1. 背景
- 生成对抗网络通过语义丰富的潜在空间捕获和建模图像分布的能力已经改变了无数领域。但是这些模型的范围通常仅限于可以收集大量图像的领域,这一要求严重限制了它们的适用性。
- 近年来,一些研究已经对具有有限数量目标图像的预训练生成器模型进行了微调,使它们能够生成新的图像域。但是这些方法在对单个目标图像进行微调时往往会出现过拟合或欠拟合的问题。
为了解决这一问题,本文提出了一种新的通过统一的CLIP空间操作的单样本GAN自适应方法。模型能够成功地将基于大数据预先训练的模型微调到只有单个目标图像的目标域中。该模型可以生成与目标域对应的各种图像,同时保留源域的内容属性。
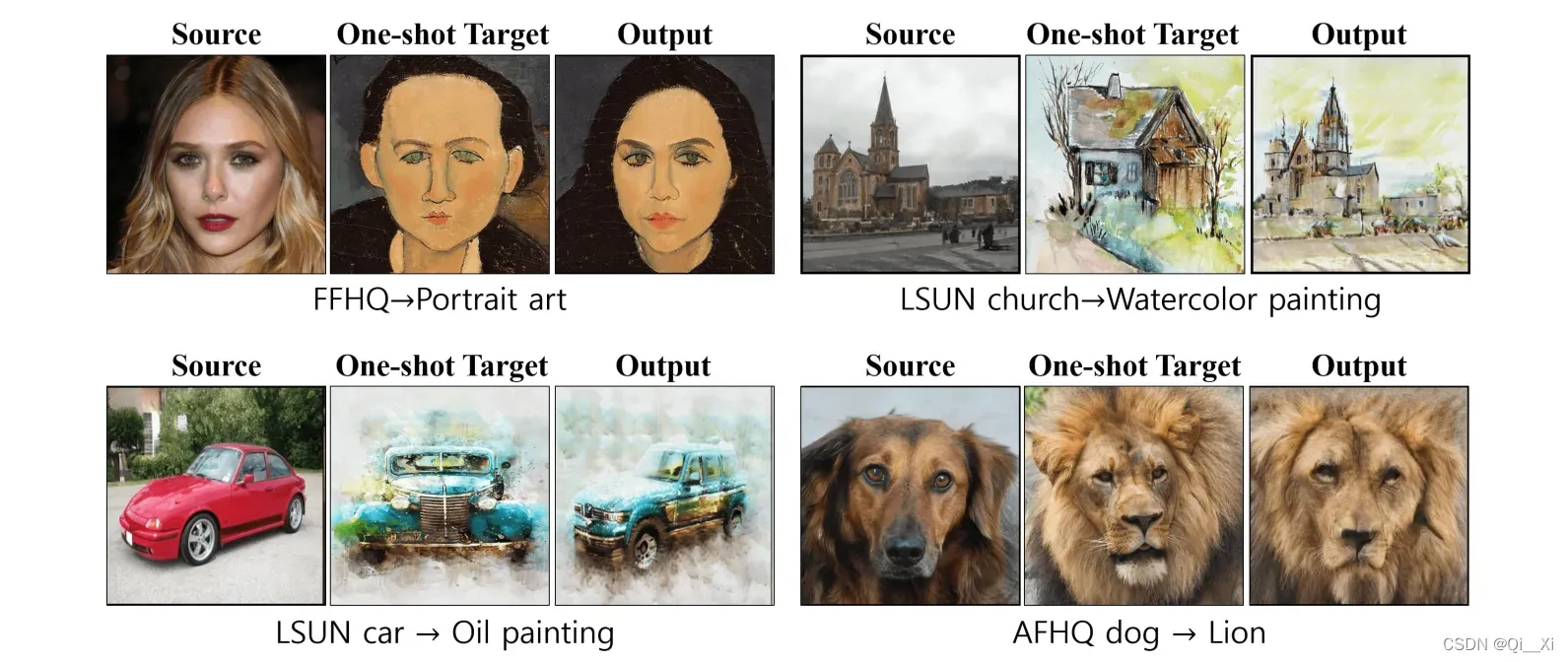
2. 方法
我们的方法包括两个步骤:
(1)在CLIP空间中找到参考图像
(2)微调模型
2.1 CLIP引导的潜在优化
第一步是CLIP引导的潜在优化,这一步是在源域生成器s的潜在空间中优化潜码
ref,以便它可以生成与给定的单个目标图像
trg最相似的参考图像
ref。下面是本文提出的CLIP引导的潜在优化概述图。
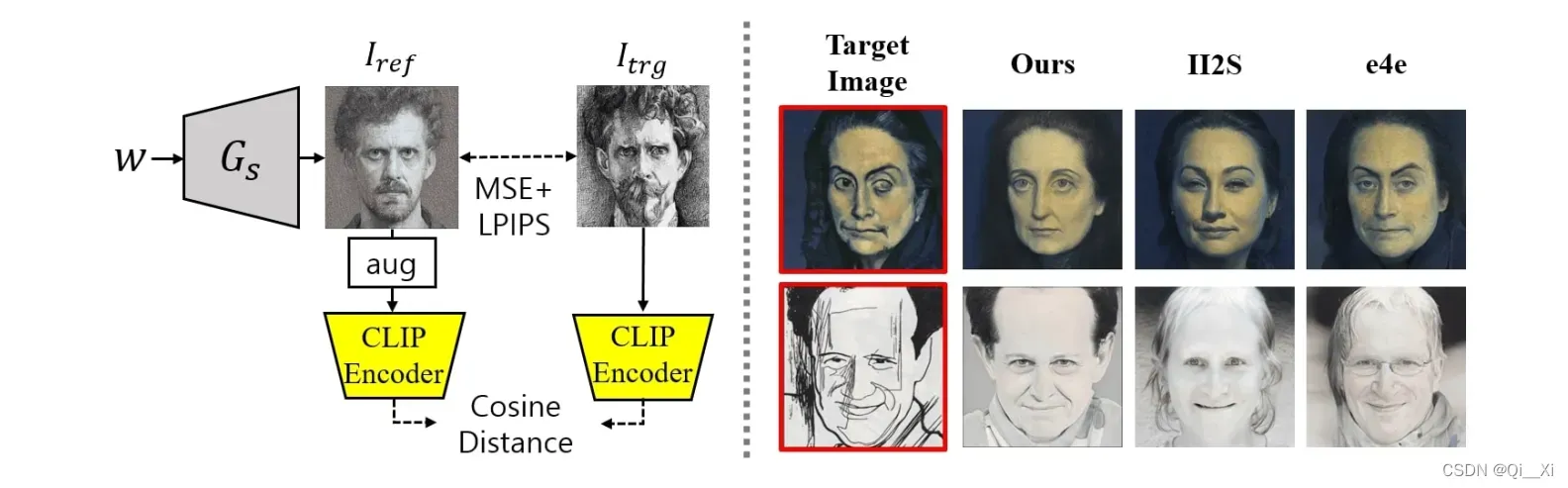
本文提出的CLIP引导优化的结果如图(右)所示。与现有的反演方法II2S和e4e相比,我们的方法得到的图像反映了目标图像的属性(如性别)。由于我们的目的是获得准确拥有目标图像属性同时表示源域的ref,因此所提出的方法更适合于生成参考。
为了找到最符合目标图像的图像,会使用II2S、e4e等反演方法,但由于这些反演模型只关注像素上的相似性,当目标图像trg的域(例如抽象草图)远离源域(例如FFHQ)时,这些模型就无法重建目标图像
trg的属性。
为了解决这一问题,本文使用预先训练的CLIP模型引导生成的参考图像ref遵循目标图像
trg的语义属性。当使用参考图像和目标图像之间的像素级损失时,本文引入了一个额外的损失,这个损失减小了两幅图像的CLIP空间嵌入之间的余弦距离。另外,我们还对参考图像
ref进行了增强以避免伪影。得到的优化问题用下面这个公式表示:
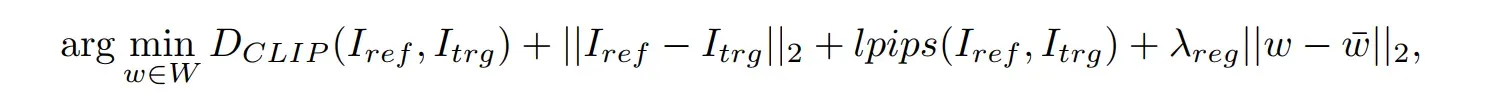
CLIP是CLIP嵌入之间的余弦距离,
是感知损失,
是源生成器
s的平均样式向量。
本文在和
之间使用
正则化来避免重建不现实的图像。此外,为了提高搜索效率,我们没有对
使用随机的起始点,而是将
作为
的起始点。经过优化步骤后,我们使用最终的潜在向量
作为参考潜码
ref。然后将得到的图像
ref作为参考点,在下一步的模型微调中与目标图像
trg进行对齐。
2.2 生成模型微调
第二步是生成模型微调。以下是本文提出的模型微调步骤的概述。

(a)CLIP空间的跨域语义一致性
在这一步,作者通过微调预训练生成器的权值来创建目标生成器t。这里使用了patch判别器,使目标生成器
t生成的图像具有目标图像
trg的纹理。但是,单独使用判别器容易导致过拟合,因此需要使用额外的正则化,使
t能够继承源模型
s的生成多样性。
具体来说,源模型s和目标模型
t以相同的潜码
生成图像,然后使用预先训练的CLIP模型获得嵌入的特征向量,并计算嵌入向量在CLIP空间中的余弦相似度得分。通过计算相似度得分,可以计算出
s和
t之间的相似度损失。两个域之间的相似度得分 (
s,
t) 通过L2回归聚合。下面这个函数就是源生成器
s和目标生成器
t的语义一致性损失:
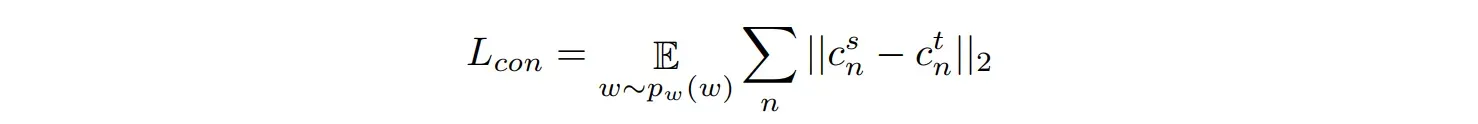
(s,
t) 分别是两个域的余弦相似度得分
(b)CLIP空间的patch语义一致性
虽然使用(a)的损失避免了过拟合的问题,但损失是对生成图像的样本语义进行正则化,所以忽略了图像的局部特征。为了更好地保持源和目标生成器之间的细节一致性,作者提出了一种新的patch一致性损失算法。
具体来说,在从s和
t生成的图像中随机位置裁剪出patch后,使用CLIP编码器嵌入图像patch。然后,减小在同一位置裁剪的正patch之间的距离,增大其他位置裁剪的负patch之间的距离。通过裁剪的patch,可以计算出patch的损失。下面这个函数就是裁剪的patch一致性损失:
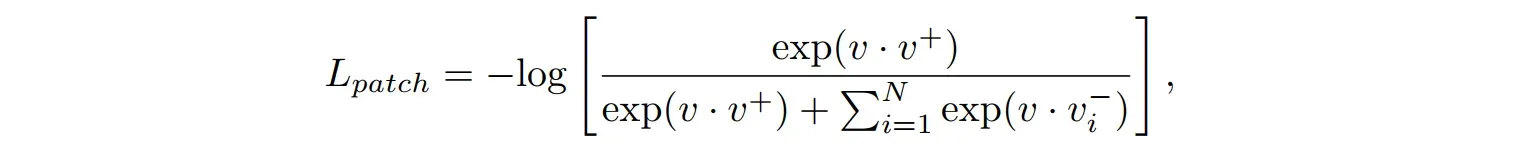
,
+为正向量,
—为负向量
(c)参考目标对齐
由于步骤1中得到的参考图像ref具有与目标图像
trg最相似的属性,并且是代表源域的图像,因此域适应的输出
t(
ref)应与目标图像
trg匹配。这里按照像素和感知角度进行匹配。另外进一步用全局判别器
glob引导
t(
ref),使图像更接近目标图像
trg。
2.3 整体训练
总的来说,网络是通过交替最小化以下两个损失来训练的。首先,当使用参考潜在变量ref时,损失定义为:
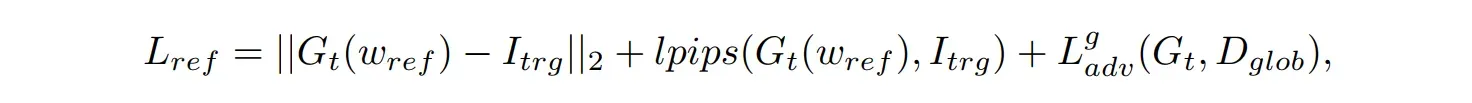
当对任意潜变量 进行采样时,损失定义为:
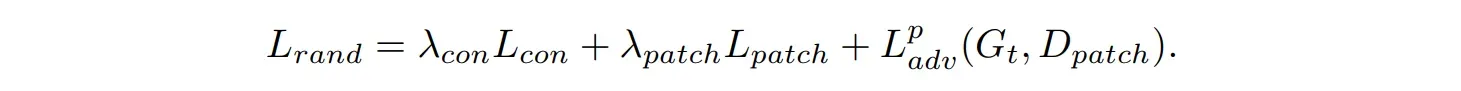
adv是StyleGAN对抗性损失,对于全局判别器,我们对预先训练的StyleGAN2判别器进行了微调。
由于同时使用两种损失进行训练会降低训练稳定性并消耗过多的内存,因此我们先只使用ref训练模型3次迭代,然后只使用
rand训练模型1次迭代。
3. 实验
3.1 与baseline模型比较
第一个实验是与baseline模型的比较结果。本文采用了三种最先进的GAN网络域适应方法作为对比模型。
(1)人脸数据集
顶行的图像是源内容图像,两侧的图像是目标图像。这些数字是四个模型生成的结果。我们的方法生成的结果包含目标图像的纹理,同时保留源图像的内容属性。

第一种方法(Few-shot adapt)生成的图像由于过拟合严重而不能反映源域的属性,也就是面部身份几乎相同。第二种方法(Style-NADA)生成的图像包含部分源域图像的内容,但模型不能准确反映目标图像的纹理。第三种方法(MIND GAP)能够在保留源域图像内容的同时生成不同的图像,但生成的图像在大多数情况下并不能很好地反映目标图像的域纹理,主要是改变全局颜色或背景等比较容易的特征,特别是当目标图像与源域存在较大差异时(例如左侧的草图),问题更加明显。本文的模型在保持源域图像内容的前提下,生成的图像能够准确反映目标图像的复杂纹理(如笔画、素描线)。
(2)其他数据集
除了人脸数据集,本文还使用教堂和汽车数据集进行对比实验。

前两种方法都存在过拟合问题。尽管它们通过一定程度上反映了源域的几何信息,生成的图像与人脸的结果相比略有不同,但图像仍然显示相同类型的汽车或形状统一的建筑物。第三种方法生成的图像具有源图像的内容信息,但模型反应的目标域风格较弱。相比之下,我们的模型充分尊重目标图像的域信息,同时保持源域的内容属性。
3.2 潜在空间编辑
本文的目的是训练一个微调的模型来生成具有目标纹理的图像,同时保留源域的潜在空间特征。为了验证这一点,作者通过属性编辑来测试模型的潜在空间是否充分包含源域的解纠缠特征。本文采用StyleCLIP中的潜在空间编辑技术,图中显示了属性编辑的实验结果。

当通过各种文本条件进行编辑时,自适应生成器t也可以生成编辑后的输出,而不会产生纠缠。这就验证了本文的自适应生成器能够保留源域的内容特征。
3.3 消融实验
本文还进行了三组消融实验,结果如图 1 所示。

第一组是去掉语义一致性损失con,由于自适应模型过拟合,生成的人脸属性具有相似的形状。第二组是去掉patch一致性损失
patch,由于源图像和输出图像的局部区域缺乏一致性,导致生成的人脸具有与源域图像不同的人脸身份。第三组是为了评估本文提出的CLIP引导优化(CLIPopt)的优越性,使用II2S作为替代来训练模型,生成的图像有部分面部属性(例如眼睛形状、胡须)没有得到正确反映。
4. 总结
本文提出了一个新框架,该框架可以通过对单个目标图像进行微调来转换预先训练的StyleGAN以生成目标域图像。关键思想是通过两步法进行CLIP空间操作。首先使用CLIP引导的潜在优化在源生成器中搜索参考图像,然后使用新的损失函数对生成器进行微调。为了进一步改进自适应模型以产生相对于源生成器的空间一致性样本,本文还提出了对CLIP空间中的patch关系的对比正则化。实验结果表明,与现有方法相比,本文提出的方法具有更好的感知质量和多样性。
本文是我结合论文主要内容和自己理解的整理,欢迎批评指正!
论文链接:https://arxiv.org/abs/2203.09301
代码链接:https://github.com/submission6378/OneshotCLIP
文章出处登录后可见!