Nearest Neighbors 是 KNN、Optics、DBSCAN、HDBSCAN 和 SMOTE 的基础
穿越最近邻及其衍生算法的旅程

有多种算法建立在其他算法的基础上。以下文章重点介绍最近邻 (NN),其他模型在其概念或代码之上利用和创新。
无监督最近邻
让我们从基础模型开始,即在 Scikit 中实现的无监督最近邻模型。此算法用于判断您的训练数据中的实例是否与您正在测量的点最接近。它是用于计算 NN 的不同算法的接口,例如 BallTree、KDTree。如下所示,它继承了 KNeighborsMixin、RadiusNeighborsMixin、NeighborsBase。[0]


K-最近邻
继续使用 K 最近邻进行分类,每个数据科学家都会遇到这种情况,并使用上述方法并根据其 K 个邻居确定未见过的样本是否属于某个类别。[0]
如下代码所示,KNN 继承了相同的基类“NeighborsBase、KNeighborsMixin 和 RadiusNeighborsMixin”,但顺序不同;在文档中,它在内部对 fit() 使用 NeighborsBase 实现,对 predict() 使用 KNeighborsMixin。[0]


DBSCAN
继续讨论 DBSCAN,这是一种基于密度的聚类算法。简单来说,DBSCAN 会发现高密度样本的集群。我们可以在这里找到 DBSCAN 的代码,我们已经可以在文档中看到 DBSCAN 的内部算法指向 NN 模块。[0][1]
深入挖掘,我们看到 DBSCAN 的代码在内部使用了“NearestNeighbors”模块,如下面快照中 DBSCAN 的 fit() 函数代码和文档所示。[0]
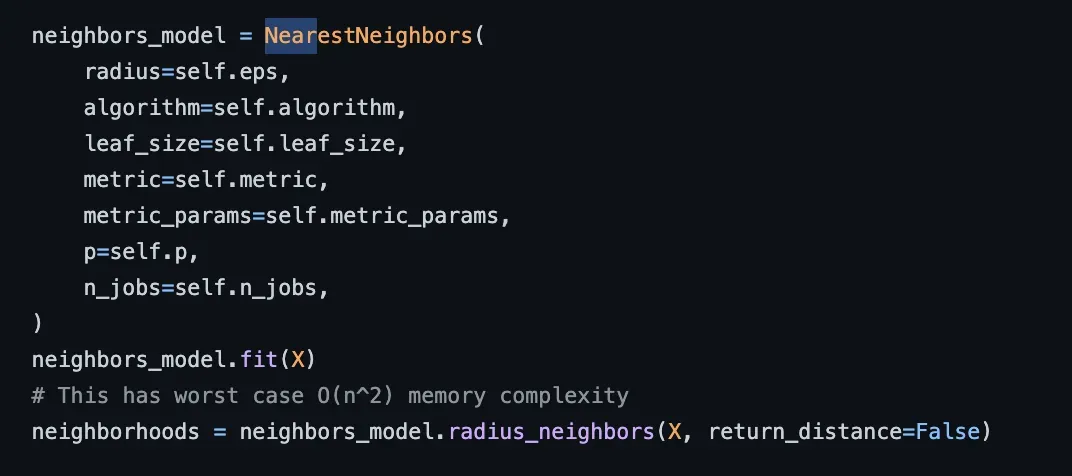

Optics
光学与 DBSCAN 密切相关,类似地,它发现高密度区域并从中扩展集群,但是,它使用基于半径的集群层次结构,Scikit 建议在更大的数据集上使用它。 Optics 的这种实现在所有点上使用 k-最近邻搜索[0]
查看 repo 内部,我们看到 Optics 的代码在内部依赖于“NearestNeighbors”模块及其算法,如下面的 Optics compute_optics_graph() 函数代码和文档快照所示。[0]
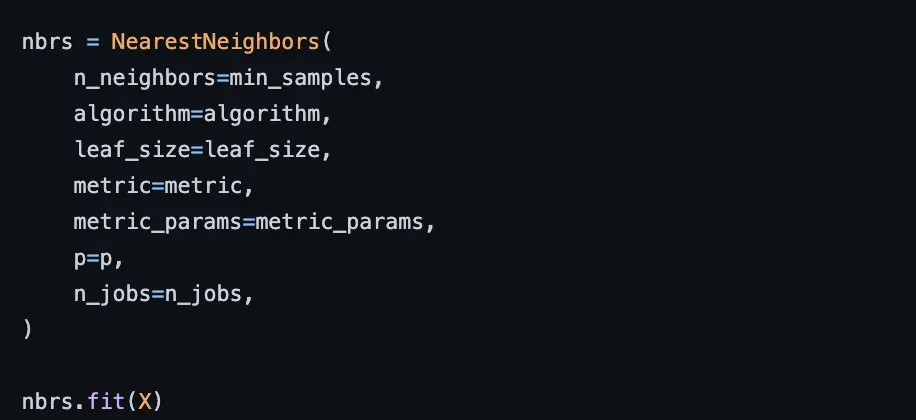

HDBSCAN
HDBSCAN 通过将 DBSCAN 转换为层次聚类算法来扩展 DBSCAN,然后在顶部使用平面聚类提取。[0]
我们可以在 API 参考和代码中看到一些指向 KNN 的线索[0][1]

深入代码我们可以看到,在下面的代码中,函数 _rsl_prims_balltree 实际上是基于 BallTree,而 _rsl_prims_kdtree 是基于 KDTree,它们是 Scikit-learn 中用于计算 NN 的算法。
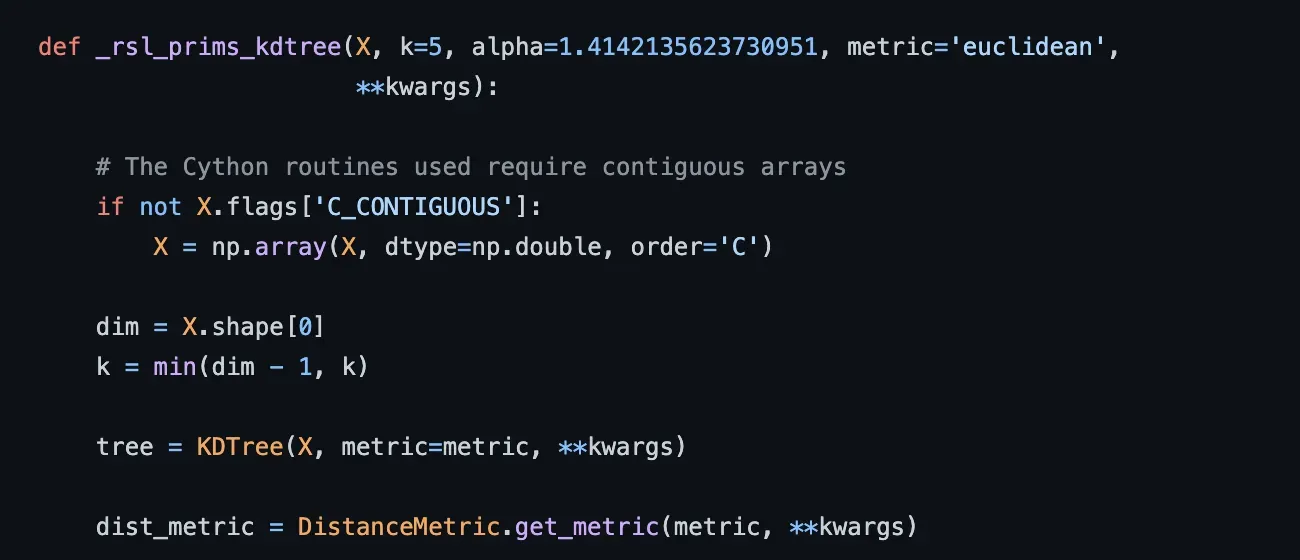
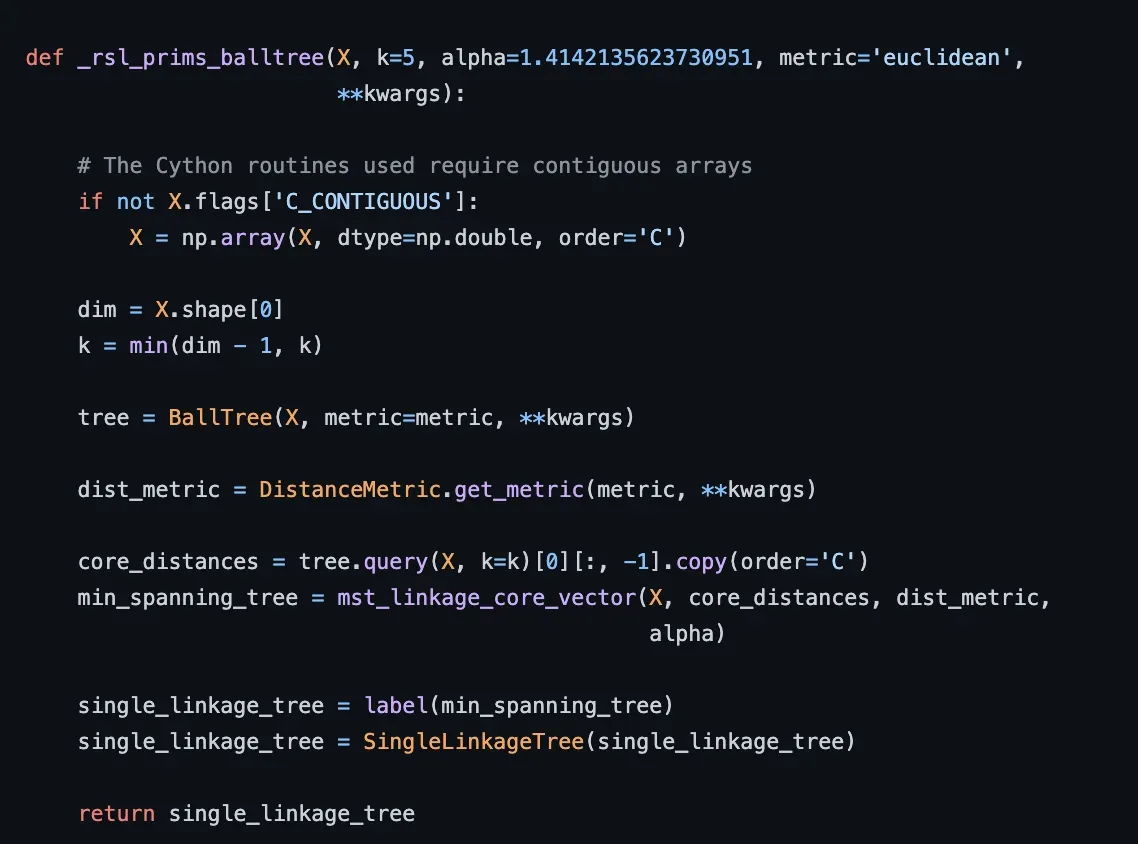
SMOTE
Synthetic Minority Over-sampling algorithm (SMOTE) 的 Imbalance-learn 实现,它不直接使用 Scikit-learn NN 类实现,但确实使用了 NN 概念。我们可以一瞥代码和文档,并立即发现 generate_samples() 函数中的 k_neighbors 参数。[0][1]

Summary
最近邻算法,由 Evelyn Fix、Joseph Hodges 等人开发。人。在 1951 年,后来在 1967 年由 Thomas Cover 扩展,对于上述所有实现都至关重要。我们还可以看到,Scikit-learn 的各种算法实现都在重用该代码,并且各种其他软件包都使用了 NN 算法,以便为我们带来更高级的模型。[0][1][2]
我真的希望这篇评论能让你了解所有这些算法之间的联系和关系,并希望帮助你使用众多算法方法解决更多问题。
[1] 修复,伊芙琳;霍奇斯,约瑟夫 L. (1951)。判别分析。非参数判别:一致性属性 (PDF)(报告)。美国空军航空医学院,德克萨斯州伦道夫菲尔德。[0]
[2] 封面,托马斯 M.;哈特,彼得 E. (1967)。 “最近邻模式分类”(PDF)。 IEEE交易[0][1][2]
Ori Cohen 博士拥有博士学位。计算机科学专业,专注于机器学习。他是 ML & DL Compendium 和 StateOfMLOps.com 的作者,对 AIOps & MLOps 领域很感兴趣。他是 Justt.ai 的数据和数据科学高级总监。[0][1]
文章出处登录后可见!