python的小方法
- (1)利用dir()这个函数方法,知道库里面的方法有些什么。
- (2) 利用type()这个函数方法,知道是什么类型的数据
- (3)从序列元素中获取元素
- [1]单个星号还可以在列表/元组/字典推导式中用于对元素进行解包。
- 不能str
- [2]双个星号:可能会被用于将字典解包为不同的变量
- 获取键
- 使用单星号(*)而不是双星号(**)提供了一个字典作为参数,那么它只会将字典解包为一个元组,其中每个项目都是字典的一个键。
- 举例子
- (4) 利用id()这个函数方法,知道数据内存的地址
- 划重点
- (5)取消print的自动换行
- (6)不能以0打头的数字
- (7)== 和 is 在 Python 中的区别是很容易引起混淆的。
- (8)数据类型不可变or可变
- (9)检查字符串是否含有相同
- 普通
- Python中的sorted方法可以用来检查两个字符串的每个字母是否相同且出现的次数相同
- 保留出现的字符(仅仅一个)
- 再来个区分的地方:
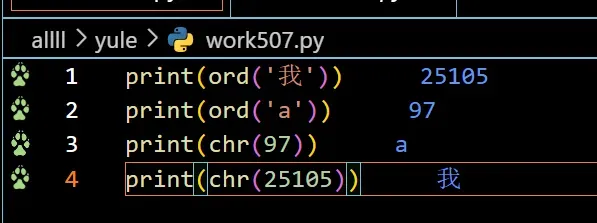
- (10)用ord()知道万国码编码chr()反向获取
- (11)迭代器是什么
- (12)python排序
- (13)查找:
- 搞清两个问题
- (1)为什么不管是字典,元组和列表的查找都是利用运算符号[]里判断的呢
- (2)那为什么用圆括号()就不行了
- (3) 那大括号{}为什么也不可以
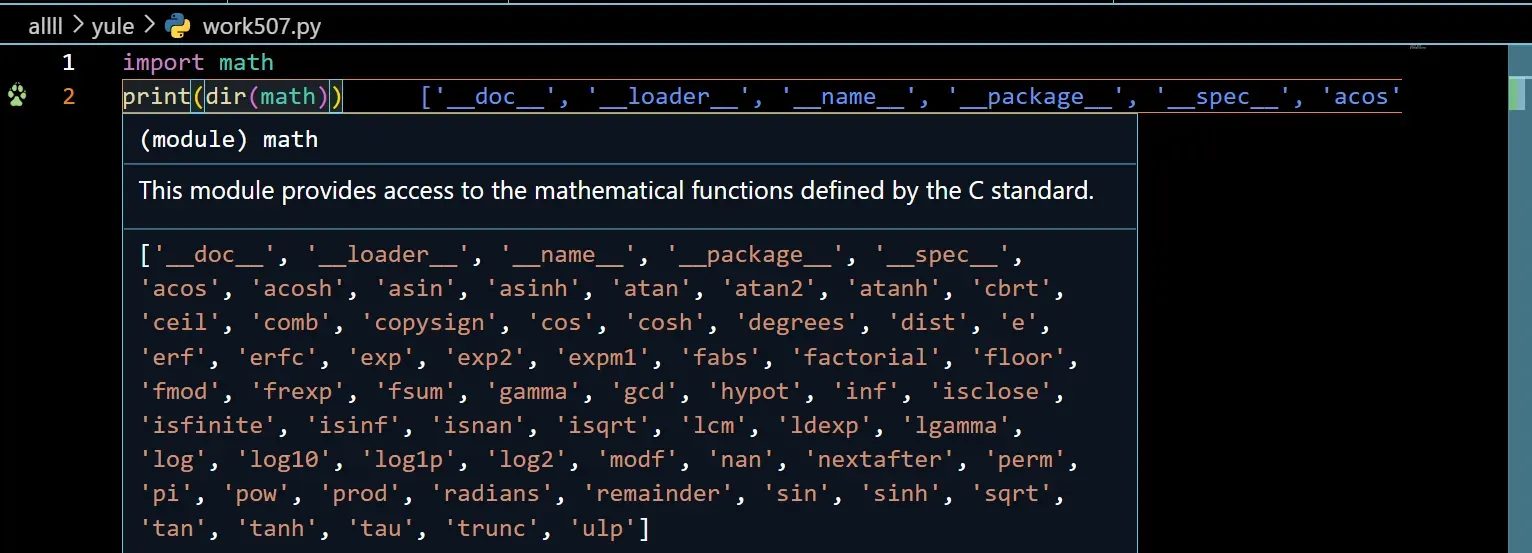
(1)利用dir()这个函数方法,知道库里面的方法有些什么。
import math
print(dir(math))
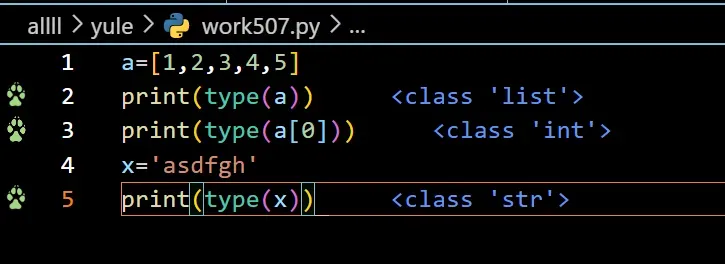
(2) 利用type()这个函数方法,知道是什么类型的数据
type() 函数只接受一个参数
a=[1,2,3,4,5]
print(type(a))
print(type(a[0]))
x='asdfgh'
print(type(x))
(3)从序列元素中获取元素
【1】前提元素个数和取出的存放要一致
元素个数!=存放个数就需要拆包
在从序列元素中获取元素时,只能使用一个单星号语法,用于解包可迭代对象中剩余的元素。
【2】 拆包为关键字参数
*在Python中被称为unpacking操作符,用于将一个可迭代对象(如列表、元组等)中的元素解包为单独的元素。
但是要注意 TypeError: print() argument after * must be an iterable, not int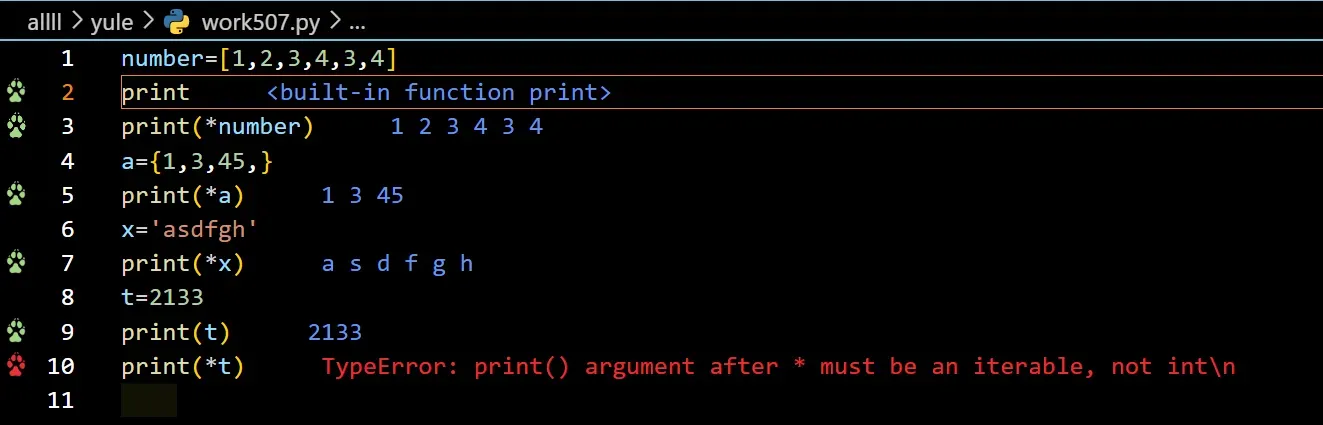
[1]单个星号还可以在列表/元组/字典推导式中用于对元素进行解包。
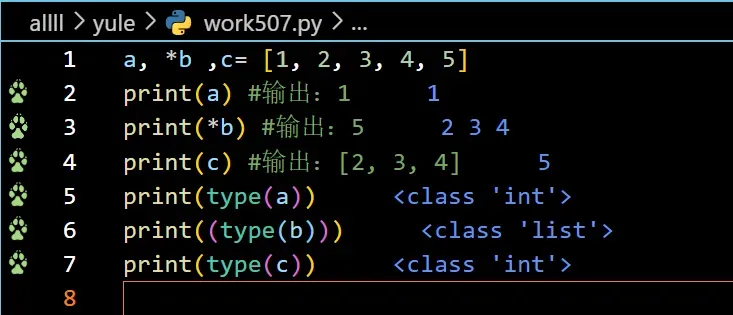
a, *b, c = [1, 2, 3, 4, 5]
print(a) #输出:1
print(c) #输出:5
print(b) #输出:[2, 3, 4]
有【1】可以知道,一一对应,a对于元素1,c对于元素5,那么b就将其打包。
[使用解包操作后,剩余的元素被打包为一个列表,而变量a、c、b则按照赋值的顺序对应原列表的位置。]
在Python中,变量的数据类型是根据赋值对象的数据类型自动推导出来的,因此变量a和变量c都是整型变量。
不能str
字符串对象是不可变的序列类型,而打包操作会生成一个可变的列表对象,这与字符串对象的特性不匹配。
x='1234'
print(type(*x))
^^^^^^^^
TypeError: type() takes 1 or 3 arguments
type() 函数只接受一个参数,因此 *x 语法在这里是无效的。
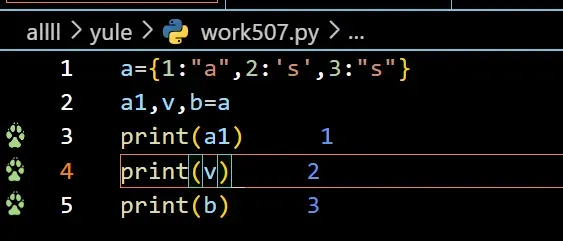
[2]双个星号:可能会被用于将字典解包为不同的变量
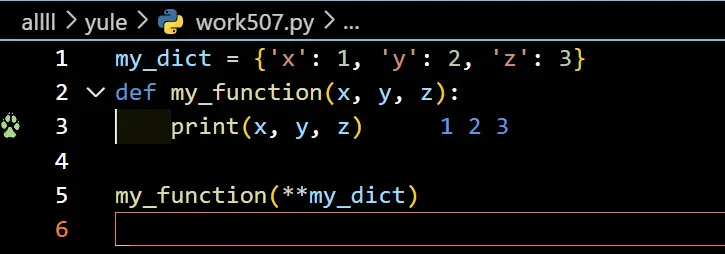
print()函数和字典中使用双星号(**),则这不是有效的用法。 print()函数不能像另一个函数my_function()(从前面的示例中)那样解包字典。
获取键
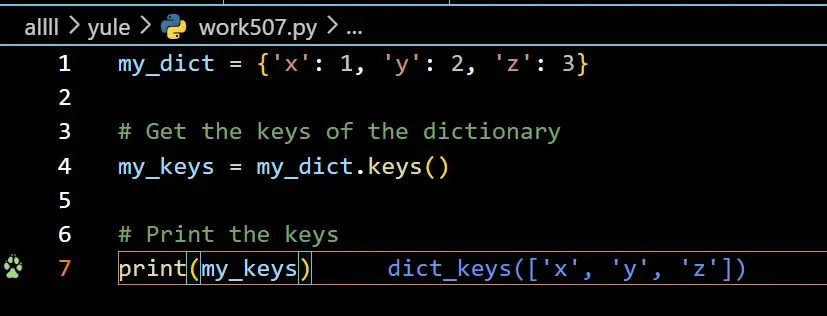
使用单星号(*)而不是双星号(**)提供了一个字典作为参数,那么它只会将字典解包为一个元组,其中每个项目都是字典的一个键。
b = {'a': 1, 'b': 2}
print({**b})
print 语句中使用解包操作符,您需要将字典括在花括号 {} 中。这是因为解包操作符 ** 用于将字典作为关键字参数传递给函数。当在函数调用之外使用时,需要将其括在花括号中以表示它是一个字典。
举例子
#用星号解包出来值
my_dict = {'a': 1, 'b': 2}
print(*my_dict.values())
#如果要将值解包到单独的变量中,可以执行以下操作:
a, b = my_dict.values()
#字典 b 使用双星号运算符 ** 进行解包。这用于将字典解包为新字典。
# 在这种情况下,新字典只是 b 的副本。生成的字典将具有与 b 相同的键值对。
b = {'a': 1, 'b': 2}
print({**b})#b 相同的键值对的新字典:{'a': 1, 'b': 2}。
(4) 利用id()这个函数方法,知道数据内存的地址
id()函数在Python中返回一个对象的唯一标识符。这个标识符是一个非负整数,通常用作对象的内存地址。它们都具有相同的标识符。
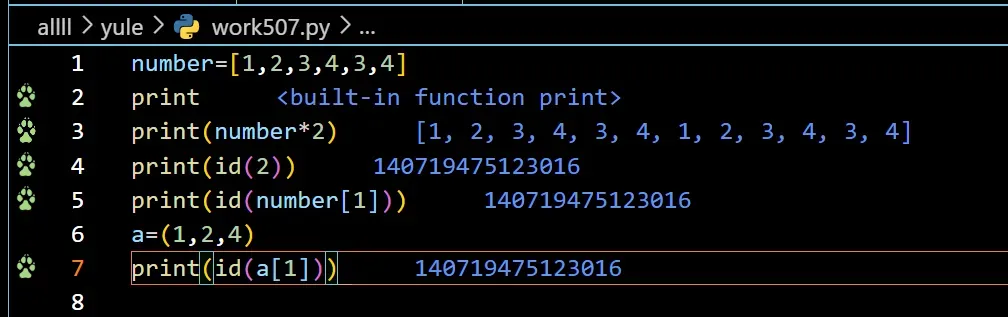
number=[1,2,3,4,3,4]
print
print(number*2)
print(id(2))
print(id(number[1]))
a=(1,2,4)
print(id(a[1]))
划重点
为了在Python中生成唯一的内存地址,您可以使用内置的 id() 函数,它返回对象的身份,即每个对象的唯一整数。这个身份保证对对象的生命周期唯一且恒定。如果你需要比较两个对象是否具有相同的身份,你可以使用 is 运算符来比较它们的身份而不是它们的值。
a = [1, 2, 3]
b = a
c = [1, 2, 3]
print(id(a)) # 打印一个表示a的内存位置地址的唯一整数
print(id(b)) # 输出与a相同的整数,因为b只是另一个对与a相同的列表对象的引用
print(id(c)) # 输出一个与a和b不同的整数,因为c是一个完全不同的列表对象
print(a is b) # 输出 True,因为a和b引用同一个对象
print(a is c) # 输出 False,因为a和c是具有不同内存地址的不同对象
需要注意的是,此行为特定于Python中的小整数(精确地说,介于-5和256之间的整数值)。对于其他类型的对象或较大的整数值,Python可能会创建具有唯一标识符的新对象。
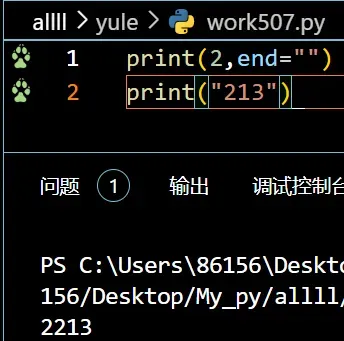
(5)取消print的自动换行
print(2,end="")
print("213")
(6)不能以0打头的数字
八进制数在Python 3中不再支持前缀0。如果您在Python 2中使用前缀0表示八进制数
[对比C语言中的整型字面量,以0作为开头表示为八进制数,以0x或0X开头表示为十六进制数]
num = 0o10
print(num) # 输出8
(7)== 和 is 在 Python 中的区别是很容易引起混淆的。
== 用于比较两个对象的值是否相等。在使用 == 时,比较的是两个对象的值是否相等,即使它们在内存中并不相同。
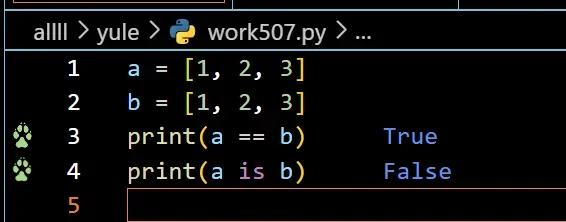
is 用于比较两个对象在内存中的位置是否相同。(这个情况要联系(5)的id()函数)
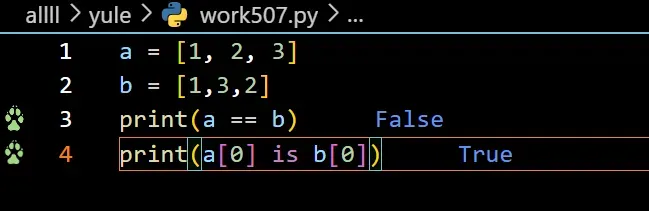
(8)数据类型不可变or可变
字符串和元组是不可变的
列表,字典,集合可变。
(9)检查字符串是否含有相同
普通
可以使用 str() 函数将两个字符串转换为相同的大小写,然后使用 == 比较它们。如果要忽略大小写比较字符串,则此方法非常有用。
使用 is 操作符比较两个字符串的身份。如果两个字符串是同一个对象,则返回 True,否则返回 False。
直接使用 == 操作符直接比较两个字符串。如果字符串相同,则返回布尔值 True,否则返回 False。
Python中的sorted方法可以用来检查两个字符串的每个字母是否相同且出现的次数相同

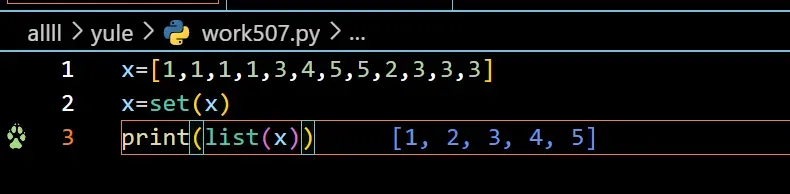
保留出现的字符(仅仅一个)
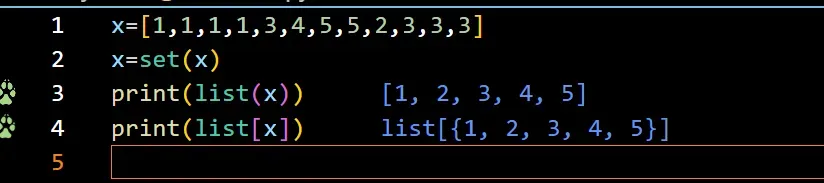
x=[1,1,1,1,3,4,5,5,,2,3,3,3]
x=set(x)
print(list[x])
再来个区分的地方:
(10)用ord()知道万国码编码chr()反向获取
(11)迭代器是什么
代器是一种对象,它允许程序员在遍历集合时访问每个元素,而不会暴露整个集合的实现。在Python中,迭代器是一个支持迭代(返回连续的值)和无限序列(可能无限数量的值)的对象而无需预先计算序列的所有值。迭代器需要实现两个方法:iter()和__next__()。iter()方法返回迭代器对象本身,并将迭代器的内部指针设置为序列开头。
(12)python排序
python中有许多函数后面加上了ed就变得不一样,一般就是对于原序列操作和生成新序列的一个区别
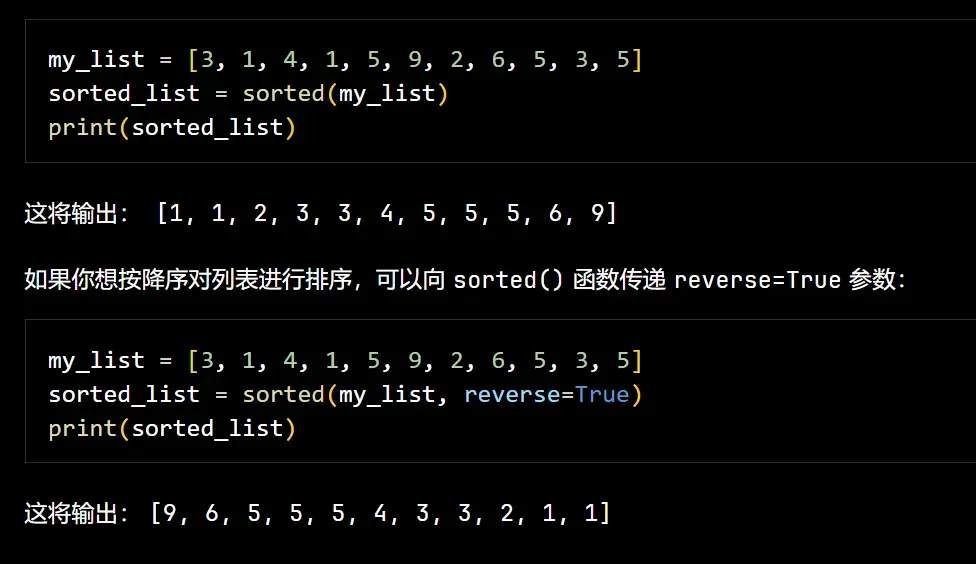
(13)查找:
字典查找:您可以使用字典根据键执行查找。以下是一个示例:
num = int(input(""))
result = {0: "Yes", 1: "No"}[num &1]
print(result)
#列表索引:您可以使用列表根据索引执行查找。以下是一个示例:
num = int(input(""))
result = ["Yes", "No"][num % 2]
print(result)
如果是元组的话能就是把上方的左边的列表换成元组的符号()就是“”元祖查找“”或者叫做“”元祖索引“”
搞清两个问题
(1)为什么不管是字典,元组和列表的查找都是利用运算符号[]里判断的呢
(2)那为什么用圆括号()就不行了
(3) 那大括号{}为什么也不可以

在Python中,字典、元组和列表都是序列类型,因此使用方括号[]访问它们的元素。序列类型是由整数索引的。
(1)方括号[]用于指示要访问的元素的索引。在字典中,索引是元素的键,而在列表和元组中,索引是序列中元素的位置。这种索引约定在Python的所有序列类型中都是一致的,使得以类似的方式处理不同类型的数据结构变得容易。
(2)然而,圆括号()在Python中不用于索引,因为它们在Python中有不同的含义。圆括号用于分组表达式、调用函数和创建元组。当用于索引时,圆括号被解释为函数调用,这不是我们想要的。因此,我们使用方括号进行索引。
(3)大括号{}不能用于索引,因为它们与方括号[]有不同的含义。大括号用于定义集合和字典。集合是无序的唯一元素的集合,而字典是无序的键值对的集合。因此,使用大括号进行索引是没有意义的,并且会导致语法错误。
文章出处登录后可见!