学习时间:2022.04.09~2022.04.09
2. BP神经网络
上一节了解了感知机模型(Perceptron),当结构上使用了多层的感知机递接连成一个前向型的网络时,就是一个多层感知机(MLP,Multilayer Perceptron),是一种前馈人工神经网络模型。
单个感知机只能实现二分类问题,MLP引入了隐含层(Hidden Layer),可用于多分类。
而BP神经网络,就是在MLP的基础上,引入非线性的激活函数,加入了BP(Back Propagation,反向传播)算法,采用了梯度下降等优化算法进行参数调优的神经网络。
简单理解:BP神经网络指的是用了“BP算法”进行训练的“多层感知机模型”。
2.1 理论基础
首先,从整体上理解一下BP神经网络的实现过程(实线代表正向传播,虚线代表反向传播)。
当一个正向和反向传播完成时,神经网络的一次训练迭代就完成了。反复迭代,误差越来越小,一个完整的模型就诞生了。
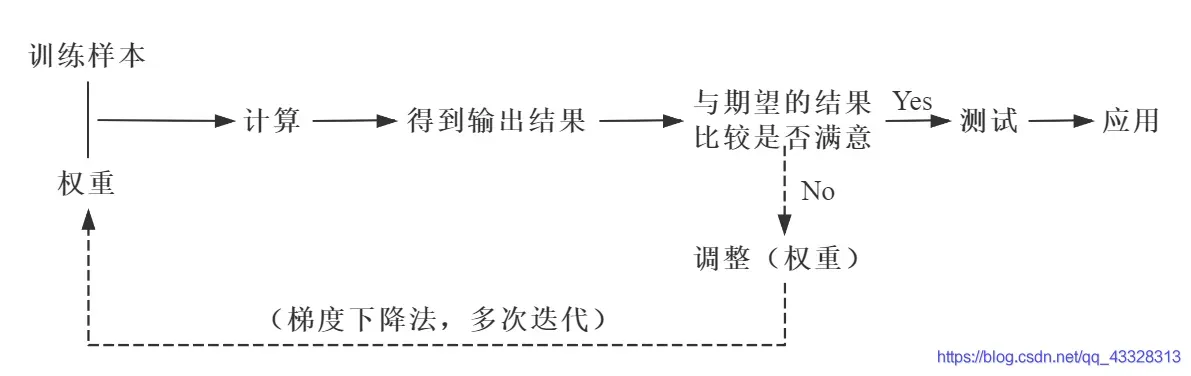
2.1.1 正向传播
数据(信息、信号)从输入端输入后,沿着网络的方向,乘以对应的权重并相加,然后将结果作为输入在激活函数中进行计算,并将计算结果传递作为下一个节点的输入。依次进行计算,直到得到最终结果。
通过每一层的感知器/神经元,层层计算,得到输出,每个节点的输出作为下一个节点的输入。这个过程就是正向传播。
2.1.2 反向传播
反向传播的基本思想是通过计算输出层与期望值之间的误差来调整网络参数,使误差变小,本质上是一个“负反馈”的过程。
通过多次迭代,网络上各个节点之间的权重不断调整(更新),权重的调整(更新)采用梯度下降学习方法。
反向传播的思想很简单,然而人们认识到它的重要作用却经过了很长的时间。后向传播算法产生于1970年,但它的重要性一直到David Rumelhart,Geoffrey Hinton和Ronald Williams于1986年合著的论文发表才被重视。
事实上,人工神经网络的威力几乎是基于反向传播算法。反向传播基于四个基本方程。数学很美。只有四个方程可以概括神经网络的反向传播过程。然而,了解这种美丽可能需要一些脑力。
2.1.3 梯度下降
在前向传播的过程中,存在与预期结果相比令人满意的环节。在这个环节中,实际输出结果与预期输出结果会有误差。为了减少这个错误,这也意味着转换为一个优化过程。
对于任何优化问题,总是会有一个目标函数 (objective function),这个目标函数就是损失函数(Loss Function)/代价函数(Cost Function)。让实际的输出结果与期望的输出结果之间的误差最小,就是利用梯度下降法原理,慢慢地寻找损失函数的最小值,从而得到模型的最终参数。
梯度下降法是一种非常重要和重要的计算方法。为了解释这种方法的原理,还涉及到另一个问题:逻辑回归。下面是一个简单的说明,只有一个图表。
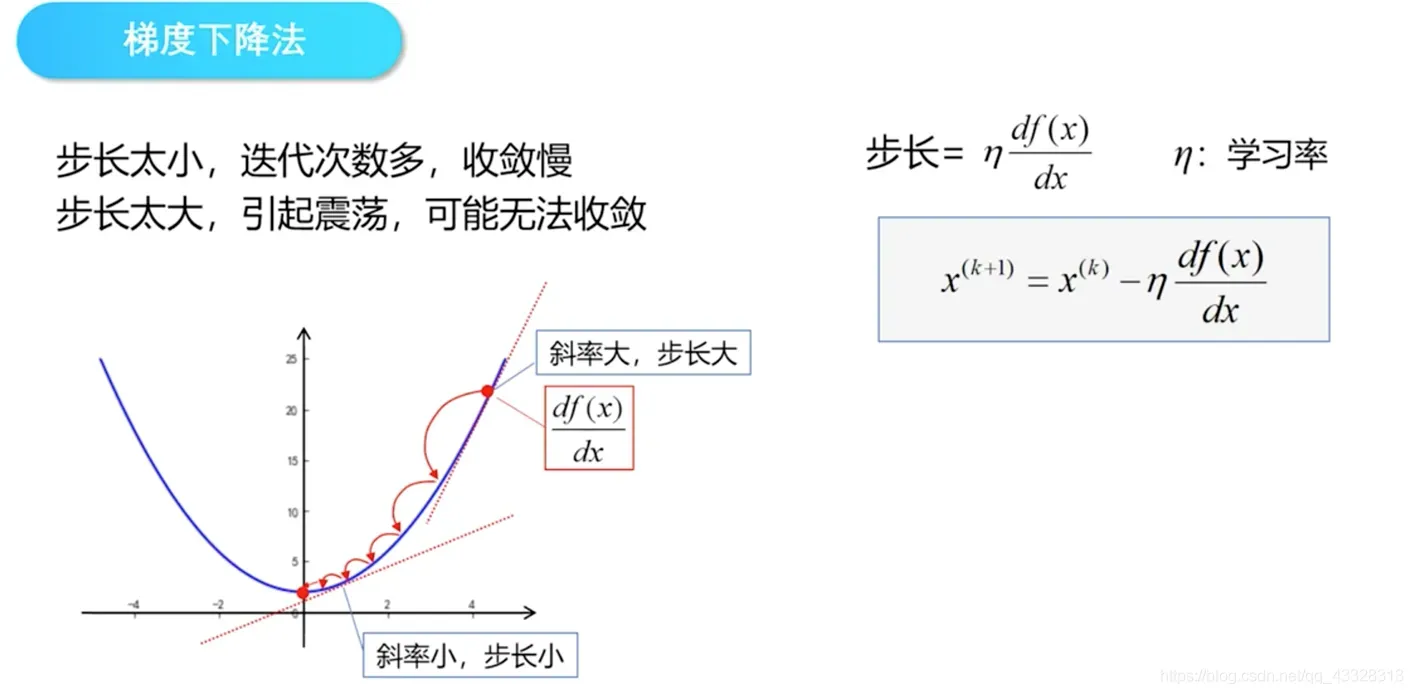
假设上图中的曲线是损失函数的图像,它有一个最小值。梯度是推导得到的值,可以理解为参数的变化。在几何意义上,梯度代表了损失函数增长最快的方向。相反,沿着相反的方向,loss可以不断逼近最小值,也就是让网络逼近真实的关系。
那么反向传播的过程就可以理解为,根据损失loss ,来反向计算出每个参数(如等的梯度
等等,再将原来的参数分别加上自己对应的梯度,就完成了一次反向传播。
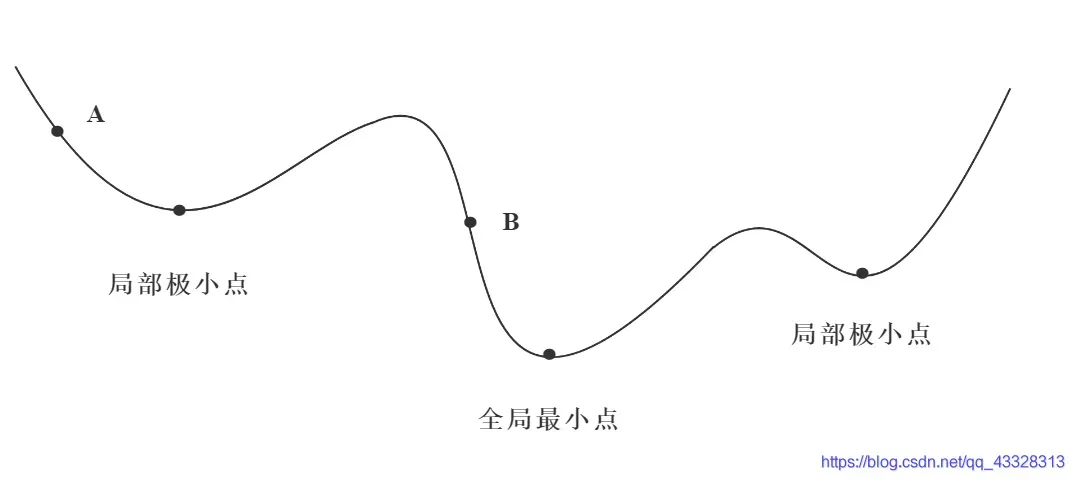
但实际中的梯度下降学习法,有些像高山滑雪运动员总是在寻找坡度最大的地段向下滑行。当他处于A点位置时,沿最大坡度路线下降,达到局部极小点,则停止滑行;如果他是从B点开始向下滑行,则他最终将达到全局最小点。
补充:逻辑回归
逻辑函数:Sigmoid函数。
可以看出,logistic函数的导函数可以转化为自身的表达式,后面用梯度下降法求解参数时会用到。
逻辑回归的原理:用逻辑函数把线性回归的结果
映射到
。(把线性回归函数的结果y,放到sigmod函数中去,就构造了逻辑回归函数。)
用一个公式描述上面的句子:
转换逻辑回归函数的过程如下:

2.2 BP算法原理
来源:一文搞定BP神经网络。
2.2.1 四个等式
首先,使用以下符号约定:
表示:网络中从
层
神经元到
层
神经元的连接权重;
表示:第
表示:
表示:第
表示:激活函数。
- 因此,
反向传播知道如何改变网络中的权重和偏差
来改变成本函数值。最终这意味着它能够计算偏导数
和
。为了计算这些偏导数,我们首先引入一个中间变量
,它表示:网络第
层第2个神经元的误差,通过反向传播计算。如果在第
层的第
个神经元上加一个扰动
,使损失函数或成本函数更小,那么它就是一个好的扰动。
与
相反。因此,每一层的误差向量可以表示为:
。下面介绍反向传播原理的四个基本方程。
- 输出层误差(
代表输出层数):
- 隐藏层错误:
- 参数变化率:
- 参数更新规则(
为学习率):
总结如下: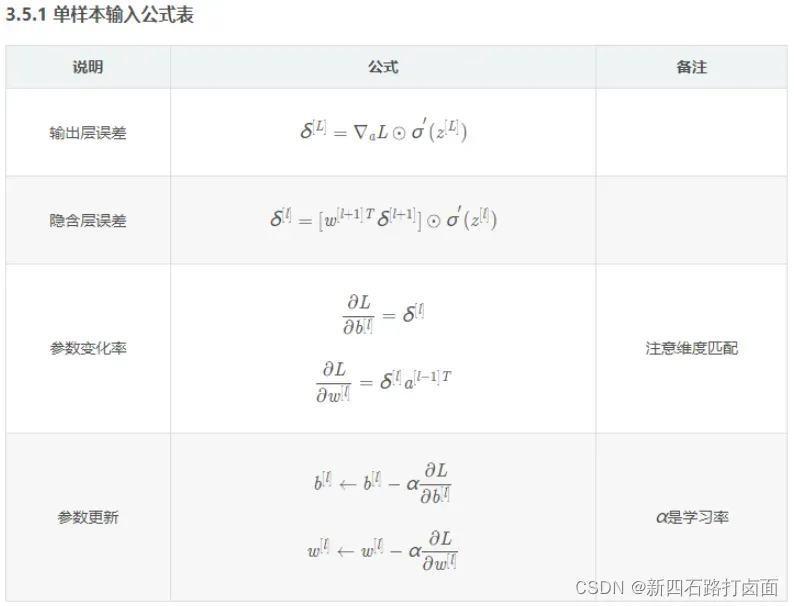
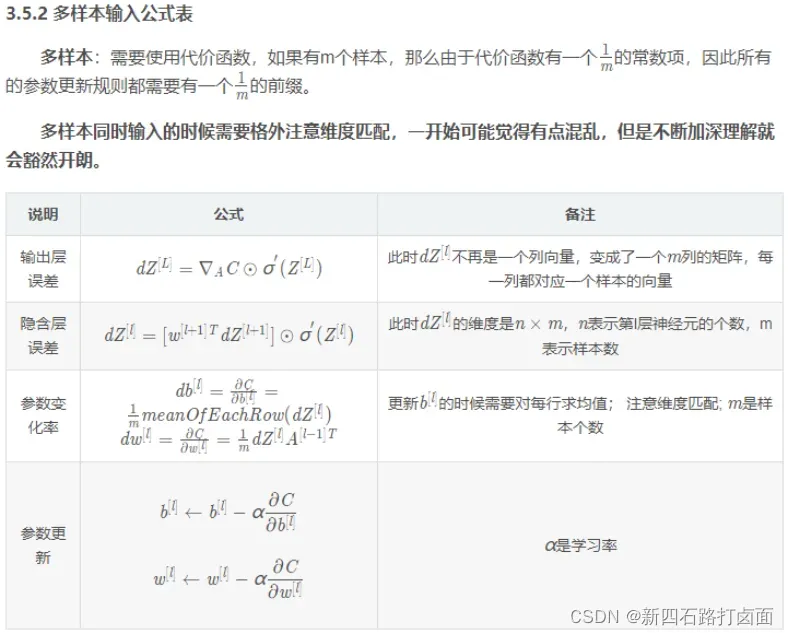
- 超参数:
神经网络模型中有些参数需要设计者给出,有些参数是模型自己解决的。
比如学习率、隐藏层的个数、每个隐藏层的神经元个数、激活函数的选择、损失函数(成本函数)的选择等等。这些需要确定的参数模型设计者称为超参数。
其他参数,如权重矩阵和偏置系数
,可以在确定超参数后通过模型计算得到。这些参数称为普通参数,或简称参数。
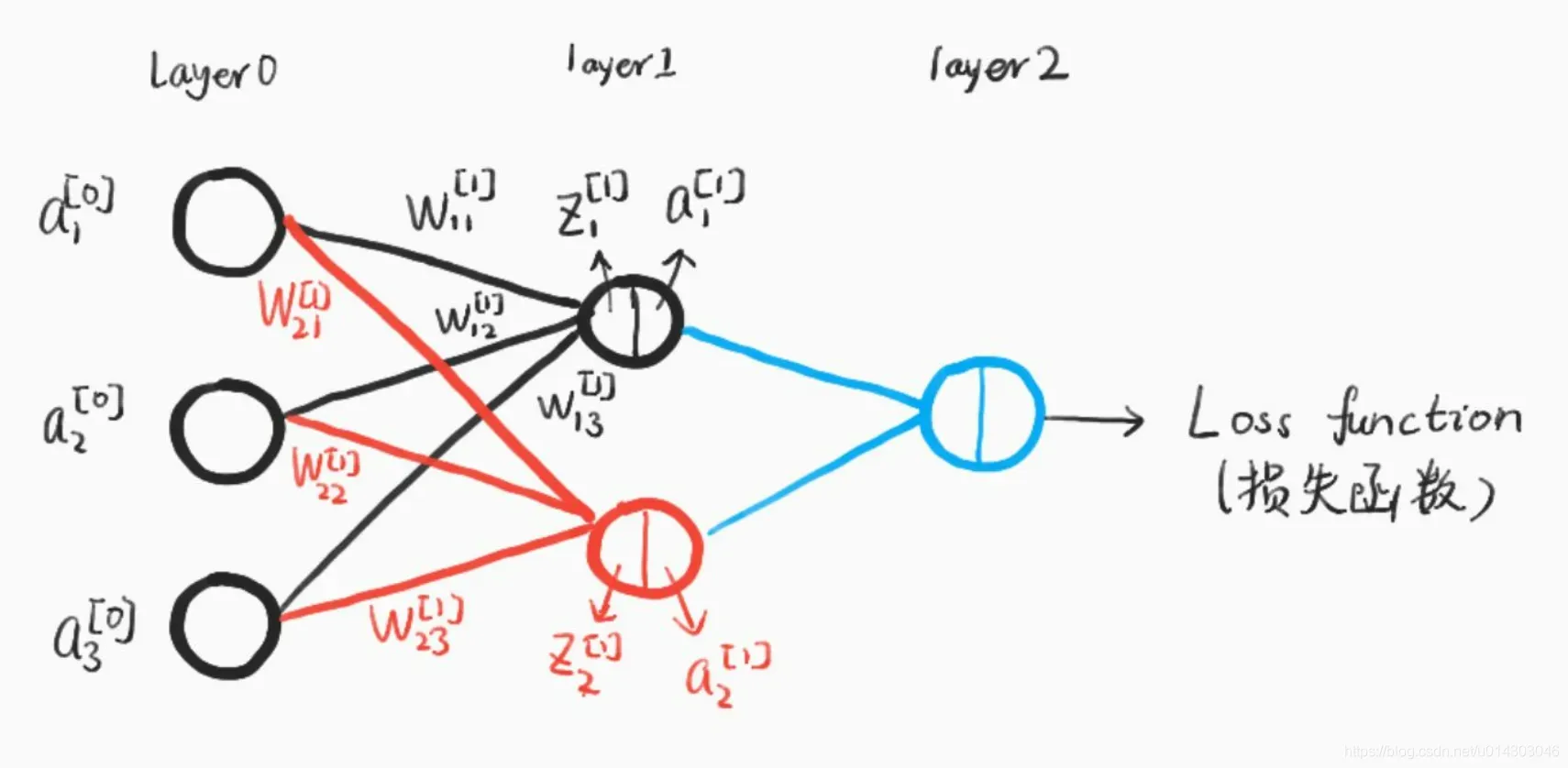
2.2.2 推导和计算
建立一个典型的三层神经网络结构,如下图:
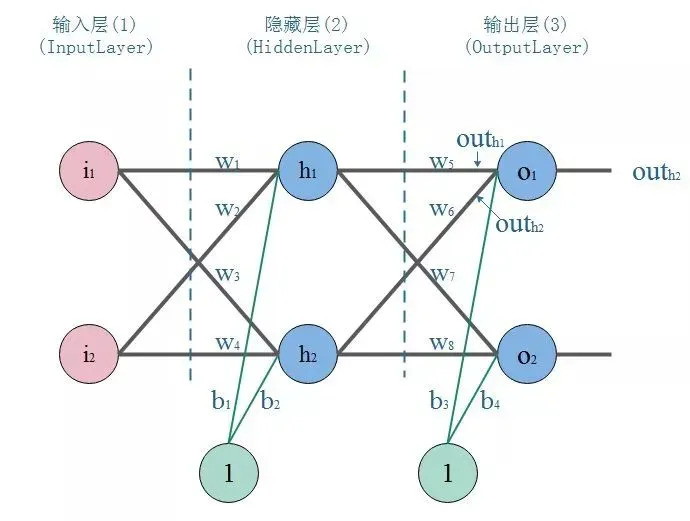
- 参数初始化:
输入:特征、
;
输出:预期结果,
;
初始重量:;
偏见:。
- 前向传播(输入层→隐藏层):
计算隐藏层神经元的输入加权和:
;
通过激活函数Sigmoid计算隐含层神经元的输出:
;
同理,计算隐藏层神经元的输出:
。
- 前向传播(隐藏层→输出层):
计算输出层神经元的输入加权和:
;
计算输出层神经元的输出:
;
同理,计算隐藏层神经元的输出:
。
- 比较输出结果:
输出层的输出结果:,预期结果
,差距明显过大。这时候我们需要使用反向传播,更新权重
,然后重新计算输出。
- 反向传播(计算输出错误):
此处使用均方误差(MSE)作为损失函数:;
PS:使用均方误差(MSE)作为例子,是因为计算比较简单,实际上用的时候效果不怎么样。
如果激活函数饱和,缺点是系统迭代更新变慢,系统收敛慢。当然,有办法弥补这一点。一种方法是使用交叉熵函数作为损失函数。
作为代价函数,交叉熵可以实现上述优化系统的收敛,因为它在计算误差对输入的梯度时抵消了激活函数的导数项,从而避免了激活函数的“饱和”。对系统产生负面影响。
- 反向传播(更新隐藏层的权重
→输出层,以
为例):
我们知道,权重的大小能直接影响输出,
不合适会使得输出存在误差。要想直到某一个
值对误差影响的程度,可以用误差对该
的变化率来表达。如果
的一点点变动,就会导致误差增大很多,说明这个w对误差影响的程度就更大,也就是说,误差对该
的变化率越高。而误差对
的变化率就是误差对
的偏导。
因此,根据链式法则:。
依次计算:、
、
;
留置权:;
因此,的更新值为:
,
的值可以用同样的方法计算。
- 反向传播(更新隐藏层的偏置
→输出层,以
为例):
同理,更新偏差,有:,和:
。
留置权:;
因此,的更新值为:
,同理,可以计算出
的更新值。
- 反向传播(更新输入层→隐藏层的权重
为例):
仔细观察,我们在求的更新,误差反向传递路径输出层→隐层,即out(O1)→in(O1)→w5,总误差只有一根线能传回来。但是求
时,误差反向传递路径是隐藏层→输入层,但是隐藏层的神经元是有2根线的,所以总误差沿着2个路径回来,也就是说,计算偏导时,要分开来算。
即:,结果为:
。
因此,的更新值为:
,
的值可以用同样的方法计算,偏差
的值也可以用同样的方法计算。
偏差和权重可以使用不同的学习率,每一层之间可以使用不同的学习率。
到此,计算出所有更新的权重和偏置,完成了1次迭代训练,可以重新进行第二次正向传播。随着迭代的次数加深,输出层的误差会越来越小,模型趋于收敛。
文章出处登录后可见!