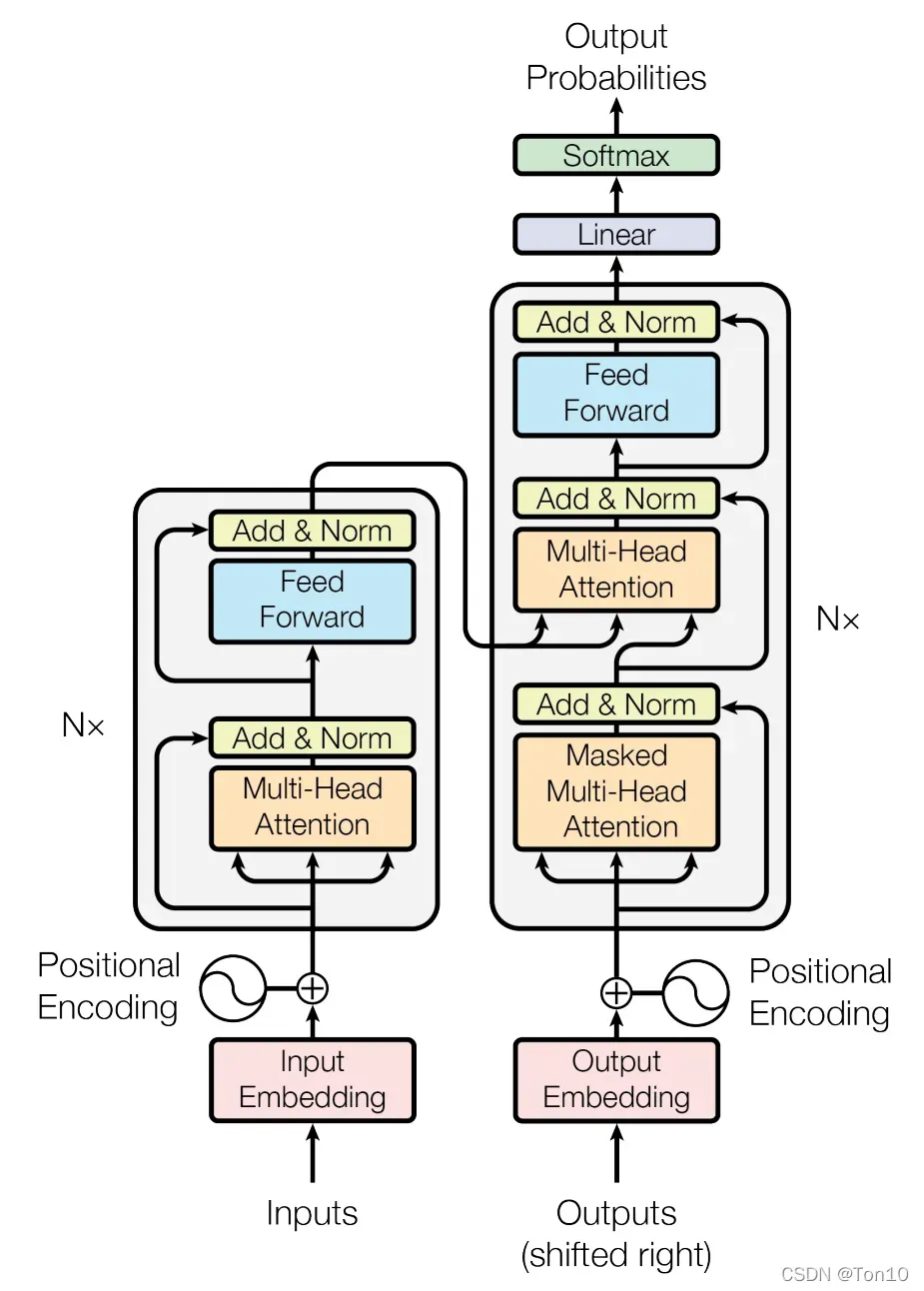
Transformer模型是目前GPT、BERT这种大规模预训练模型的基础,他抛弃了传统CNN和RNN结构的神经网络,采用将注意力模块堆积的方式形成的一种模型。
具体请看我的另一篇Transformer。
版权声明:本文为博主Ton10原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/MR_kdcon/article/details/123113542