原文标题:An LSTM-Based Deep Learning Approach for Classifying Malicious Traffic at the Packet Level
原文作者:Ren-Hung Hwang * , Min-Chun Peng, Van-Linh Nguyen and Yu-Lun Chang
发表会议:IEEE ICASI 2019
原文链接:https://www.mdpi.com/2076-3417/9/16/3414
中文标题:一种基于LSTM的包级恶意流量分类的深度学习方法
1 Motivation
最近,深度学习已成功应用于网络安全评估和入侵检测系统 (IDS),并取得了多项突破,例如使用卷积神经网络 (CNN) 和长短期记忆 (LSTM) 对恶意流量进行分类。然而,由于基于流的数据预处理的时间开销,这些最先进的系统也面临着满足实时分析要求的巨大挑战,即需要时间将数据包累积到特定流中然后提取特征。如果恶意流量检测可以在包级别进行,检测时间将大大减少,这使得基于深度学习技术的在线实时恶意流量检测变得非常有前景。
综上所述,作者希望在达到一定检测精度的同时,实现包级别的恶意流量检测,以达到实时检测的目的。
2 论文主要工作
- 提出了一种基于 LSTM 的深度学习方法,用于 IDS中的数据包级分类。该方法可以通过数据包区分恶意流量的语义,与基于流的深度学习方法相比具有很强的竞争力,同时显着减少了流处理时间。
- 提出了一种新颖的词嵌入和 LSTM 模型来将传入的数据包分为正常和异常状态。提出的模型在ISCX2012、USTC-TFC2016、Robert Gordon大学的物联网数据集和我们的 Mirai bonet上收集的物联网数据集的评估结果表明,在检测恶意数据包方面可以达到接近 100% 的准确度和精度。
- 对基于数据包的深度学习分类和检测的讨论有望提供有价值的信息并激励研究界克服剩余的挑战,特别是加快基于 DL 的 IDS 检测过程的目标。
3 数据集
- ISCX2012。 ISCX2012 包含 7 天收集的数据包。第一天和第六天收集的数据包是正常流量。第二天和第三天,收集正常报文和攻击报文。第4天、第5天、第7天,除了正常流量外,分别收集HTTP DoS、DDoS和IRC Botnet、Brute Force SSH数据包。
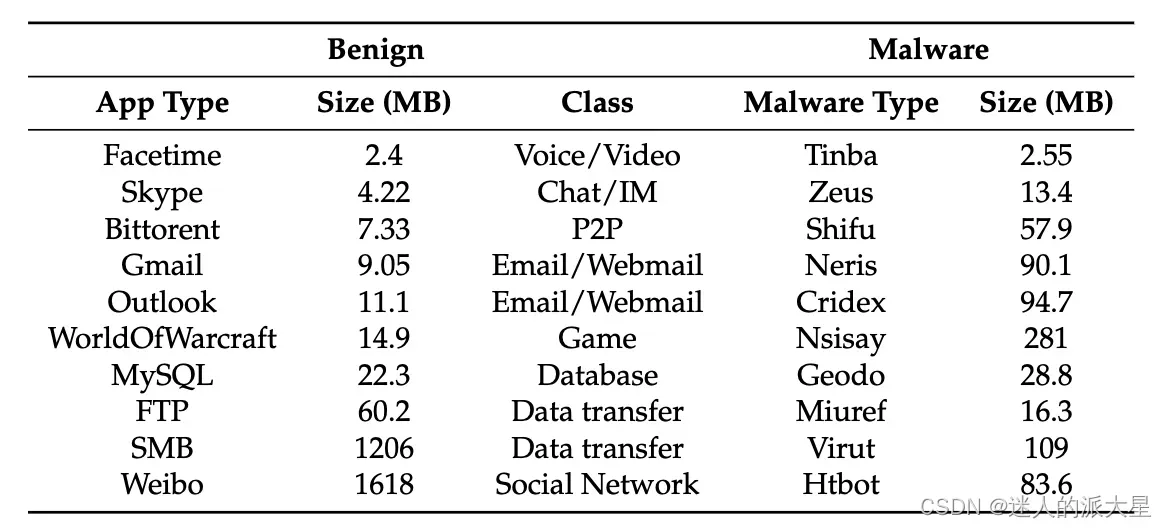
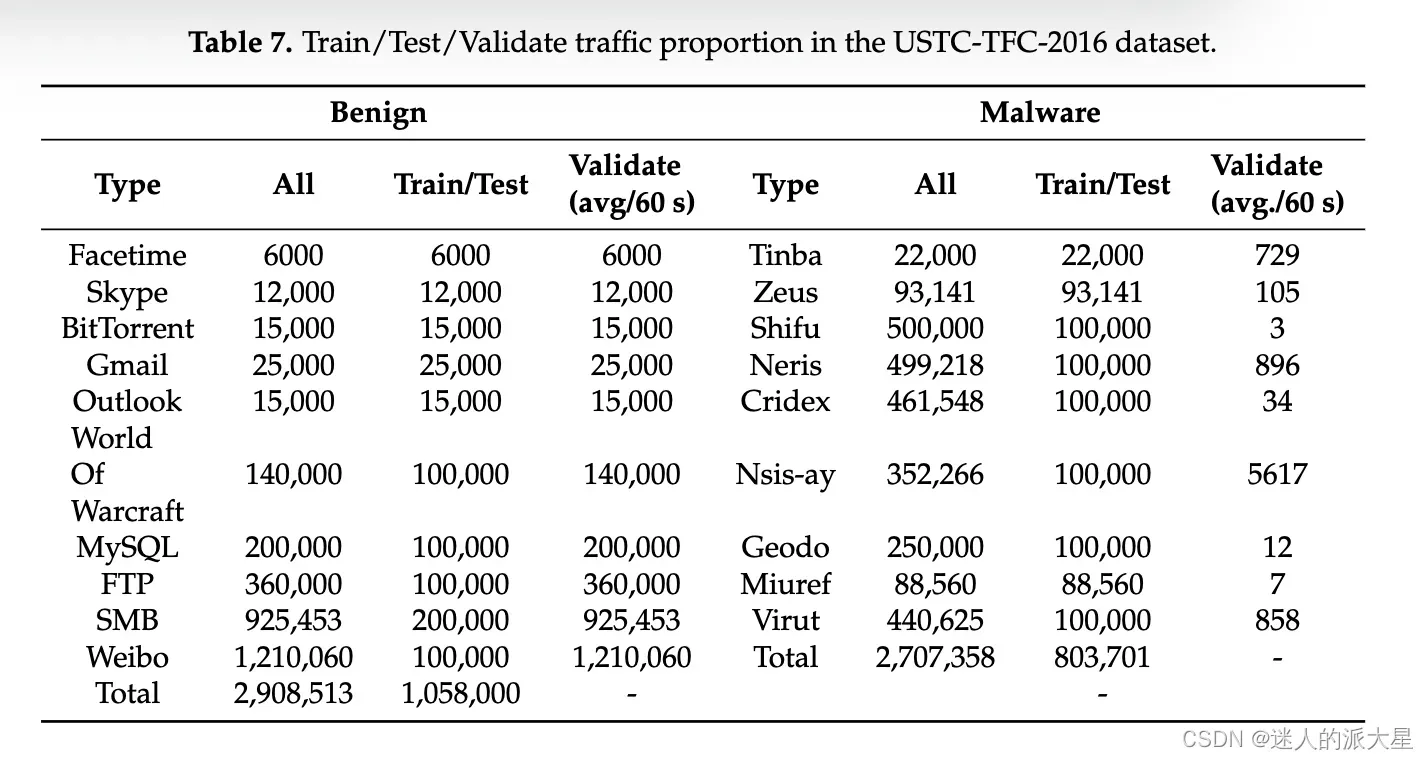
- USTC-TFC2016(SMB:服务器消息块;IM:即时消息;P2P:点对点)
- Mirai-RGU(Robert Gordon大学公开的数据集)。该数据集包含 Mirai 僵尸网络流量,例如扫描、感染、控制、攻击流量和正常的物联网 IP 摄像机流量。它包含十种恶意流量,包括HTTP Flood、UDP Flood、DNS Flood、Mirai流量、VSE Flood、GREIP Flood、GREETH Flood、TCP ACK Flood、TCP SYN Flood和UDPPLAIN Flood。数据集包括时间、源、目的地、协议、长度和整体有效载荷信息。
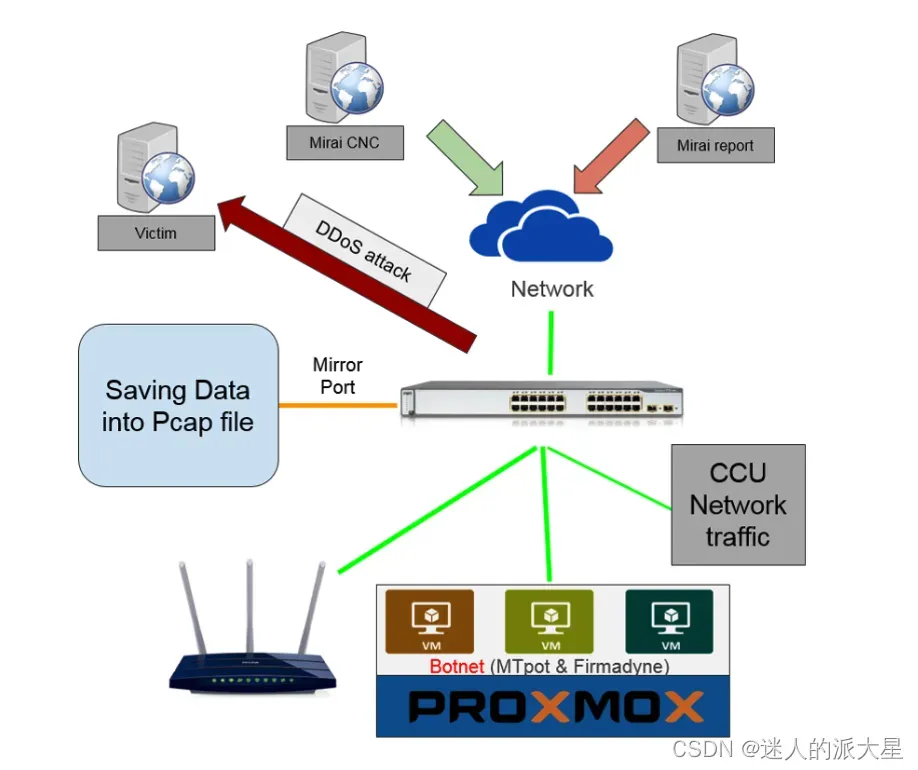
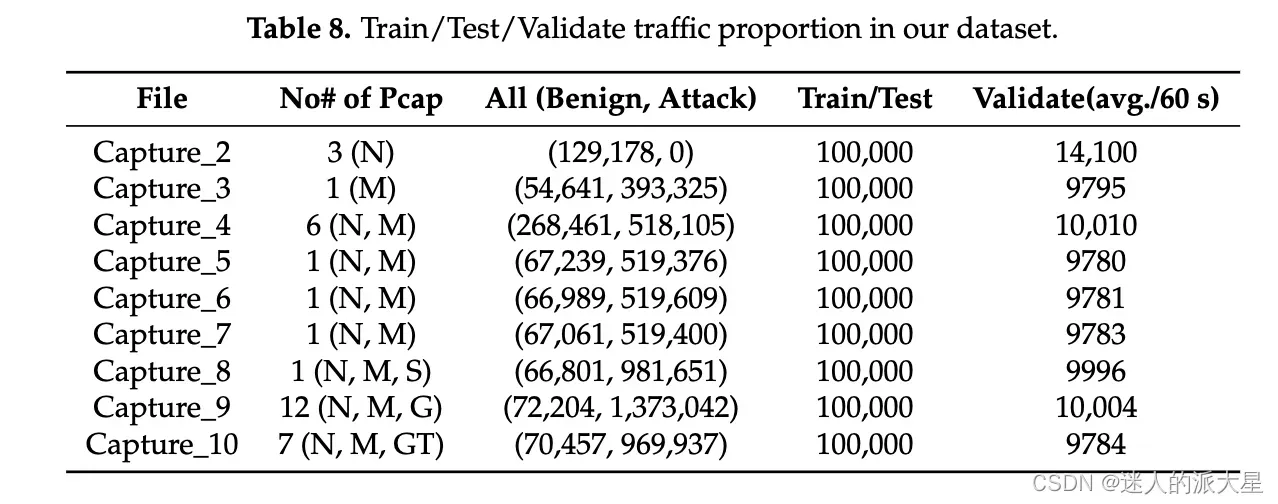
- Mirai-CCU(作者自己采集的数据)。包含四种攻击流量:TCP SYN(41 GB)、TCP ACK(2.4 GB)、HTTP POST(103 GB)、UDP(127.06 GB)。采集平台结构如下:
4 检测方法
作者提出的检测框架主要由两部分组成:数据预处理和分类。下面分别介绍:
4.1 数据预处理和词嵌入
我们的目标是将传入的数据包分类(对单个数据包,不是流)为良性或恶意类。为了实现这个目标,我们不考虑整个流(例如,作为文档),而是考虑每个数据包(例如,作为一个段落)并从每个数据包中构造关键语句,其中每个单词都是数据包头中的一个字段。之后,我们应用词嵌入从这个句子中提取语义和句法特征。我们选择考虑句子的含义而不是整个段落是因为段落的含义通常可以被关键句捕获。在这里,每个数据包中字段的顺序(针对每种数据包类型是固定的)起着类似于一些语法规则的作用,这些规则对于构建恶意流量(基于签名的检测)或良性流量(异常检测)的句型具有决定性意义。值得注意的是,这种基于数据包到句子的模型可以显着加速流量分类,因为一个或多个首数据包的行为和特征可以完全揭示它们的流是否是恶意流。一般来说,每个数据包中的字段可以是数据包头的一个字节、数据包头的一个字段或数据包有效载荷的一个块。作为初步试验,我们将包头中的一个字段视为一个word,并将包修剪为固定长度 n = 54 字节。根据数据包中的字段长度,word长度可能会有所不同。数据包结构中字段的严格顺序为构建的句子构造了潜在的语法规则。请注意,提取字段阶段可以与数据包读取/解码(即数据预处理)一起完成,因此资源消耗非常有效。此外,如果数据包的长度小于 n 字节,则会用 0 填充。packet到word的转换机制如下图所示: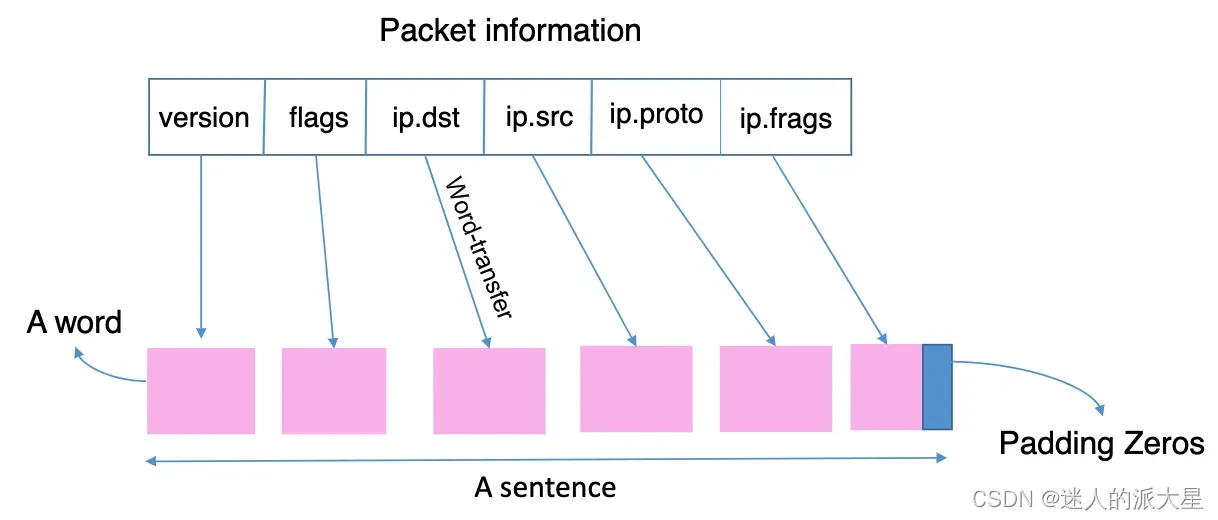
选择n=54 字节的原因是大多数 TCP 数据包都有一个 14 字节的 MAC 头、一个 20 字节的 IP 头和一个 20 字节的 TCP 头。下表列出了 TCP 和 UDP 数据包的报头字段及其长度: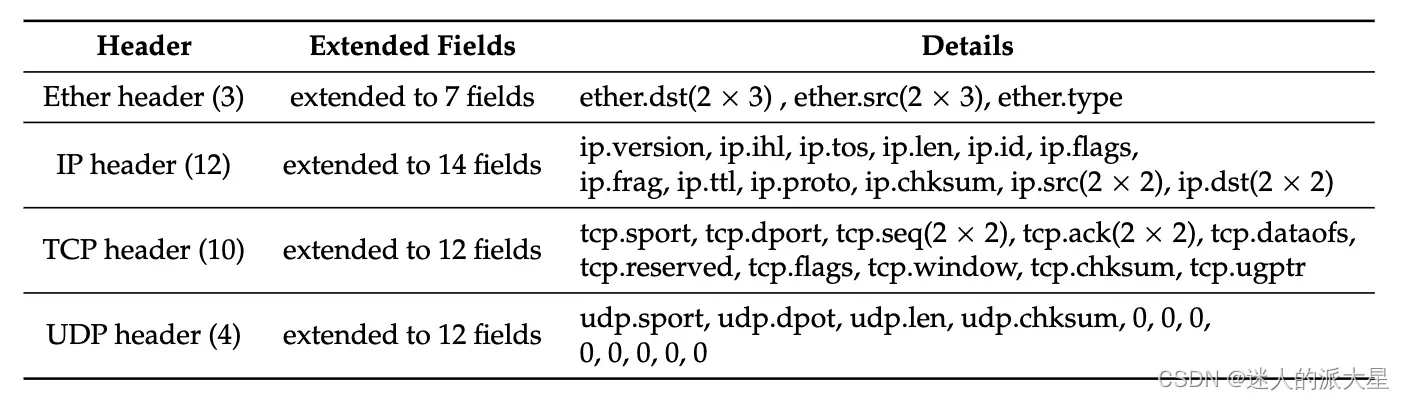
在将词嵌入技术应用于数据包头中的字段之后,每个包头字段被嵌入(即基于它们在所有单词的字典中的索引为整数格式)并重新整形(即维度)并放入用于执行分类任务的基于 LSTM 的训练模型。字长(超参数)选择和进一步的字嵌入策略是可调的,并且可以由系统保护伞下的部署环境和物联网应用程序指定。
4.2 分类
训练/验证的总结流程如下:
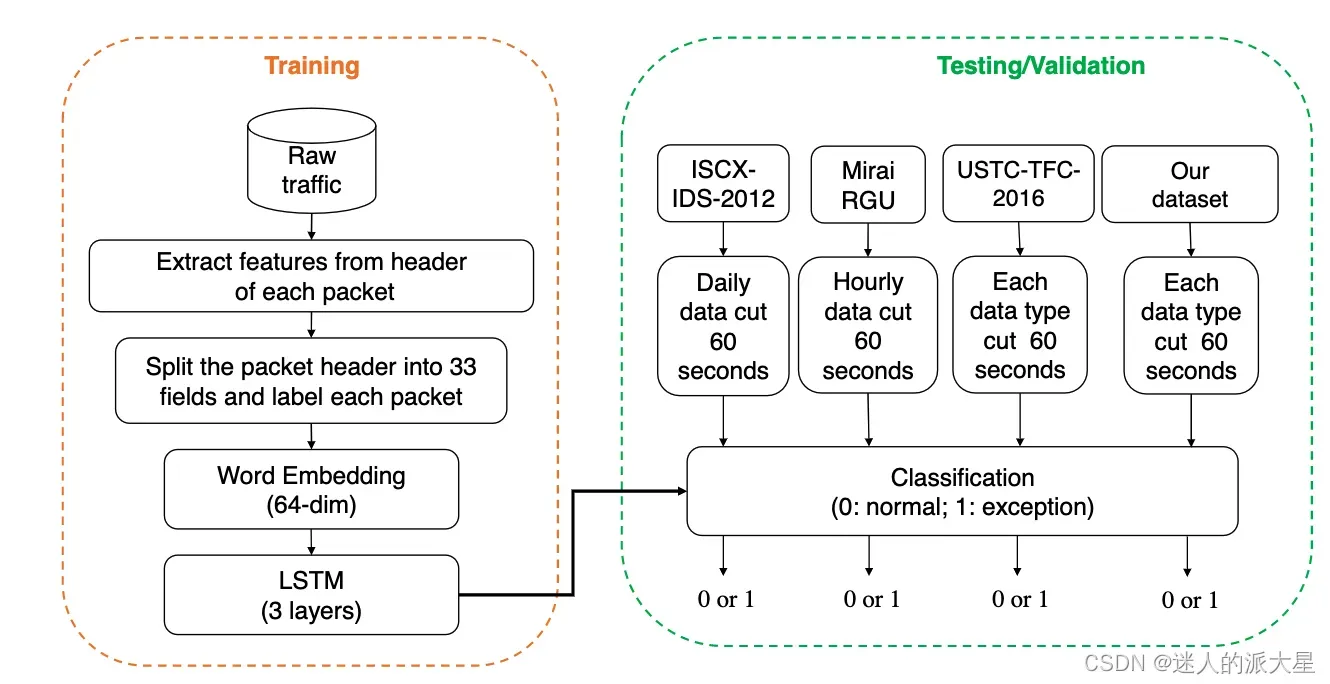
原始流程包头经过预处理(填充到54字节)后,对每个包提取的字段进行词向量嵌入后送入到LSTM模块训练。分类模块结构如下: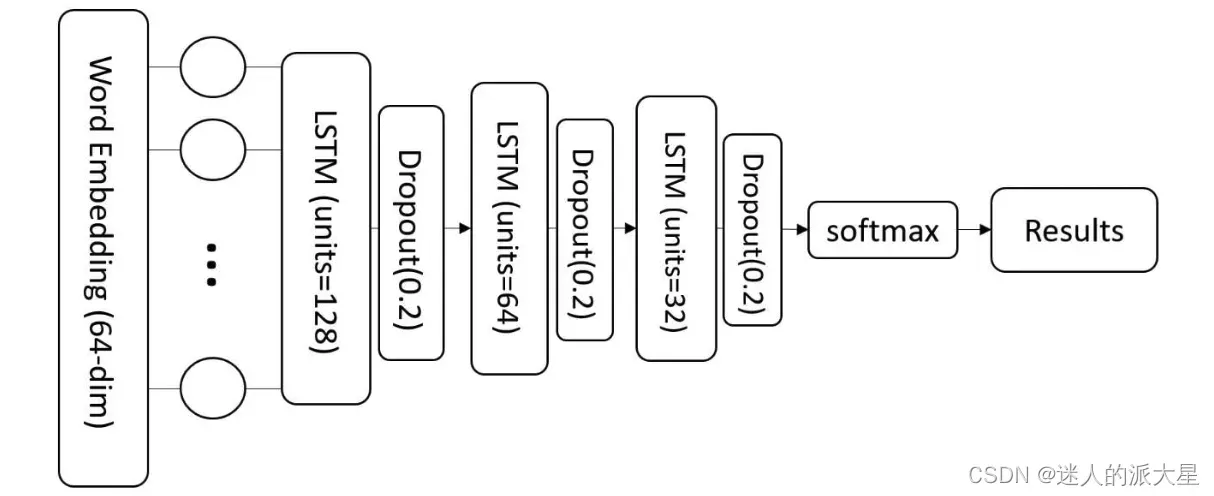
5 实验结果
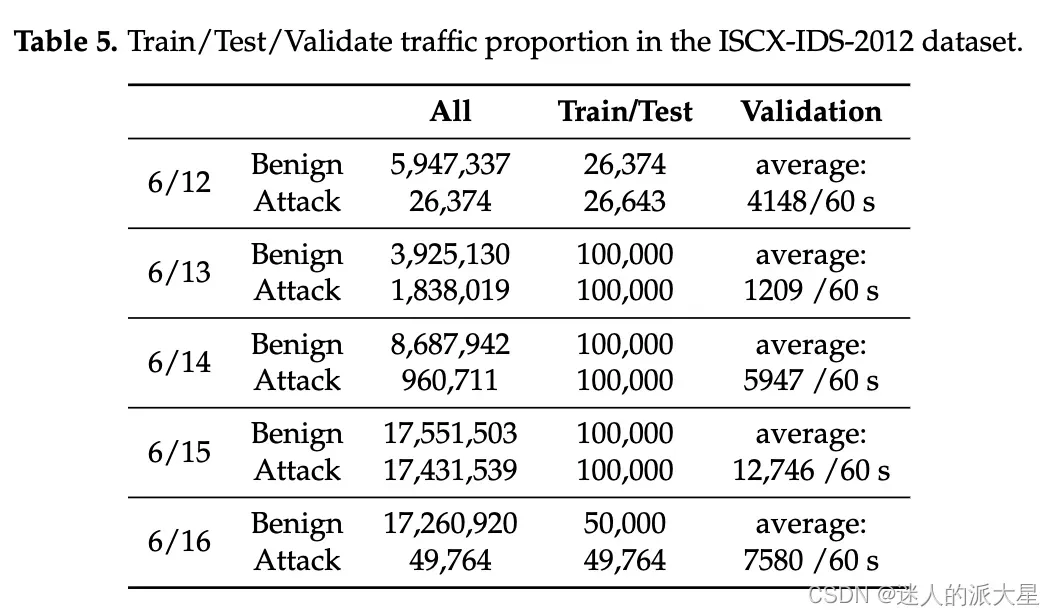
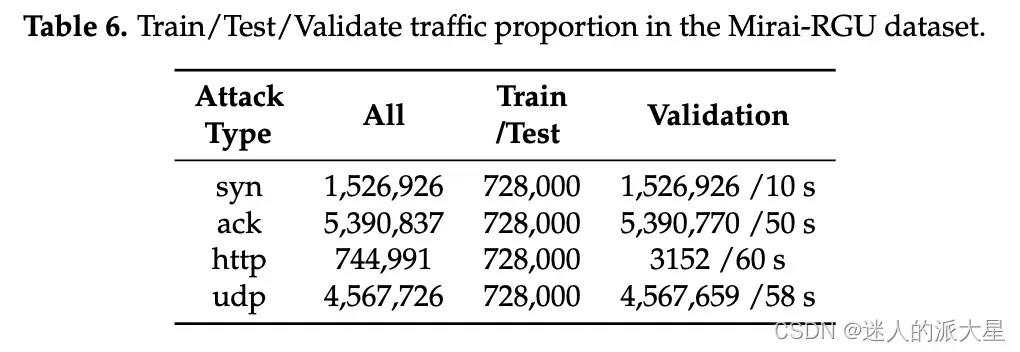
为了进行评估,我们使用了 ISCX2012、USTC-TFC2016、Mirai-RGU 和 Mirai-CCU 数据集。在训练和测试阶段,我们尝试包含数百到数千个数据包,同时平衡良性和恶意流量。在验证阶段,我们对从所选数据集中每 60 秒随机提取的数据包运行训练模型,即在保持其时间顺序的同时提取原始数据集中连续 60 秒的数据包。在这个阶段,原始流量直接输入到经过训练的模型,不对两种类型的流量进行任何操作或平衡。四个数据集的训练/测试/验证配置的流量比例分别如下表:
6 总结
本文的主要贡献是提出了一种新的原始流量包数据表征的方法(对数据包头字段进行词向量嵌入),并使用LSTM模型来训练,在四个数据集上的验证都达到了很高的精度。同时,由于不需要进行流级别的预处理工作,使得模型的检测速度大大提高(作者在离线验证时,一个108MB的数据包文件只需要2s就可以完成检测)。
作者认为未来的改进可以增加并行度(可以同时处理多个数据包,但会增加内存消耗)。
还提出了一个有趣的方向:
最后,基于 DL的分类方法由于依赖于训练数据,因此极易受到数据中毒攻击。到目前为止,我们发现很少有针对逃避基于深度学习的恶意分类系统的攻击模型,包括我们的。然而,当深度学习的普及将吸引更多攻击者利用其漏洞进行黑客攻击或货币化时,这种情况很快就会改变。因此,生成/预防针对深度学习的模型是最有趣和最有前途的安全研究课题之一。
文章出处登录后可见!