SE-Net、SK-Net与CBAM
1 SENet
原文链接:SENet原文
源码链接:SENet源码[0][1]
Squeeze-and-Excitation Networks(SENet)是由自动驾驶公司Momenta在2017年公布的一种全新的图像识别结构,它通过对特征通道间的相关性进行建模,把重要的特征进行强化来提升准确率。这个结构是2017 ILSVR竞赛的冠军,作者在原文中提到,SENet将top5的错误率达到了2.251%,比2016年的第一名还要低25%,在当年也是很有成就的一件事。
1.1 Squeeze-and-Excitation Blocks
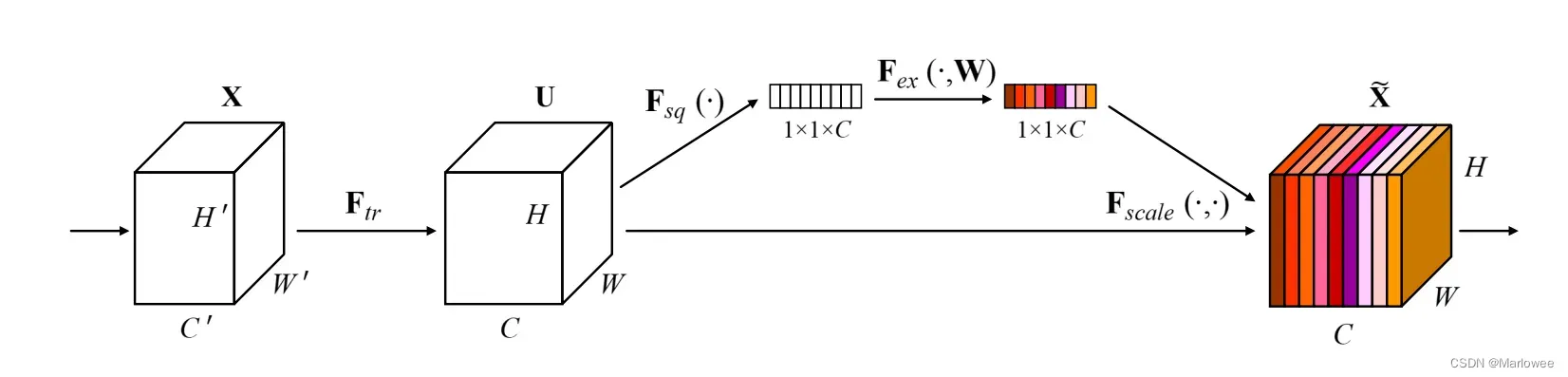
SE Block模块主要由Squeeze操作和Excitation操作组成:Squeeze操作负责将spatial维度进行全局池化(比如7 x 7 –>1 x 1);Excitation操作则学习池化后的通道依赖关系,并进行通道权重的赋权。上图网络结构其实很好地概括了SENet的主题思想,下面我将会从Squeeze和Excitation两个方面具体讲解。
1.1.1 Squeeze: Global Information Embedding
网络结构最开始的部分Ftr:X->U是以往的经典卷积结构,U之后的部分才是SENet的创新部分:使用全局平均池化在H和W两个维度对U进行Squeeze,将一个channel上整个空间特征编码为一个全局特征,得到1x1xC的中间输出。说得通俗点,这里其实就是使用一个二维的池化核对特征图进行降维,由原来的H、W、C上的3个维度降到了C这1个维度上,使得后续的通道赋权操作可行,其公式如下图所示: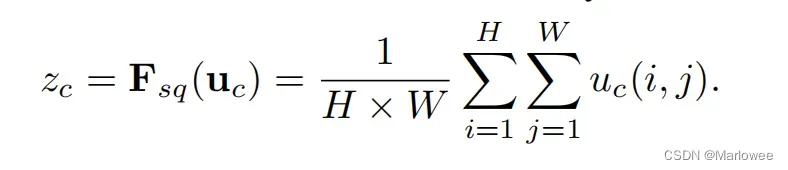
1.1.2 Excitation: Adaptive Recalibration
为了更好的学习到Squeeze操作得到的特征信息,作者使用Excitation操作获取通道之间的依赖关系。为了实现这一目标,作者分析到该函数必须满足两个标准:(1)它必须是灵活的(特别是能够学习通道之间的非线性交互作用);(2)它必须能够学习一种非互斥的关系(因为我们希望确保允许强调多个通道)。所以作者使用两个全连接层FC学习通道之间的依赖关系,最后再通过sigmoid函数对权重进行归一(将各通道的权重值限制在0-1,权重和限定为1),其公式如下: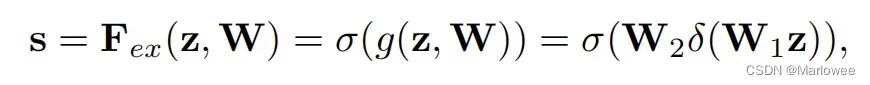
1.1.3 举个栗子:SE-ResNet Module
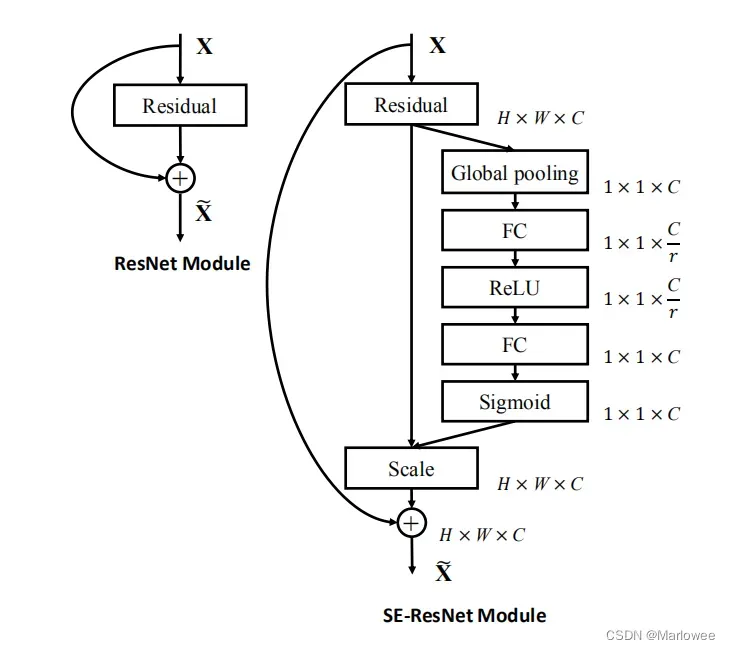
上图是SE-ResNet的网络结构。对于Residual阶段,SE-Block会通过一次全局池化进行降维(说降维可能不规范)得到通道C这一维度的特征,而后经过两层FC。第一层FC会继续降低C的维度,主要通过超参数r来实现(r是指压缩的比例,作者尝试了r在各种取值下的性能 ,最后得出结论r=16时整体性能和计算量最平衡);经过激活后,第二层FC则将压缩后的通道映射回原来的维度,最后利用Sigmoid函数对每个通道赋予不同的权重。
Scale代表将权重与待加权的特征相乘的操作,经过Scale操作后,channel维度上权重就完美地添加到特征中了。
1.2 代码实现
1.2.1 SE module
SE的实现如下代码所示,具体每一步我都做了详细的注释。如果前面的公式看不明白,对应这里的函数操作可能会帮助理解公式。
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)# Squeeze操作的定义
self.fc = nn.Sequential(# Excitation操作的定义
nn.Linear(channel, channel // reduction, bias=False),# 压缩
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),# 恢复
nn.Sigmoid()# 定义归一化操作
)
def forward(self, x):
b, c, _, _ = x.size()# 得到H和W的维度,在这两个维度上进行全局池化
y = self.avg_pool(x).view(b, c)# Squeeze操作的实现
y = self.fc(y).view(b, c, 1, 1)# Excitation操作的实现
# 将y扩展到x相同大小的维度后进行赋权
return x * y.expand_as(x)
1.2.2 SE-ResNet
下列代码展示了将SENet中加入到Resnet中残差链接前的操作,其实理论上来说SENet可以在浅层Block中添加(如添加在conv1前),也可以在深层中添加(bn2后),具体的添加位置要根据自身任务确定。 如果你的网络更关注浅层特征,如纹理特征,那么就可以加在浅层;相反,如果你的网络更关注深层特征,如轮廓特征、结构特征,那就应该加在深层, 具体问题具体分析。
class SEBasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None,
*, reduction=16):
super(SEBasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes, 1)
self.bn2 = nn.BatchNorm2d(planes)
self.se = SELayer(planes, reduction)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.se(out)# 加入通道注意力机制
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
2 SKNet
原文链接:SKNet原文
源码链接:SKNet源码[0][1]
CVPR2019的文章Selective Kernel Networks,这篇文章也是致敬了SENet的思想。 SENet提出了Sequeeze and Excitation block,而SKNet提出了Selective Kernel Convolution. 二者都可以很方便的嵌入到现在的网络结构,比如ResNet、Inception、ShuffleNet,实现精度的提升。
2.1 Selective Kernel Convolution
文章的重点是不同大小的感受野对不同尺度的目标有不同的影响,我们应该采取什么方法让网络自动使用对分类有效的感受野?为了解决这个问题,作者在文章中提出了卷积核的动态选择机制,可以让每个神经元根据输入信息的多尺度自适应地调整其感受野(卷积核)的大小。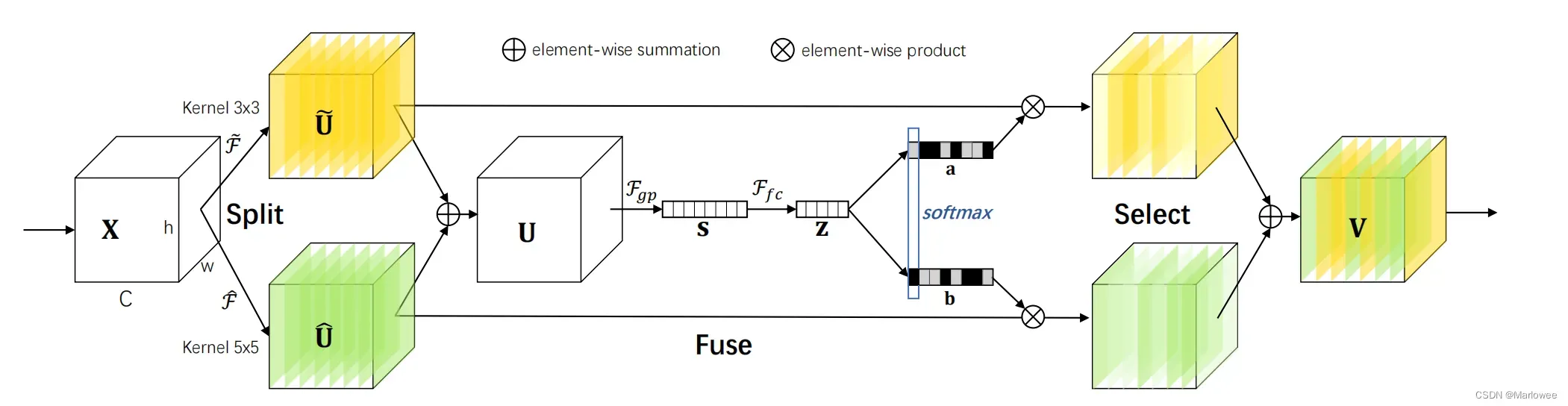
上图就是select kernel convolution模块,网络中主要包括Split、Fuse、Select三个操作。Split通过多条不同大小的kernel产生不同特征图,上图中的模型只设计了两个不同大小的卷积核,实际上可以设计多个分支的多个卷积核;Fuse运算结合并聚合来自多个路径的信息,以获得用于选择权重的全局和综合表示;select操作根据选择权重聚合不同大小内核的特征图。
2.1.1 Split
对输入X使用不同的卷积核生成不同的特征输出,上图所示的是使用3×3和5×5的卷积核进行的卷积操作,为了提高运算效率,5×5的卷积操作是用空洞率为2、卷积核为3×3的空洞卷积实现的,并且使用了分组卷积、深度可分离卷积、BatchNorm和ReLU。
2.1.2 Fuze
将得到的多个特征输出进行信息融合,即pytorch中的sum操作,得到新的特征图U,即下图中的公式(1);然后利用Squeeze相同的操作生成通道这个维度的信息,即下图中的公式(2);最后利用1层全连接层FC学习通道之间的依赖关系,最后使用ReLU和BatchNorm进行归一,即下图中的公式(3)。相关公式如下:
2.1.3 Select
在通道这个维度对多个分支得到的最终特征图进行赋权,使用sigmoid函数。最后将所有分支加权后的特征图相加,得到最终的输出。
2.2 代码实现
结合上面的解释,代码其实很清楚了。具体的定义和操作我已经评论过了。大家可以参考评论理解。
class SKConv(nn.Module):
def __init__(self, features, WH, M, G, r, stride=1 ,L=32):
super(SKConv, self).__init__()
d = max(int(features/r), L)
self.M = M
self.features = features
self.convs = nn.ModuleList([])
# 生成M个分支,将其添加到convs中,每个分支采用不同的卷积核和不同规模的padding,保证最终得到的特征图大小一致
for i in range(M):
self.convs.append(nn.Sequential(
nn.Conv2d(features, features, kernel_size=3+i*2, stride=stride, padding=1+i, groups=G),
nn.BatchNorm2d(features),
nn.ReLU(inplace=False)
))
# 学习通道间依赖的全连接层
self.fc = nn.Linear(features, d)
self.fcs = nn.ModuleList([])
for i in range(M):
self.fcs.append(
nn.Linear(d, features)
)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
for i, conv in enumerate(self.convs):
fea = conv(x).unsqueeze_(dim=1)
if i == 0:
feas = fea
else:
feas = torch.cat([feas, fea], dim=1)
fea_U = torch.sum(feas, dim=1)# 将多个分支得到的特征图进行融合
fea_s = fea_U.mean(-1).mean(-1)# 在channel这个维度进行特征抽取
fea_z = self.fc(fea_s)# 学习通道间的依赖关系
# 赋权操作,由于是对多维数组赋权,所以看起来比SENet麻烦一些
for i, fc in enumerate(self.fcs):
vector = fc(fea_z).unsqueeze_(dim=1)
if i == 0:
attention_vectors = vector
else:
attention_vectors = torch.cat([attention_vectors, vector], dim=1)
attention_vectors = self.softmax(attention_vectors)
attention_vectors = attention_vectors.unsqueeze(-1).unsqueeze(-1)
fea_v = (feas * attention_vectors).sum(dim=1)
return fea_v
3 CBAM
CBAM( Convolutional Block Attention Module )是一种轻量化的通道注意力机制,也是目前应用比较广泛的一种视觉注意力机制,在2018年的ECCV中提出。文章同时使用了Channel Attention和Spatial Attention,发现将两种attention串联在一起效果较好。
3.1 Convolutional Block Attention Module
下图是CBAM的网络结构图。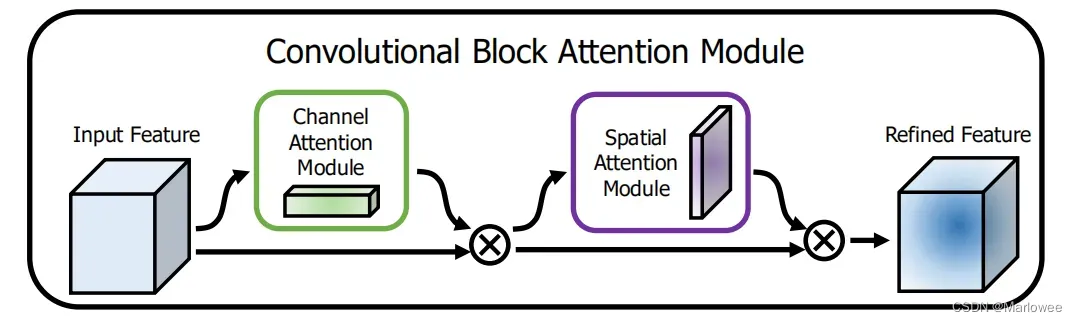
可以看到CBAM包含2个独立的子模块, 通道注意力模块(Channel Attention Module,CAM) 和空间注意力模块(Spartial Attention Module,SAM) ,分别进行通道与空间上的赋权。这样不只能够节约参数和计算力,并且保证了其能够做为即插即用的模块集成到现有的网络架构中去。
3.1.1 Channel attention module
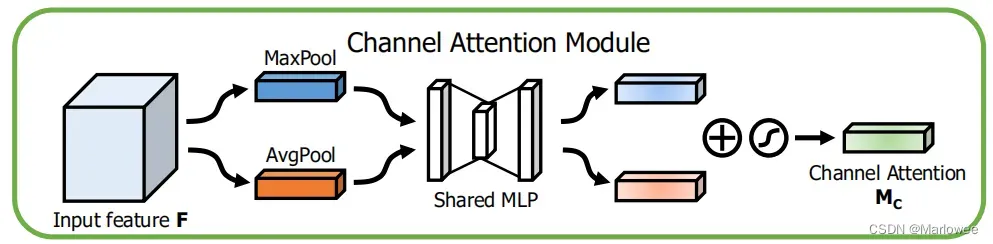
通道注意力机制的基本思想与SENet相同,但是具体操作与SENet略有不同,不同部分我用红色进行了标记。
首先,将输入的特征图F(H×W×C)分别经过基于H和W两个维度的 全局最大池化(MaxPool)和全局平均池化(AvgPool),得到两个1×1×C的特征图; 然后,将两个特征图送入一个 共享权值的双层神经网络(MLP)进行通道间依赖关系的学习,两层神经层之间通过压缩比r实现降维。 最后,将MLP输出的特征进行基于element-wise的加和操作,再经过sigmoid激活操作,生成最终的通道加权,即M_c。其公式如下图: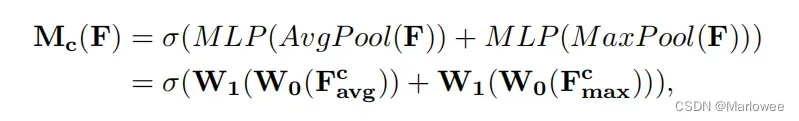
3.1.2 Spatial attention module
本来本篇专题主要对通道注意力机制进行讨论,想着下一篇空间注意力机制的时候再说CBAM的后续,但按照我懿姐的说法就是,算法都送到嘴边了,那我干脆一块解决了。
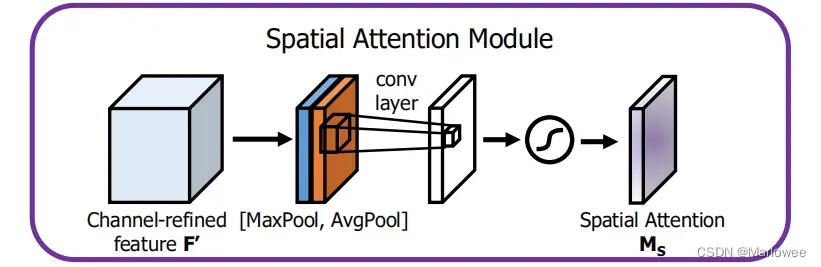
空间注意力机制将通道注意力模块输出的特征图F‘作为本模块的输入特征图。
首先,基于channel这个维度进行最大池化(MaxPool)和平均池化(AvgPool)操作,得到两个H×W×1 的特征图; 然后,将两个特征图基于通道维度进行拼接,即concat操作; 再然后,使用7×7卷积核(作者通过实验验证了7×7效果好于其他维度卷积核)进行通道降维,降维为单通道的特征图,即H×W×1; 最后,经过sigmoid学习空间元素之间的依赖关系,生成空间维度的权重,即M_s。其公式如下: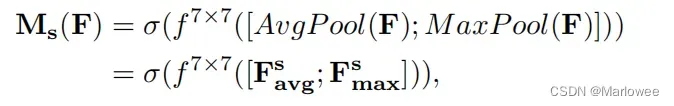
3.2 代码实现
3.2.1 CA&SA
具体的网络定义和操作实现可以参考我的代码注释。
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)# 定义全局平均池化
self.max_pool = nn.AdaptiveMaxPool2d(1)# 定义全局最大池化
# 定义CBAM中的通道依赖关系学习层,注意这里是使用1x1的卷积实现的,而不是全连接层
self.fc = nn.Sequential(nn.Conv2d(in_planes, in_planes // 16, 1, bias=False),
nn.ReLU(),
nn.Conv2d(in_planes // 16, in_planes, 1, bias=False))
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc(self.avg_pool(x))# 实现全局平均池化
max_out = self.fc(self.max_pool(x))# 实现全局最大池化
out = avg_out + max_out# 两种信息融合
# 最后利用sigmoid进行赋权
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
# 定义7*7的空间依赖关系学习层
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=kernel_size//2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)# 实现channel维度的平均池化
max_out, _ = torch.max(x, dim=1, keepdim=True)# 实现channel维度的最大池化
x = torch.cat([avg_out, max_out], dim=1)# 拼接上述两种操作的到的两个特征图
x = self.conv1(x)# 学习空间上的依赖关系
# 对空间元素进行赋权
return self.sigmoid(x)
3.2.2 CBAM_ResNet
篇幅限制,这里仅展示BasicBlock的CA&SA的添加
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
# 定义ca和sa,注意CA与channel num有关,需要指定这个超参!!!
self.ca = ChannelAttention(planes)
self.sa = SpatialAttention()
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.ca(out) * out# 对channel赋权
out = self.sa(out) * out# 对spatial赋权
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
文章出处登录后可见!