一.大纲
写在前面
本文主要参考: 《PRML》,B站《白板推导》 和 周志华《机器学习》
二.内容
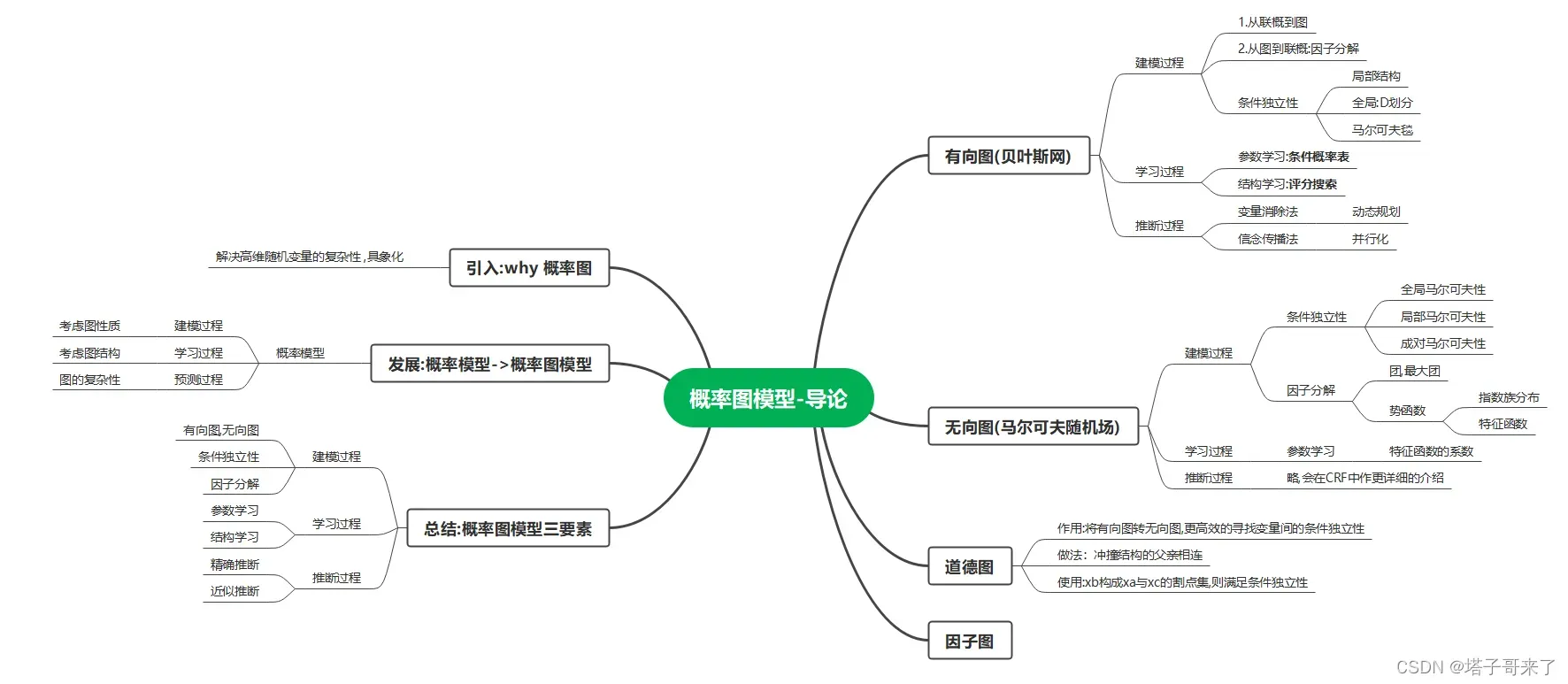
简介:为什么要使用概率图形模型
概率图模型可以说是贝叶斯的法宝。多年来,对概率图模型的研究很多,形成了一个非常完整的体系,在这个体系下也产生了许多优秀的模型,如:模型。概率图,顾名思义,是概率论和图论的结合。概率图模型是如何提出的?概率论有几个基本原理。无论概率推理和学习问题多么复杂,都可以认为是以下两个操作原则:
3,4比较常见,故也一起写出来,他们也可以由1,2推得.
然而,我们在现实生活中面临的问题往往涉及很多变量,即高维随机变量:。这样,结构化概率模型的使用就会非常复杂。图模型在图结构中包含了复杂的代数运算,可以让我们更直观地理解随机变量之间的依赖属性(条件独立性),从而设计出更复杂的模型。
发展:从概率模型到概率图形模型
大家需要明确的是,概率图模型是概率模型和图模型的结合。因此,概率模型中的内容在概率图模型中应该是可用的。结合前面的内容,我们知道概率模型的三大要素是:建模过程、学习过程、预测过程。这三个阶段要做的事情大致如下:
- 建模过程:1.确定建模的对象(条件分布还是联合分布) 2.适当的模型假设(朴素贝叶斯为了简化计算作的条件独立性假设,逻辑回归为了将
关联起来作的广义线性模型三假设) 3.得到概率分布的参数化形式
- 学习过程:基于数据的参数估计
- 预测过程:点估计,通常取最高概率
作为结果
概率图模型也应该对应这三个过程。而由于概率图结合了图,所以在建模阶段中还要考虑图的本身的性质(有向还是无向),而且朴素贝叶斯中的条件独立性假设在概率图中得到了推广。在学习过程中还要学习图的具体结构(确定这张图长啥样),称为结构学习。在预测阶段(概率图模型中称其为推断),由于图结构在数学表达上是很复杂的,只不过我们把它隐藏起来了,所以概率模型的精确预测在图模型中显得十分复杂(在介绍变量消除法和信念传播时大家将会有深刻的体会),甚至变成了NPC问题。这样的困境促使我们创造了近似推断的方法,即退而求其次的求近似解。
大纲:概率图的组成
一个完整的概率图模型由三部分组成:图表示+学习+推理。主要内容如下图所示: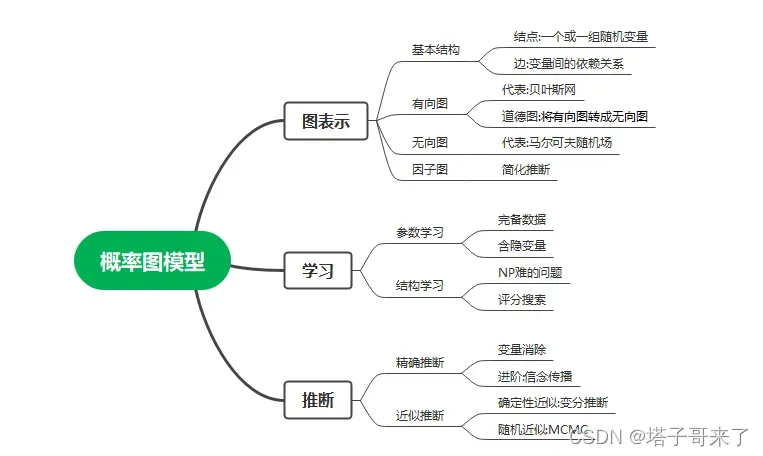
图表示
在概率图模型中,每个结点表示一个随机变量(或者一组随机变量),边表示这些随机变量之间的依赖关系。按边的方向分有两个主要的图模型,1.有向图,也称贝叶斯网.2.无向图,也称马尔可夫随机场。为了更加直观的观察有向图的条件独立性,会将有向图转换成道德图(无向图).而无论是有向图还是无向图,为了更好的做推断都可以将他们转化成因子图。
学习
在图模型中,不仅需要学习参数:贝叶斯网中就是学习条件概率表,HMM学习转移矩阵和发射矩阵,线性链CRF就是学习特征函数的权重系数。而且对于含有隐函数的模型(HMM,CRF),还需要使用EM算法进行求解。而且更重要也更难学习到的就是结构(也就是这个图长什么样子):最优的图结构是NPC问题,没有多项式的解法,在贝叶斯网中常见的做法就是”评分搜索”:我们使用评分函数来定量描述结构与训练数据的契合程度,然后基于评分函数搜索寻找最优结构。显然,评分函数引入了关于我们希望得到什么样的图模型的归纳偏好。
推断
当模型训练好了以后就能够回答”查询”了。所以推断就是预测。主要的推断目标有:1.边际条件分布2.条件概率分布 3.最大后验估计推断.推断的方式分为两种,一种是精确推断,这种方法可以求精确值但是算法复杂度过高,适用范围有限,具体的方法有变量消去法(本质就是动态规划),信念传播(并行化算法)。一种是近似推断,希望在较低的时间复杂度内获得原问题的近似解,方法分为两大类:确定性近似,例如变分推断。采样近似,即通过随机化的方法完成近似,例如
对于初学者来说,上面的描述对于专业术语来说可能过于密集。别着急,我们以后会详细介绍这些术语,但现在我们只是为您建立一个通用框架。
我们在本章中介绍了两个基本的概率图模型:贝叶斯网络和马尔可夫随机场。
有向图:贝叶斯网络
引入
在正式学习贝叶斯网络之前,强烈推荐大家学习朴素贝叶斯和半朴素贝叶斯(可以看西瓜书或者我的博客)。因为其实我们在半朴素贝叶斯中已经可以看到概率图模型的影子了,在这两者的基础上引入贝叶斯网络是很自然的。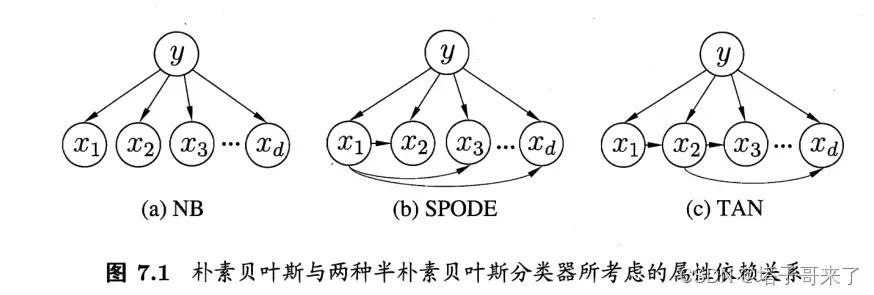
建模过程
从联合概率分布到图结构
举个简单的例子:给定三个变量,它们的联合概率分布可以转化为:
显然,这样的分解满足任意三个变量的联合概率分布。将其转换为有向图,如下图所示: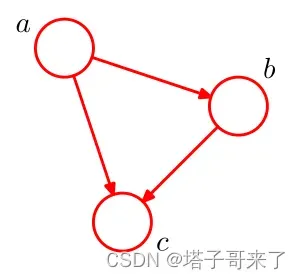
为什么要这样构建?这种构造方法可以看作是一种人工构造的规则,更符合人类的直觉。
进一步:对于变量的联合概率分布,用
得到:
如果你把它画成一个有向图,你可以看到它是一个全连通图。
从图结构到联合概率分布
总之,我们的建图规则已经非常清晰了。那反过来,给定一张图,我们如何将它的联合概率分布表示出来呢?其实也非常简单:1.图中有多少个结点就有多少项 2.对于每个变量结点的条件概率中的条件变量就是它的前驱结点集合
.所以联合概率分布表示为:
在概率图中,这种“看图”分解也称为因式分解。
为什么要对联合概率分布进行因子分解:就如NB的条件独立假设一样,直接计算联合概率分布复杂度过高,我们希望引入一些合适的假设将其分解成若干个独立的部分,使得复杂度降下来。
条件独立性
现在我们知道是将公式转换为图形还是将图形转换为公式。这里应该相当简单。但到目前为止,我还没有意识到图模型的威力。在第一节中,我们说过引入图模型的主要目的是可以直观地描述条件独立性。现在我们通过一个例子来让大家了解一下图结构是如何将条件独立的数学表达式融入到图结构中的。在我们考虑全连接图之前,现在尝试删除一些边。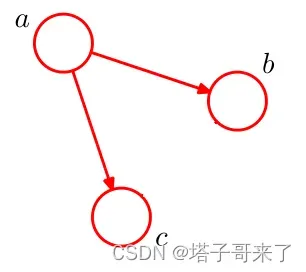
①在观察、
相互独立的情况下,写:
。
②如果没有观察到,
不独立,写
证明①:
按链条原理:
证明②:
因为我们要考察之间的关系,我们自然会考虑:
无法启动
我们可以从这样一个简单的例子中体会到图形模型的威力。图模型在结构上描述了条件独立性,足够直观。有趣的是,这种处理方式与我们之前的处理方式有点“相反”。之前,我们都希望用数学公式来量化描述具体的思想,而提出图模型是因为具体的数学公式过于复杂,不方便人类进行概括和概括,所以具体化了。
局部:三种结构
在有向图中,我们归纳了三种能够描述条件独立性的简单结构,分别是同父结构,V型结构,顺序结构,如下图所示: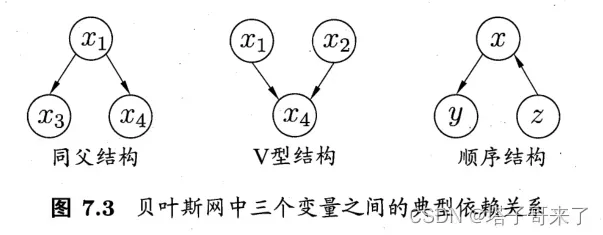
而V型结构是一个比较有趣的结构,它的行为和前两个结构正好相反:且
.
prove:
①
②
而,所以证明。
此外,的所有后继节点都满足这个性质。
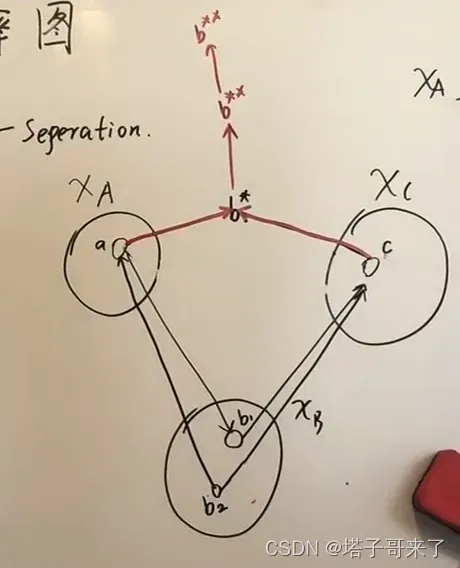
全局:D划分
上面只讨论了局部情况,我们考虑整体图并概括条件独立的描述:
其中,是三点的集合。
现在我们的目标就是给定,找到相应的
使其满足条件独立性.其实只需要根据局部的三种情况稍加推广即可得到
:
若
满足 [是同父结构中的父亲或顺序结构中的中心结点] 且 不是冲撞结构中的冲撞点以及其后代.则
.如下图所示:
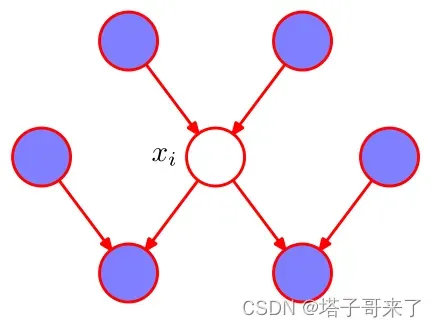
马尔可夫毯
定义:在有向图中,在随机变量的全集中,对于给定的变量
和变量
,如果有
则满足上述条件的最小变量集称为
的马尔可夫毯。
查找:考虑贝叶斯定理:
我们注意到分母是对的积分,所以其中所有和
不相关的项可以从积分符号中提取出来,然后与分子约掉。剩下来的分子分母部分就只与
有关了.把他称作马尔可夫毯是因为它的图形很像一个展开的毯子:
应用
帮助特征选择:对于目标变量,如果我们需要知道这个变量的分布,我们只需要得到马尔可夫毯。帮助我们确定冗余特征并降低特征空间的维度。 (进一步)
学习过程
参数学习
贝叶斯网通常使用条件概率表[1]进行推断。对于每个结点我们都需要维护一张条件概率表,此表蕴含了的所有取值可能。具体的对于随机变量
,令其取值个数为
,那么对于点
它的所有可能的取值个数是(即表的大小):
所以我们在学习阶段需要解决的目标就是条件概率表。该过程“计数”样本,例如朴素贝叶斯。
结构学习
参数学习的前提是图的结构确定下来了。而确定图的具体结构(图长什么样子)的过程称作结构学习。结构学习的目标是找到一个与训练数据拟合程度最好的图结构.直观解释是这张图的随机变量之间的依赖关系最好能够匹配训练数据的实际情况。找到最优结构是一个NPC问题.一般我们采用求近似解的方法,评分搜索:先确定一个评分函数,再根据评分函数搜索(暴力)一个比较好的结构。而评分函数通常基于信息论准则,将本问题转化为最小描述长度()任务。
回忆一下:半朴素贝叶斯中TAN的做法是退而求其次,假设这张图一定是一棵树,然后根据互信息跑最大生成树,在确定方向。那么在树假设下,最大生成树倒是个最优结果。
推断过程
- 近似推理系统比较大,我暂时不解释,只介绍精确推理
变量消除法(Variable Elimination)
变量消除的方法是在求解概率分布的时候,将相关的条件概率求和/积分,然后按照一定的顺序一步一步消除变量(类似动态规划的思想),例如在马尔科夫链中: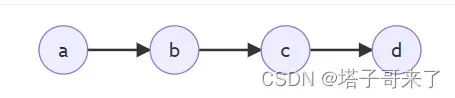
应用加法原理;这时候如果暴力求解,时间复杂度相对于变量值的个数是指数级的,因为需要枚举
的所有可能值
这一步很重要,原来枚举集是无序的,现在设置枚举顺序,这样就可以找到重叠的子问题了
应用乘法原理
提取公因子:表达式
为边际概率分布
;表达式
是边际概率分布
;表达式
是边际概率分布
;这时,我们只需要按
的顺序求解,但需要存储中间结果。
至此,具体步骤如下:
- 1.求一张关于
的概率分布表
- 2.查
表,求一张关于
的概率分布表
- 3.查
表求解出
.
复杂性分析:
假设链长为,每个变量的取值范围为
,那么每个表的长度为
,需要对表中的每个值求和,复杂度为
。并且因为需要存储表,所以有
的空间开销。
shortcoming:
1.上面的例子是简单的链型,效果不错,这是因为链结构下最优的变量消解顺序是一个NP问题。但一旦图结构复杂起来最优的变量消解顺序就升级为NPC问题了。
2.算法没有对中间变量存储的功能, 因此每次查询都要重新做一次计算
信念传播(Belief Propagation)
作者对这个算法也有一些疑惑,让我想想。 . .
无向图:马尔可夫随机场
马尔可夫随机场也有相应的条件独立和分解。
如果可以得到显示的依赖方向,则直接使用贝叶斯网络。如果在实践中难以获得显示的依赖关系,则使用马尔可夫随机场,变量为软约束。
建模过程
条件独立性
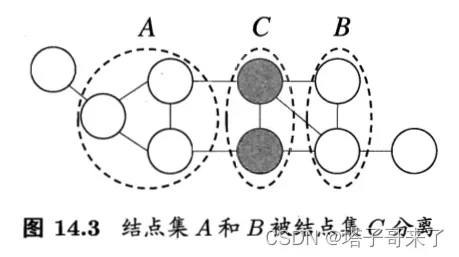
全局马尔可夫性质:若将
分为两组点,则
1.局部马尔可夫性:
无向图中一个点的马尔可夫毯是由其所有邻居组成的点的集合
2.成对马尔可夫性:
因子分解
Clique:图中节点的子集,满足集合的节点由边连接
最大组:如果组中不能再添加节点,则称为最大组
使用这个定义,我们可以定义无向图的分解。假设有组
,
是归一化因子,那么我们有:
其中,称为势函数,用于定义变量
之间的相关性。具体来说,给定组
中每个变量的特定值,它会为您提供一个概率,该概率表示获得该值的概率。
例如,一个模型有两个团,它们的势函数定义为(先忽略它们的参数形式,只考虑输出):
那么该模型可以理解为:成正相关关系,
成负相关关系.所以满足
的联合概率较高。
为了满足非负性,势函数一般定义为:,所以分解也可以写成:
这个分布称作Gibbs分布,它属于指数族分布。而是一个关于变量组
的实值函数,用来刻画团内变量之间的关系。由于关系分两种,一个是对自身的关系,一个是任意两个变量的关系,所以可以设计为:
其中,为参数,
为特征函数(与最大熵模型中的特征函数含义相同)。马尔可夫随机场的参数学习归结为特征函数权重参数的学习。
学习过程
参数学习
马尔科夫随机场的参数学习归结为特征函数权重参数的学习。
结构学习
与贝叶斯网络相同
推断过程
- 这里只介绍精确推理
与贝叶斯网的区别不大,会在后续的CRF介绍中详细介绍
道德图:两种图的变换
我们经常希望对于有向图可以更直观地观察条件独立,所以有一种方法可以将有向图转换为无向图。这个过程称为道德化,由此产生的无向图称为道德图。
转换方法:找到所有的碰撞结构,用一条边连接两个父节点
用法:对于两个点集,如果两个点集在去掉
后存在于两个不同的连通分量中,则有
三.数学推导
四.参考资料
[1] https://en.wikipedia.org/wiki/Conditional_probability_table 维基百科,条件概率表
文章出处登录后可见!