下午跟朋友聊天,聊到编码和传输,兴致未尽,有必要继续说说有损传输,承接 从意义中恢复而不从数据包恢复。
在 AI 大模型催化下,网络通信方式将完全不同,依赖编码的柔性,有损传输将比 tcp/ip 更具弹性和吸引力,只有能接受信息传输的失真,智能才能真正涌现。换句话说,要用 “人的方式而不是计算机的方式” 传输信息,这才是 AI。
没有柔性的网络,大量算力将会花(“浪费”在这里更合适)在比如保序,重传,一致性上,这些问题如果不受控将指数级爆发,很快将系统淹没。如果不接受丢包,就必须对丢包进行重传(或 fec),重传就会引发重传风暴进而拥塞崩溃,而拥塞控制就在这背景下提出,事情逐渐变得复杂,而这种复杂是平添的,随着时间推移,这种平添的复杂将消耗人和网络的大量算力。
我们先看看 “人的方式”。
以视听为例,我们用眼睛和耳朵接收到的自然界的信息都是有损的,这很容易解释,每个人视力听力都不同,接收到的光和声波度量也不同,但只要不是太瞎太聋,这种有损的信息并不妨碍每个人看到听到同样的东西。这种模糊识别的能力来自动物独有的智能,这也解释了计算机为什么没有智能。
计算机如何涌现出智能,或更现实一点,AI 大模型时代的信息传输到底有什么不同。在接受有损的前提再谈信息传输就简单了。比如传输 1 + 2,你肯定会说这里面 “1”,“+”,“2” 都不能丢,丢了肯定要重传的,这岂不是又回到 “可靠” 需求上来了吗?
让我们看看 “有损” 在这个 case 中损失的是什么以及 “从意义中恢复” 恢复的又是什么。
tcp/ip 传统很容易把注意力集中在 “数据包”,但事实上数据包空气一样,只是承载信息的介质,它没有意义,既然要从意义中恢复,就要对 “意义” 编码而不是对 “数字 1” 编码,如果对 “1 的形象” 编码,比如编码成竖着排列的 10 个点进行传输,即使丢几个点,剩下的依然是 “一列点”,对于人而言,眯着眼看,它就是 “数字 1”。计算机也应有这能力。
这 case 中,可能你看到编码若干个点比编码一个 ascii 码 49 更浪费带宽,这不是自找麻烦吗,请接着往下看。
上面 case 中我试图用 “1 的形象” 替代 “数字 1”,然后让接收端看图识字,这不够高效,但这就是人的方式,人一直在看图识字,在读这篇文章时你也在看图识字,人识别信息的方式就是识别 “形象” 而不是识别编码,但视网膜成像原理和网络传输不同,前者带宽近乎无限,而网络带宽显然有限。计算机做得到普遍的看图识字吗?
继续这问题前先解决更实际的计算机网络传输音视频流的问题,我在 从意义中恢复而不从数据包恢复 一文中提到人们流媒体传输的路子走偏了,因为人们没模仿大自然传播图像和声音的方式。自然界中,声音和颜色作为信源就在那里,信息传输靠 “receiver 拉” 而不是 “sender 推”,视力好的人一定比视力不好的人看得清,但无论谁都不可能看得 100% 清,有趣的是,考虑到这一点,人们对图像和声音进行数字化编码和存储时,采用的就是有损的方式 “采样” 而不是在胶卷上模拟曝光或用录放机模拟原始震动,遗憾的是,网络传输音视频信息时没有采用这种自然的方式,却偏偏引入 “可靠” 因素,虽然人们心里知道信息可丢,但实际上还是这里 arq,那里 fec。
再展示一下简化的有损传输,这双皮鞋以后不会再展示了:
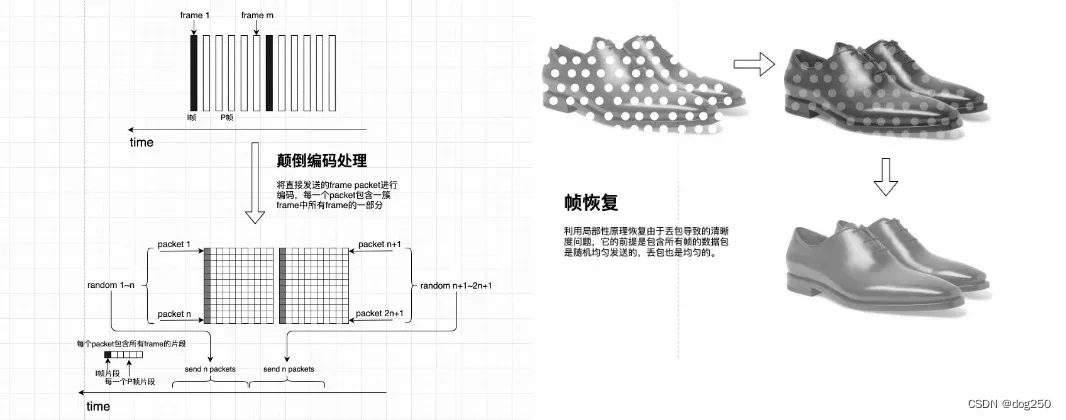
回到计算机网络看图识字的效率问题,让我们集中关注比如文字类的抽象信息传输,它们在大自然并不存在。既然看图识字的方式带宽效能太低,我们不得不详细审视这类抽象信息的本质。
文字本身就是人类智能给世间万物的编码,换到计算机网络的世界,根本不存在 “对文字再编码” 的需求,根本就不需要传输文字本身,忘掉这回事,只需要让计算机对世间万物学人的样子做就是了,人用了文字,而计算机可用别的。
记住关键点,传输的是 “意义” 而不是 “编码”,当我们有一个苹果时,除非教学,否则没人会说苹果这词,至多指着苹果说 “它很甜”,只有在没有苹果时,才会说 “中午我吃了一个苹果”。
我们依然按照人的方式理解文字,然后看计算机怎么做。
人从婴儿到成人,一直在不停学习某种或几种语言的听说读写,本质上是在不断建立形象的,抽象的,具象的,概念的世间万物和某种符号的映射关系,从字到词,词组,句子的读写,到吵架,面试,扯淡,演讲,辩论,都是这种映射关系的学习,矫正,甚至遗忘,即增删改查。如果你对一个从没有接触过汉语的人讲汉语,在他的库里,这种映射数量为 0,他完全不知道你在说什么。但对于一个中国人,当他听到 “锄x日当午,汗滴x下土”,他能很快补上缺失的两个字,因为在他心里有个包含足够多映射关系的 “大模型”,而缺了两个字的两句诗恰好 99.9…% 匹配到 “锄禾日当午,汗滴和下土”,于是他能把有损信息恢复,在整个传输中,“禾”,“和” 二字没进行任何冗余重复。
有点像 chatgpt 了,实际上 chatgpt 也只是这种类型交流的一个具体 case。
OK,我们用 “人的方式” 构建一个非看图识字的计算机网络传输的机制。
假设所有计算机内部都存储着同一个大立方体,将形象的,抽象的,具象的,概念的世间万物划分为 n(n是个巨大无比的数) 个维度,那么每一个形象的,抽象的,具象的,概念的东西就是这 n 维立方体中的 “点”,该点在每个维度的坐标轴上的投影就是这东西在该维度的度量,假设 “锄禾日当午,汗滴和下土” 可通过坐标 (s0,s1,s2…sm…sn) 表示,传输过程中某些坐标比如 s1,s2,sm 丢了,receiver 按照实际收到的坐标在立方体中定位点,虽缺了 3 个数字无法定位到一个精确的点,但剩下的 n – 3 个数字足以定位到某范围,幸运的是,这范围中只有一个点,即 “锄禾日当午,汗滴和下土”,那么就是它了。
如果这范围内有多个点,就只能随机找一个,如果得到某种反馈,那么这个立方体就会被刻画的更加精确,升高一个维度,这就是学习的过程。
于是,网络不再传输 “单个编码”,而改为传输 “一个坐标”,对于网络传输介质而言,传输一个坐标表示一个东西和传输一个 ascii 码表示一个东西没区别,(1,2,3,4) 不是 “皮鞋”,49(ascii 的 1) 也不是 1,对介质而言都是某个编码,但对 sender 和 receiver 而言,坐标是它们理解的。就好像对于空气而言,乌鸦的一声 “啊” 和人的一声 “啊” 的震动也差不多。人类不关注介质,可计算机网络关注数据包,得改。
如果计算机能如此用人的方式交流沟通,它们各自的 n 维立方体会不断细化,n 不断变大,点越来越多,刻画越来越细致,大模型不断被训练,最终涌现出真正的智能。事实上,一开始 n 可以很小,灌输一些简单的概念,就像孩童学话一样,随着输入和输出反馈,整个计算机网络智能就开始成长起来。
未来在 AI 大模型需求驱动下,同时随着存内计算,在网计算,软硬件一体化的发展,一定会倒逼反压传统的网络通信和传输技术一定要改变以适应。既然拥塞控制不好做就不做了,根本不存在拥塞时,本来无一物,何处惹尘埃。
关于人的方式,有个有趣的点,当我们学习母语的时候,我们确实用的是人的方式,但当大多数人成年后学习外语时,却以计算机的方式呈现。
学习英文时,我们按照单词 “apple” 的读音和写法识别它是苹果,一旦缺了 a 这个音节,或缺了 ple,或跟别的词连读在一起,就什么都识别不到了,必须重复一遍甚至几遍,完全分解出 apple 才行,但对一个母语就是英文的,他在乎的是 apple 与 🍎 的映射,发音和写法只是 “apple” 的属性。
以中文 “苹果” 为例,我们会说 “🍎” 有很多属性:
口味:甜的,酸的…
形状:圆的,扁的…
发音:pingguo,pingg,,,及学名,各种方言发音
写法:苹-果
…
中国人无论听到哪个读音,残缺的,方言,连读的,学名,都能想到 🍎,但对于老外学中文,除了按照他学习时老师教的标准普通话 “pingguo” 读音和写法之外,换个山东人读快一点他都不知道在说什么,因为他在记忆语音和字形的编码,而不是在建立一种映射。
记忆一个具象的编码一定要精确的,可搜寻一个立方体区域里的点就不必。
我儿子安德森先生是如何建立映射学习母语的呢?
安德森学说话时,我观察到他是先有了物品概念,再随便(注意,随便)用一个语音标识它,他说 “衣服” 是 “laba”,完全和 “yifu” 无关。他每次都称 “衣服” 为 “laba”,我就知道他建立了 “衣服” 和 “laba” 的映射,在他眼里,laba 是衣服的一个属性,指代衣服,当他开始跟大人交流 “衣服” 时,发现大家不叫衣服为 laba,他慢慢开始矫正这个映射,但不是一次性的,依次大概为 “lagu”,“agu”,“afu”,“yifu”,就这样矫正到和每一个中国人一样关于衣服和读音的映射,就慢慢学会了母语。
他是先有了一个概念,再对其进行编码指代它,如果他不与别人交流这个概念,他一辈子都可以叫衣服为 laba,最后纠正为 “yifu” 只为形成映射的共识方便沟通,不管最后纠正为 “yifu”,还是 “clothes”,都不重要。这大致也解释了为什么婴儿之间可以交流,但他们的话我们却听不懂吧,映射是有的,只是跟我们的不同。
智能就是这样靠不断沟通增删改查自己那份映射涌现的,计算机也如此,但需要改变信息传输的方式。
浙江温州皮鞋湿,下雨进水不会胖。
文章出处登录后可见!