Deformer:Decomposing Pre-trained Transformers for Faster Question Answering
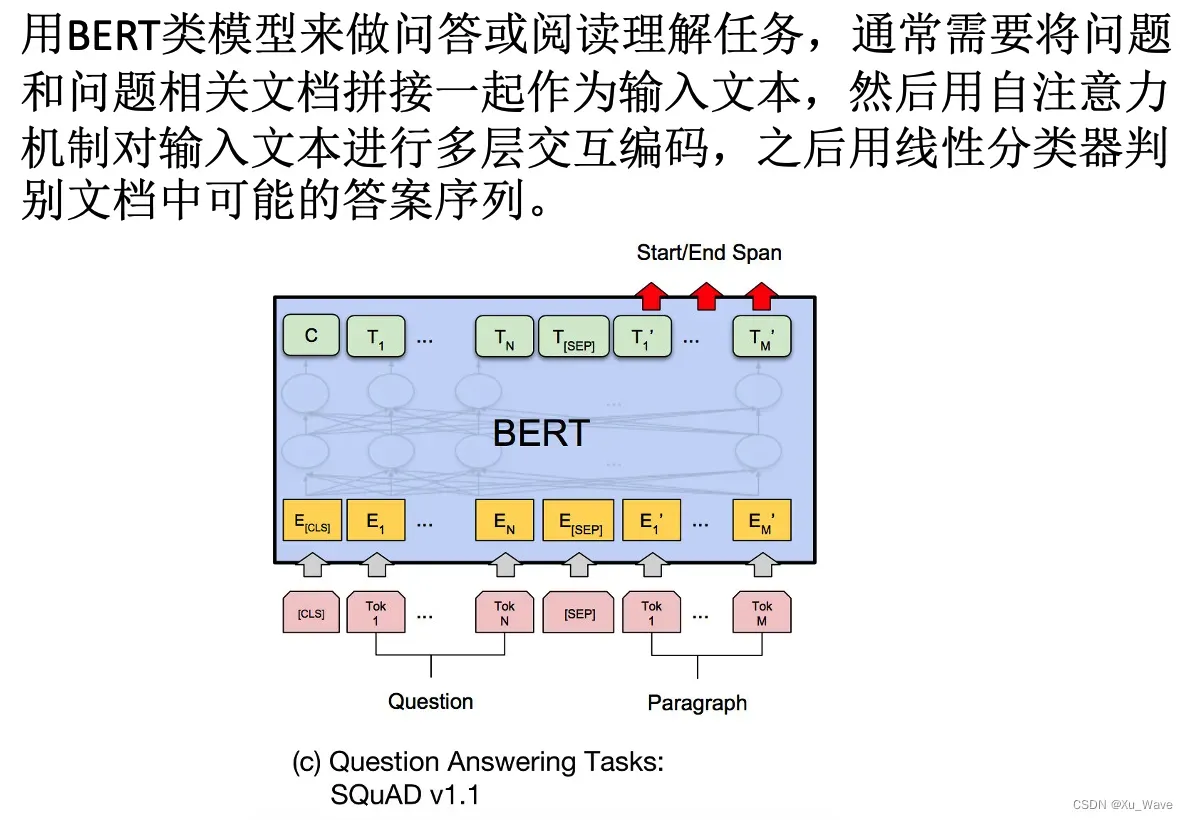
虽然这种片段拼接的输入方式可以让自注意力机制对全部的token进行交互,得到的文档表示是问题相关的(反之亦然),但相关文档往往很长,token数量一般可达问题文本的10~20倍,这样就造成了大量的计算。
在实际场景下,考虑到设备的运算速度和内存大小,往往会对模型进行压缩,比如通过蒸馏(distillation)小模型、剪枝(pruning)、量化(quantization)和低轶近似/权重共享等方法。
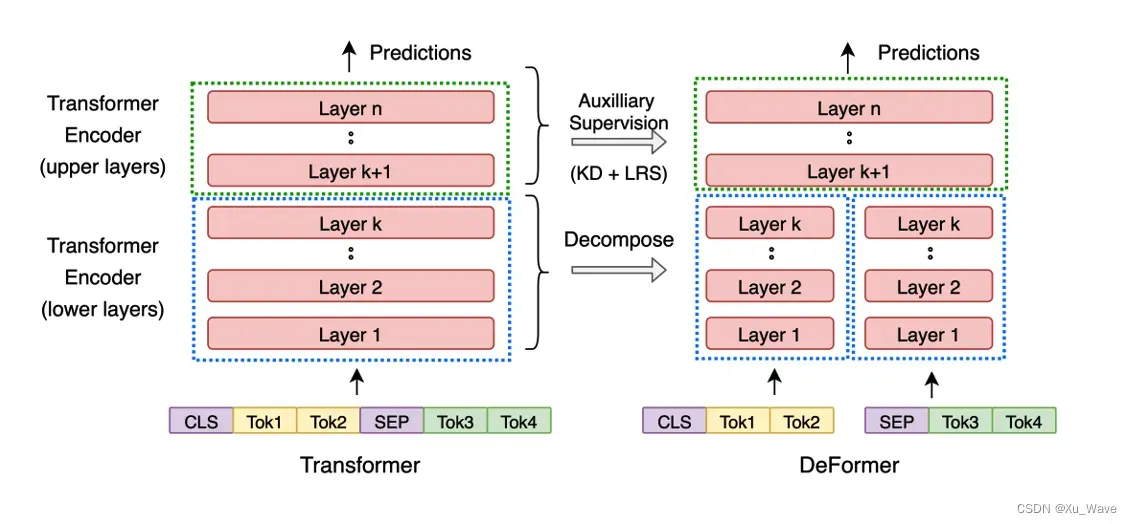
但是,模型压缩仍然会带来一定的精度损失。所以我们想,是不是可以参考双流模型的结构,提前做一些计算,提高模型的推理速度呢?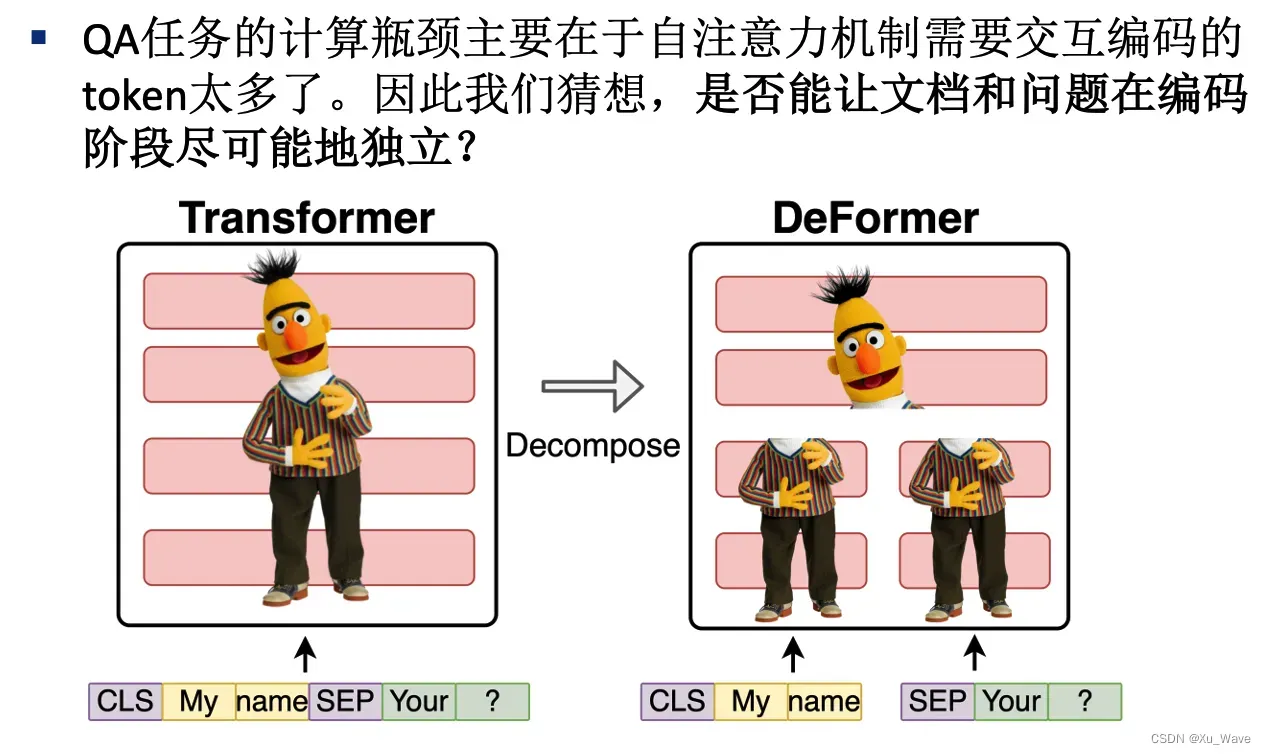
Is BERT Really Robust? A Strong Baseline for Natural Language Attack on Text Classification and Entailment (AAAI 2020 Oral)
方法总览
给定一个黑匣子
输入:句子、对应标签、模型、相似度计算函数Sim、 ε 、词表和词嵌入
输出:对抗性示例
背景
机器学习算法通常容易受到与最初训练模型的数据相关的类似广告的示例的影响。
那么如何解决这个攻击问题呢?我们可以自己生成这些广告的类似示例,以评估甚至提高模型的稳健性。
作者提出 TEXTFOOLER
并在文本分类和textual entailment 上进行实验
攻击了三种模型,Bert、卷积、循环神经网络。
这种对抗在图像领域的使用越来越广泛,但对于自然语言来说,仍然是一个很大的挑战。
对于图像模型,输入一张图像(与肉眼不可分割的变化),模型会判断错误。所以随着新的研究方向,产生了更多的例子,这些对抗性的例子在训练阶段被看到以提高鲁棒性。
扩展到自然语言处理领域,改变一些词,比如文本分类模型,可能会让模型识别出错误的标签等。
方法细节
输入:句子、对应标签、模型、相似度计算函数Sim、 ε 、词表和词嵌入
我们用输入的句子X,来初始化
对句子X中的每个词进行重要性计算,并将其排序全部放入W集合中,并过滤掉W集合内的停用词。
找出所选单词(W中的每个单词)的所有可能候选词。
找的策略:根据与词汇表中其他每个单词之间的余弦相似度,以N个最接近的同义词作为候选词集合。(这里就用到了余弦相似度和词表和词嵌入)(这里还没用到Sim函数)
选的词嵌入是专门用来计算相似度的,N的设置也是有讲究的,文中N=50,余弦相似度的下限为0.7
最后得到的候选词集合candidate(也进行了词性过滤,只保留和原来词词性相同的词)
请注意,这是逐字处理。
对candidate集合中的每个候选词都与其对应的进行替换得到X’,然后计算X’与原来的
的Sim函数相似度。
如果大于阈值ε,且用该X’生成的结果和生成的结果不一样,则放入最终候选集合中。最终选择该集合中与
语义相似度最高的词进行替换
。
如果生成的结果相同,则选择置信度分数最低的词作为的最佳替换词,然后重复前面的步骤来变换下一个选中的词。
实验

ICML 2020 | Description Based Text Classification with Reinforcement Learning
背景
大概的概念:
-明确引入分类标签的描述信息,提高效果。
介绍描述性信息的三种方式:
1 给各个标签一个静态的描述信息
2 文本 – 标签,用文本信息来当做标签的描述信息
3 动态地根据输入的文本,为每个标签都生成一段描述信息
经典的文本分类方法把标签看做0、1、2、3即简单的下标,但这是对标签本身描述信息的浪费,我们希望能够利用到标签本身的描述信息。
方法一
利用词典,输出标签的定义(描述),从而作为该标签的描述信息,如positive,“full of hope and confidence, or giving cause for hope and confidence”
本文的方法是将描述和原文拼接到模型中,然后模型进行预测。
但是这个定义(描述)往往是不准确的。
方法二和三

使用强化学习来学习标签描述(抽取)

抽取方法中,每一个输入,同一个class的描述都是不同的,每一个class的描述都是输入的substring。
当前class如果的确和输入x匹配,那么可以找到对应描述;如果不匹配,则很难找到对应描述,所以论文在输入x中加入了很多的伪token,如果找到的描述指向了伪token,则使用静态描述。
强化学习算法三个核心点:action a,policy π,reward R
1 对于每一个标签,action就是从输入x中选择合适的描述,这个描述是通过上下标来选择的,如上图。
2 Policy则为上下标选择出来的正确的描述的概率值,即P_span。
3 输入x和描述,然后输出正确标签的概率,这个概率将用于更新分类模型以及抽取方法。
最大化reward,loss则最小化-reward,最后用来更新参数的loss,就如上图所示。
强化学习是一个框架,任何一个任务定义好 action policy reward 即可。
生成的方法

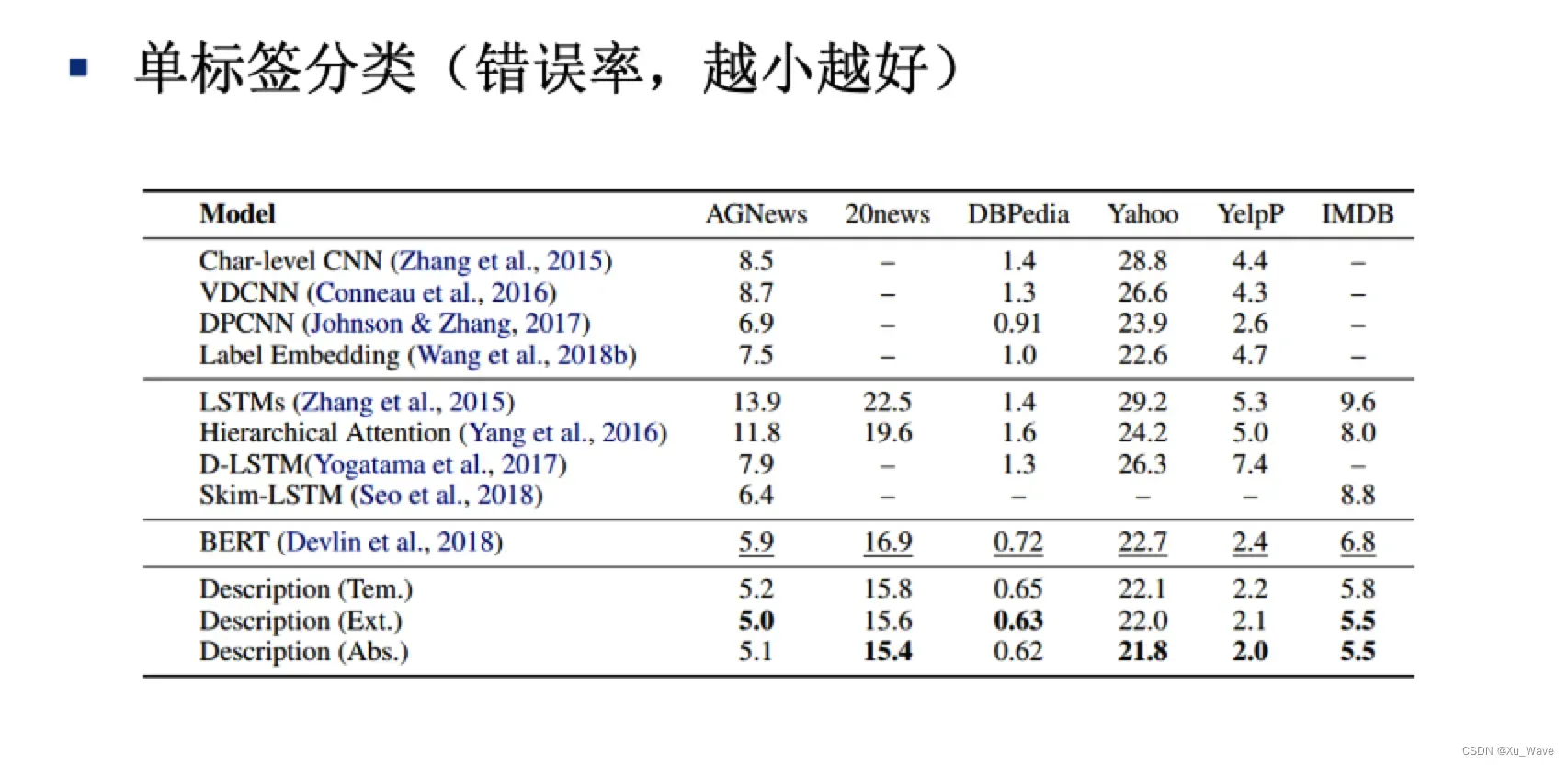
实验
文章出处登录后可见!