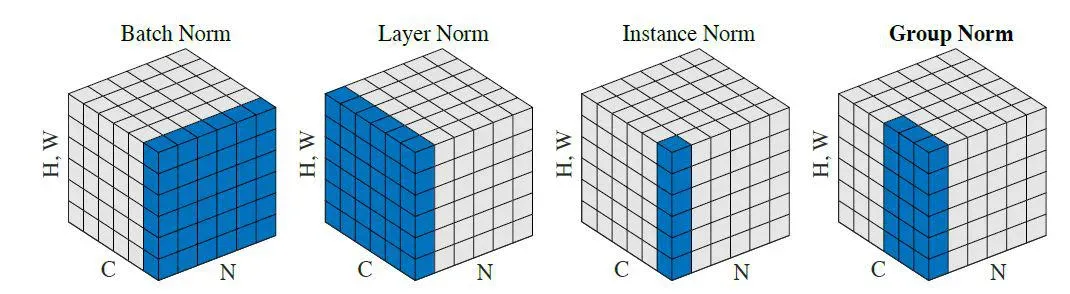
绿色区域表示将该区域作用域(四种方法都贯穿了w,h维度),即将该区域数值进行归一化,变为均值为0,标准差为1。BN的作用区域时N,W,H,表示一个batch数据的每一个通道均值为0,标准差为1;LN则是让每个数据的所有channel的均值为0,标准差为1。IN表示对每个数据的每个通道的均值为0,标准差为1.
BN,LN,IN,GN从学术化上解释差异:
BatchNorm:batch方向做归一化,算NHW的均值,对小batchsize效果不好;BN主要缺点是对batchsize的大小比较敏感,由于每次计算均值和方差是在一个batch上,所以如果batchsize太小,则计算的均值、方差不足以代表整个数据分布
LayerNorm:channel方向做归一化,算CHW的均值,主要对RNN作用明显;
InstanceNorm:一个channel内做归一化,算H*W的均值,用在风格化迁移;因为在图像风格化中,生成结果主要依赖于某个图像实例,所以对整个batch归一化不适合图像风格化中,因而对HW做归一化。可以加速模型收敛,并且保持每个图像实例之间的独立。
GroupNorm:将channel方向分group,然后每个group内做归一化,算(C//G)HW的均值;这样与batchsize无关,不受其约束。
SwitchableNorm是将BN、LN、IN结合,赋予权重,让网络自己去学习归一化层应该使用什么方法。
BN的理解
Internal Covariate Shift定义
在深层网络训练的过程中,由于网络中参数变化而引起内部结点数据分布发生变化的这一过程被称作Internal Covariate Shift。
Internal Covariate Shift引发的问题
1)上层网络需要不停调整来适应输入数据分布的变化,导致网络学习速度的降低
我们在上面提到了梯度下降的过程会让每一层的参数 ![]() 和
和 ![]() 发生变化,进而使得每一层的线性与非线性计算结果分布产生变化。后层网络就要不停地去适应这种分布变化,这个时候就会使得整个网络的学习速率过慢。
发生变化,进而使得每一层的线性与非线性计算结果分布产生变化。后层网络就要不停地去适应这种分布变化,这个时候就会使得整个网络的学习速率过慢。
(2)网络的训练过程容易陷入梯度饱和区,减缓网络收敛速度
当我们在神经网络中采用饱和激活函数(saturated activation function)时,例如sigmoid,tanh激活函数,很容易使得模型训练陷入梯度饱和区(saturated regime)。随着模型训练的进行,我们的参数 ![]() 会逐渐更新并变大,此时
会逐渐更新并变大,此时 ![]() 就会随之变大,并且
就会随之变大,并且 ![]() 还受到更底层网络参数
还受到更底层网络参数 ![]() 的影响,随着网络层数的加深,
的影响,随着网络层数的加深, ![]() 很容易陷入梯度饱和区,此时梯度会变得很小甚至接近于0,参数的更新速度就会减慢,进而就会放慢网络的收敛速度。
很容易陷入梯度饱和区,此时梯度会变得很小甚至接近于0,参数的更新速度就会减慢,进而就会放慢网络的收敛速度。
对于激活函数梯度饱和问题,有两种解决思路。第一种就是更为非饱和性激活函数,例如线性整流函数ReLU可以在一定程度上解决训练进入梯度饱和区的问题。另一种思路是,我们可以让激活函数的输入分布保持在一个稳定状态来尽可能避免它们陷入梯度饱和区,这也就是Normalization的思路。
BN的优点
(1)BN使得网络中每层输入数据的分布相对稳定,加速模型学习速度
(2)BN使得模型对网络中的参数不那么敏感,简化调参过程,使得网络学习更加稳定
(3)BN允许网络使用饱和性激活函数(例如sigmoid,tanh等),缓解梯度消失问题
(4)BN具有一定的正则化效果
BN的用法
对小批量(mini-batch)的2d或3d输入进行批标准化(Batch Normalization)操作
![]()
在每一个小批量(mini-batch)数据中,计算输入各个维度的均值和标准差。gamma与beta是可学习的大小为C的参数向量(C为输入大小)
在训练时,该层计算每次输入的均值与方差,并进行移动平均。移动平均默认的动量值为0.1。
在验证时,训练求得的均值/方差将用于标准化验证数据。
参数:
num_features: 来自期望输入的特征数,该期望输入的大小为’batch_size x num_features x width
eps: 为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。
momentum: 动态均值和动态方差所使用的动量。默认为0.1。
affine: 一个布尔值,当设为true,给该层添加可学习的仿射变换参数。
Shape: – 输入:(N, C)或者(N, C, L) – 输出:(N, C)或者(N,C,L)(输入输出相同)
example:
>>> # With Learnable Parameters
>>> m = nn.BatchNorm1d(100)
>>> # Without Learnable Parameters
>>> m = nn.BatchNorm1d(100, affine=False)
>>> input = autograd.Variable(torch.randn(20, 100))
>>> output = m(input)Shape: – 输入:(N, C,H, W) – 输出:(N, C, H, W)(输入输出相同)
归一化维度:[N,H,W],计算C次均值方差
>>> # With Learnable Parameters
>>> m = nn.BatchNorm2d(100)
>>> # Without Learnable Parameters
>>> m = nn.BatchNorm2d(100, affine=False)
>>> input = autograd.Variable(torch.randn(20, 100, 35, 45))
>>> output = m(input)LN的用法
# NLP Example
batch, sentence_length, embedding_dim = 20, 5, 10
embedding = torch.randn(batch, sentence_length, embedding_dim)
layer_norm = nn.LayerNorm(embedding_dim)
# Activate module
layer_norm(embedding)
# Image Example
N, C, H, W = 20, 5, 10, 10
input = torch.randn(N, C, H, W)
# Normalize over the last three dimensions (i.e. the channel and spatial dimensions)
# as shown in the image below
layer_norm = nn.LayerNorm([C, H, W])
output = layer_norm(input)IN的用法
# Without Learnable Parameters
m = nn.InstanceNorm2d(100)
# With Learnable Parameters
m = nn.InstanceNorm2d(100, affine=True)
input = torch.randn(20, 100, 35, 45)
output = m(input)GN的用法
input = torch.randn(20, 6, 10, 10)
# Separate 6 channels into 3 groups
m = nn.GroupNorm(3, 6)
# Separate 6 channels into 6 groups (equivalent with InstanceNorm)
m = nn.GroupNorm(6, 6)
# Put all 6 channels into a single group (equivalent with LayerNorm)
m = nn.GroupNorm(1, 6)
# Activating the module
output = m(input)BN和LN的用法差异
BN是把除了轴C外的所有轴的元素放在一起,取平均值和方差的,然后对每个元素进行归一化,最后再乘以对应的γ和β(共享)。BN共有num_features个mean和var,(假设输入数据的维度为(N,C, H, W))。
而LN是把normalized_shape这几个轴的元素都放在一起,取平均值和方差的,然后对每个元素进行归一化,最后再乘以对应的γ和β (每个元素不同)。LN共有N1*N2个mean和var(假设输入数据的维度为(N,normalized_shape(C, H, W),normalized_shape表示多个维度)
思考题1:为什么Layer Norm是对每个单词的Embedding做归一化?
因为每个序列(每个样本)的单词个数不一样,但在代码实现的时候会进行padding,比如一个序列原始单词数为30个,另一个序列原始单词数是8,然后你统一padding成了30个单词,那如果按照相同维度,进行归一化,norm的信息就会被无意义的padding的embedding冲淡的!这显然是不合理的。
思考题2:为什么BN训练和测试时有区别,而LN没区别?
BatchNorm的统计量是一个batch算出来的,在线测试时,不太可能累计一个batch资料后再进行测试的。所以在训练的时候要记录统计量running mean和running var,作为预测时的均值和方差。
而LayerNorm训练和测试的时候不需要model.train()和model.eval(),是因为它只针对一个样本,不是针对一个batch,所以LayerNorm只有参数gamma和beta,没有统计量,因此LN训练和预测没有区别。
参考文献:
https://zhuanlan.zhihu.com/p/34879333
https://pytorch-cn.readthedocs.io/zh/latest/package_references/torch-nn/#normalization-layers-source
https://blog.csdn.net/fksfdh/article/details/124750629
https://liumin.blog.csdn.net/article/details/85075706
https://blog.csdn.net/qq_43827595/article/details/121877901
https://pytorch.org/docs/stable/generated/torch.nn.LayerNorm.html#torch.nn.LayerNorm
文章出处登录后可见!