一,介绍
官方介绍:“结巴”中文分词:做最好的 Python 中文分词组件
我理解的官方的目标是做最好的python中文分词组件,但是在网上一搜,很多文章直接说成了是最好的中文分词组件,我看是误解了原文意思,就目前来说jieba分词在解决中文歧义方面还是解决不了(接下来会通过代码实战说明),所以精确度不是最好,也就不能说是最好的中文分词组件了,在此做个记录以便后期找到更好的中文分词组件.现在这类自然语言处理模块越来越多,关于好不好而言,只能说没有最好,只有更好,因为每个中文分词组件都在更新和进步.
二,特点 (以下引用自官文的readme)
- 支持四种分词模式:
- 精确模式,试图将句子最精确地切开,适合文本分析;
- 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
- 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
- paddle模式,利用PaddlePaddle深度学习框架,训练序列标注(双向GRU)网络模型实现分词。同时支持词性标注。paddle模式使用需安装paddlepaddle-tiny,
pip install paddlepaddle-tiny==1.6.1。目前paddle模式支持jieba v0.40及以上版本。jieba v0.40以下版本,请升级jieba,pip install jieba --upgrade。PaddlePaddle官网
- 支持繁体分词
- 支持自定义词典
- MIT 授权协议
关于第四种分词模式的实战理解:如果jieba v0.40及以上版本,并且paddlepaddle在2.0.0以上版本,直接使用jieba.enable_paddle()会报错,因为paddlepaddle在2.0.0以上是默认开启静态图模式
Traceback (most recent call last):
File "D:\Party_committee_project\党员转出回执收集V1\Lib\identify_name.py", line 15, in <module>
jieba.enable_paddle()
File "D:\Party_committee_project\党员转出回执收集V1\Lib\jieba\_compat.py", line 46, in enable_paddle
import jieba.lac_small.predict as predict
File "D:\Party_committee_project\党员转出回执收集V1\Lib\jieba\lac_small\predict.py", line 43, in <module>
infer_ret = creator.create_model(dataset.vocab_size, dataset.num_labels, mode='infer')
File "D:\Party_committee_project\党员转出回执收集V1\Lib\jieba\lac_small\creator.py", line 32, in create_model
words = fluid.data(name='words', shape=[-1, 1], dtype='int64', lod_level=1)
File "<decorator-gen-31>", line 2, in data
File "D:\Party_committee_project\党员转出回执收集V1\Lib\paddle\fluid\wrapped_decorator.py", line 25, in __impl__
return wrapped_func(*args, **kwargs)
File "D:\Party_committee_project\党员转出回执收集V1\Lib\paddle\fluid\framework.py", line 442, in __impl__
), "In PaddlePaddle 2.x, we turn on dynamic graph mode by default, and '%s()' is only supported in static graph mode. So if you want to use this api, please call 'paddle.enable_static()' before this api to enter static graph mode." % func.__name__
AssertionError: In PaddlePaddle 2.x, we turn on dynamic graph mode by default, and 'data()' is only supported in static graph mode. So if you want to use this api, please call 'paddle.enable_static()' before this api to enter static graph mode.
Process finished with exit code 1三,安装说明 (以下引用自官文的readme)
代码对 Python 2/3 均兼容
- 全自动安装:
easy_install jieba或者pip install jieba/pip3 install jieba - 半自动安装:先下载 jieba · PyPI ,解压后运行
python setup.py install - 手动安装:将 jieba 目录放置于当前目录或者 site-packages 目录
- 通过
import jieba来引用 - 如果需要使用paddle模式下的分词和词性标注功能,请先安装paddlepaddle-tiny,
pip install paddlepaddle-tiny==1.6.1。
四,算法 (以下引用自官文的readme)
- 基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG)
- 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合
- 对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法
五,主要功能
1.分词
jieba.cut方法接受四个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用 HMM 模型;use_paddle 参数用来控制是否使用paddle模式下的分词模式,paddle模式采用延迟加载方式,通过enable_paddle接口安装paddlepaddle-tiny,并且import相关代码;jieba.cut_for_search方法接受两个参数:需要分词的字符串;是否使用 HMM 模型。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细- 待分词的字符串可以是 unicode 或 UTF-8 字符串、GBK 字符串。注意:不建议直接输入 GBK 字符串,可能无法预料地错误解码成 UTF-8
jieba.cut以及jieba.cut_for_search返回的结构都是一个可迭代的 generator,可以使用 for 循环来获得分词后得到的每一个词语(unicode),或者用jieba.lcut以及jieba.lcut_for_search直接返回 listjieba.Tokenizer(dictionary=DEFAULT_DICT)新建自定义分词器,可用于同时使用不同词典。jieba.dt为默认分词器,所有全局分词相关函数都是该分词器的映射。
2.词性标注
接下来就是本文要介绍的重点,实战部分
(1)运行环境:python3.7.2 + windows10
(2)实际项目背景:从outlook邮箱的指定收件箱的邮件中找到指定主题的邮件,从这些邮件的主题或者正文中识别出中文姓名
(3)部分代码举例展示:
import paddle
import jieba.posseg as pseg
paddle.enable_static() # 从2.0.0版本开始,Paddle默认开启静态图模式
def identify_person_name(text):
"""
识别姓名
:param text: 语句, str
:return: 姓名, list
"""
"""
jieba算法识别中文名
特殊参数解释: use_paddle: 使用飞浆模式,默认为False
"""
try:
words = pseg.cut(text, use_paddle=True) # jieba分词及词性标注列表
# words = pseg.cut(text) # jieba分词及词性标注列表
name_jieba = [] # jieba识别出来的人名
for pair_word in list(words): # 遍历pair对象
if list(pair_word)[1] == 'nr' or list(pair_word)[1] == 'PER':
name_jieba.append(list(pair_word)[0])
if not name_jieba:
return '未识别到人名'
return f'已识别完毕,结果为{name_jieba}'
except Exception as e:
return e为什么要重点讲解词性标注,因为在实际项目中,识别中文姓名时候是通过词性标注去拿到中文姓名的,所以上述代码中使用了jieba的pseg模块,它可以同时返回识别出来的词语以及词性,当词性为’nr’或’per’时,即为人名;
paddle模式词性标注对应表如下:
paddle模式词性和专名类别标签集合如下表,其中词性标签 24 个(小写字母),专名类别标签 4 个(大写字母)。
| 标签 | 含义 | 标签 | 含义 | 标签 | 含义 | 标签 | 含义 |
|---|---|---|---|---|---|---|---|
| n | 普通名词 | f | 方位名词 | s | 处所名词 | t | 时间 |
| nr | 人名 | ns | 地名 | nt | 机构名 | nw | 作品名 |
| nz | 其他专名 | v | 普通动词 | vd | 动副词 | vn | 名动词 |
| a | 形容词 | ad | 副形词 | an | 名形词 | d | 副词 |
| m | 数量词 | q | 量词 | r | 代词 | p | 介词 |
| c | 连词 | u | 助词 | xc | 其他虚词 | w | 标点符号 |
| PER | 人名 | LOC | 地名 | ORG | 机构名 | TIME | 时间 |
接下来开始实战运行
print(identify_person_name('钟伟政党组织关系转出回执给张颖'))运行结果为:
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\L84171~1\AppData\Local\Temp\jieba.cache
已识别完毕,结果为['钟伟', '张颖']
Loading model cost 0.565 seconds.
Prefix dict has been built successfully.从运行结果可以看出第一个人名没有准确识别出来,原因可能是因为中文歧义的原因,因为语句中的’政党’算一个名词,第二个人名识别出来,不存在歧义,且该人名比较多见
进一步佐证一下,debug一下,看看所有识别出的词语以及词性是什么
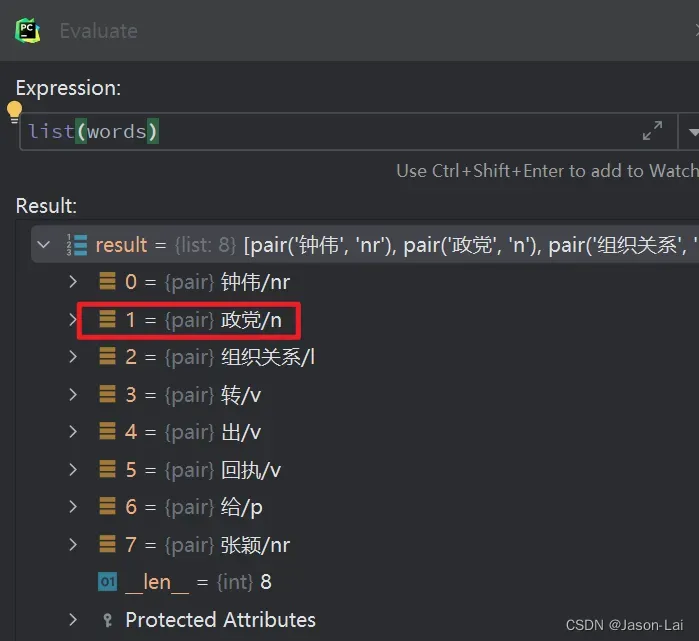
jieba算法把人名’钟伟政’拆开成’钟伟’了,然后把’政’和’党’组成普通名词了,果然是中文歧义的问题,当时用jieba算法去识别实际项目时就是这样不够精确,以至于后期只能跟别的自然语言中文识别组件结合一起使用,或者干脆用别的组件代替jieba,想要知道这个更精确的中文人名识别组件是什么吗,请持续关注本博主发文,欢迎一起交流自然语言处理工具
文章出处登录后可见!