前言
FATE是微众银行开发的联邦学习平台,是全球首个工业级的联邦学习开源框架,在github上拥有近4000stars,可谓是相当有名气的,该平台为联邦学习提供了完整的生态和社区支持,为联邦学习初学者提供了很好的环境,否则利用python从零开发,那将会是一件非常痛苦的事情。本篇博客内容涉及《联邦学习实战》第十五章内容,使用的fate版本为1.6.0,fate的安装已经在这篇博客中介绍,有需要的朋友可以点击查阅。本章内容主要涉及联邦学习在训练过程中所遇到的网络安全问题,联邦学习因其设备间的独立性、数据间的异构性、数据分布的不平衡和安全隐私设计等特点,更容易受到对抗攻击的影响。与集中式的模型训练相比,FL场景防御更为困难。
1. 后门攻击
1.1 问题定义
攻击者意图使模型对具有一定特征的数据做出错误判断,但模型不会影响主要任务。本节讨论横向联邦学习场景下的后门攻击行为,如下图所示:
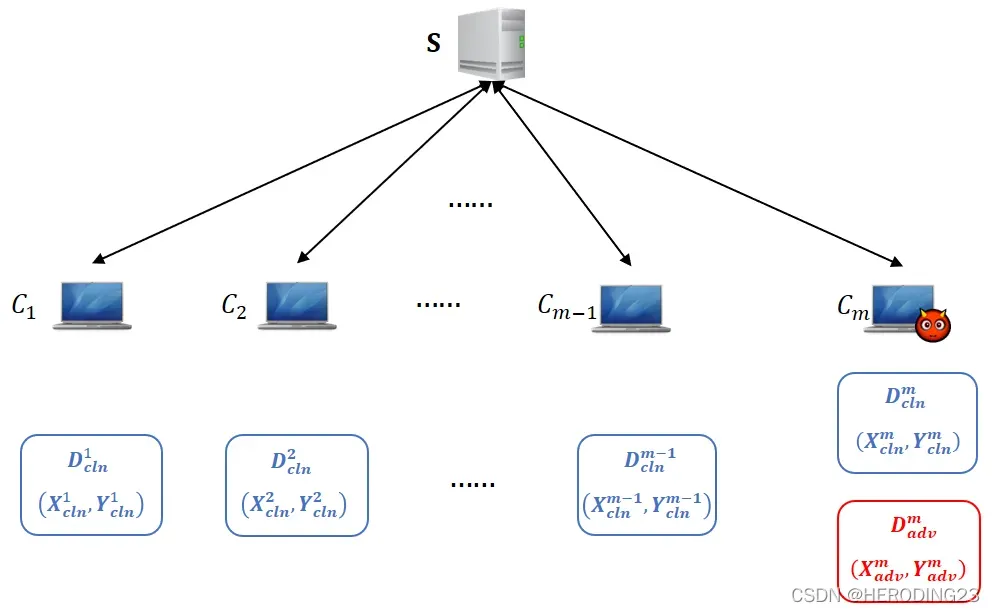
在上图展示的场景中有m个客户端,记为,假设有客户端
被攻击者挟持,即我们通常所说的恶意客户端,其他客户端都正常,所有客户端都包含本地数据
。对于恶意客户端
,除了包含正常数据
,还包含被嵌入后门的篡改数据集
。
例如,一辆具有明显红色特征的汽车,攻击者打算将红色汽车标记为鸟。攻击者首先会通过劫持用户的客户端标签将红色汽车标记为鸟,然后让模型重新开始训练。这样训练出来的最终模型在推断时会判断红色汽车是鸟,但不会影响其他图片的判断。
后门攻击的策略有很多种,这里介绍文献How To Backdoor Federated Learning提出的模型替换攻击策略,该策略在多个公开的数据集中都取得了不错的攻击效果。
1.2 后门攻击策略
对于带有后门攻击的联邦学习,其客户端可以分为恶意客户端和正常客户端。不同类型的客户有不同的本地培训策略。正常的客户培训策略如下:
对于恶意客户端的本地训练,它与普通客户端的区别在于两个方面:损失函数的设计和模型权重在服务器端的上传。
首先分析损失函数的设计。恶意客户端在训练时,一方面保证模型训练在中毒数据集和正常数据集上都能取得良好的效果。另一方面,它必须确保当前训练的局部模型不会与全局模型有太大的偏差。具体来说,它的损失函数主要由以下两部分组成。
- 类别丢失:恶意客户端既有正常数据集
,也有篡改和中毒数据集
。因此,训练的目标是一方面保证主任务的性能不下降,另一方面保证模型在中毒数据中出错。判断。我们将这部分损失值称为类别损失
,其计算公式如下:
- 距离损失:在How To Backdoor Federated Learning中,如果仅用上式的损失还书对恶意客户端进行训练,那么服务器可以通过观察模型距离等异常检测的方法,判断上传的客户端模型是否为异常模型,如计算两个模型之间的欧氏距离。为此我们修改异常客户端的损失函数,在上式基础上添加当前模型与全局模型的距离损失。我们将两个模型的距离定义为它们对应参数的欧氏距离。修改后的损失函数定义为:
综上所述,恶意客户端的目标是一方面保证模型在正常数据集和中毒数据集上表现良好,另一方面保证局部训练与全局模型的距离尽可能小.
接下来,我们分析恶意客户端模型的权重。如上所述,在联邦学习场景中很难进行后门攻击。原因之一是在模型聚合操作过程中,恶意客户端模型的影响将在平均后基本消除。此外,由于服务器的选择机制,我们无法保证每一轮都能选择被劫持的客户端,进一步降低了后门攻击的风险。
为了有效解决这个问题,先来回顾传统的联邦学习聚合过程。假设当前在进行第t轮的模型聚合,表示第t轮后的全局模型,
表示第t+1轮后客户端
的最新本地模型。此时可以列出模型聚合公式:
对于被毒化的客户端,其最理想的模型是X,在理想情况下,我们期望聚合后的结果就是模型X,也就是等价于只有恶意参与方参与,这样上式就可以改写成:
其中对于普通客户端,当模型接近收敛时,方程:
已确立的。因此,我们可以重新修改上述公式,使恶意客户端提交的本地模型
满足:
将上式代入上式,我们得到:
上式表明,当恶意参与方上传模型是时,攻击成功率将有明显提升,观察可以发现,通常n值要远大于
,该式本质上通过增大异常客户端m的模型权重,使其在后面的聚合过程中,对全局模型的影响和贡献尽量持久。
恶意客户端算法如下所示:
1.3 详细实现
本节实现将复用第三章的代码框架,利用ResNet-18模型,对带有后门攻击、修改的cifar10数据集进行分类。代码可以在对应的github目录中找到。
首先,它模拟恶意客户端篡改数据,将具有特定特征的数据判断为特定类型。一般的方法是直接从数据集中挑选特定数据并更改其标签。本节采用另一种引入后门的方式,即通过在图像中植入特征来篡改数据。
import matplotlib.pyplot as plt
import torch, copy
import numpy as np
from torchvision import datasets, transforms
# 获取cifar数据集
def get_dataset(dir):
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
train_dataset = datasets.CIFAR10(dir, train=True, download=True,
transform=transform_train)
eval_dataset = datasets.CIFAR10(dir, train=False, transform=transform_test)
return train_dataset, eval_dataset
# 获取参与方id=0的数据集
dir = "./data/"
id = 0
train_dataset, eval_dataset = get_dataset(dir)
all_range = list(range(len(train_dataset)))
data_len = int(len(train_dataset) / 10)
train_indices = all_range[id * data_len: (id + 1) * data_len]
train_load = torch.utils.data.DataLoader(train_dataset, batch_size=32, sampler=torch.utils.data.sampler.SubsetRandomSampler(train_indices))
# 初始化标记的范围
pos = []
for i in range(2, 28):
pos.append([i, 3])
pos.append([i, 4])
pos.append([i, 5])
for batch_id, batch in enumerate(train_load):
images, target = batch
img = images[0].numpy()
new_img = copy.deepcopy(img)
img = np.transpose(img, (1,2,0))
for i in range(0, len(pos)):
new_img[0][pos[i][0]][pos[i][1]] = 1.0
new_img[1][pos[i][0]][pos[i][1]] = 0
new_img[2][pos[i][0]][pos[i][1]] = 0
new_img = np.transpose(new_img, (1,2,0))
plt.imshow(new_img)
结果如下图: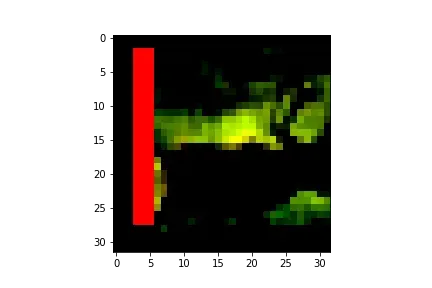
- 配置信息:模拟中毒样本数据后,需要在配置文件中添加必要的字段,帮助我们完成训练。
{
"model_name" : "resnet18", # 使用模型
"no_models" : 10, # 参与方个数
"type" : "cifar", # 数据集种类
"global_epochs" : 20, # 全局迭代次数
"local_epochs" : 3, # 本地迭代次数
"k" : 3, # 每次随机选取3个参与方
"batch_size" : 32, # 批大小
"lr" : 0.001, # 学习率
"momentum" : 0.0001, # momentum参数
"lambda" : 0.3, # 正则化参数
"eta" : 2, # 恶意客户端权重
"alpha" : 1.0, # class_loss 和 dist_loss 之间的权重比例
"poison_label" : 2, # 约定将被毒化的数据归为哪一类
"poisoning_per_batch" : 4 # 当恶意客户端在本地训练时,有多少数据是被篡改的
}
- 服务端:使用经典的FedAvg算法。事实上,针对后门攻击,有许多改进的算法如RFA,FoolsGold和FedProx等,具有更好的对抗后门攻击能力。
- 客户端:训练代码更改都在客户端。对于普通客户端,不需要更改代码,如第 3 章所述。在恶意客户端训练中,损失函数包括分类损失和距离损失。其中距离损失用于衡量两个同构模型之间的距离。为此,我们首先添加两个模型的距离函数,如下所示:
def model_norm(model_1, model_2):
squared_sum = 0
for name, layer in model_1.named_parameters():
squared_sum += torch.sum(torch.pow(layer.data - model_2.state_dict()[name].data, 2))
return math.sqrt(squared_sum)
在客户端的本地训练中,我们添加一个函数用于恶意客户端的训练。参考算法5给出如下代码实现,主要改动在损失函数的构建和返回值上。
def local_train_malicious(self, model):
for name, param in model.state_dict().items():
self.local_model.state_dict()[name].copy_(param.clone())
# 设置优化函数器
optimizer = torch.optim.SGD(self.local_model.parameters(), lr=self.conf['lr'],
momentum=self.conf['momentum'])
# 设置毒化数据样式
pos = []
for i in range(2, 28):
pos.append([i, 3])
pos.append([i, 4])
pos.append([i, 5])
self.local_model.train()
for e in range(self.conf["local_epochs"]):
for batch_id, batch in enumerate(self.train_loader):
data, target = batch
# 在线修改数据,模拟被攻击场景
for k in range(self.conf["poisoning_per_batch"]):
img = data[k].numpy()
for i in range(0,len(pos)):
img[0][pos[i][0]][pos[i][1]] = 1.0
img[1][pos[i][0]][pos[i][1]] = 0
img[2][pos[i][0]][pos[i][1]] = 0
if torch.cuda.is_available():
data = data.cuda()
target = target.cuda()
optimizer.zero_grad()
output = self.local_model(data)
# 类别损失和距离损失
class_loss = torch.nn.functional.cross_entropy(output, target)
dist_loss = models.model_norm(self.local_model, model)
# 总的损失函数
loss = self.conf["alpha"]*class_loss + (1-self.conf["alpha"])*dist_loss
loss.backward()
optimizer.step()
print("Epoch %d done." % e)
diff = dict()
# 计算返回值
for name, data in self.local_model.state_dict().items():
diff[name] = self.conf["eta"]*(data - model.state_dict()[name])+model.state_dict()[name]
return diff
训练准确率如下图所示: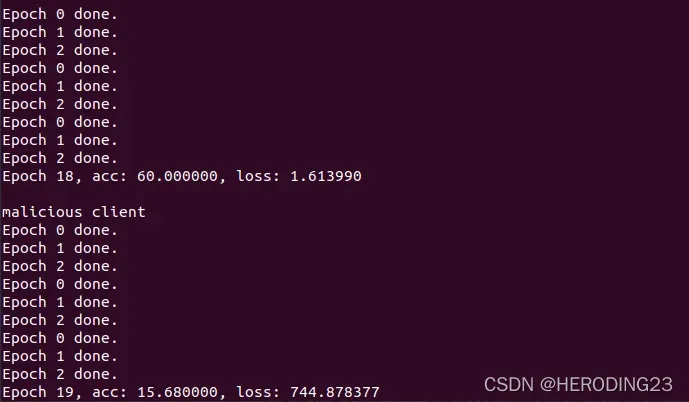
可以看到模型训练的效果并不理想,可以通过调参的方式提高模型准确度。注意在调整参数后,比如增加本地训练迭代轮次,增加每轮参与方个数,修改恶意方的权重等,在开始的全局训练中,输出的loss可能为nan,经过个人的分析,很可能是由于计算中出现了0结果导致了爆炸情况,但是这不影响经过几十轮的全局迭代后,训练准确度和loss恢复正常,因为首先cifar数据集本身就50000张数据,分发给各个参与方后没方只有几千张,然后本地训练的轮次又很少,这就导致前期聚合后的模型效果很不理想,但是随着全局模型性能的提高,本地训练的模型性能也随之提高,计算出的loss也变得有规律起来,所以后面轮次的结果会更加理想。
写到这里,我突然想到一个名词叫群体智慧,单一个体所做出的决策往往会比起多数决的决策来的不精准,群体智慧是一种共享的或者群体的智能,以及集结众人的意见进而转化为决策的一种过程。这个名词是我在看某站up主林亦LYi发布的五千人开一辆车的视频中了解的,那场面可谓相当震撼。五千多网友在线通过输入指令共同操作游戏中汽车的运行,在不排除高达数十秒的网络延迟的情况下,汽车由一开始的横冲直撞,无脑乱跑,到最后能够平稳的驰骋在大道上,并且还能躲避障碍物,这就是群体智慧的体现。无独有偶,联邦学习场景下的模型训练,其中根本的思想也即群体智慧,虽然参与方可能有因为数据集等问题出现模型性能不佳的情况,但是随着全局模型的迭代更新,模型会一步步朝着最优的方向提升,最终达到理想的效果。所以当一开始模型效果很差甚至出现nan的情况,别担心,参与方的群体智慧会指引模型向正确的方向提升的。
2. 差分隐私
差分隐私的初始应用场景主要包括数据库查询操作、数据挖掘、数据统计等。本节介绍差分隐私如何应用于联邦学习场景。
2.1 集中式差分隐私
差分隐私技术应用于集中训练,主要是通过添加噪声。
回顾差分隐私的定义,它建立在两个相邻数据集D和D’上,所谓相邻数据集,即使二者之间仅有一条数据不同,例如,二者满足:
差分隐私技术使得用户无法从获取的输出数据中区分数据是来源于D还是D‘,从而达到保护数据隐私的目的,这种隐私保护强调数据层面的保护。
在传统的梯度下降算法SGD中,定义了损失函数和优化器后,可以利用反向传播求解,过程如下:
for i, data in enumerate(train_datasets):
inputs, targets = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
DPSGD的迭代过程如下。在每轮迭代中,前面代码块部分基本一致,主要不同点在于梯度裁剪和添加高斯噪声。DPSGD修改损失函数的表示,然后按照损失函数进行求导,对每个样本的梯度进行裁剪,在聚合过程中添加高斯噪声,得到带有噪声的梯度,最后利用梯度下降更新模型参数。
for i, data in enumerate(train_datasets):
inputs, targets = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
# 初始化记录裁剪和添加噪声的容器
losses = torch.mean(loss.reshape(batch_size, -1), dim=1)
gradients = dict()
for tensor_name, tensor in model.named_parameters():
gradients[tensor_name] = torch.zeros_like(tensor)
for j in losses:
j.backward(retain_graph=True)
# 裁剪梯度,C为边界值,使得模型参数梯度在[-C,C]范围内
torch.nn.utils.clip_grad_norm_(model.parameters(), C)
# 存储裁剪后的梯度
for tensor_name, tensor in model.named_parameters()
gradients[tensor_name].add_(tensor.grad)
model.zero_grad()
for tensor_name, tensor in model.named_parameters():
# 初始化噪声
if torch.cuda.is_available():
noise = torch.cuda.FloatTensor(tensor.grad.shape).normal_(0, sigma)
else:
noise = torch.FloatTensor(tensor.grad.shape).normal_(0, sigma)
# 添加高斯噪声
gradients[tensor_name].add_(noise)
tensor.grad = gradients[tensor_name] / num_microbatches
optimizer.step()
DPSGD算法流程如下所示。
2.2 联邦差分隐私
与中心化差分隐私相比,联邦场景下的差分隐私技术不仅需要考虑数据层面的隐私安全,还要考虑用户层面的安全。
相邻数据集:设有两个数据集D和D‘,若它们之间有且仅有一条数据不一样,那我们就称D和D’为相邻数据集。
用户相邻数据集:设每个用户对应的本地数据集为
,D和D‘是两个用户数据的集合,我们定义D和D’为用户相邻数据集,当且仅当D去除或者添加某一个客户端
的本地数据集
后变为D’。
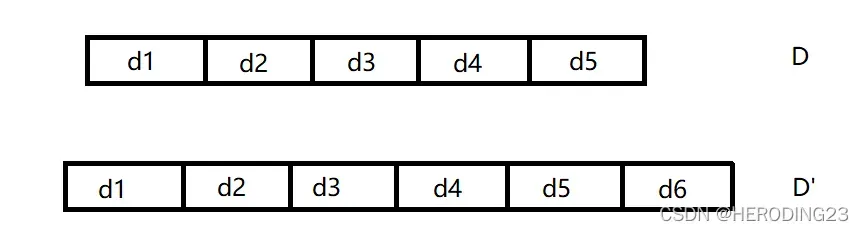
如上是相邻数据集的,D和D’只差一个元素d6。用户相邻数据集如下图所示,数据集D包含用户c1,c2,c3本地数据,而数据集D’包括用户c2,c3的数据,因此D和D’是用户相邻的。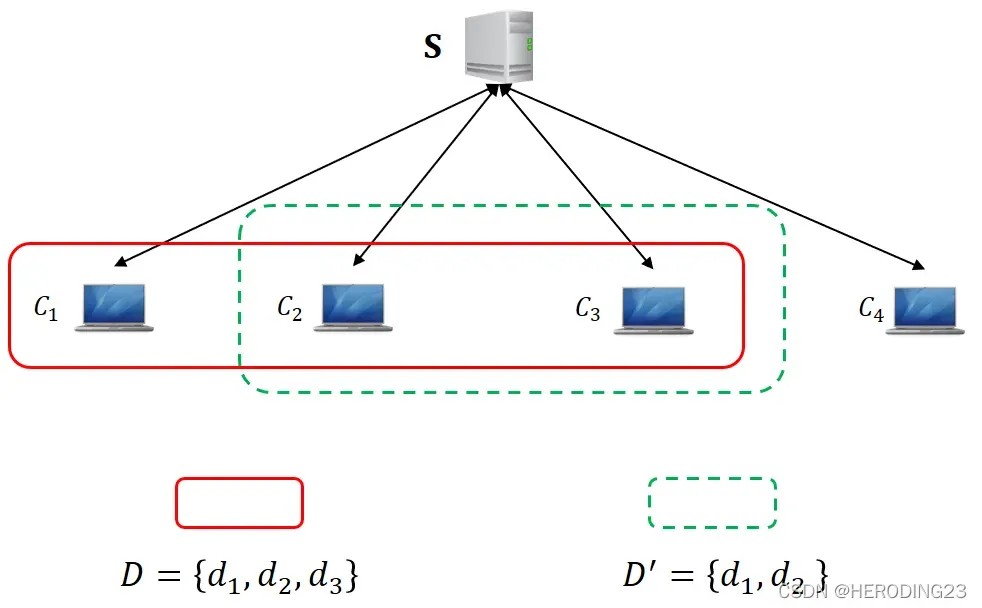
联邦差分隐私不仅需要每个客户端本地数据模型的隐私和安全,还需要客户端之间的信息安全,即当用户在服务器上接收到客户端的本地模型时,既不能推断出是哪个客户端上传的,也不能推断出是哪个客户端上传的。它。客户是否参加培训。
文献Learning Differentially Private Language Models Without Losing Accuracy介绍了一种DP-FedAvg的算法,它将联邦学习中经典的FedAvg算法和差分隐私训练相结合,并应用在语言模型上,取得不错的效果。DP-FedAvg的客户端本地训练算法如下所示:
与FedAvg客户端本地训练相比,DP-FedAvg需要在每一步本地迭代更新后,对参数进行裁剪。服务端侧算法如下面算法所示:
其主要工作包括以下几点:
- 随机选择一组客户参与培训
。
- 对于选定的客户端
,进行本地模型训练。
- 服务端接收每一个客户端k的模型参数
,执行聚合操作,得到
。
- 求高斯噪声分布的方差
,利用高斯分布
生成噪声数据。
- 将噪声数据添加到全局模型聚合操作中以获得新的全局模型参数
。
- 重复上述步骤直到收敛。
2.3 详细实现
本节给出DP-FedAvg的详细实现,复用第三章的代码框架,在其基础上加上差分隐私策略。在DP-FedAvg的实现中,需要求取两个相同结构的模型权重差值的范数,如下所示:
def model_norm(model_1, model_2):
squared_sum = 0
for name, layer in model_1.named_parameters():
squared_sum += torch.sum(torch.pow(layer.data - model_2.state_dict()[name].data, 2))
return math.sqrt(squared_sum)
配置信息如下:
{
"model_name" : "resnet18", # 使用模型
"no_models" : 10, # 参与方个数
"type" : "cifar", # 数据集种类
"global_epochs" : 100, # 全局迭代次数
"local_epochs" : 3, # 本地迭代次数
"k" : 2, # 每次随机选取2个参与方
"batch_size" : 32, # 批大小
"lr" : 0.01, # 学习率
"momentum" : 0.0001, # momentum参数
"lambda" : 0.5, # 正则化参数
"dp" : true, # 使用差分隐私
"C" : 1000, # 裁剪边界值
"sigma" : 0.001, # 差分隐私参数
"q" : 0.1, # 源码未用
"W" : 1 # 源码未用
}
客户端的修改主要在本地训练过程中进行,每轮迭代完成后,主要过程如下,参数更新后,参数的变化切,切系数是:
经过几轮本地训练,最终模型参数变化值上传到服务器。
if self.conf["dp"]:
model_norm = models.model_norm(model, self.local_model)
norm_scale = min(1, self.conf['C'] / (model_norm))
for name, layer in self.local_model.named_parameters():
clipped_difference = norm_scale * (layer.data - model.state_dict()[name])
layer.data.copy_(model.state_dict()[name] + clipped_difference)
服务端的修改主要是在聚合全局模型参数时加入噪声,噪声是由高斯分布产生的。高斯分布的参数包括均值和标准差,这里取为。其实为了方便,
的值可以直接在配置文件中设置。
def model_aggregate(self, weight_accumulator):
for name, data in self.global_model.state_dict().items():
update_per_layer = weight_accumulator[name] * self.conf["lambda"]
if self.conf['dp']:
sigma = self.conf['sigma']
if torch.cuda.is_available():
noise = torch.cuda.FloatTensor(update_per_layer.shape).normal_(0, sigma)
else:
noise = torch.FloatTensor(update_per_layer.shape).normal_(0, sigma)
update_per_layer.add_(noise)
if data.type() != update_per_layer.type():
data.add_(update_per_layer.to(torch.int64))
else:
data.add_(update_per_layer)
在baseline下,即单点训练的条件下,没有添加高斯噪声,训练的准确度为88%,如下图所示(PS:大概在20多轮的时候准确度就已经达到了87%,也就是说后面的训练并没有提高模型的性能,此时模型性能已经饱和):
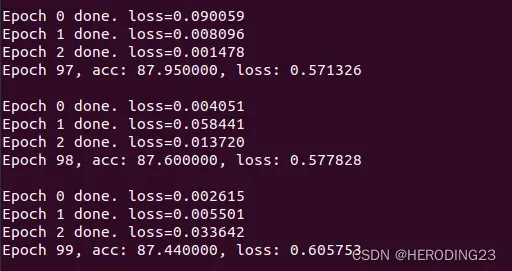
在上述配置文件超参数的设置下,经过100轮训练,得到的准确度能达到86%,如下图所示: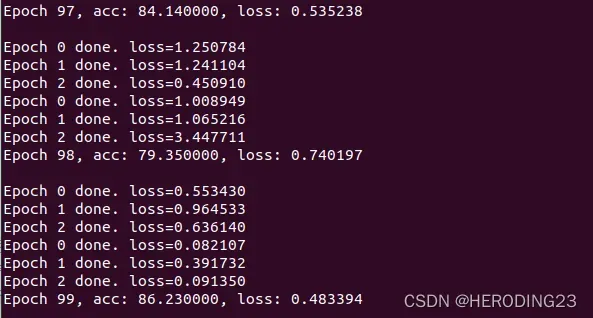
在同等条件下,设置DP=false,得到的准确度为85%,可见在梯度参数上添加少量的噪声,并不会影响训练的准确度,同时也保证了数据隐私。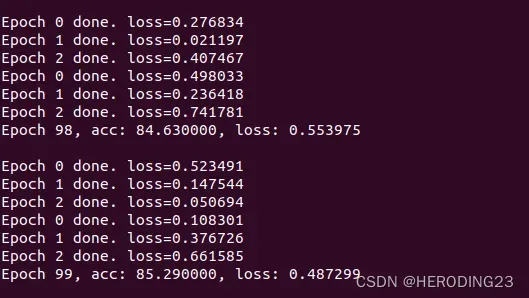
3. 模型压缩
模型压缩是深度学习领域的常用技术,主要是减小模型参数和大小,提高模型的训练和推理速度。在联邦学习场景下,压缩模型有以下好处:
- 减少模型参数传递量。联邦学习在训练过程中需要服务器和客户端传输大量的参数,所以网络的稳定性比较高。减少模型参数传输量可以减少对网络稳定性的依赖。
- 提高安全性。模型压缩导致非原始参数数据的传输,因此与差分隐私一样,即使恶意攻击者窃取了中间模型参数,也很难恢复它们。
3.1 参数稀疏化
稀疏化是一种常用的模型压缩技术。
稀疏化思想与差分隐私的噪声机制类似,但是稀疏化操作更直接。假设当前模型结构为,这里的
表示第i层。在第t轮中,客户端
的本地迭代训练中,模型将从
变为
。按照FedAvg的意思,客户端
将向服务端上传模型参数
。
稀疏化思想是在每个客户端中保存一份掩码矩阵。
是与
形状大小相同的参数矩阵,且只由0和1构成。客户端将模型参数
与
结合,上传
。
3.1.1 详细实现
首先在配置文件里添加“prop”,用来控制掩码矩阵中1的数量的。具体来说,prop越大,掩码矩阵中1的值越多,矩阵越稠密,相反,prop越小,1的值越少,矩阵越稀疏。
{
"model_name" : "resnet50", # 使用模型
"no_models" : 10, # 参与方个数
"type" : "cifar", # 数据集种类
"global_epochs" : 30, # 全局迭代次数
"local_epochs" : 3, # 本地迭代次数
"k" : 2, # 每次随机选取2个参与方
"batch_size" : 32, # 批大小
"lr" : 0.01, # 学习率
"momentum" : 0.01, # momentum参数
"lambda" : 0.5, # 正则化参数
"prop" : 0.6 # 控制掩码矩阵1的数量
}
算法主要改动在客户端。我们先在客户端类构造函数中添加生成掩码矩阵mask的代码,掩码矩阵是用伯努利分布函数随机生成的。
self.mask = {}
for name, param in self.local_model.state_dict().items():
p=torch.ones_like(param)*self.conf["prop"]
if torch.is_floating_point(param):
self.mask[name] = torch.bernoulli(p)
else:
self.mask[name] = torch.bernoulli(p).long()
在本地训练中,在最后一步上传模型的时,将模型参数与掩码矩阵相乘,掩码中0对应的参数相当于被隐藏了。
def local_train(self, model):
for name, param in model.state_dict().items():
self.local_model.state_dict()[name].copy_(param.clone())
optimizer = torch.optim.SGD(self.local_model.parameters(), lr=self.conf['lr'],
momentum=self.conf['momentum'])
self.local_model.train()
for e in range(self.conf["local_epochs"]):
for batch_id, batch in enumerate(self.train_loader):
data, target = batch
if torch.cuda.is_available():
data = data.cuda()
target = target.cuda()
optimizer.zero_grad()
output = self.local_model(data)
loss = torch.nn.functional.cross_entropy(output, target)
loss.backward()
optimizer.step()
print("Epoch %d done." % e)
diff = dict()
for name, data in self.local_model.state_dict().items():
diff[name] = (data - model.state_dict()[name])
# 模型参数与掩码相乘,隐藏部分参数值,达到防御目的
diff[name] = diff[name]*self.mask[name]
return diff
3.1.2 实验分析
在实验过程中,博主分别设置了,来评估经过参数稀疏化后模型的性能表现。下面分别是
的训练截图(证明自己真实做了实验hh)。
只是最后的实验准确度不能够判断参数稀疏化后模型的性能表现变化过程,所以三次训练中的每轮acc和loss我都记录下来,制作成图表,便于观察,得出结论。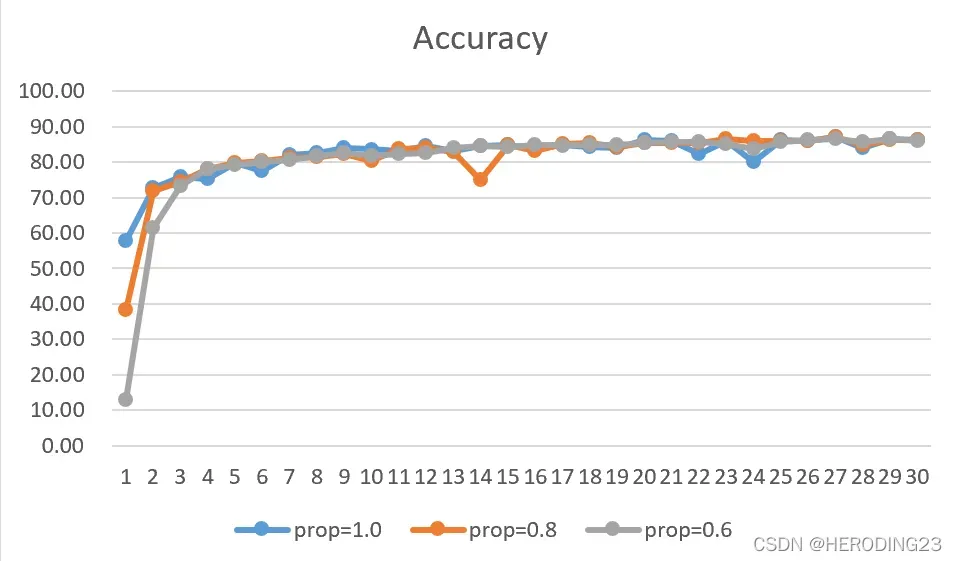
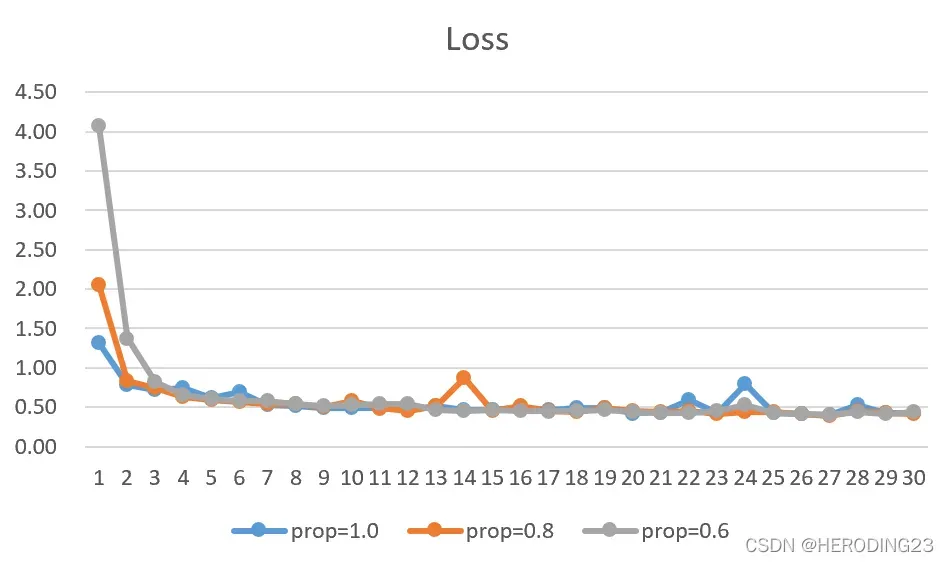
由上述图表可以看出,模型一共训练了30轮,随着掩码矩阵中的0的数量越来越多,稀疏化处理后的模型性能在开始迭代时会有所下降,但随着迭代的进行,模型的性能会逐步恢复到正常状态。
3.2 按层敏感度传输
在联邦场景下,训练模型与集中训练一样,模型参数存在显著冗余。在文献Predicting Parameters in Deep Learning中指出,大部分的神经网络中,仅使用很少的(5%)的权值,就可以达到和原来神经网络相近的性能,甚至优于原神经网络,这种思想类似于Dropout,丢弃的权值有的是没有意义的,甚至对模型有副作用。
这种网络权重重要性的思想在模型压缩中起到了重要的作用。一方面,它可以减少传输开销。另一方面,由于只输出了部分参数信息,攻击者很难通过反转攻击来反转原始数据,从而有效提高系统安全性。本节将解释基于敏感性剪枝的防御技术在联邦学习中的实现。
层敏感度:设当前的模型表示为,这里的
表示第i层。在第t轮中,客户端
进行联邦学习本地训练时,模型将从
变为
。我们将第i层的变化记为:
其中是每层参数的平均变化,它成为灵敏度。
基于层敏感性剪枝的实现过程:对于任意选中的客户端,在完成模型的局部训练后,根据上式计算模型各层的平均变化,各层的变化来自从大到小。排序,变化越大,图层越敏感,算法会上传敏感度高的图层。
3.2.1 详细实现
下面将继续复用第三章代码框架,利用ResNet-50模型对cifar10图像进行分类任务。
配置信息如下:
{
"model_name" : "resnet50", # 使用模型
"no_models" : 10, # 参与方个数
"type" : "cifar", # 数据集种类
"global_epochs" : 30, # 全局迭代次数
"local_epochs" : 3, # 本地迭代次数
"k" : 2, # 每次随机选取2个参与方
"batch_size" : 32, # 批大小
"lr" : 0.01, # 学习率
"momentum" : 0.0001, # momentum参数
"lambda" : 0.5, # 正则化参数
"rate" : 0.95, # 传输比例
}
其中主要添加了rate字段,用来控制传输比例。通过上述公式求出每一层训练前后变化值,并对其排序。
def local_train(self, model):
for name, param in model.state_dict().items():
self.local_model.state_dict()[name].copy_(param.clone())
#print("\n\nlocal model train ... ... ")
#for name, layer in self.local_model.named_parameters():
# print(name, "->", torch.mean(layer.data))
#print("\n\n")
optimizer = torch.optim.SGD(self.local_model.parameters(), lr=self.conf['lr'],
momentum=self.conf['momentum'])
self.local_model.train()
for e in range(self.conf["local_epochs"]):
for batch_id, batch in enumerate(self.train_loader):
data, target = batch
if torch.cuda.is_available():
data = data.cuda()
target = target.cuda()
optimizer.zero_grad()
output = self.local_model(data)
loss = torch.nn.functional.cross_entropy(output, target)
loss.backward()
optimizer.step()
print("Epoch %d done." % e)
diff = dict()
for name, data in self.local_model.state_dict().items():
diff[name] = (data - model.state_dict()[name])
# 按变化率排序
diff = sorted(diff.items(), key=lambda item:abs(torch.mean(item[1].float())), reverse=True)
sum1, sum2 = 0, 0
for id, (name, data) in enumerate(diff):
if id < 304:
sum1 += torch.prod(torch.tensor(data.size()))
else:
sum2 += torch.prod(torch.tensor(data.size()))
# 返回变化率最大的层
ret_size = int(self.conf["rate"]*len(diff))
return dict(diff[:ret_size])
服务器端聚合也被修改。由于客户端是逐层上传的,所以聚合也应该是逐层进行的。
def model_aggregate(self, weight_accumulator, cnt):
for name, data in self.global_model.state_dict().items():
if name in weight_accumulator and cnt[name] > 0:
#print(cnt[name])
update_per_layer = weight_accumulator[name] * (1.0 / cnt[name]
if data.type() != update_per_layer.type():
data.add_(update_per_layer.to(torch.int64))
else:
data.add_(update_per_layer)
3.2.2 实验分析
按照之前的配置文件信息,实验结果如上图所示,可以在经过三十轮的训练后,准确度能达到85%,几乎已经和单机训练的结果持平,再分析一波上传参数的比例,通过设定rate分别为1.0,0.95和0.9,最后得到的训练图像结果如下折线图所示(来自原文中github图片):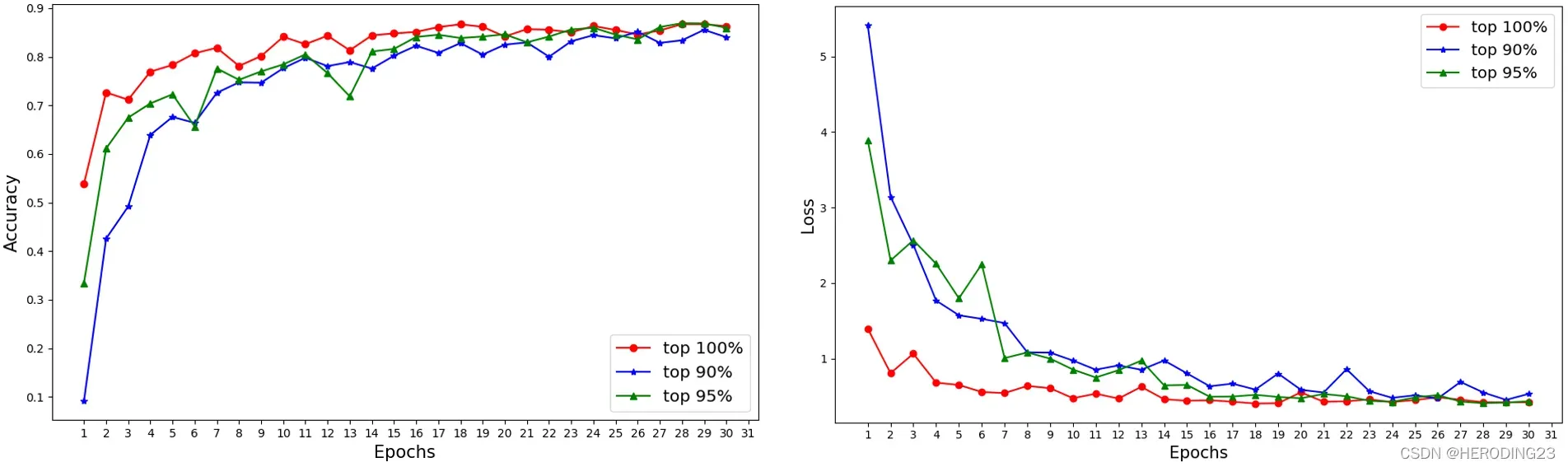
可以看出,在开始训练阶段,上传参数比例小的模型损失较大,结果不太准确,但随着模型的迭代,经过大约十五轮的训练,0.9的模型就和其余两个模型训练结果相差无几了,可以表明,通过层敏感度进行的模型压缩和原始模型性能
相比之下,几乎没有性能损失。
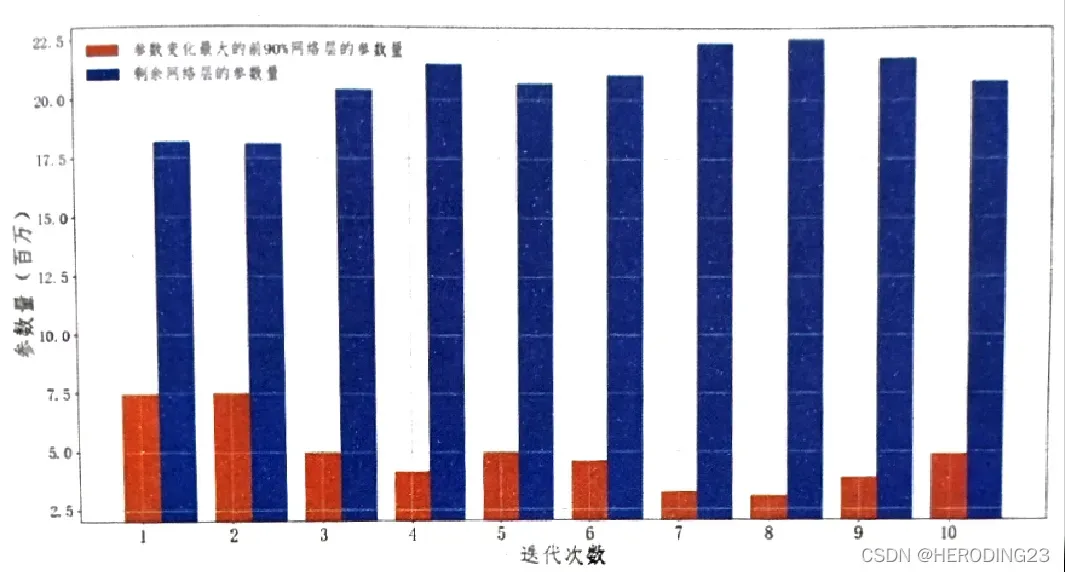
此外,根据观察,按层的变化排序后,参数较多的层变化一般都比较小,变化最小的后10%层的参数占整体参数的75%,如上图所示。
4. 同态加密
本节介绍如何用Paillier半同态加密算法来保护横向联邦学习过程中数据隐私问题。Paillier半同态加密算法是非对称算法的一种实现,说到半同态加密,就不得不提同态加密的三种形式,在这里作为补充。
全同态加密形式等价于一个域。字段中的元素可以在字段范围内进行相乘和相乘,从而映射到字段中的其他元素。二是半同态加密,相当于一个群,只能对群中的元素进行二元运算,将群中的元素映射到群中的其他元素,三是微同态加密,即群中的某些操作同态加密方法(如加法和乘法)只能执行有限的次数,因为在运算过程中加入了噪声,一旦超过限制,就不能得到正确的结果。由于目前的全同态加密是建立在一点同态加密之上的,而且成本很高,所以大部分工作都集中在一点同态加密上。
4.1 Paillier半同态加密算法
回到Paillier半同态加密算法本身,它能够在加密的情况对加密数据进行操作,然后对加密结果进行解密,得到的结果与直接在明文下操作的结果相同。
为了方便讨论,使用x表示明文,使用表示其对应的明文。Paillier算法支持下面两种加密状态的运算:
- 加法同态:
- 标量乘法同态:对于任意常数k。满足
但该算法不满足乘法同态,但该算法计算效率高,在业界得到广泛应用。
4.2 加密损失函数计算
求解机器学习模型时,通常定义一个损失函数,然后使用SGD等方法最小化损失函数,得到最优解。我们以逻辑回归为例,设当前有n个样本数据集合为:
其中,
,LR使用对数损失作为其目标损失函数:
推导上式得到损失函数的梯度,满足:
引入梯度下降并更新模型参数:
循环上述过程,直到损失函数值不再下降或达到最大次数停止迭代。然而上述计算过程都在明文状态下计算的,基于HE的联邦学习,则要求在加密状态下进行参数求解。也就是说,传输的参数是加密后的值,损失函数可以写为:
尽管上式涉及对加密数据的指数运算和对数运算,但是Paillier加密算法只支持加法同态和标量乘法同态,不支持乘法同态及其他复杂运算,所以无法在加密条件下求解该式。
文献Private federated learning on vertically partitioned data via entity resolution and additively homomorphic encryption提出了一种Taylor损失来近似原始对数损失的方法,即通过对原始对数损失函数进行泰勒展开,通过多项式近似对数损失函数,此时损失函数转换为只有加法和标量乘法的运算,可以直接利用Paillier加密。
对于函数,其在x=0处的泰勒多项式展开为
对于损失函数,在z=0处的泰勒展开为:
取其中一个二阶多项式逼近对数损失函数,将带入上式可得:
其中,因此直接去除,最终得到的L为:
对上式求导得到损失值L关于参数的导数:
上式对应的加密梯度为:
4.3 详细实现
实现部分是使用Paillier算法实现横向联邦学习,数据集为乳腺癌数据,代码框架为第三章横向联邦学习代码。
定义模型类:首先自定义模型类LR_Model,方便加密解密操作。
class LR_Model(object):
def __init__ (self, public_key, w_size=None, w=None, encrypted=False):
"""
w_size: 权重参数数量
w: 是否直接传递已有权重,w和w_size只需要传递一个即可
encrypted: 是明文还是加密的形式
"""
self.public_key = public_key
if w is not None:
self.weights = w
else:
limit = -1.0/w_size
self.weights = np.random.uniform(-0.5, 0.5, (w_size,))
# 如果是明文进行加密
if encrypted==False:
self.encrypt_weights = encrypt_vector(public_key, self.weights)
else:
self.encrypt_weights = self.weights
def set_encrypt_weights(self, w):
for id, e in enumerate(w):
self.encrypt_weights[id] = e
def set_raw_weights(self, w):
for id, e in enumerate(w):
self.weights[id] = e
在上述类中,定义了权重向量weights和加密的权重向量encrypt_weights,还定义了两个类函数,分别用来更新明文和密文权重向量。
局部模型训练:局部模型训练在加密状态下进行。首先给出了局部模型训练的算法模块。
def local_train(self, weights):
# 用全局权重更新本地权重
original_w = weights
self.local_model.set_encrypt_weights(weights)
neg_one = self.public_key.encrypt(-1)
for e in range(self.conf["local_epochs"]):
print("start epoch ", e)
idx = np.arange(self.data_x.shape[0])
batch_idx = np.random.choice(idx, self.conf['batch_size'], replace=False)
x = self.data_x[batch_idx]
x = np.concatenate((x, np.ones((x.shape[0], 1))), axis=1)
y = self.data_y[batch_idx].reshape((-1, 1))
# 在加密状态下求取加密梯度,利用上面加密梯度公式求解
batch_encrypted_grad = x.transpose() * (0.25 * x.dot(self.local_model.encrypt_weights) + 0.5 * y.transpose() * neg_one)
encrypted_grad = batch_encrypted_grad.sum(axis=1) / y.shape[0]
for j in range(len(self.local_model.encrypt_weights)):
self.local_model.encrypt_weights[j] -= self.conf["lr"] * encrypted_grad[j]
weight_accumulators = []
for j in range(len(self.local_model.encrypt_weights)):
weight_accumulators.append(self.local_model.encrypt_weights[j] - original_w[j])
return weight_accumulators
这里需要注意的是,在使用Paillier算法进行加解密运算的时候,会涉及大量的大素数幂运算,因此中间可能会越界,所以需要要个有效的处理方法,即加密迭代到一定轮次,重新加密数据,如下所示:
if e > 0 and e%2 == 0:
self.local_model.encrypt_weights = Server.re_encrypt(self.local_model.encrypt_weights)
生成公钥和私钥:利用Paillier算法生成公钥和私钥,私钥保留在可信服务器,公钥分发给客户端。
public_key, private_ley = paillier.generate_paillier_leypair(n_length=1024)
重新加密的过程也在服务器上进行,先利用Paillier私钥解密,再重新加密。
@staticmethod
def re_encrypt(w):
return models.encrypt_vector(Server.public_key, models.decrypt_vector(Server.private_key, w))
在Paillier加密下的横向联邦学习训练结果如下:
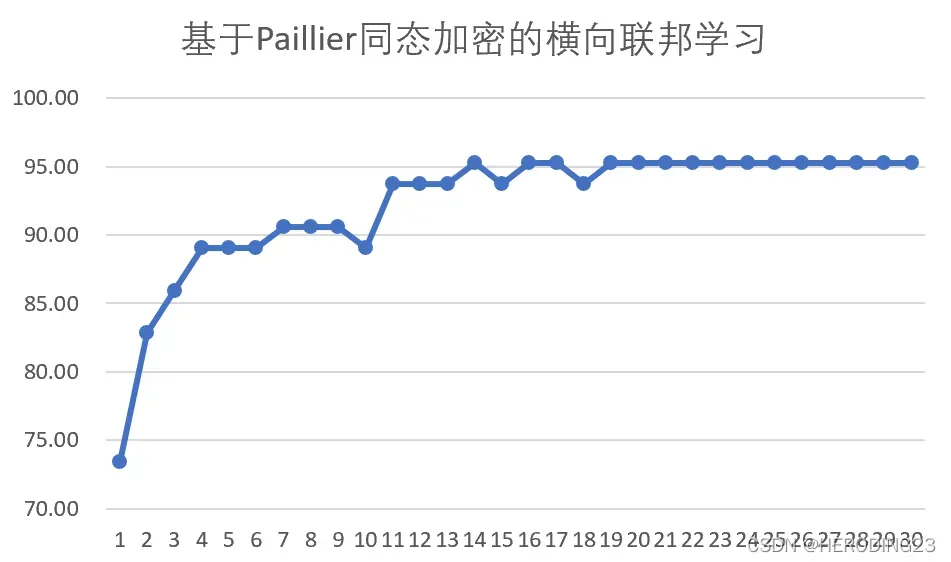
看上面的折线图,我们可以看到二阶逼近的结果对模型性能影响不大,算法经过二十轮迭代后取得了不错的性能。
阅读摘要
花了将近一个星期的时间,终于认真地阅读了整章。这一章的内容可以说是全书的核心,因为联邦学习最大的亮点就是可以保证用户数据的隐私和安全。本章内容涉及隐私保护方式的不同。威胁联邦学习模型的隐私、同态加密、模型压缩和后门攻击。通过完整的学习,我终于在实战中实践了传统联邦学习中的隐私保护算法,而不是只在各种文献中看到。虽然目前只是一个简单的实现,核心构建部分还比较模糊,但我有信心完全理解核心部分,完善自己想要的混合同态加密和差分隐私的加密机制。
当然了,阅读完这章内容,还是有很大的遗憾,就是书中并未提及如何在FATE环境中使用隐私保护算法,这部分的内容,我还得好好研究研究。
参考
https://arxiv.org/abs/1807.00459
https://github.com/FederatedAI/Practicing-Federated-Learning/tree/main/chapter15_Backdoor_Attack
https://arxiv.org/pdf/1306.0543.pdf
https://github.com/FederatedAI/Practicing-Federated-Learning/tree/main/chapter15_Compression
https://blog.csdn.net/qq_40258073/article/details/107939708
文章出处登录后可见!