由于其黑盒性质,机器学习使得模型本身难以解释
SHAP提供了一个统一的标准来规范以往十分模糊的“Feature Importance”的含义。
SHAP增强了对模型的解释性,但是我在使用的时候遇到了几个问题。
1. 为什么要用测试集?
SHAP文档
该文档提供了许多示例,例如:
#加载糖尿病数据集
import sklearn
from sklearn.model_selection import train_test_split
import numpy as np
import shap
import time
X,y = shap.datasets.diabetes()
X_train,X_test,y_train,y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# rather than use the whole training set to estimate expected values, we summarize with
# a set of weighted kmeans, each weighted by the number of points they represent.
X_train_summary = shap.kmeans(X_train, 10)
def print_accuracy(f):
print("Root mean squared test error = {0}".format(np.sqrt(np.mean((f(X_test) - y_test)**2))))
time.sleep(0.5) # to let the print get out before any progress bars
shap.initjs()
from sklearn import linear_model
lin_regr = linear_model.LinearRegression()
lin_regr.fit(X_train, y_train)
print_accuracy(lin_regr.predict)
shap_values = ex.shap_values(X_test)
shap.summary_plot(shap_values, X_test)
输出结果如图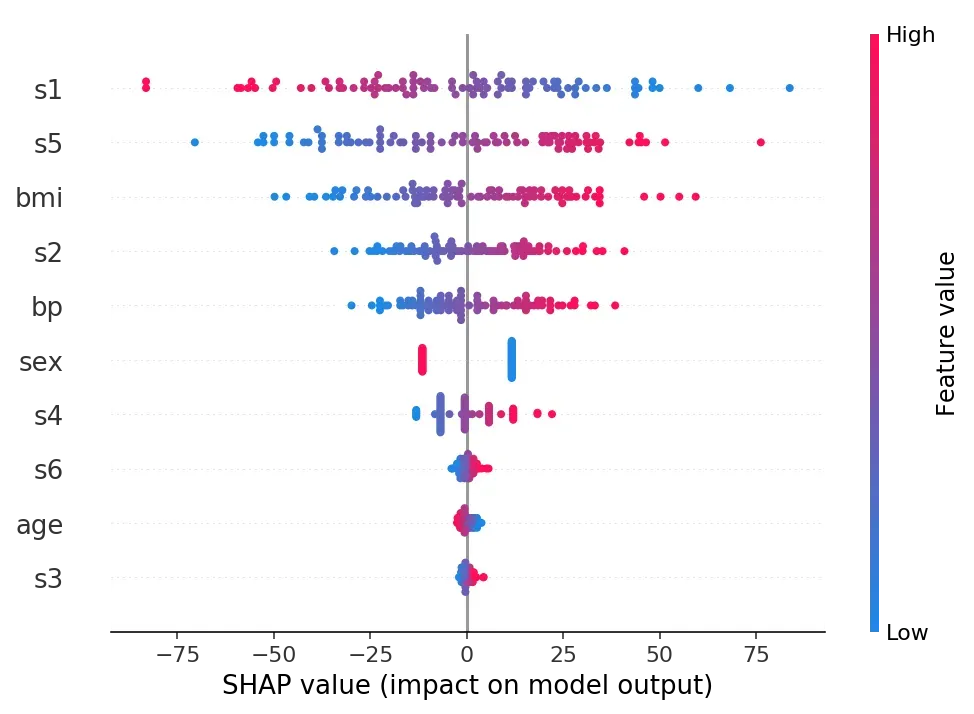
这个图解释了不同样本点的不同特征的SHAP值以及颜色显示了数值本身的大小,我的疑问是测试集样本数据对模型本身有影响吗,比如各种神经网络模型,各个隐含层节点的权重分配难道不是来自于训练集的不断迭代训练吗?测试集与模型本身是否有关联?
- 遇到的问题
绘制依赖图时,存在无法识别特征名称的问题。我的数据是表格数据,特征名是列名,文档上面的例子如下:
shap.dependence_plot("bmi", shap_values, X_test)
我只是简单地标记了特征名称,但是在绘制自己的数据时找不到特征名称。我尝试将数据本身输出,或者使用在数据集中对列进行索引的方法,但我无法绘制它。请告诉我们如何解决它。
文章出处登录后可见!
已经登录?立即刷新