反向传播学习连接:前向传播、反向传播——通俗易懂_马鹏森的博客-CSDN博客_前向传播 反向传播[0]
梯度下降和反向传播
1、反向传播 是 求解损失函数关于各个参数的梯度的一种方法。(求梯度)
2、梯度下降 是 根据计算得到的梯度来更新各个权重W,使损失函数极小值的一种方法。(使梯度下降)
学习率 α 与梯度下降有何关系?
学习率 α 是梯度下降中权重更新公式的一部分
梯度下降中的权重更新公式:
利用,权重更新公式 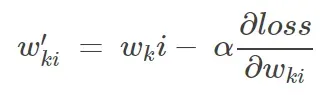 更新权重W,其中 α 是学习率
更新权重W,其中 α 是学习率
备注:我认为:学习率有 == 步长
优化器与梯度下降有何关系?
梯度下降是一种优化器。优化器是一种最小化损失函数的方法。它还包含学习率。
在机器学习、深度学习中使用的优化算法除了常见的梯度下降,还有 Adam,Adagrad,RMSProp 等几种优化器
实际代码:
理解了上面的内容后,我们便知道了整个神经网络的实现过程分为5步:(Pytorch实现神经网络_马鹏森的博客-CSDN博客)[0]
前向传播得到预测值 –> 计算预测值和真实值之间的损失 –> 优化器梯度被清除 –> 求所有参数的梯度 –> 优化器更新梯度
# Gradient Descent
for epoch in range(50):
# Forward pass: Compute predicted y by passing x to the model
y_pred = model(x)
# Compute and print loss
loss = criterion(y_pred, y)
print('epoch: ', epoch,' loss: ', loss.item())
# Zero gradients, perform a backward pass, and update the weights.
optimizer.zero_grad()
# perform a backward pass (backpropagation)
loss.backward()
# Update the parameters
optimizer.step()备注:这里的 optimizer.zero_grad() 是梯度清零操作,需要的内存较大,如果使用“梯度累加”操作的话:在内存大小不够的情况下叠加多个batch的grad作为一个大batch进行迭代,因为这个和大batch_size得到的梯度是等价的,但是效果自然是差一些,这个可以说是“增大batch-size减少内存”的一个小trick吧
PyTorch中在反向传播前为什么要手动将梯度清零? – 知乎[0]
损失函数与优化器理解+【PyTorch】在反向传播前为什么要手动将梯度清零?optimizer.zero_grad()_马鹏森的博客-CSDN博客[0]
文章出处登录后可见!
已经登录?立即刷新