目录
1.通用分页是什么?
Java通用分页是指在Java编程语言中实现的一种通用分页功能。它通常用于在Java Web应用中展示大量数据或查询结果,并将其分页显示给用户。
在Java中,通常会使用以下几个组件或类来实现通用分页功能:
1. 分页查询:通常会通过数据库查询或其他方式获取大量数据,然后使用分页查询技术来获取特定页的数据。这通常包括设置每页显示的数据数量、当前页码和排序规则等参数,然后根据参数筛选和返回相应页的数据。
2. 页面展示:通用分页需要在前端页面上展示分页数据,可以使用Java的模板引擎或前端框架来实现。在页面上通常会显示当前页的数据列表、页码导航、上一页和下一页按钮等控件,以便用户浏览和导航不同页的数据。
3. 分页逻辑:在Java中,通常会使用一些逻辑代码或工具类来处理分页逻辑,例如计算总页数、当前页起始索引、数据转换等。这些代码可以根据每页显示的数据数量、总数据量和当前页码等来计算所需的数据范围,并在数据库查询中使用相应的参数。
4. 控制器和路由:在Java Web应用中,控制器和路由负责处理用户的请求,并将相应的数据传递给前端页面。在通用分页中,控制器会接收用户请求的页码等参数,并将相应页的数据查询结果传递给页面展示部分进行渲染。
总体而言,Java通用分页是通过数据库查询、分页逻辑、页面展示和控制器等组件配合工作,实现在Java Web应用中对大量数据进行分页显示的一种功能。它可以提升用户体验、优化数据加载性能,并方便用户浏览和导航大数据集。
通用分页通常会包括如下元素:
1. 页面切换按钮或链接:用于在不同页面之间切换。
2. 当前页码信息:显示当前所在的页面。
3. 总页面数信息:显示内容总共被分成了多少页。
4. 上一页和下一页按钮或链接:用于直接跳转到上一页或下一页。
5. 条目计数信息:显示当前页面的内容数量。
2.通用分页的作用
Java通用分页在Java Web应用中具有以下几个作用:
1. 改善用户体验:通用分页可以将大量数据分页展示,避免一次性加载大量数据导致页面加载过慢的问题。通过分页显示,用户可以更快速地获取所需信息,提升用户体验。
2. 优化数据加载性能:通过分页查询,Java通用分页可以减少每次数据查询返回的数据量,减轻服务器的负载压力,降低数据库查询的开销,提高数据检索的效率和性能。
3. 方便数据导航和浏览:Java通用分页提供了方便的导航和浏览功能,用户可以通过页码导航、上一页和下一页按钮等进行页面切换,快速浏览各个分页的数据内容。
4. 防止数据溢出:当需要展示的数据量非常大时,如果不使用分页,可能会导致内存溢出或网络传输超时等问题。通过使用Java通用分页,将数据分批加载和展示,可以避免这种情况的发生。
5. 支持可配置性:Java通用分页通常提供了一些可配置的参数,如每页显示的数据数量、排序规则等,允许用户根据需求进行个性化配置,满足不同用户对分页展示的需求。
总之,Java通用分页在Java Web应用中起到提升用户体验、优化数据加载性能、支持数据导航和浏览等作用。它使得展示大量数据更加高效、灵活,并能够满足用户对数据展示的需求。
3. 通用分页的优缺点
Java通用分页的优点:
1. 提高用户体验:通用分页可以将大量数据划分为多个页面,避免加载过长的页面,提高页面加载速度,让用户能够快速浏览和查找所需内容,提升用户体验。
2. 优化性能:通过分页查询,可以减少一次性加载大量数据的开销,节省内存和网络资源,提高数据查询和展示性能,减轻服务器压力。
3. 方便导航和浏览:通用分页提供了直观的导航和浏览方式,用户可以通过上一页和下一页按钮或页码导航快速切换页面,浏览不同页的内容,方便数据的导航和查找。
4. 可配置性强:通用分页通常支持配置每页显示的数据量、排序规则等参数,可以根据具体需求进行个性化配置,满足不同用户的需求。
5. 可复用性高:Java通用分页的实现一般是基于模块化和可扩展的原则,通过封装和抽象,可以将通用分页的功能模块复用于不同的应用场景。
Java通用分页的缺点:
1. 数据一致性:当数据在分页过程中发生变化时,例如新增或删除了一部分数据,会导致分页结果的数据不一致性,需要注意及时更新分页数据以保持一致性。
2. 数据查询效率:在某些场景下,特别是在数据量非常大的情况下,分页查询可能会对数据库性能产生较大的影响,因为每次查询只返回部分数据,可能需要多次查询才能得到完整的结果。
3. 分页参数管理:在应用中需要合理管理分页的参数,特别是上一页、下一页的状态和页码等信息,这需要一定的编码和逻辑控制,否则可能导致分页显示混乱或错误。
需要根据具体应用场景和需求综合考虑这些优缺点,并选择合适的实现方式以达到最佳的效果和用户体验。
4.通用分页的核心思想
Java通用分页的核心思想是将大量数据进行分割,每次只返回部分数据,以便更好地展示和处理数据。其主要的核心思想包括:
1. 数据切片:将大量数据划分为多个较小的数据块或页,每页包含固定数量的数据。这样可以减少一次性加载所有数据的压力,提高数据的检索和加载性能。
2. 分页参数:定义和管理分页的参数,例如当前页码、每页显示的数据量等。通过这些参数,可以精确控制要返回的数据范围。
3. 数据导航:提供导航和切换不同页的功能,让用户能够方便地浏览和导航数据。通常会包括上一页和下一页按钮、页码导航等控件,用于切换不同页的数据。
4. 数据查询和过滤:根据分页参数,对数据进行查询和筛选,只返回当前页的数据。这可以通过数据库查询语句的limit和offset等关键字来实现,限制返回的数据量和数据起始位置。
5. 数据展示和渲染:将查询到的分页数据进行呈现和展示,可以使用Java的模板引擎或前端框架来实现数据的渲染和展示。
通过这些核心思想,Java通用分页可以更好地控制数据的加载和展示,提高用户体验和数据处理的效率。它允许大数据集的分页展示,并提供了灵活的导航和配置选项,满足不同用户对数据浏览需求的需求。
5.通用分页实例
书籍实体类:
package com.liao.enity;
public class Book {
private int bid;
private String bname;
private float price;
@Override
public String toString() {
return "Book [bid=" + bid + ", bname=" + bname + ", price=" + price + "]";
}
public int getBid() {
return bid;
}
public void setBid(int bid) {
this.bid = bid;
}
public String getBname() {
return bname;
}
public void setBname(String bname) {
this.bname = bname;
}
public float getPrice() {
return price;
}
public void setPrice(float price) {
this.price = price;
}
}
封装pageBean类:
package com.liao.utils;
/**
* 分页工具类
*
*/
public class PageBean {
private int page = 1;// 页码
private int rows = 10;// 页大小
private int total = 0;// 总记录数
private boolean pagination = true;// 是否分页
public PageBean() {
super();
}
public int getPage() {
return page;
}
public void setPage(int page) {
this.page = page;
}
public int getRows() {
return rows;
}
public void setRows(int rows) {
this.rows = rows;
}
public int getTotal() {
return total;
}
public void setTotal(int total) {
this.total = total;
}
public void setTotal(String total) {
this.total = Integer.parseInt(total);
}
public boolean isPagination() {
return pagination;
}
public void setPagination(boolean pagination) {
this.pagination = pagination;
}
/**
* 获得起始记录的下标
*
* @return
*/
public int getStartIndex() {
return (this.page - 1) * this.rows;
}
@Override
public String toString() {
return "PageBean [page=" + page + ", rows=" + rows + ", total=" + total + ", pagination=" + pagination + "]";
}
}
书籍“分页模糊查询所有”方法
package com.liao.Dao;
import java.sql.CallableStatement;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
import org.junit.Test;
import com.liao.enity.Book;
import com.liao.utils.DBAccess;
import com.liao.utils.PageBean;
import com.liao.utils.StringUtils;
/**
* 传统dao方法
* 重复代码:
* Connection conn = DBAccess.getConnection();
* CallableStatement ps = conn.prepareCall(sql);
ResultSet rs = ps.executeQuery();
*
* 流程重复:
* 1.需要创建数据库表对应的实体类对象
* 2.将查询出来的结果集添加到实例化对象属性中
* 3.已经被填充的实体对象,加入集合中
* while(rs.next()) {
Book b = new Book();
b.setBid(rs.getInt("bid"));
b.setBname(rs.getString("bname"));
b.setPrice(rs.getFloat("price"));
list.add(b);
}
*
*
*
* @author Administrator
*
*/
public class BookDao extends BaseDoa<Book>{
/**
* 查询Dao方法 优化前
* @param book
* @param pagebean
* @return
* @throws Exception
*/
public List<Book> list1(Book book,PageBean pagebean) throws Exception{
List<Book> list = new ArrayList<Book>();
//获取连接
Connection conn = DBAccess.getConnection();
//查询sql语句
String sql ="select * from t_mvc_book where 1=1 ";
String bname = book.getBname();
if(StringUtils.isNotBlank(bname)) {
sql += "and bname like '%"+bname+"%'";
}
CallableStatement ps = conn.prepareCall(sql);
ResultSet rs = ps.executeQuery();
while(rs.next()) {
Book b = new Book();
b.setBid(rs.getInt("bid"));
b.setBname(rs.getString("bname"));
b.setPrice(rs.getFloat("price"));
list.add(b);
}
return list;
}
/**
* 优化后
* @param book
* @param pagebean
* @return
* @throws Exception
*/
public List<Book> list2(Book book,PageBean pagebean) throws Exception{
//查询sql语句
String sql ="select * from t_mvc_book where 1=1 ";
String bname = book.getBname();
if(StringUtils.isNotBlank(bname)) {
sql += "and bname like '%"+bname+"%'";
}
return super.executeQuery(sql, Book.class, pagebean);
}
public static void main(String[] args) throws Exception {
BookDao bookDao = new BookDao();
Book book = new Book();
book.setBname("圣墟");
PageBean pagebean = new PageBean();
List<Book> list = bookDao.list2(book, pagebean);
//查询第二页
pagebean.setPage(2);
for (Book b : list) {
System.out.println(b);
}
// bookDao.list2(book, pagebean);
// 查询总记录数
System.out.println(pagebean);
}
}
封装baseDao通用分页模糊查询的方法
package com.liao.Dao;
import java.lang.reflect.Field;
import java.sql.CallableStatement;
import java.sql.Connection;
import java.sql.ResultSet;
import java.util.ArrayList;
import java.util.List;
import com.liao.enity.Book;
import com.liao.utils.DBAccess;
import com.liao.utils.PageBean;
import com.liao.utils.StringUtils;
/**
*/
public class BaseDoa<T> {
/**
* 通用Dao 利用反射机制
* @param sql
* @param cls
* @param pagebean
* @return
* @throws Exception
*/
public List<T> executeQuery(String sql,Class cls,PageBean pagebean) throws Exception{
List<T> list = new ArrayList<T>();
Connection conn = null;
CallableStatement ps = null;
ResultSet rs = null;
// select * from t_mvc_book where bname LIKE '%圣墟%'
// SELECT count(1) as n from (SELECT * FROM t_mvc_book WHERE bname LIKE '%圣墟%') t
// select * from t_mvc_book where bname LIKE '%圣墟%' LIMIT 0,10
if(pagebean !=null && pagebean.isPagination()) {
String countSQL = getcount(sql);
conn = DBAccess.getConnection();
ps = conn.prepareCall(countSQL);
rs = ps.executeQuery();
if(rs.next()){
pagebean.setTotal(rs.getObject("n").toString());
}
String pageSQL = getpage(sql,pagebean);
conn = DBAccess.getConnection();
ps = conn.prepareCall(pageSQL);
rs = ps.executeQuery();
}else {
conn = DBAccess.getConnection();
ps = conn.prepareCall(sql);
rs = ps.executeQuery();
}
while(rs.next()) {
T t =(T) cls.newInstance();
Field[] fields = cls.getDeclaredFields();
for (Field f : fields) {
f.setAccessible(true);
f.set(t, rs.getObject(f.getName()));
}
list.add(t);
}
return list;
}
/**
* 拼接最终展示数据
* @param sql 原生态sql语句
* @param pagebean
* @return
*/
private String getpage(String sql, PageBean pagebean) {
return sql+"LIMIT "+pagebean.getStartIndex()+","+pagebean.getRows();
}
/**
* 拼接出查询符合条件的总记录数sql
* @param sql
* @return
*/
private String getcount(String sql) {
// TODO Auto-generated method stub
return "SELECT count(1) as n from ("+sql+") t";
}
}
运行结果:
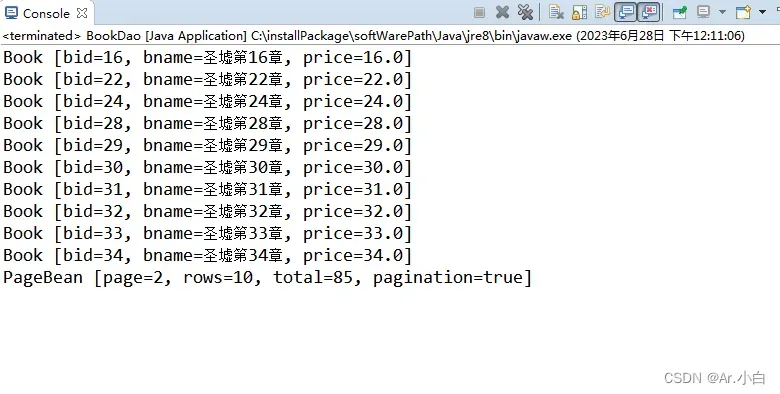
使用工具: MySQL数据库,eclipse
6.单元测试框架JUnit4
JUnit是一个广泛使用的Java单元测试框架,其最新版本为JUnit 5。
JUnit 4提供了一组基于注解的API来编写和运行单元测试。以下是JUnit 4的一些主要特点和用法:
1. 定义测试方法:通过在测试方法上添加@Test注解,可以将普通的Java方法标记为测试方法,JUnit会自动执行这些测试方法并验证预期的行为和结果。
2. 设置测试前置条件:@Before和@BeforeClass注解用于在每个测试方法和测试类之前执行指定的方法,可以用来初始化测试环境或加载测试数据。
3. 设置测试后置条件:@After和@AfterClass注解用于在每个测试方法和测试类之后执行指定的方法,可以用来清理临时数据或资源。
4. 断言和验证:JUnit提供了一组断言方法(如assertEquals、assertTrue、assertFalse等)来验证实际结果与预期结果是否一致。如果断言失败,测试将会被标记为失败。
5. 异常测试:通过在测试方法上添加@Test注解,并指定期望抛出的异常类型,可以对抛出异常的情况进行测试,确保代码在异常条件下能够正确处理。
6. 参数化测试:通过使用@RunWith(Parameterized.class)注解和@Parameters注解,可以支持参数化测试,即对同一个测试方法进行多组参数的测试。
7. 忽略测试:通过在测试方法上添加@Ignore注解,可以标记某个测试方法为忽略,JUnit将不会执行该测试方法。
除了以上的功能,JUnit 4还支持测试套件(@RunWith(Suite.class))、超时设置(@Test(timeout = xxx))、测试规则(@Rule)等高级特性,可以进行更灵活、高效的单元测试。
下面是一个简单的JUnit 4测试类的示例:
import org.junit.Test;
import static org.junit.Assert.*;
public class MyTest {
@Test
public void testAddition() {
int result = 2 + 2;
assertEquals(4, result);
}
}
```在这个示例中,我们使用@Test注解将方法testAddition标记为测试方法,并使用assertEquals断言来验证加法的结果。
以上是一些JUnit 4的主要特点和用法,JUnit 4是Java开发中非常常用的单元测试框架,它可以帮助开发者编写可靠的、自动化的测试代码来验证程序的正确性,提高代码质量和可维护性。
eclipse中使用JUnit4
第一步:选择并且需要添加JUnit4的项目
操作步骤如下:
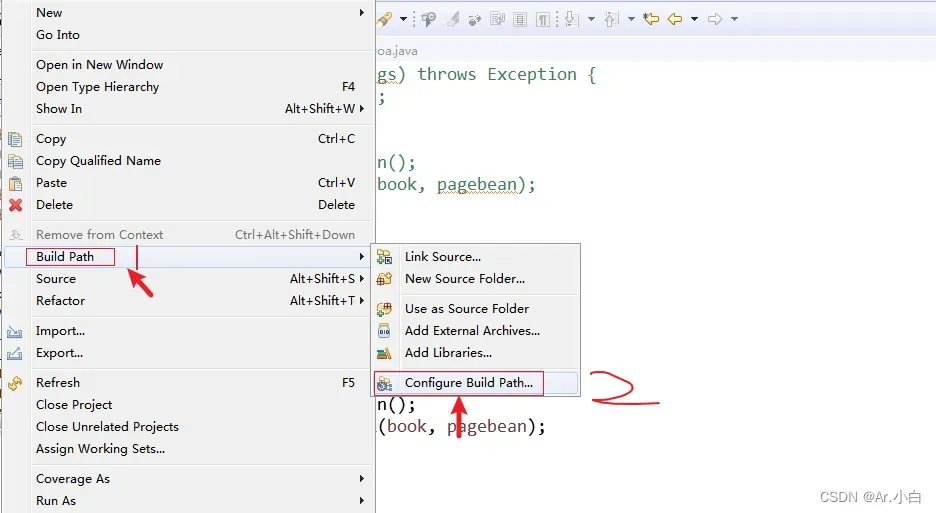
第二步:
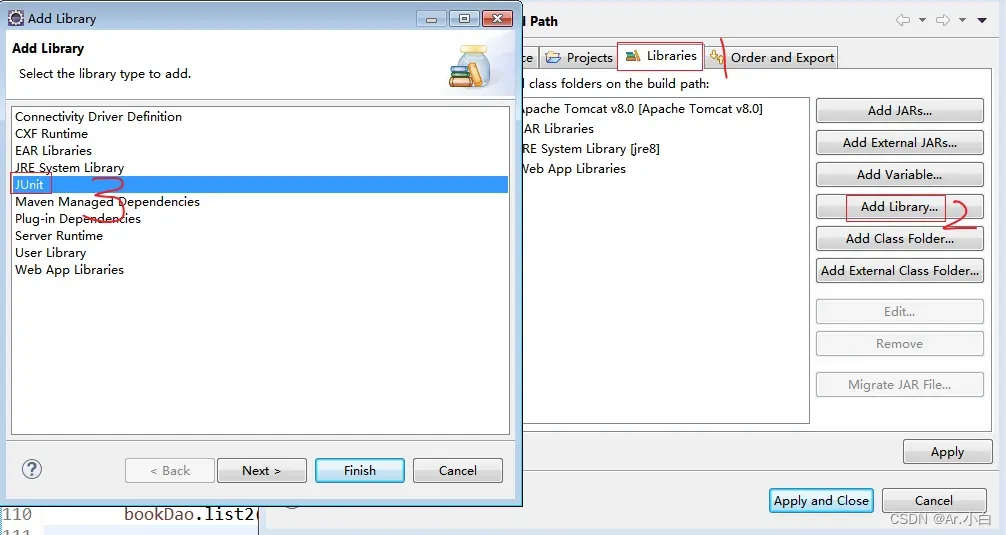
第三步:
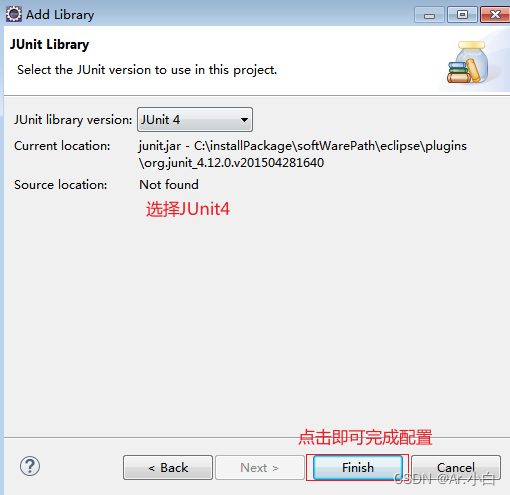
保存并且关闭即可完成
为什么是JUnit4不是JUnit5?
以下是JUnit 4和JUnit 5的一些主要对比:
编程模型:JUnit 4使用基于注解的编程模型,而JUnit 5引入了基于注解与基于扩展模型的组合。JUnit 5引入了新的注解和接口,如@Test、@BeforeAll、@AfterAll 等注解,以及TestInstance.Lifecycle等接口,帮助开发者更灵活地编写测试代码。
扩展性:JUnit 5提供了更灵活的扩展机制,支持自定义扩展,编写测试扩展可以实现更强大的测试功能,如参数化测试、条件执行等。
参数化测试:JUnit 4中参数化测试是通过使用特定的库来实现,而JUnit 5内置了参数化测试的支持,提供了更简洁、易读的语法。JUnit 5的参数化测试使用@ParameterizedTest、@ValueSource等注解,更方便地进行参数化测试。
条件执行:JUnit 5引入了@EnabledXxx与@DisabledXxx注解,可以根据条件更灵活地决定是否执行某个测试方法或整个测试类。
断言库:JUnit 5支持使用不同的断言库,不再限定于JUnit 4的断言方法。JUnit 5内置的断言方法更加灵活、易于使用,并提供了额外的功能,如展示自定义失败消息、懒加载、对比器等。
兼容性 :JUnit 4和JUnit 5的测试代码在语法上是不兼容的。JUnit 5是作为独立的框架,并且允许与JUnit 4的测试代码共存,但需要使用适配器或运行器来运行JUnit 4的测试。
并行执行:JUnit 5支持并行执行测试。可以通过在测试类上添加@Execution注解来指定并行执行的策略。
总的来说,JUnit 5在扩展性、参数化测试和条件执行等方面改进了JUnit 4,提供了更多的灵活性和功能。它还提供了更简洁、易用的断言方法和更好的兼容性。无论使用JUnit 4还是JUnit 5,都能够有效地进行Java单元测试,具体选择取决于项目需求和个人喜好。
文章出处登录后可见!