1. 感知机的前向推理?
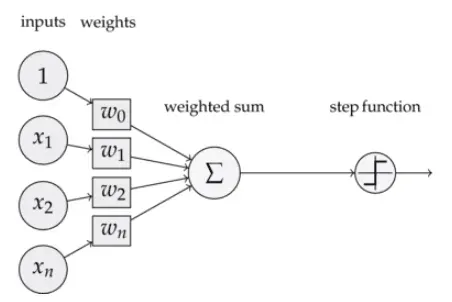
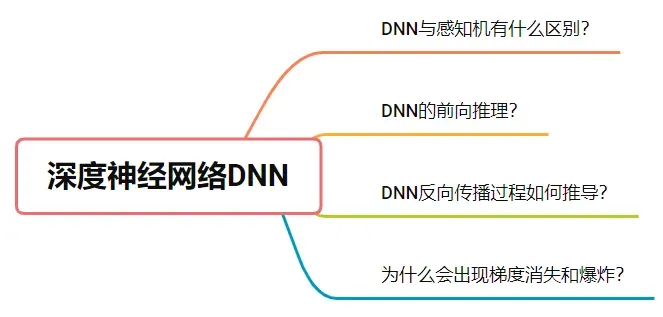
- 感知器实际上是类似于神经网络的神经元。
- w0相当于bias,也就是偏置
- w1-wn是权重
- step fuction是sign
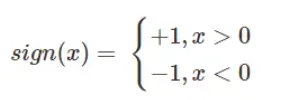
前向推理公式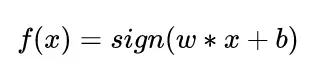
2. 感知机的loss function是什么?
loss function即目标函数,模型所要去干的事情就是我们所定义的目标函数
这里用每个误分类点和超平面之间的距离来定义。
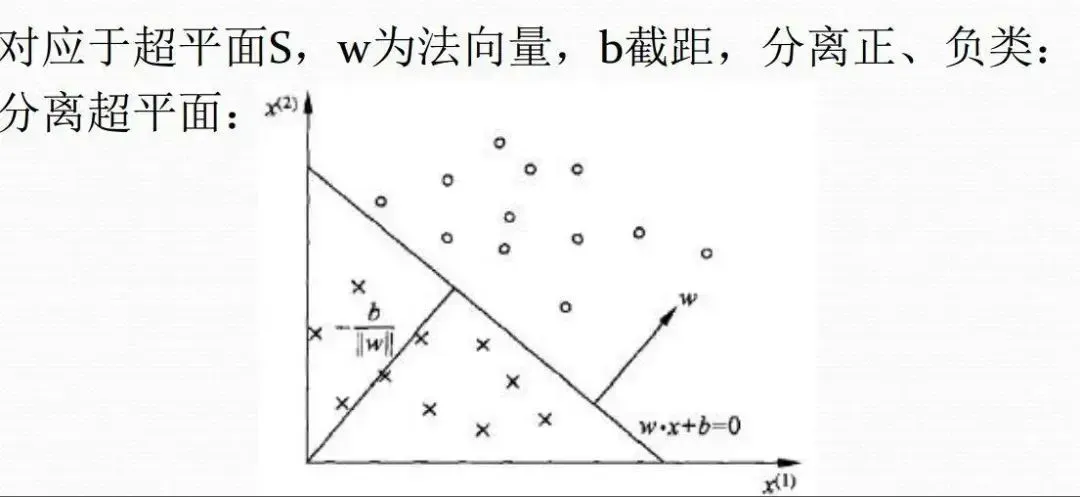
图中(目前以输入为2维(x为x1和x2)情况下举例)w为超平面的法向量,与法向量夹角为锐角即为+1的分类,与法向量夹角为钝角为-1的分类
具体公式: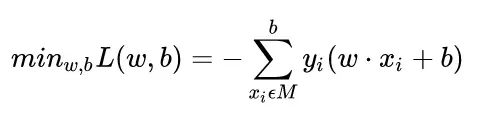
其中 M为一个集和,包含所有的误分类点。
解释一下公式,首先,损失函数是是去判断误分类点到平面的距离的,但是这个正确的分类点的话,是大于零的(正确:y=1,wx+b>0;y=0,wx+b<0),但如果是错误分类的话,
是小于零的,于是计算距离损失的时候需要增加一个负号
。
3. 权重是如何更新的?
梯度下降
利用不断地更新可学习参数,使loss function尽可能的小。
简单来说,就是用loss对你所要更新的权重做一阶导数,得到梯度,在这里我们要更新的权重(也就是我们模型所要学习的部分)是w和b,对它俩做一阶导数。
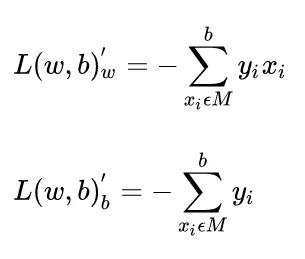
接下来就是更新w和b,利用学习率*一阶导数与目前的w和b进行相加。
感知器不会每次都使用所有的错误分类点进行更新,而是在遇到错误分类点时进行更新。使用的梯度下降法实际上是随机梯度下降法,所以更新后的公式需要去掉累积。 .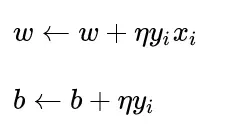
4. 整体过程
- 初始化w和b,其实就是初始一个超平面
- 随机选取一个点(x, y) ,如果满足y(wx+b)<0说明是误分类点(因为如果wx+b>0,y=+1,所以分类正确情况两者相乘>0, 反之),开始第3步
- 更新权重w和b
- 之后回到第2步继续训练,直到训练集中没有误分类点
如果您还没有学习感知器,请转到感知器
机器学习的感知器学习内容详解
1. 二者的区别(感知机和深度神经网络)
感知器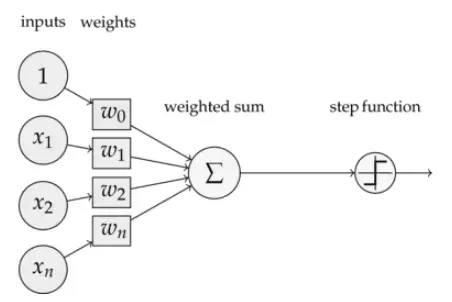
- 多输入,一输出
- 由于激活函数是sign函数,所以只能是二分类问题。
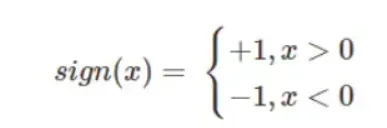
深度神经网络
- 多输入多输出
- 不仅适用于分类问题,还适用于回归、聚类等问题。
- 添加隐藏层,可以有多个或一个隐藏层(深度神经网络结构=输入层+隐藏层+输出层)
- 隐藏层中的每个神经元实际上是一个感知器,因此深度神经网络也称为多层感知器
- 激活函数不再是sign,而是sigmoid,后面还出现tanh、relu或者softmax等激活函数.
Reference
https://www.zybuluo.com/hanbingtao/note/433855
https://blog.csdn.net/m0_37957160/article/details/113922919
https://www.zhihu.com/search?type=content&q=%E6%84%9F%E7%9F%A5%E6%9C%BA
https://zhuanlan.zhihu.com/p/72040253
文章出处登录后可见!