Waymo Open Dataset 数据集: Scalability in Perception for Autonomous Driving: Waymo Open Dataset – 自动驾驶感知的可扩展性:Waymo开放数据集(CVPR 2020)
声明:此翻译仅为个人学习记录
文章信息
- 标题:Scalability in Perception for Autonomous Driving: Waymo Open Dataset (CVPR 2020)
- 作者:Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aur´elien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, Vijay Vasudevan, Wei Han, Jiquan Ngiam, Hang Zhao, Aleksei Timofeev, Scott Ettinger, Maxim Krivokon, Amy Gao, Aditya Joshi, Yu Zhang, Jonathon Shlens, Zhifeng Chen, and Dragomir Anguelov
- 文章链接:https://arxiv.org/pdf/1912.04838v5.pdf
数据集简介
- 数据集官网:https://waymo.com/open/
- 数据集开发工具包:https://github.com/waymo-research/waymo-open-dataset
(依靠数据集开发工具包,可以了解标签的更多信息,并可以使用 Python 阅读标签,可视化点云)- 官方下载地址:https://waymo.com/open/download/
摘要
尽管获取具有代表性的真实世界数据的资源密集,但研究界对自动驾驶研究的兴趣与日俱增。现有的自动驾驶数据集在其捕获的环境的规模和变化方面受到限制,尽管操作区域内和操作区域之间的通用性对该技术的整体可行性至关重要。为了帮助研究界的贡献与现实世界中的自动驾驶问题保持一致,我们引入了一个新的大规模、高质量、多样化的数据集。我们的新数据集由1150个场景组成,每个场景跨度为20秒,包括在一系列城市和郊区地理位置上捕获的同步和校准的高质量激光雷达和相机数据。根据我们提出的多样性度量,它比最大的相机+激光雷达数据集的多样性高15倍。我们用2D(相机图像)和3D(激光雷达)边界框对该数据进行了详尽的注释,并在帧间使用一致的标识符。最后,我们为2D以及3D检测和跟踪任务提供了强大的基线。我们进一步研究了数据集大小和跨地理区域的泛化对3D检测方法的影响。查找数据、代码和更多最新信息http://www.waymo.com/open。
1. 导言
自动驾驶技术有望实现广泛的应用,这些应用有可能挽救许多人的生命,从自动驾驶出租车到自动驾驶卡车。公共大规模数据集和基准的可用性大大加快了机器感知任务的进展,包括图像分类、目标检测、目标跟踪、语义分割以及实例分割[7,17,23,10]。
为了进一步加快自动驾驶技术的发展,我们提供了迄今为止最大和最多样化的多模式自动驾驶数据集,包括由多个高分辨率相机记录的图像和安装在自动驾驶车辆车队上的多个高质量激光雷达扫描仪的传感器读数。我们的数据集捕获的地理区域远远大于任何其他可比的自动驾驶数据集所覆盖的区域,无论是在绝对区域覆盖率方面,还是在各个地理区域的覆盖率分布方面。数据记录了多个城市的一系列情况,即旧金山、凤凰城和山景城,每个城市的地理覆盖范围都很大。我们证明,这些地理位置的差异导致了明显的领域差距,从而在领域适应领域创造了令人兴奋的研究机会。
我们提出的数据集包含大量用于LiDAR数据的高质量、手动注释的3D真值边界框,以及用于相机图像的2D紧密拟合边界框。所有真值框都包含跟踪标识符,以支持目标跟踪。此外,研究人员可以使用我们提供的滚动快门感知投影库从3D LiDAR框中提取2D非模态的相机框。多模态真值有助于利用激光雷达和相机标注进行传感器融合的研究。我们的数据集包含大约1200万个LiDAR框注释和1000万个相机框注释,从而产生113k个LiDAR目标轨迹和160k个相机图像轨迹。所有标注均由经过培训的标签工使用生产级标签工具创建并随后进行审查。
我们使用由多个高分辨率相机和多个高质量激光雷达传感器组成的工业强度传感器套件记录了数据集的所有传感器数据。此外,我们提供了摄像机和激光雷达读数之间的同步,这为跨领域学习和转移提供了有趣的机会。我们以距离图像的形式发布激光雷达传感器读数。除了传感器特征(如伸长),我们还为每个距离图像像素提供精确的车辆姿态。这是第一个具有此类低级同步信息的数据集,使得对LiDAR输入表示的研究比流行的3D点集格式更容易。
我们的数据集目前包含1000个用于训练和验证的场景,以及150个用于测试的场景,其中每个场景跨越20秒。从地理保持区域中选择测试集场景,可以让我们评估在数据集上训练的模型在多大程度上推广到以前看不到的区域。
我们在数据集上展示了几种最先进的2D和3D目标检测和跟踪方法的基准结果。
2. 相关工作
高质量、大规模的数据集对自动驾驶研究至关重要。近年来,向社区发布数据集的努力越来越多。
大多数自动驾驶系统融合来自多个传感器的传感器读数,包括摄像头、激光雷达、雷达、GPS、车轮里程计和IMU。最近发布的自动驾驶数据集包括由多个传感器获得的传感器读数。Geiger等人于2012年引入了多传感器KITTI数据集[9,8],该数据集为22个序列提供同步立体摄像机和激光雷达传感器数据,实现了3D目标检测和跟踪、视觉里程计和场景流估计等任务。SemanticKITTI数据集[2]提供了将每个LiDAR点与KITTI数据库的所有22个序列中的28个语义类之一关联的注释。
2017年发布的ApolloScape数据集[12]为在各种交通条件下捕获的140k个摄像头图像提供了每像素语义注释,从简单场景到具有许多目标的更具挑战性场景。数据集进一步提供关于静态背景点云的姿态信息。KAIST多光谱数据集[6]按时段(如白天、夜间、黄昏和黎明)对包括热成像相机在内的多个传感器记录的场景进行分组。本田研究所3D数据集(H3D)[19]是一个3D目标检测和跟踪数据集,提供160个拥挤城市场景中记录的3D激光雷达传感器读数。
最近发布的一些数据集还包括有关环境的地图信息。例如,除了摄像机、激光雷达和雷达等多个传感器之外,nuScenes数据集[4]还提供了相关区域的光栅化自上而下语义图,这些语义图对1k场景的可驾驶区域和人行道信息进行编码。该数据集的LiDAR传感器质量有限,每帧34K点,有效面积为5km2的地理多样性有限的区域(表1)。
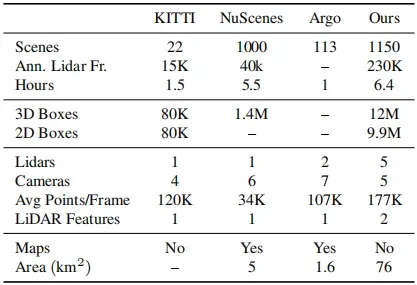
表1. 一些流行数据集的比较。Argo数据集仅指其跟踪数据集,而非运动预测数据集。投影到2D的3D标签不计入2D框中。Avg Points/Frame是根据发布的数据计算的所有LiDAR返回的点数。通过将每个自我姿势稀释150米并合并所有稀释的区域来测量面积。主要观察结果:1。我们的数据集具有15.2倍的有效地理覆盖率,由第3.5节中的多样性面积度量定义。2.我们的数据集比其他相机+激光雷达数据集更大。(第2节)
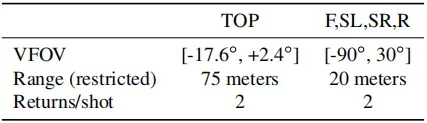
表2. 前(F)、右(R)、左侧(SL)、右侧(SR)和顶部(Top)传感器的LiDAR数据规格。垂直视野(VFOV)是根据倾角(第3.2节)规定的。
除了光栅化地图之外,Argorverse数据集[5]还提供了详细的环境几何和语义地图,包括地面高度信息以及道路车道及其连通性的矢量表示。他们进一步研究了所提供的地图背景对自动驾驶任务的影响,包括3D跟踪和轨迹预测。Argorverse发布的原始传感器数据非常有限。
不同数据集的比较见表1。
3. Waymo开放数据集
3.1 传感器规格
使用五个激光雷达传感器和五个高分辨率针孔摄像头进行数据采集。我们限制激光雷达数据的范围,并为每个激光脉冲的前两次返回提供数据。表2包含我们的激光雷达数据的详细规格。相机图像是通过滚动快门扫描拍摄的,精确的扫描模式可能会因场景而异。所有相机图像都被下采样并从原始图像中裁剪;表3提供了摄像机图像的规格。与数据集相关的传感器布局见图1。
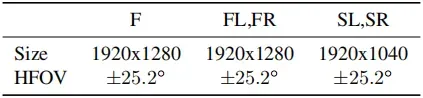
表3. 前(F)、左前(FL)、右前(FR)、左侧(SL)、右侧(SR)摄像头的摄像头规格。图像大小反映了裁剪和下采样原始传感器数据的结果。摄像机水平视野(HFOV)作为相机传感器帧x-y平面中x轴的角度范围提供(图1)。
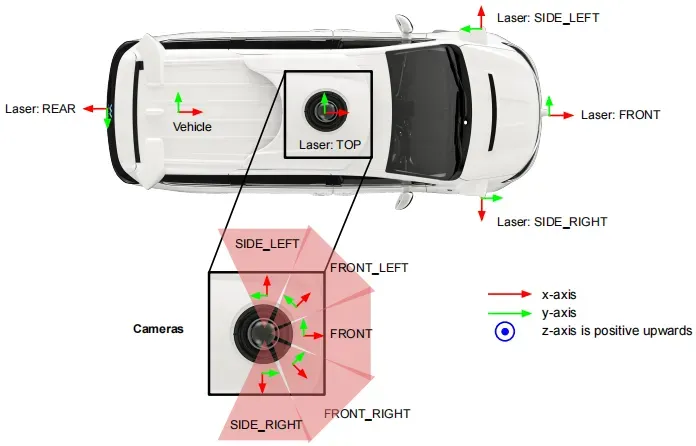
图1. 传感器布局和坐标系。
3.2 坐标系
本节介绍数据集中使用的坐标系。所有坐标系都遵循右手规则,数据集包含在运行段内任意两个帧之间转换数据所需的所有信息。
全局帧在车辆运动之前设置。它是一个东北向上的坐标系:向上(z)与重力向量对齐,正向上;东(x)点沿纬度线直接向东;北(y)指向北极。
车辆帧随车辆移动。其x轴向前为正,y轴向左为正,z轴向上为正。车辆姿态定义为从车辆帧到全局帧的4×4变换矩阵。全局帧可以用作不同车辆帧之间变换的代理。在该数据集中,近帧之间的变换非常准确。
为每个传感器定义了传感器帧。它表示为4×4变换矩阵,将数据从传感器帧映射到车辆帧。这也被称为“外在”矩阵。
LiDAR传感器帧的z指向上。x-y轴取决于激光雷达。
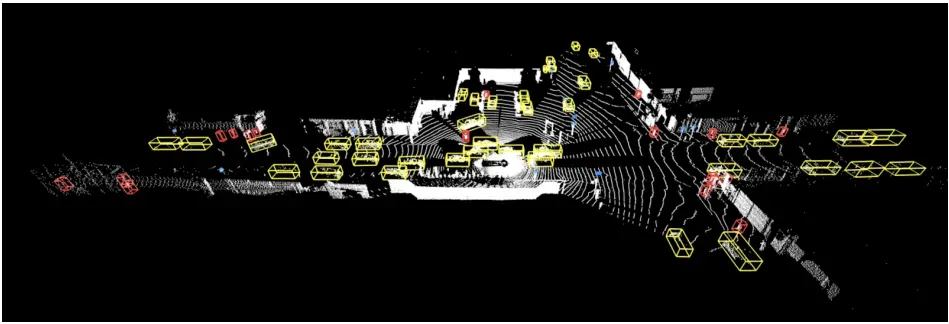
图2. LiDAR标签示例。黄色=车辆。红色=行人。蓝色=标志。粉色=骑车人。
相机传感器帧放置在镜头的中心。x轴指向镜头外的镜筒。z轴指向上。y/z平面与图像平面平行。
图像帧是为每个相机图像定义的2D坐标系+x是沿着图像宽度(即从左侧开始的列索引),+y是沿着图像高度(即从顶部开始的行索引)。原点位于左上角。
LiDAR球面坐标系基于LiDAR传感器帧中的笛卡尔坐标系。LiDAR笛卡尔坐标系中的点(x,y,z)可以通过以下方程唯一地转换为LiDAR球面坐标系中(距离、方位角、倾角)的元组:
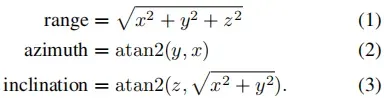
3.3 真值标签
我们为LiDAR传感器读数和相机图像提供高质量的真值注释。LiDAR和相机数据中的单独注释为传感器融合开辟了令人兴奋的研究途径。对于任何标签,我们将长度、宽度和高度分别定义为沿x轴、y轴和z轴的大小。
我们在激光雷达传感器读数中对车辆、行人、标志和骑车人进行了详尽的注释。我们将每个目标标记为具有唯一跟踪ID的7自由度3D直立边界框(cx,cy,cz,l,w,h,θ),其中cx,y,cz表示中心坐标,l,w,h表示长度、宽度、高度,α表示边界框的方向角(弧度)。图2举例说明了一个带注释的场景。
除了激光雷达标签,我们在所有相机图像中分别对车辆、行人和自行车进行了详尽的注释。我们用一个紧密拟合的4自由度图像轴对齐的2D边界框来标注每个目标,该边界框与3D框及其变形的2D投影互补。标签编码为(cx,cy,l,w),具有唯一的跟踪ID,其中cx和cy表示框的中心像素,l表示框在图像帧中沿水平(x)轴的长度,w表示框沿图像帧中垂直(y)轴的宽度。我们使用这种长度和宽度的约定来与3D框保持一致。使用数据集可以探索的一个有趣的可能性是仅使用相机预测3D框。在这种情况下,紧密贴合的框会有多大的帮助,这是一个悬而未决的问题,但我们已经可以注意到,非最大抑制对于非模态框来说是崩溃的。
如果真值标签被标注者标注为困难的标签,则手动标注为LEVEL_2,否则标注为LEVEL_1。与KITTI的难度分解类似,LEVEL_2的度量是累积的,因此包括LEVEL_1。不同的任务可以忽略一些真值标签,或将更多真值标签标注为LEVEL_2。例如,单帧3D目标检测任务忽略没有任何LiDAR点的所有3D标签,并将少于5个点(包括5个点)的所有3D标记注释为LEVEL_2。
我们强调,所有LiDAR和所有相机真值标签都是由经验丰富的人类注释员使用工业强度标签工具手动创建的。我们进行了多个阶段的标签验证,以确保高标签质量。
3.4 传感器数据
LiDAR数据在该数据集中被编码为距离图像,每个LiDAR返回一个;提供了前两次返回的数据。距离图像格式与滚动快门相机图像相似,从左到右逐列填充。每个距离图像像素对应于激光雷达回波。高度和宽度由LiDAR传感器帧中倾斜和方位角的分辨率确定。提供每个距离图像行的每个倾斜。行0(图像的顶行)对应于最大倾斜。列0(图像的最左列)对应于负x轴(即,向后方向)。图像的中心对应于正x轴(即,正向)。需要进行方位角校正,以确保距离图像的中心与正x轴相对应。
距离图像中的每个像素都包含以下属性。图4展示了一个示例距离图像。
-
距离:LiDAR传感器帧中LiDAR点与原点之间的距离。
-
强度:表示产生激光雷达点的激光脉冲返回强度的测量值,部分基于激光脉冲撞击目标的反射率。
-
伸长率:激光脉冲的伸长率超过其标称宽度。例如,长脉冲延长可以指示激光反射可能被涂抹或折射,从而使返回脉冲在时间上被拉长。
-
无标签区域:该字段指示LiDAR点是否属于无标签区域,即标记时忽略的区域。
-
车辆姿态:捕捉激光雷达点时的姿态。
-
相机投影:我们提供精确的LiDAR点对相机图像投影,并对滚动快门效果进行补偿。图5显示了LiDAR点可以通过投影精确地映射到图像像素。
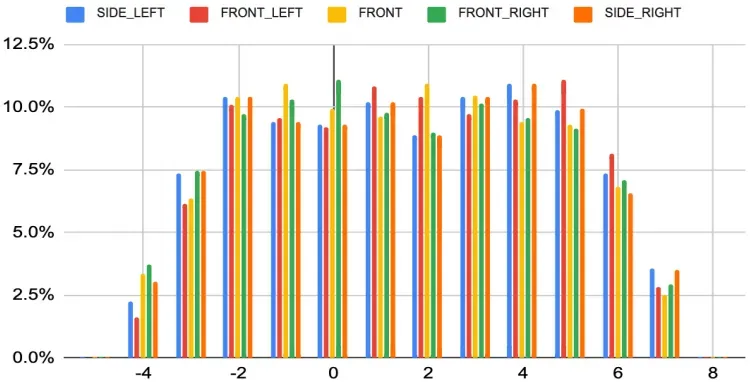
图3. 相机激光雷达同步精度(毫秒)。x轴上的数字以毫秒为单位。y轴表示数据帧的百分比。
我们的相机和激光雷达数据同步良好。同步精度计算如下

camera_center_time是图像中心像素的曝光时间。frame_start_time是此数据帧的开始时间。 camera_center_offset是每个相机传感器帧的+x轴相对于车辆向后方向的偏移。camera_center_offset为90°对于SIDE_LEFT相机,90°+ 45° 对于FRONT_LEFT相机等。所有相机的同步精度见图3。同步误差的范围为[-6ms,7ms],置信度为99.7%,[-6ms、8ms],置信率为99.9995%。
相机图像是JPEG压缩图像。滚动快门定时信息被提供给每个图像。
3.5 数据集分析
该数据集有从郊区和城市地区选择的场景,这些场景来自一天中的不同时间。分布情况见表4。除了城市/郊区和白天时间的多样性,数据集中的场景是从城市中的许多不同部分选择的。我们将数据集多样性度量定义为数据集中所有150米稀释自我姿态的联合面积。根据这个定义,我们的数据集涵盖凤凰城40平方公里的面积,以及旧金山和山景城36平方公里的总面积。所有场景中所有自我姿势接触的所有level 13 S2 cells[1]的平行四边形覆盖图见图6。
数据集具有12M个标记的3D激光雷达目标和113K个唯一的激光雷达跟踪ID,9.9M个标记的2D图像目标和210K个唯一图像跟踪ID。每个类别的计数见表5。

图4. 距离图像示例。裁剪后仅显示正面90°。前三行是第一次激光雷达返回的距离、强度和延伸率。最后三个是第二次激光雷达返回的距离、强度和延伸率。

图5. 用LiDAR点投影覆盖的示例图像。

表4. 凤凰城(PHX),山景(MTV)和旧金山(SF)的场景数以及训练和验证集的不同时间。
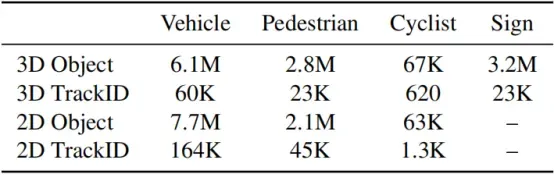
表5. 不同目标类型的标记目标和跟踪ID计数。3D标签是LiDAR标签。2D标签是相机图像标签。
4. 任务
我们为数据集定义了2D和3D目标检测和跟踪任务。我们预计将在未来增加其他任务,如分割、领域适应、行为预测和模拟规划。
为了一致地报告结果,我们提供了预定义的训练集(798个场景)、验证集(202个场景)和测试集(150个场景)划分。每个标签类别中的目标数量见表5。LiDAR标注捕获半径75m内的所有目标。相机图像注释捕获相机图像中可见的所有目标,与LiDAR数据无关。
4.1 目标检测
4.1.1 3D检测
对于给定的帧,3D检测任务包括预测车辆、行人、标志和骑车人的3D直立框。检测方法可以使用来自任何LiDAR和相机传感器的数据;它们还可以选择利用来自先前帧的传感器输入。
平均精度(AP)和航向精度加权平均精度(APH)用作检测度量:
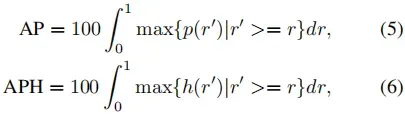
其中p(r)是p/r曲线。此外,h(r)的计算类似于p(r),但每个真阳性均通过定义为的航向精度进行加权,其中
和θ是预测航向,真值航向以弧度表示,在[-π,π]内。度量实现采用一组分数归一化为[0,1]的预测,并在此区间内统一采样固定数量的分数阈值。对于采样的每个分数阈值,它在分数高于阈值的预测和真值之间进行匈牙利匹配,以最大化匹配对之间的总体IoU。它根据匹配结果计算精度和召回率。如果PR曲线上两个连续操作点的召回值之间的差距大于预设阈值(设置为0.05),则更多的p/r点以保守的精度明确插入其间。示例:p(r):p(0)=1.0,p(1)=0.0,δ=0.05。我们将p(0.95)=0.0,p(0.90)=0.0…,p(0.05)=0.0添加。增强后AP=0.05。这避免了使用非常稀疏的p/r曲线采样产生过估计的AP。这种实现可以很容易地并行化,这使得在大型数据集上进行评估时更加高效。IoU用于确定车辆、行人和骑车人的真阳性。方框中心距离用于确定标志的真阳性。
4.1.2 相机图像中的2D目标检测
与3D检测任务相反,2D相机图像检测任务将输入数据限制为相机图像,不包括LiDAR数据。任务是基于单个相机图像在相机图像中生成2D轴对齐的边界框。对于此任务,我们考虑车辆、行人和骑车人的目标类别的AP度量。除了使用2D IoU进行匹配之外,我们使用与第4.1.1节所述相同的AP度量实现。
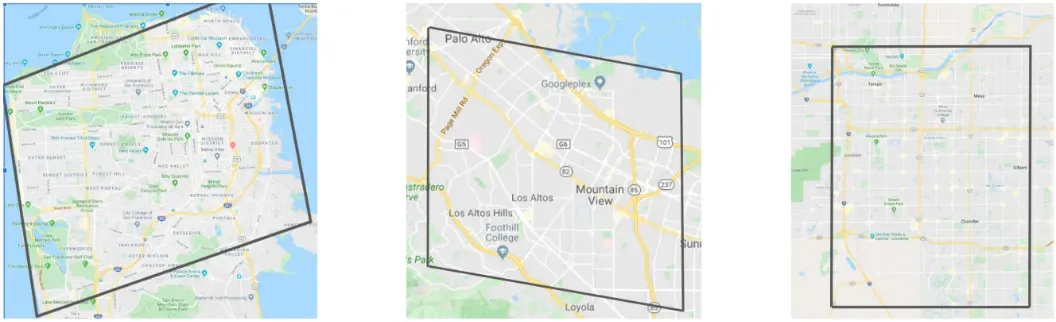
图6. 在旧金山、山景城和凤凰城,所有自我姿势触及的13级S2细胞的平行图覆盖。
4.2 目标跟踪
多目标跟踪涉及随着时间的推移准确跟踪场景中目标的身份、位置和可选属性(例如形状或长方体尺寸)。
我们的数据集被组织成序列,每个序列长20秒,多个传感器产生10Hz采样的数据。此外,数据集中的每个目标都用在每个序列中一致的唯一标识符进行注释。我们支持在2D图像视图和3D车辆中心坐标中评估跟踪结果。
为了评估跟踪性能,我们使用多目标跟踪(MOT)度量[3]。该度量旨在将跟踪系统的几个不同特性(即跟踪器随时间检测、定位和跟踪目标身份的能力)合并为一个度量,以帮助直接比较方法质量:
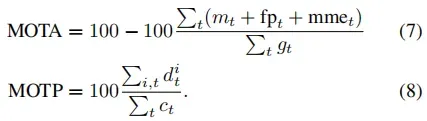
与4.1中描述的检测度量实现类似,我们直接对分数进行采样,并计算每个分数截止值的MOTA。我们在所有分数截止值中选择最高的MOTA作为最终指标。
5. 实验
我们基于最近的车辆和行人检测和跟踪方法,在数据集上提供基线。相同的方法可以应用于数据集中的其他目标类型。在计算所有任务的指标时,车辆使用0.7 IoU,行人使用0.5 IoU。
5.1 目标检测基线
3D激光雷达检测 为了建立3D目标检测基线,我们重新实现了PointPillars[16],这是一种简单高效的基于LiDAR的3D检测器,它首先使用单层PointNet[20]将点云体素化为鸟瞰图,然后是CNN区域提案网络[25]。我们在包含所有激光雷达的单帧传感器数据上训练模型。该数据集为利用传感器数据序列获得更好结果的模型提供了令人兴奋的研究方向。
对于车辆和行人,我们将体素大小设置为0.33m,网格范围沿X轴和Y轴设置为[-85m,85m],沿Z轴设置为[−3m,3m]。这为我们提供了512×512像素的鸟瞰图(BEV)伪图像。我们使用与原始论文相同的卷积主干架构[16],只是我们的车辆模型与行人模型匹配,第一个卷积块的步长为1。这一决定意味着模型的输入和输出空间分辨率均为512×512像素,这以更昂贵的模型为代价提高了精度。我们将车辆锚定尺寸(l、w、h)定义为(4.73m、2.08m、1.77m),行人锚定尺寸为(0.9m、0.86m、1.71m)。车辆和行人的锚都指向0和π/2弧度。为了实现良好的航向预测,我们使用了不同的旋转损失公式,使用了航向残余误差的平滑L1损失,将结果封装在[-π,π]之间,轮毂δ=1/9。我们还使用动态体素化[24],其中每个具有点的位置都被体素化,而不是具有固定数量的柱。
除了第3.3节中的LEVEL定义外,单帧3D目标检测任务忽略所有没有任何点的3D标签,并将具有5个点(包括5个点)的3D标签注释为LEVEL 2。
我们评估了150个场景隐藏测试集上7自由度3D框和5自由度BEV框的提议3D检测度量模型。对于我们的3D任务,车辆使用0.7 IoU,行人使用0.5 IoU。表6显示了详细结果;我们可以大致得出结论:1)在这个新的数据集中,车辆检测更困难;2) 我们可以用足够数量的行人数据建立一个适当的行人3D目标检测模型。
这些基线仅为激光雷达;在该数据集上研究相机+LiDAR、仅相机或时间3D目标检测方法是令人兴奋的。
相机图像中的2D目标检测 我们使用更快的R-CNN目标检测架构[21],ResNet-101[11]作为特征提取器。在对数据集上的模型进行微调之前,我们在COCO数据集上对模型进行了预训练[17]。然后,我们对所有5幅相机图像运行检测器,并汇总结果进行评估。由此得出的模型在车辆的LEVEL_1 AP为68.4,在LEVEL_2 AP为57.6,行人的LEVEL_1 AP为55.8,在LEVEL_2 AP为52.7。结果表明,该数据集上的2D目标检测任务极具挑战性,这可能是由于驾驶环境、目标外观和目标大小的巨大差异。
5.2 多目标跟踪基线
3D跟踪 我们提供了一个在线3D多目标跟踪基线,遵循常见的检测再跟踪模式,严重依赖于上述PointPillars[16]模型。我们的方法在精神上与[22]相似。在此范例中,在每个时间步t的跟踪包括运行检测器以生成检测={
,
,…,
},其中n是检测总数,将这些检测与我们的跟踪
={
,
,……,
}相关联,其中m是当前的跟踪数,并且在给定来自检测
的新信息的情况下更新这些跟踪
的状态。此外,我们需要提供出生和死亡过程,以确定给定跟踪何时为“死亡”(不匹配)、“待定”(还不够自信)和“生存”(从跟踪器返回)。
对于我们的基线,我们使用上面已经训练过的PointPillars[16]模型,1−IOU作为我们的代价函数,匈牙利方法[15]作为我们的赋值函数,卡尔曼滤波器[13]作为我们的状态更新函数。我们忽略低于0.2类别分数的检测,并将跟踪和检测的最小阈值设置为0.5 IoU,以将其视为匹配。我们的跟踪状态由具有恒定速度模型的10参数状态={cx,cy,cz,w,l,h,α,vx,vy,vz}组成。对于我们的出生和死亡过程,我们简单地用相关的检测分数增加跟踪的分数(如果看到),如果跟踪不匹配,则减少固定成本(0.3),并提供分数的下限和上限[0,3]。车辆和行人的结果见表7。对于车辆和行人来说,失配百分比都很低,这表明采用匈牙利算法[15]的IoU是一种合理的分配方法。MOTA的大部分损失似乎是由于定位、召回或框形预测问题导致的失误。
2D跟踪 我们使用视觉多目标跟踪方法Tracktor[14],该方法基于我们在COCO数据集[17]上预训练的更快的R-CNN目标检测器,然后在我们的数据集上进行微调。我们在数据集上优化了Tracktor方法的参数,并将σactive设置为0.4,λactive设置为0.6,λnew设置为0.3。在跟踪车辆时,所得到的Tracker模型在LEVEL_1达到了19.0的MOTA,在LEVEL_2达到了15.4。
5.3 领域差距
我们数据集中的大多数场景都记录在三个不同的城市(表4),即旧金山、凤凰城和山景城。在本实验中,我们将凤凰城和山景视为一个名为郊区(SUB)的区域。SF和SUB具有相似的场景数量(表4)和不同的目标总数(表8)。由于这两个领域以令人着迷的方式彼此不同,因此我们数据集中的领域差距为领域适应领域开辟了令人兴奋的研究途径。我们通过评估在训练集的一个域中记录的数据和在验证集的另一个域评估的数据上训练的目标检测器的性能,研究了该域差距的影响。
我们使用了第5.1节中描述的目标检测器。我们过滤训练和验证数据集,使其仅包含来自特定地理子集(称为SF(旧金山)、SUB(MTV+Phoenix)或ALL(所有数据))的帧,并重新训练和评估这些划分排列的模型。表9总结了我们的结果。对于基于3D激光雷达的车辆目标检测器,我们观察到,与SUB训练和SUB评估相比,在SF上训练和评估SUB时APH降低8.0,在SUB上训练和评价SF时APH减少7.6。对于行人的3D目标检测,结果很有趣。当评估SUB时,SF或SUB的训练产生类似的APH,而所有数据的训练产生7+APH改善。在SF上进行评估时,该结果不成立。与在更大的组合数据集上进行的训练相比,仅在SF上进行训练时,产生了2.4 APH的改善,而仅在SUB上进行训练和在SF上评估导致了19.8 APH的损失。行人的这种有趣行为可能是由于SUB(MTV+凤凰城)的行人数量有限。总的来说,这些结果表明旧金山和凤凰城在3D目标检测方面存在明显的领域差距,这为利用半监督或非监督领域自适应算法缩小差距开辟了令人兴奋的研究机会。

表6. 车辆和行人的基准APH和AP。

表7. 车辆和行人的基线多目标跟踪指标。
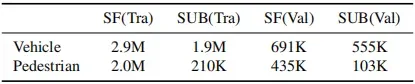
表8. 训练(Tra)和验证(Val)集合中每个域的3D LiDAR目标计数。

表9. 验证集上3D车辆和行人的域转移的3D目标检测基线LEVEL_2 APH结果。IoU阈值:车辆0.7,行人0.5。
5.4 数据集大小
更大的数据集支持对数据密集型算法的研究,如Lasernet[18]。对于在小数据集(如PointPillars[16])上运行良好的方法,更多数据可以获得更好的结果,而不需要数据增强:我们在训练序列子集上训练了第5.1节中的相同PointPillars模型[16],并在测试集上评估了这些模型。为了获得有意义的结果,这些子集是累积的,这意味着序列的较大子集包含较小的子集。这些实验的结果见表10。

表10. 随着数据集大小的增加,车辆和行人测试集上LEVEL_2 AP/APH难度。每列使用训练集的累积随机切片,其大小由第一行中的百分比确定。
6. 结论
我们提出了一个大型多模态相机+激光雷达数据集,它比任何现有的类似数据集都大得多,质量更高,地理位置更多样。它覆盖了76平方公里,结合了150米的稀释自车位姿。我们在这个数据集中展示了凤凰城、山景城和旧金山数据之间的领域多样性,这为领域适应开辟了令人兴奋的研究机会。我们在数据集上评估了2D和3D目标检测器和跟踪器的性能。数据集和相应的代码是公开的;我们将保持一个公共排行榜,以跟踪任务的进展。未来,我们计划添加地图、更多标记和未标记的数据,这些数据具有更多的多样性,侧重于不同的驾驶行为和不同的天气条件,以便对其他与自动驾驶相关的任务进行令人兴奋的研究,如行为预测、规划和更多样的领域适应。
References
[1] S2 geometry. http://s2geometry.io/. 5
[2] Jens Behley, Martin Garbade, Andres Milioto, Jan Quenzel, Sven Behnke, Cyrill Stachniss, and Juergen Gall. Semantickitti: A dataset for semantic scene understanding of lidar sequences. In Proc. of the IEEE/CVF International Conf. on Computer Vision (ICCV), 2019. 2
[3] Keni Bernardin and Rainer Stiefelhagen. Evaluating multiple object tracking performance: The clear mot metrics. 2008. 6
[4] Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. CoRR, abs/1903.11027, 2019. 2
[5] Ming-Fang Chang, John Lambert, Patsorn Sangkloy, Jagjeet Singh, Slawomir Bak, Andrew Hartnett, De Wang, Peter Carr, Simon Lucey, Deva Ramanan, and James Hays. Argoverse: 3d tracking and forecasting with rich maps. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2019. 2
[6] Yukyung Choi, Namil Kim, Soonmin Hwang, Kibaek Park, Jae Shin Yoon, Kyounghwan An, and In So Kweon. Kaist multi-spectral day/night data set for autonomous and assisted driving. IEEE Transactions on Intelligent Transportation Systems, 19(3). 2
[7] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition. 1
[8] Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The kitti dataset. International Journal of Robotics Research (IJRR), 2013. 2
[9] Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. In Conference on Computer Vision and Pattern Recognition (CVPR), 2012. 2
[10] Agrim Gupta, Piotr Dollar, and Ross Girshick. Lvis: A dataset for large vocabulary instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 1
[11] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition. 7
[12] Xinyu Huang, Xinjing Cheng, Qichuan Geng, Binbin Cao, Dingfu Zhou, Peng Wang, Yuanqing Lin, and Ruigang Yang. The apolloscape dataset for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. 2
[13] Rudolph Emil Kalman. A new approach to linear filtering and prediction problems. Transactions of the ASME–Journal of Basic Engineering, 82(Series D). 7
[14] Chanho Kim, Fuxin Li, and James M Rehg. Multi-object tracking with neural gating using bilinear lstm. In ECCV, 2018. 7
[15] Harold W. Kuhn and Bryn Yaw. The hungarian method for the assignment problem. Naval Res. Logist. Quart, 1955. 7
[16] Alex H Lang, Sourabh Vora, Holger Caesar, Lubing Zhou, Jiong Yang, and Oscar Beijbom. Pointpillars: Fast encoders for object detection from point clouds. CVPR, 2019. 6, 7, 8
[17] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision. 1, 7
[18] Gregory P Meyer, Ankit Laddha, Eric Kee, Carlos VallespiGonzalez, and Carl K Wellington. Lasernet: An efficient probabilistic 3d object detector for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 8
[19] Abhishek Patil, Srikanth Malla, Haiming Gang, and Yi-Ting Chen. The h3d dataset for full-surround 3d multi-object detection and tracking in crowded urban scenes. In Proceedings of IEEE Conference on Robotics and Automation (ICRA). 2
[20] Charles Ruizhongtai Qi, Hao Su, Kaichun Mo, and Leonidas J. Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017. 6
[21] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in neural information processing systems. 7
[22] Xinshuo Weng and Kris Kitani. A baseline for 3d multi-object tracking. arXiv:1907.03961, 2019. 7
[23] Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Scene parsing through ade20k dataset. In Proceedings of the IEEE conference on computer vision and pattern recognition. 1
[24] Yin Zhou, Pei Sun, Yu Zhang, Dragomir Anguelov, Jiyang Gao, Tom Ouyang, James Guo, Jiquan Ngiam, and Vijay Vasudevan. End-to-end multi-view fusion for 3d object detection in lidar point clouds. 2019 Conference on Robot Learning (CoRL), 2019. 7
[25] Y. Zhou and O. Tuzel. Voxelnet: End-to-end learning for point cloud based 3d object detection. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018. 6
A. 3D Segmentation 概述
具有丰富语义的每个激光雷达点的密集标签-23类,如下所示。为高分辨率激光雷达传感器捕获的整个数据集提供2Hz的标签。
我们包括以下23个细粒度类别:汽车、卡车、公共汽车、摩托车手、自行车手、行人、标志、交通灯、杆子、建筑锥、自行车、摩托车、建筑、植被、树干、路缘、道路、车道标志、可步行、人行道、其他地面、其他车辆、未定义

文章出处登录后可见!