可视化集群结果的最佳实践
集群可视化和解释的成熟技术
聚类是数据科学中最流行的技术之一。与其他技术相比,它很容易理解和应用。但是,由于集群是一种无监督的方法,因此您很难确定业务客户可以理解的不同集群。
Goal
本文为您提供下一个集群项目的可视化最佳实践。您将学习分析和诊断集群输出、使用 PaCMAP 降维正确可视化集群以及展示集群特征的最佳实践。每个可视化都附带其代码片段。您可以将本文用作参考指南。
由于我上一篇关于集群的文章已经介绍了一些技术细节和解释,所以我将在这里简短地解释。[0]
集群选择和诊断
让我们从头开始。在分析任何聚类特征之前,您必须准备数据并选择适当的聚类算法。为简单起见,我们将使用众所周知的葡萄酒数据集并使用 K-Means 模型。尽管如此,本文中显示的大多数可视化可用于任何聚类算法。[0]
上面的代码加载 wine 数据集并使用 StandardScaler 缩放整个数据集。
为了确保我们集群的后续可视化始终使用正确且相同的颜色,我们定义了六种不同颜色的列表(图 1)。

确定正确的 k 簇数
有几种方法可以确定(视觉上)正确的集群数量。下面我们将使用肘图法、(平均)轮廓评分法和轮廓分析法。
弯头法
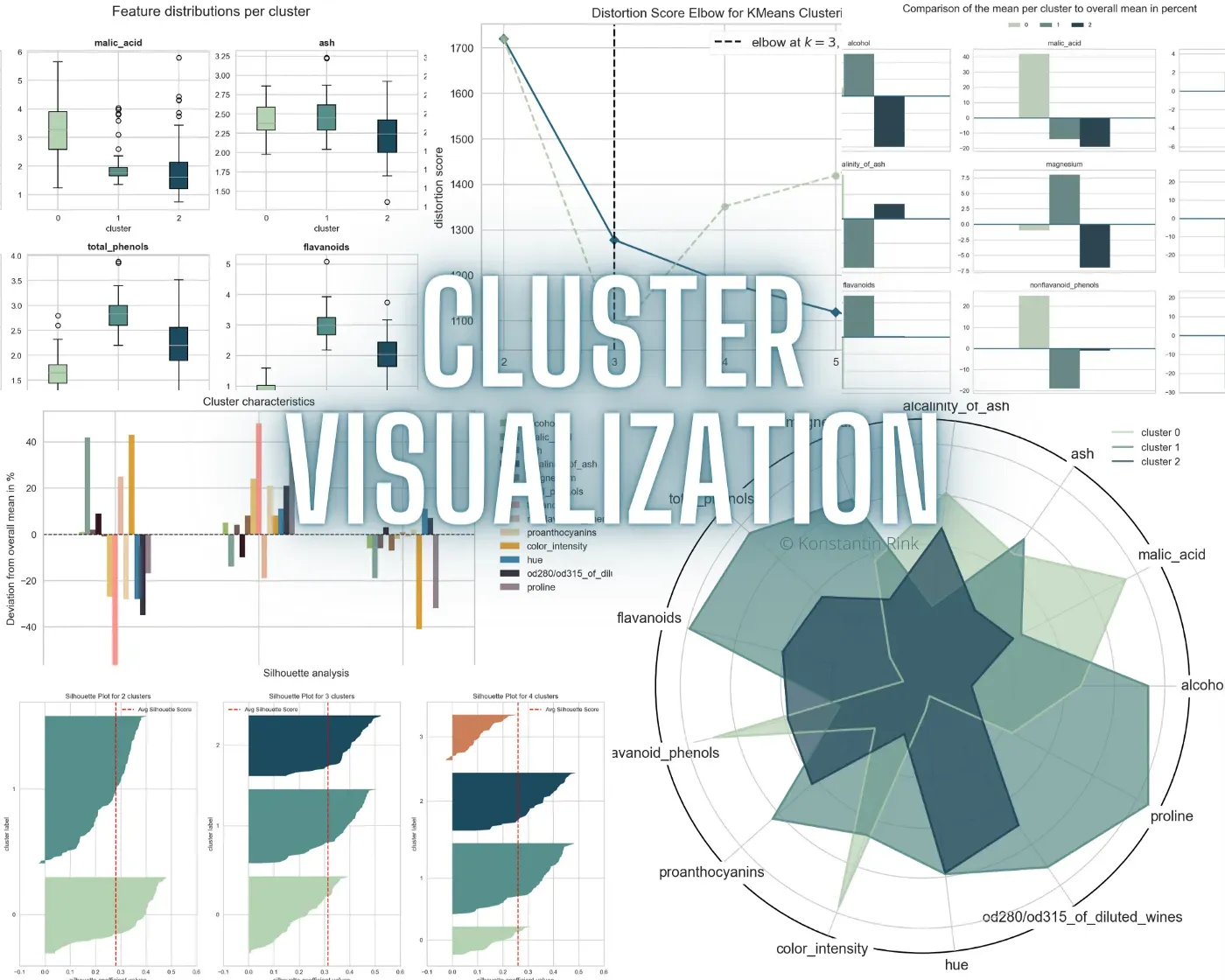
为了获得肘部图的全面和适当的可视化,我建议使用 Yellowbrick 包 pip install yellowbrick 。以下代码将生成图 2 所示的绘图。[0]
输出还绘制了一个建议(虚线),您应该选择哪个 k。如果无法确定正确的数字,则会显示警告。
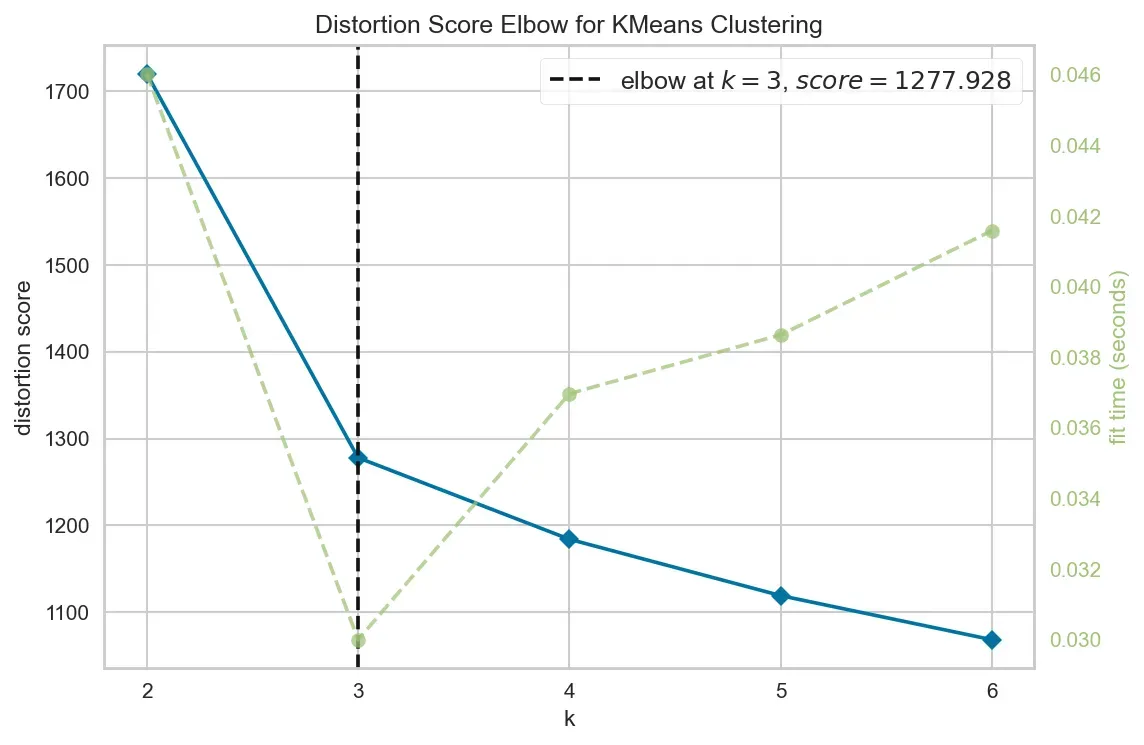
剪影得分
确定聚类数量的另一种方法是轮廓评分法。下面的代码绘制了图 3 中的输出。
得出的结果 (3) 等于肘图法得出的结果。
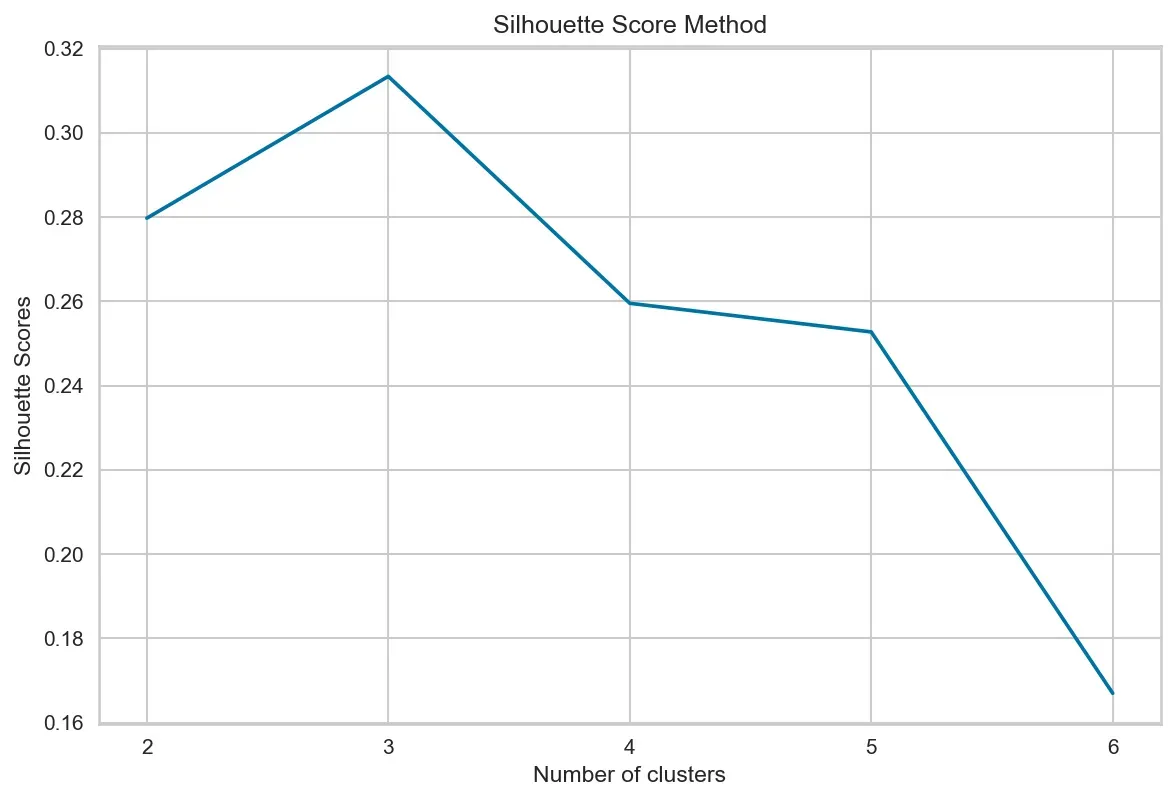
轮廓分析
最后但并非最不重要的一点是,我们可以使用轮廓分析方法来确定最佳聚类数。这篇 sklearn 文章很好地解释了这个想法和方法。[0]
上述文章中提供的代码每行绘制一个轮廓图。但是,当您拥有大量集群并想要比较它们相关的剪影图时,这可能会非常不清楚。因此,我编写了下面的代码,每行绘制三个图表,这使得后面的比较(图 4)更加清晰。
在尝试了几种方法来直观地确定 k 集群的正确数量后,我们决定继续使用 k=3 并构建我们的集群。
集群诊断
下一步是根据它们的大小和基数来诊断我们的集群。
如果您不熟悉这些术语,请查看我的文章。[0]
要创建以下图(图 5),我们将使用 data-science-utils 包,可以使用 pip install data-science-utils 安装。[0]
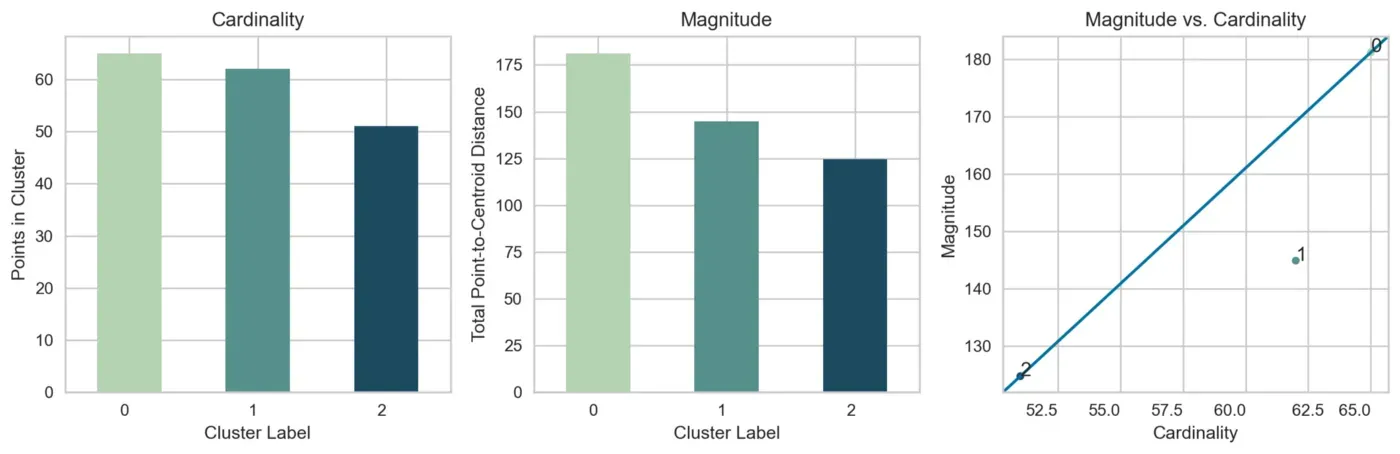
集群可视化
为了在 2D 空间中可视化我们的集群,我们需要使用降维技术。许多文章和教科书都使用 PCA。最近的博客文章还推荐了 t-SNE 或 UMAP 等方法。但是,也存在一些误区和误解。
简而言之:在使用这些降维方法时,要在保留局部结构和保留全局结构之间进行权衡。虽然 PCA 保留了全局结构,但它不保留邻域或局部结构。另一方面,t-SNE 和 UMAP 保留局部结构而不是全局结构。
但是,有一种相对较新的技术声称可以保留局部和全局结构:PaCMAP。
下面将使用 PCA 和 PaCMAP 在 2D 空间中可视化我们的集群。
如果您想了解有关不同特征和 PaCMAP 的更多信息,请查看 Mathias Gruber 的为什么不应该依赖 t-SNE、UMAP 或 TriMAP。[0]
运行代码后,您应该得到以下图(图 6):
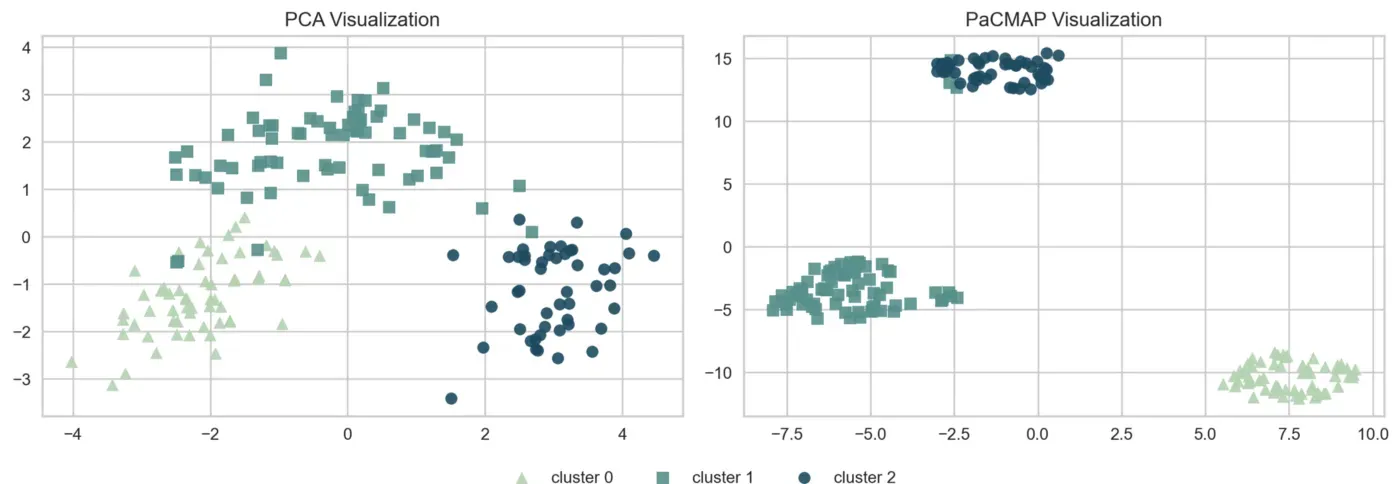
集群特征
现在让我们关注如何可视化和呈现每个集群的关键特征,以便业务人员可以轻松理解每个集群代表什么。
在我们这样做之前,我们必须使用集群列来丰富我们的标准化 (X_std) 和非标准化 (X) 数据。
Boxplots
第一种也是非常简单的方法是为每个特征生成一个箱线图,以显示它在每个集群中的分布。
为了绘制下面的结果(图 7),我们使用了非标准化数据 X。使用标准化数据 (X_std) 的绘制结果对于业务用户来说更难解释,因为它的规模和单位已经改变。
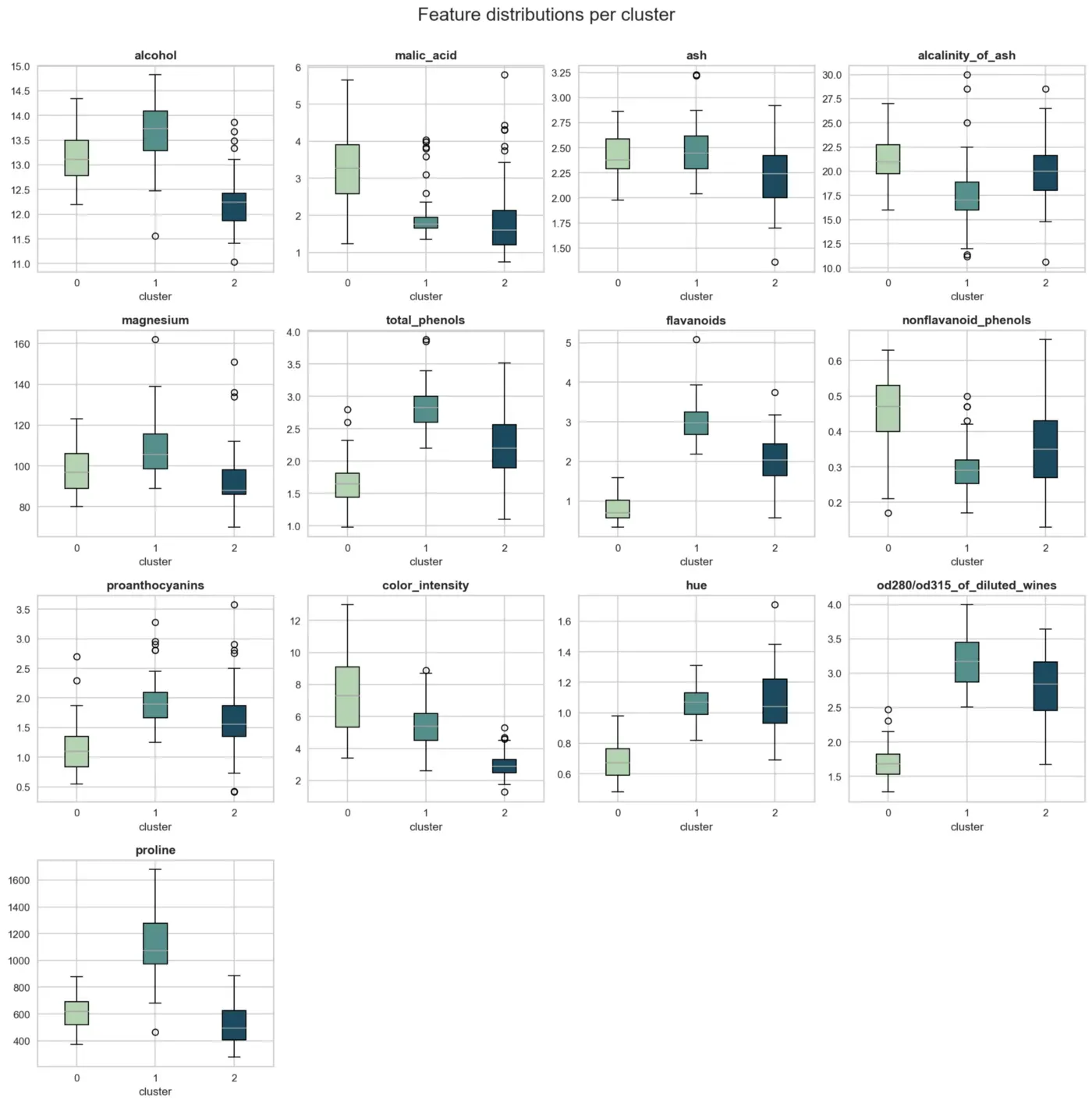
数据准备
在继续之前,我们必须为以下可视化准备数据。下面的代码帮助我们更好地比较我们的集群。
首先,我们计算每个集群的每个特征的平均值(X_mean,X_std_mean),这与上面的箱线图非常相似。
其次,我们计算每个集群的每个特征与每个特征(X_dev_rel,X_std_dev_rel)的总体平均值(与集群无关)的相对差异(以 % 为单位)。这有助于读者了解每个集群中的差异与每个特征的总体平均值相比有多大。
图 8 展示了 X 示例,我们的数据在准备步骤之后的样子。
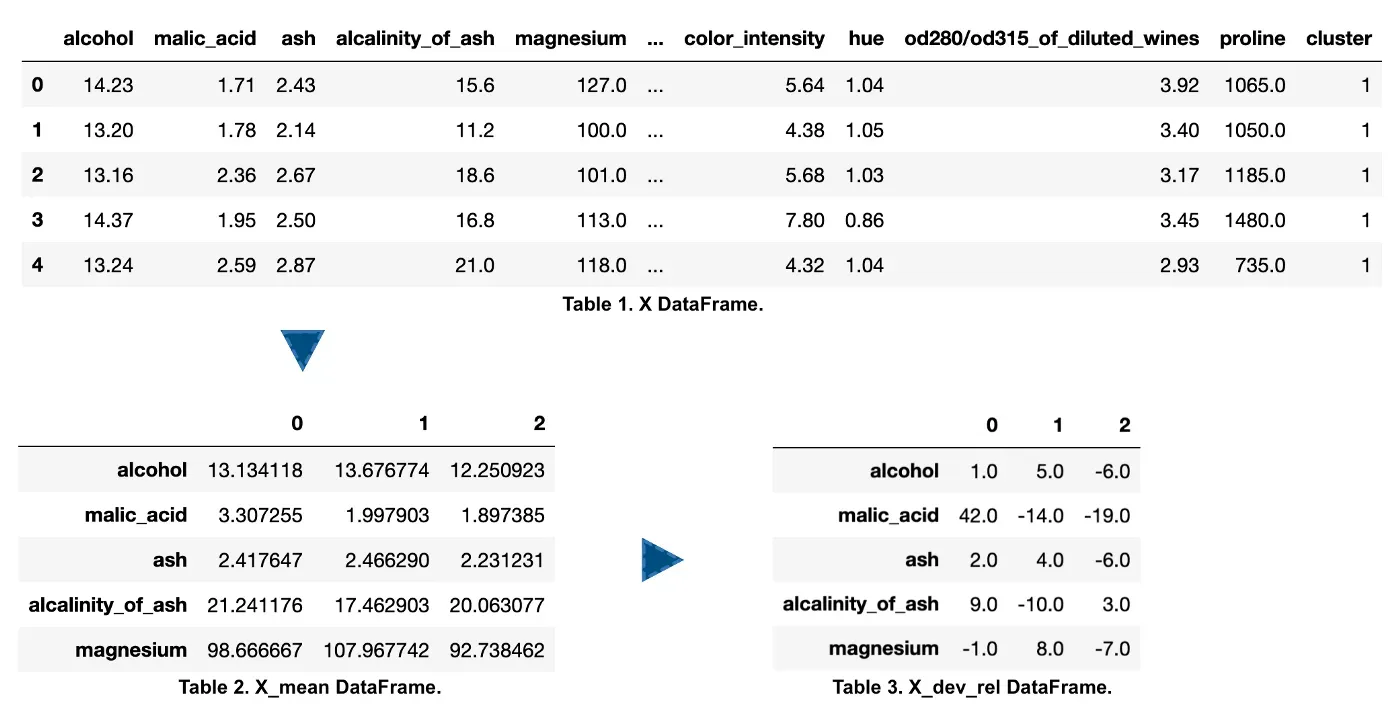
现在我们的数据形状正确,我们可以继续进行可视化。
条形图
为了可视化相对差异,我们可以使用条形图。以下代码绘制了每个特征的每个集群的差异。
import matplotlib.patches as mpatches
def cluster_comparison_bar(X_comparison, colors, deviation=True ,title="Cluster results"):
features = X_comparison.index
ncols = 3
# calculate number of rows
nrows = len(features) // ncols + (len(features) % ncols > 0)
# set figure size
fig = plt.figure(figsize=(15,15), dpi=200)
#interate through every feature
for n, feature in enumerate(features):
# create chart
ax = plt.subplot(nrows, ncols, n + 1)
X_comparison[X_comparison.index==feature].plot(kind='bar', ax=ax, title=feature,
color=colors[0:X.cluster.nunique()],
legend=False
)
plt.axhline(y=0)
x_axis = ax.axes.get_xaxis()
x_axis.set_visible(False)
c_labels = X_comparison.columns.to_list()
c_colors = colors[0:3]
mpats = [mpatches.Patch(color=c, label=l) for c,l in list(zip(colors[0:X.cluster.nunique()],
X_comparison.columns.to_list()))]
fig.legend(handles=mpats,
ncol=ncols,
loc="upper center",
fancybox=True,
bbox_to_anchor=(0.5, 0.98)
)
axes = fig.get_axes()
fig.suptitle(title, fontsize=18, y=1)
fig.supylabel('Deviation from overall mean in %')
plt.tight_layout()
plt.subplots_adjust(top=0.93)
plt.show()
cluster_comparison_bar(X_dev_rel, cluster_colors, title="Comparison of the mean per cluster to overall mean in percent")结果如下图 9 所示。
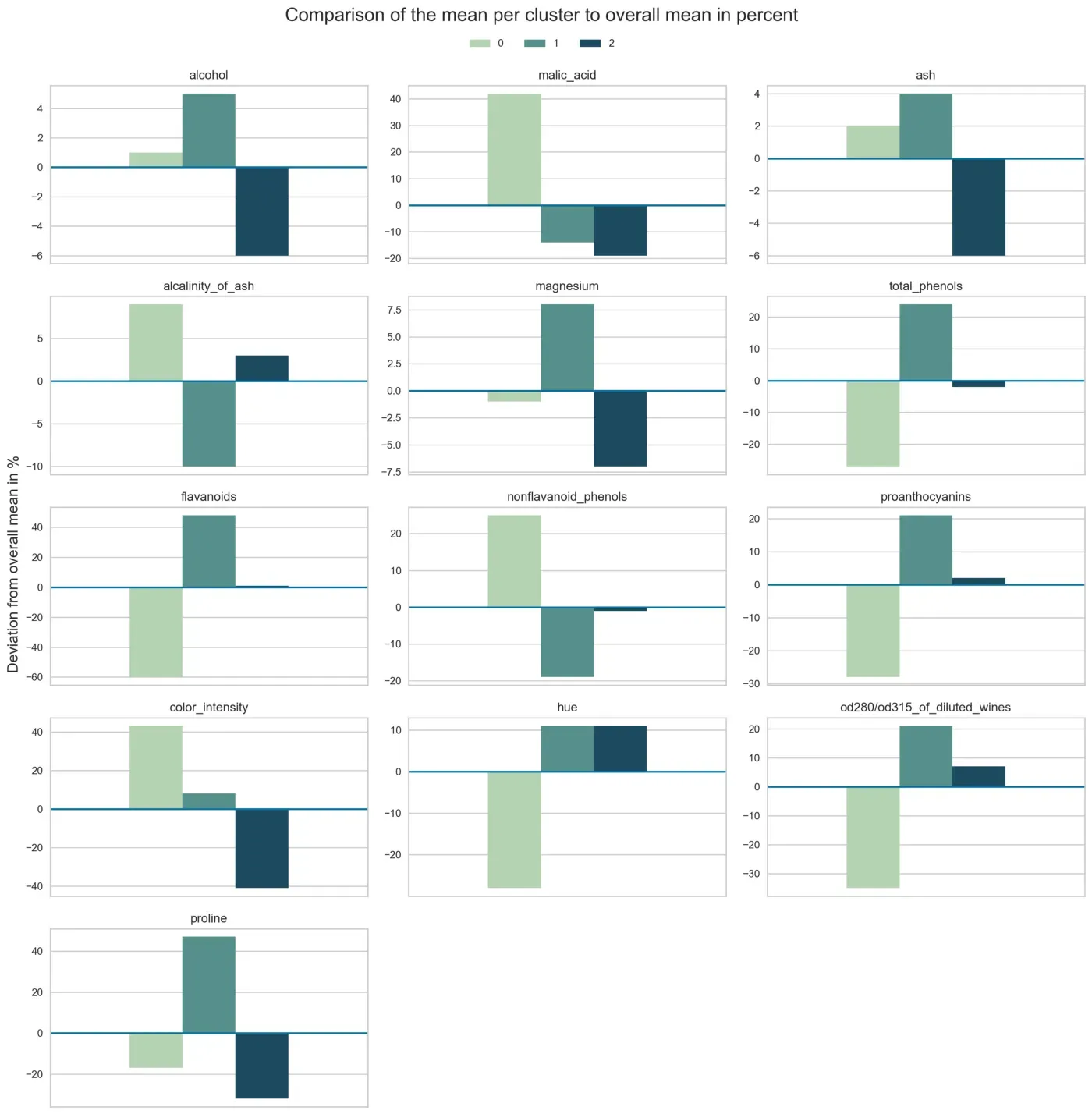
如果您想显示每个集群的详细信息,上面的图表非常棒。然而,在许多情况下,在一张图表中总结所有相关结果和特征也是有意义的。下面的解决方案是一种方法。
colors = ['#9EBD6E','#81a094','#775b59','#32161f', '#946846', '#E3C16F', '#fe938c', '#E6B89C','#EAD2AC',
'#DE9E36', '#4281A4','#37323E','#95818D'
]
fig = plt.figure(figsize=(10,5), dpi=200)
X_dev_rel.T.plot(kind='bar',
ax=fig.add_subplot(),
title="Cluster characteristics",
color=colors,
xlabel="Cluster",
ylabel="Deviation from overall mean in %"
)
plt.axhline(y=0, linewidth=1, ls='--', color='black')
plt.legend(bbox_to_anchor=(1.04,1))
fig.autofmt_xdate(rotation=0)
plt.tight_layout()
plt.show()我们在图 10 中可视化了每个特征与其每个集群的总体平均值的相对偏差。
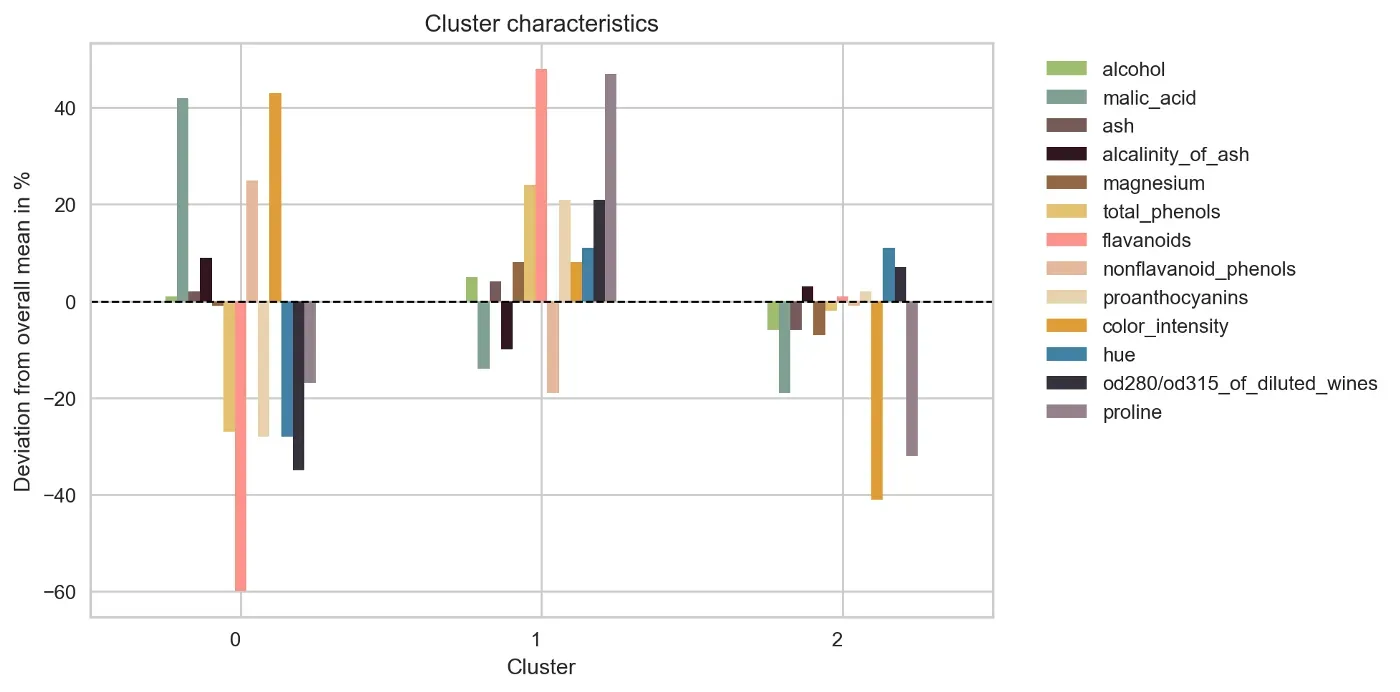
雷达图
在一个图中总结所有相关信息的另一种方法是使用雷达图。下面的代码绘制了我们标准化数据 (X_std_mean) 的计算平均值。
class Radar(object):
def __init__(self, figure, title, labels, rect=None):
if rect is None:
rect = [0.05, 0.05, 0.9, 0.9]
self.n = len(title)
self.angles = np.arange(0, 360, 360.0/self.n)
self.axes = [figure.add_axes(rect, projection='polar', label='axes%d' % i) for i in range(self.n)]
self.ax = self.axes[0]
self.ax.set_thetagrids(self.angles, labels=title, fontsize=14, backgroundcolor="white",zorder=999) # Feature names
self.ax.set_yticklabels([])
for ax in self.axes[1:]:
ax.xaxis.set_visible(False)
ax.set_yticklabels([])
ax.set_zorder(-99)
for ax, angle, label in zip(self.axes, self.angles, labels):
ax.spines['polar'].set_color('black')
ax.spines['polar'].set_zorder(-99)
def plot(self, values, *args, **kw):
angle = np.deg2rad(np.r_[self.angles, self.angles[0]])
values = np.r_[values, values[0]]
self.ax.plot(angle, values, *args, **kw)
kw['label'] = '_noLabel'
self.ax.fill(angle, values,*args,**kw)
fig = plt.figure(figsize=(8, 8))
no_features = len(km.feature_names_in_)
radar = Radar(fig, km.feature_names_in_, np.unique(km.labels_))
for k in range(0,km.n_clusters):
cluster_data = X_std_mean[k].values.tolist()
radar.plot(cluster_data, '-', lw=2, color=cluster_colors[k], alpha=0.7, label='cluster {}'.format(k))
radar.ax.legend()
radar.ax.set_title("Cluster characteristics: Feature means per cluster", size=22, pad=60)
plt.show()如果我们使用非标准化版本,不同的比例会破坏可视化(例如,脯氨酸的平均值远高于灰分的平均值)。因此,我建议使用相同的单位或至少在相似的值范围内绘制值。最终结果如图 11 所示。
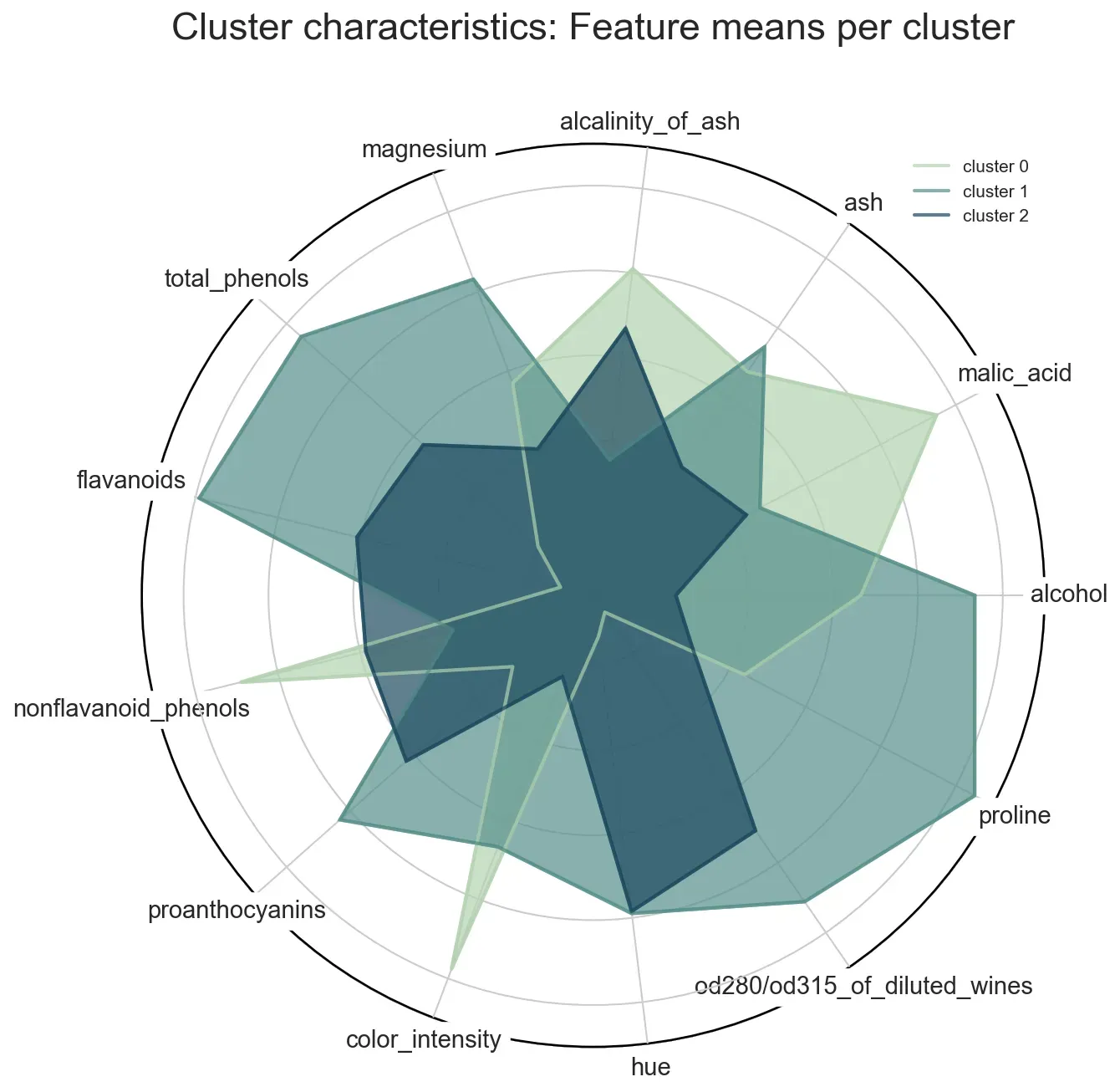
Conclusion
本文的目的是为您提供集群诊断、可视化和解释方面的最佳实践。在 2D 空间中绘制集群时考虑使用 PaCMAP。可以从不同的角度呈现聚类结果或特征。一个想法是显示每个集群的每个特征的平均值。另一种选择是计算每个集群的每个变量与每个特征的总体平均值的相对差异。在向企业展示您的结果时,最好使用一个图(例如,显示的雷达图或第二个条形图)。如果您想研究每个集群的每个功能的特征(例如,与 UX 设计师进行深入探讨),您可以使用多个图。
Sources
UCI 机器学习存储库:Wine 数据集。 “知识共享署名 4.0 国际 (CC BY 4.0) 许可”。[0][1]
Yingfan Wang、Haiyang Huang、Cynthia Rudin、Yaron Shaposhnik,了解降维工具的工作原理:解密 t-SNE、UMAP、TriMAP 和 PaCMAP 以实现数据可视化的经验方法(2020 年),https://arxiv.org/abs /2012.04456[0]
文章出处登录后可见!