TensorBoard是TensorFlow官方提供的一款可视化工具,用于可视化模型训练过程中的各种指标、图像和计算图等信息,方便用户更加直观地观察模型的训练情况。
下面是TensorBoard的一些常见可视化网页:
Scalars网页:该网页展示了模型在训练过程中的标量数据,如训练误差、测试误差、学习率等。
Graphs网页:该网页展示了模型的计算图,可以更加清晰地了解模型的结构和参数。
Histograms网页:该网页展示了模型参数的分布情况,包括权重、偏置、梯度等。
Images网页:该网页展示了模型输出的图像数据,可以直观地观察模型的输出结果。
Projector网页:该网页用于对高维数据进行降维可视化,如特征向量、嵌入向量等。
在使用tensorboard之前首先要确定有这个包,没有的话使用pip命令安装。
pip install tensorboard
在TensorBoard中,用户可以通过运行以下命令启动TensorBoard:
tensorboard --logdir=路径
#以yolov5为例
tensorboard --logdir=runs/train
输入命令后会生成一个本地网址,可以进行可视化查看

在浏览器打开网址进入tensorboard可视化网页
TensorBoard中的Time Series界面用于可视化时间序列数据,通常用于展示训练过程中的指标变化。在Time
Series界面中,可以将不同指标的变化趋势在同一个图表中进行对比,例如训练集损失和准确率、测试集损失和准确率等,并根据需要选择不同的显示方式,例如折线图、散点图、柱状图等。此外,Time
Series界面还支持对指标数据进行滤波、平滑等操作,以便更清晰地观察其变化趋势。
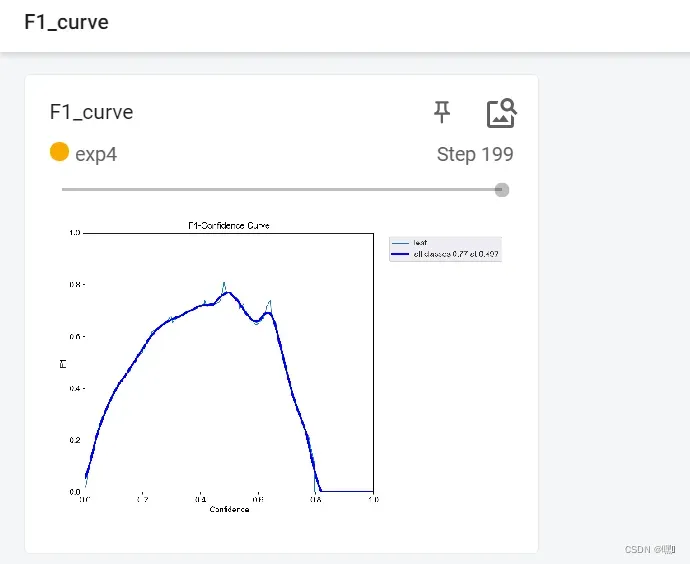
F1_curve
F1_curve是指F1得分曲线,用于衡量二分类模型的性能。在二分类问题中,我们通常会得到一个分类器预测的概率或得分,然后需要将这个得分转换为一个二进制预测。对于不同的阈值,我们可以得到不同的准确率和召回率,因此可以计算出对应的F1得分。将这些F1得分绘制成一条曲线就是F1_curve。F1_curve的横轴通常是召回率,纵轴是F1得分。
F1得分是精确率和召回率的加权调和平均值。精确率是指模型预测为正例的样本中实际为正例的比例,召回率是指实际为正例的样本中被模型正确预测为正例的比例。在F1_curve中,我们可以通过调整阈值来平衡精确率和召回率,以得到最佳的F1得分。
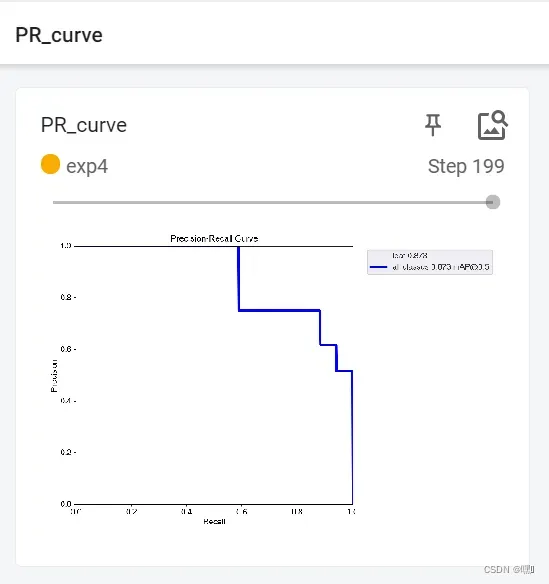
PR_curve
PR曲线(Precision-Recall curve)是评价分类器性能的一种常用方法,它是以分类器预测结果为基础的评价方法,而不是混淆矩阵。它是绘制在精确率(Precision)-召回率(Recall)空间中的曲线,精度(precision)表示在所有预测为正例的样本中,真正为正例的比例。其中精确率定义为:

在P-R曲线中,横轴表示召回率,纵轴表示精度。召回率是指所有真实正例中被分类器正确预测为正例的比例,定义为:
![]()
其中,TP表示真正例(True Positive)、FP表示假正例(False Positive)、FN表示假负例(False Negative)。PR曲线的横轴为召回率,纵轴为精确率。在PR曲线中,分类器的性能越好,曲线越靠近左上角。
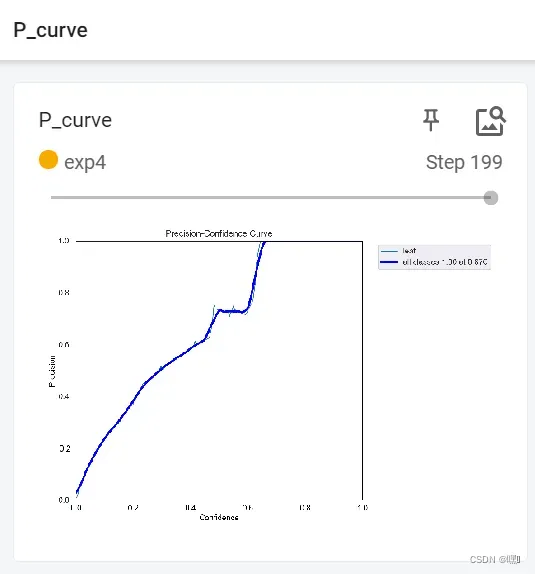
P_curve
P曲线(P-curve)是一种用于评估统计学研究中假阳性效应(False Positive Effect)的可视化方法。它显示了一组相关研究中的统计检验结果在一个给定的效应大小水平上的p值分布。P曲线的斜率代表着该效应的研究效应的方向和可重复性,斜率越陡峭则表明研究的效应越明显,结果越可信。P曲线可以帮助研究者确定某一效应是否具有统计学意义,以及结果的可靠程度。
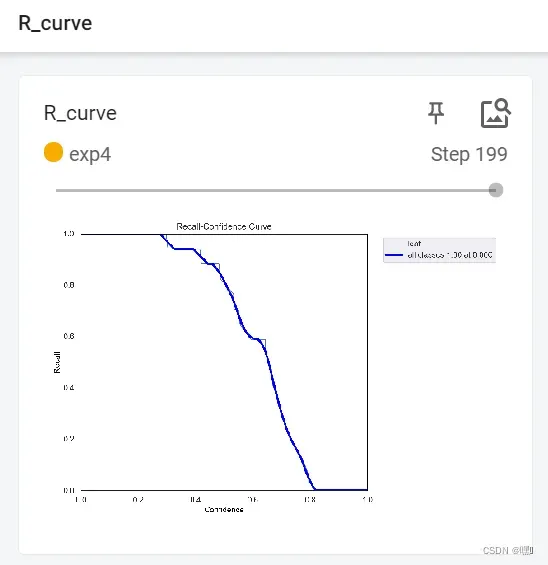
R_curve
R_curve是指在二分类问题中,不同的阈值下真实正样本(True Positive,TP)率随着真负样本(True Negative,TN)率的变化曲线。在绘制R_curve时,我们将模型预测的概率按从大到小排序,并根据不同的阈值计算TP率和TN率,将它们作为坐标轴上的横纵坐标,即可得到R_curve曲线。
与P_curve相似,R_curve也可以用来衡量模型的分类性能,但是相对于P_curve更加关注真实正样本的召回率。R_curve可以帮助我们选择最佳的阈值,使得真实正样本率和真负样本率得到平衡,以达到最优的分类效果。
confusion_matrix
混淆矩阵(confusion matrix)是用来评估分类模型性能的常用工具,可以展示模型预测结果与真实标签之间的差异。混淆矩阵可以展示四种不同的分类结果情况:真阳性(True Positive,TP)、真阴性(True Negative,TN)、假阳性(False Positive,FP)、假阴性(False Negative,FN)。
在混淆矩阵中,每行表示真实标签,每列表示模型预测结果。具体来说,混淆矩阵是一个 的矩阵,其中
表示分类的类别数,对于二分类问题,
。对于二分类问题,混淆矩阵的四个元素分别表示 TP、FN、FP 和 TN,如下所示:

metrics
“metrics”通常是指评价模型性能的一些指标,通常包括准确率(accuracy)、精度(precision)、召回率(recall)、F1值(F1 score)等。
准确率是指分类正确的样本占总样本数的比例;精度是指在所有预测为正例的样本中,真正为正例的比例;召回率是指在所有真正为正例的样本中,被预测为正例的比例;F1值综合了精度和召回率,是二者的调和平均值。
这些指标可以帮助评估模型的性能和效果,并进行模型的选择和优化。在深度学习中,常常使用这些指标来评价分类、检测、分割等任务的性能。
mAP_0.5
mAP_0.5指的是在目标检测任务中,使用0.5作为阈值计算得到的平均精度(mean average precision, mAP),其中0.5指的是用于计算precision和recall的IoU阈值。mAP是对不同类别的目标检测结果进行综合评估的指标,它是所有类别AP的平均值,AP表示平均精度,计算公式是对每个类别的precision和recall进行曲线下面积的计算。mAP_0.5通常被用于评估目标检测算法的性能表现。
mAP_0.5:0.95
mAP_0.5指IoU阈值为0.5时的平均准确度,而mAP_0.5:0.95则是在IoU阈值从0.5到0.95时,取平均值后的结果。其中,IoU (Intersection over Union)是目标检测中用于衡量预测框和真实框重叠程度的指标,其取值范围为0到1。mAP_0.5:0.95越高,表示模型在不同IoU阈值下的平均准确度越高,检测效果也越好。
precision
在机器学习和统计学中,精确度(Precision)是指被分类器判断为正样本的样本中实际为正样本的样本所占的比例。即在所有预测为正例的样本中,确实为正例的比例。
具体来说,精确度指的是所有真正例(TP)占所有判定为正例(TP+FP)的比例,其中 TP 是真正例(True Positive),FP 是假正例(False Positive)。
Precision = TP / (TP + FP)
recall
在机器学习领域中,Recall(召回率)是指模型正确识别为正样本的数量占所有正样本数量的比例。它是一个用于衡量模型在识别所有真实正样本中,正确识别出的比例的指标。Recall通常用于解决假阴性(False Negative,FN)的问题。
Recall = TP / (TP + FN)
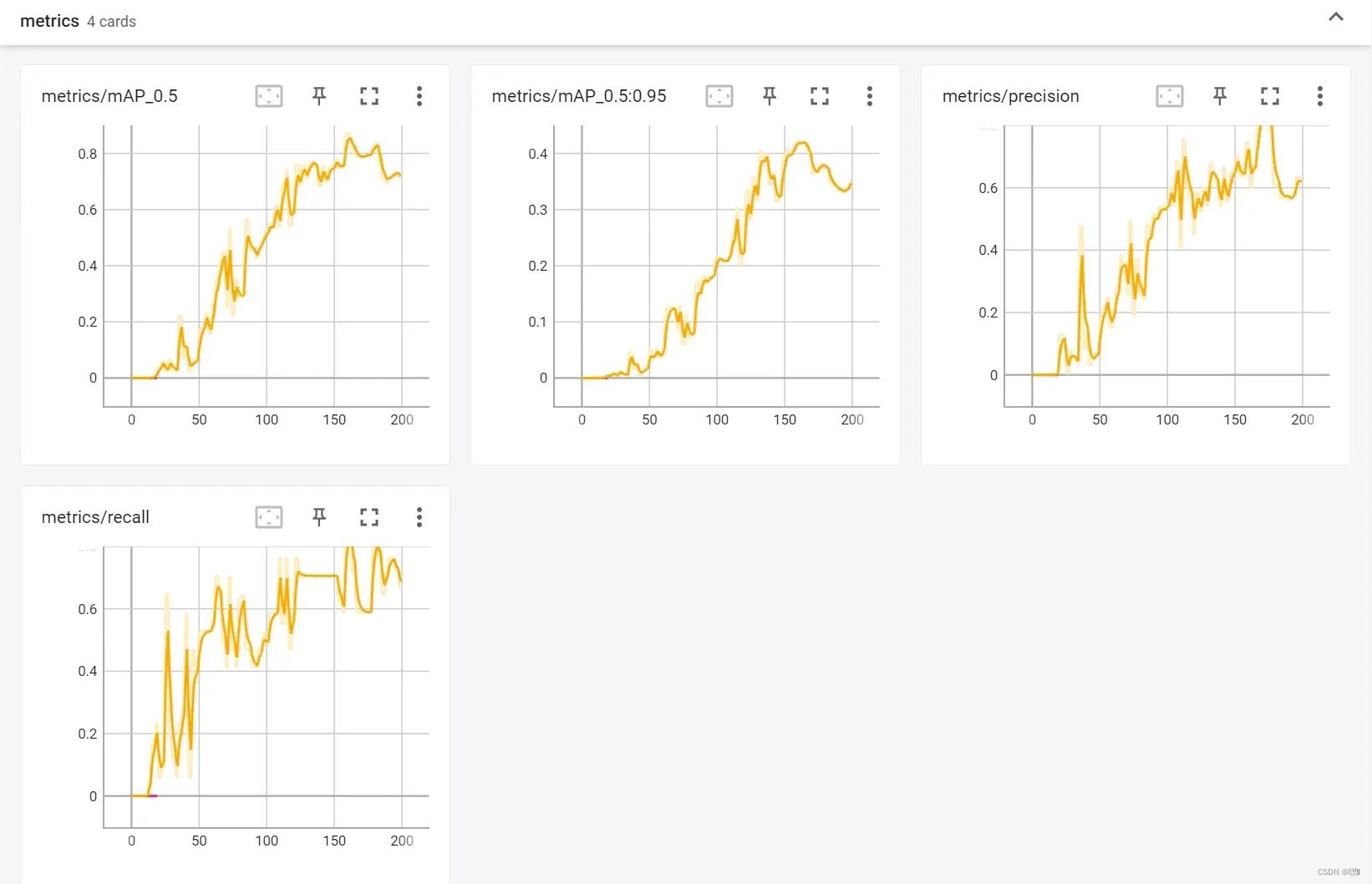
result
TensorBoard的Result面板主要用于查看实验运行过程中的各种结果指标,包括损失函数、准确率、F1值等等。Result面板通常包含两个子面板:Scalar和Histogram。
在Scalar子面板中,可以查看不同指标随着实验时间的变化曲线。例如,可以查看训练集和验证集的损失函数随着迭代次数的变化,以及精确度和召回率的变化趋势。
在Histogram子面板中,可以查看张量的分布情况。例如,可以查看权重和梯度的直方图,以帮助诊断梯度消失和爆炸问题。可以对不同实验的结果进行比较,以找出最优的超参数组合。
Result面板可以帮助数据科学家更好地理解模型的训练情况,并帮助他们调整模型和优化超参数,以提高模型的性能。
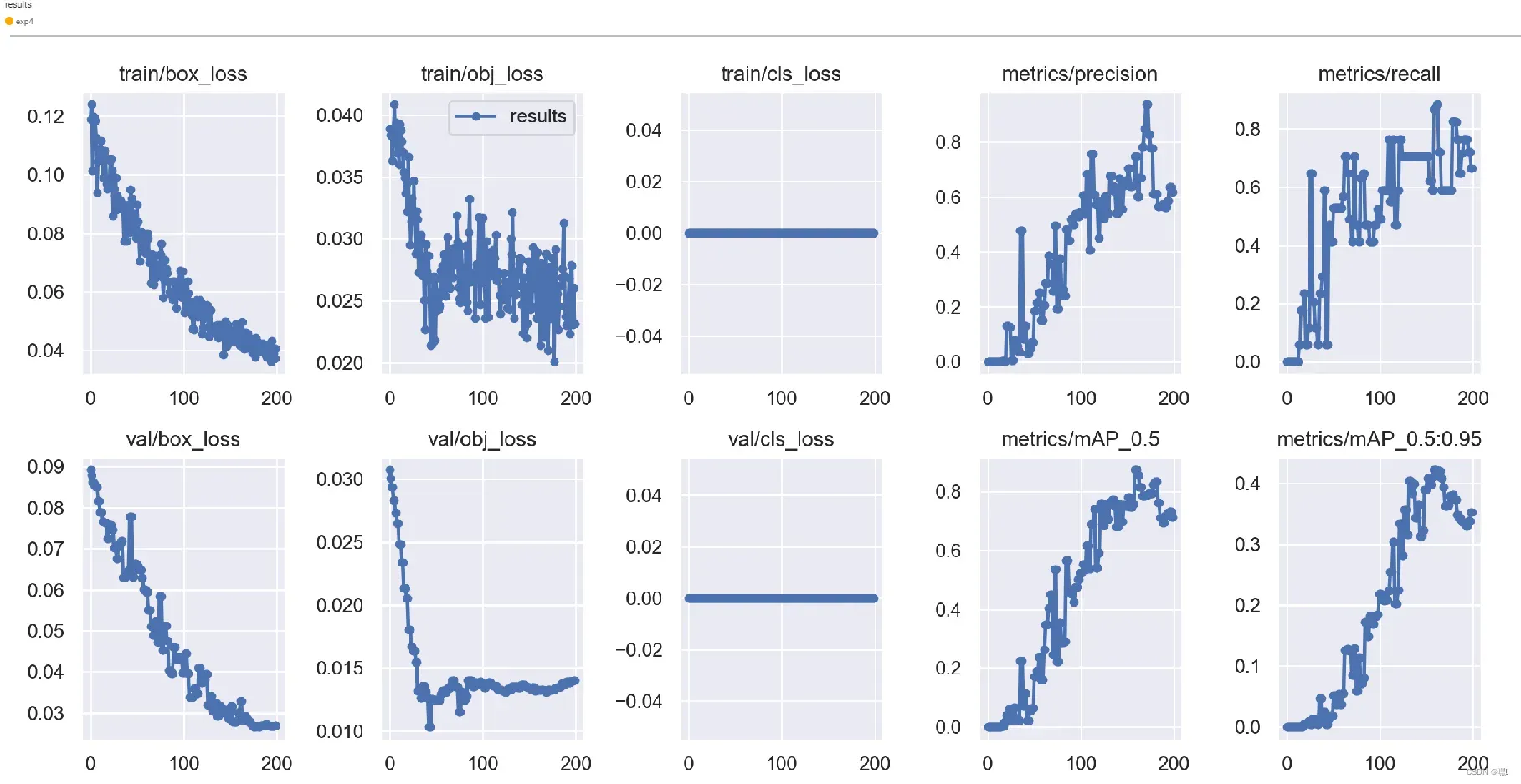
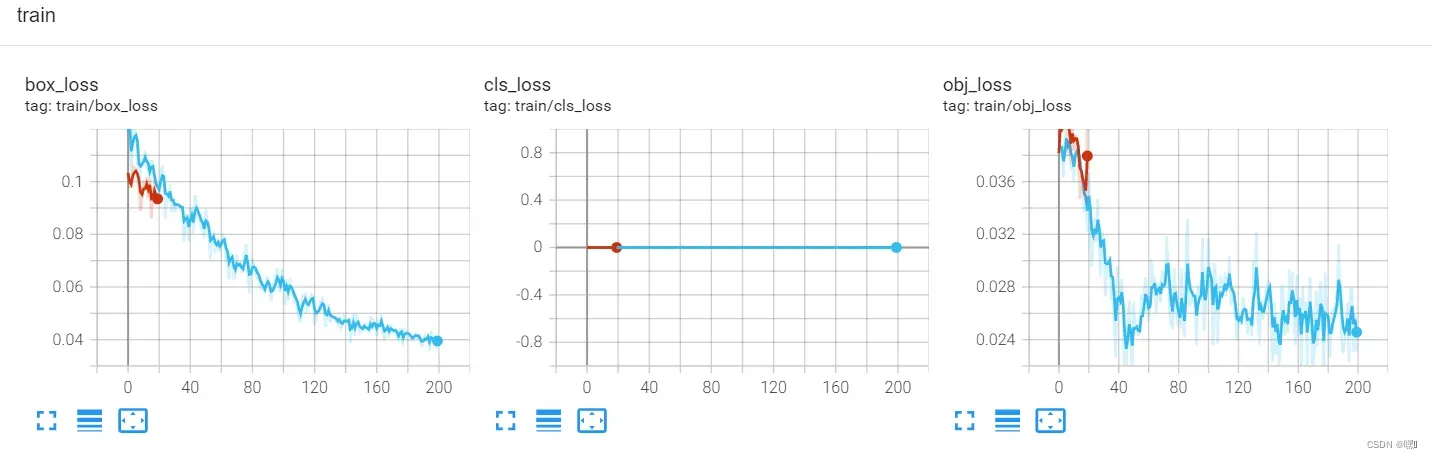
train
在 TensorBoard 中,train 标签通常用于记录训练过程的指标,例如损失值、准确率等。通常情况下,train 标签下会有多个子标签,代表不同的训练指标,比如 loss、accuracy 等。通过记录并可视化这些指标,可以更好地了解模型的训练情况,进而做出调整和优化。例如,当损失值随着训练步数增加而降低时,就可以确认模型在训练过程中是在逐渐学习的。
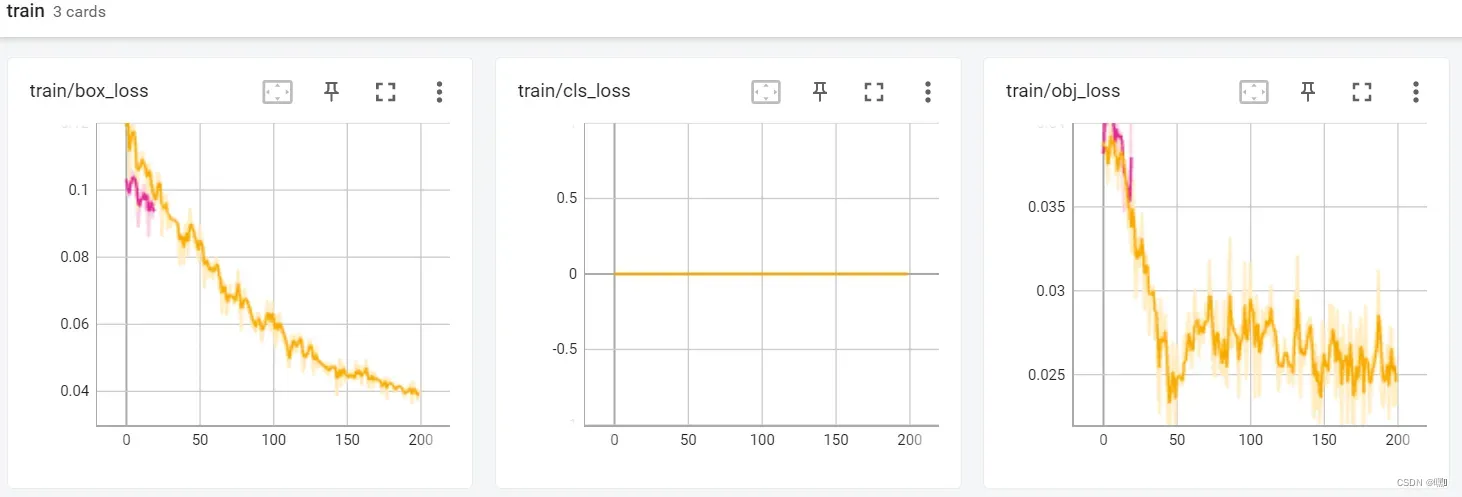
- box_loss计算目标框位置的误差,常用的计算方法是平方和误差或者L1误差,用于优化目标框的位置;
- cls_loss计算目标框类别的误差,常用的计算方法是交叉熵误差,用于优化目标框的类别;
- obj_loss计算目标框是否存在的误差,常用的计算方法是二元交叉熵误差,用于优化目标框是否存在
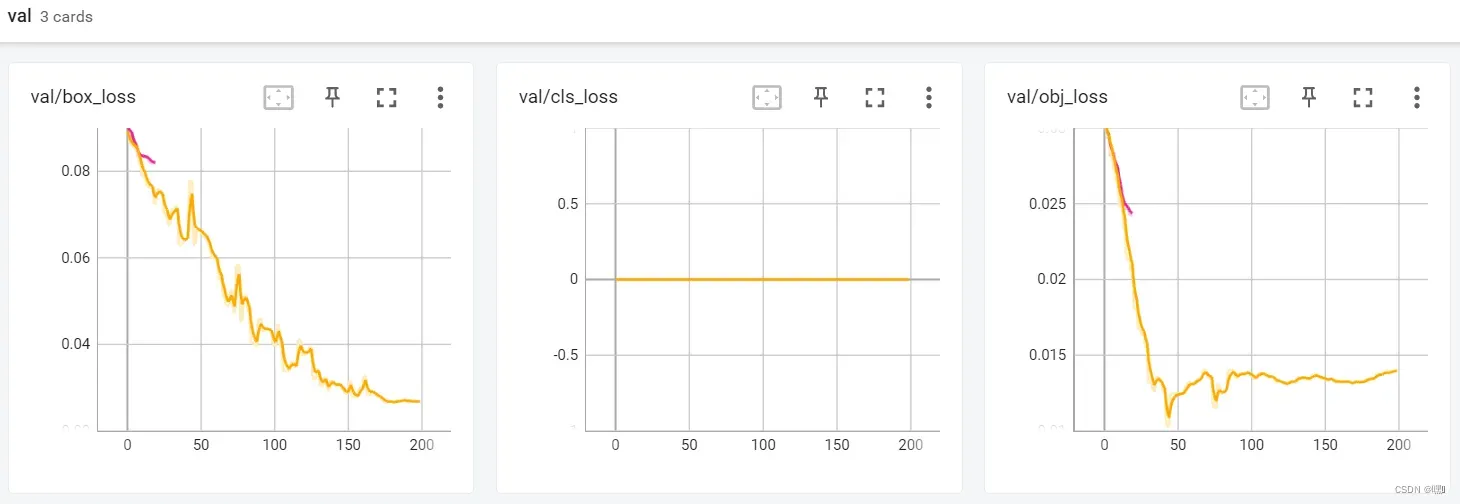
val
在深度学习中,通常使用训练集数据训练模型,使用验证集数据来评估模型的性能。因此,在使用TensorBoard进行可视化时,我们通常会将训练集和验证集的日志文件分别保存到不同的目录中。在TensorBoard中,val目录通常用于保存验证集数据的日志文件,可以用于展示模型在验证集上的性能表现,例如验证集损失函数变化情况、验证集准确率等。通过可视化这些指标,我们可以更好地了解模型在验证集上的表现,并进一步调整模型结构和超参数等。
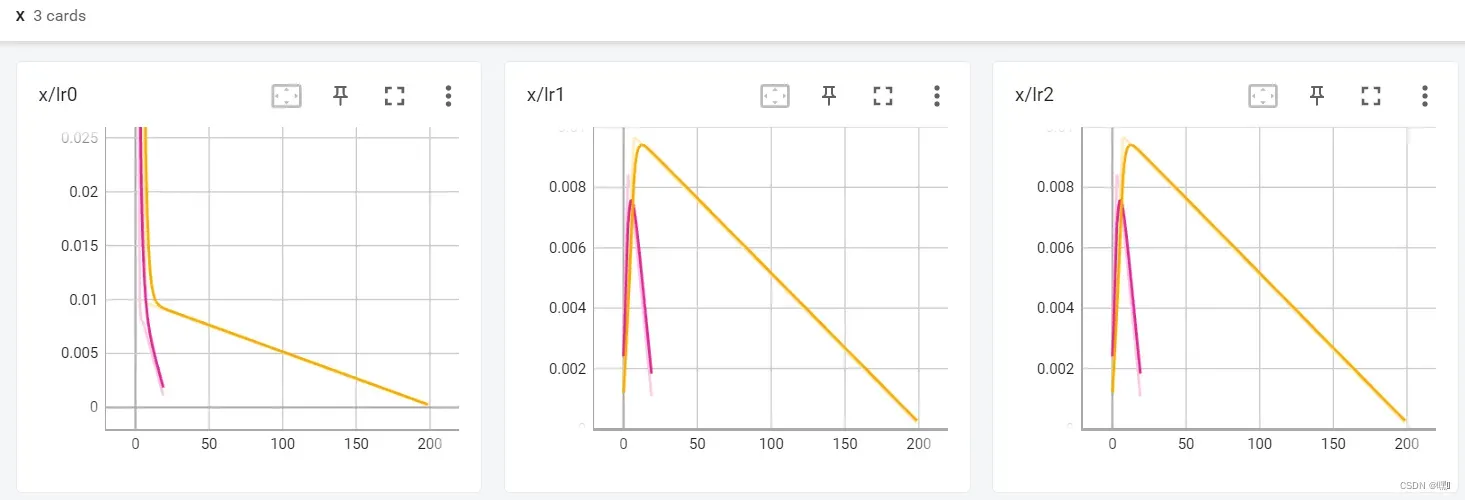
x
在 TensorBoard 的 Scalars 界面中,x 轴通常代表步数或时间。对于步数,它代表了模型在训练过程中的迭代次数或批次数;对于时间,它代表了从开始训练到当前的时间长度。在 x 轴上可以根据时间或步数绘制不同的曲线,帮助我们分析模型的训练进度和性能变化。
GRAPHS
GRAPH界面可以让我们直观地理解模型的结构,从而更好地进行模型的优化和调试。同时,它也能够帮助我们检查模型中是否存在梯度消失、梯度爆炸等问题,以及对模型进行可视化解释等。在GRAPHS界面中,我们可以选择不同的模型,查看其不同层之间的连接方式,同时还可以在界面中进行缩放和拖动操作,以便更好地查看整个计算图的结构。
文章出处登录后可见!