1、Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation
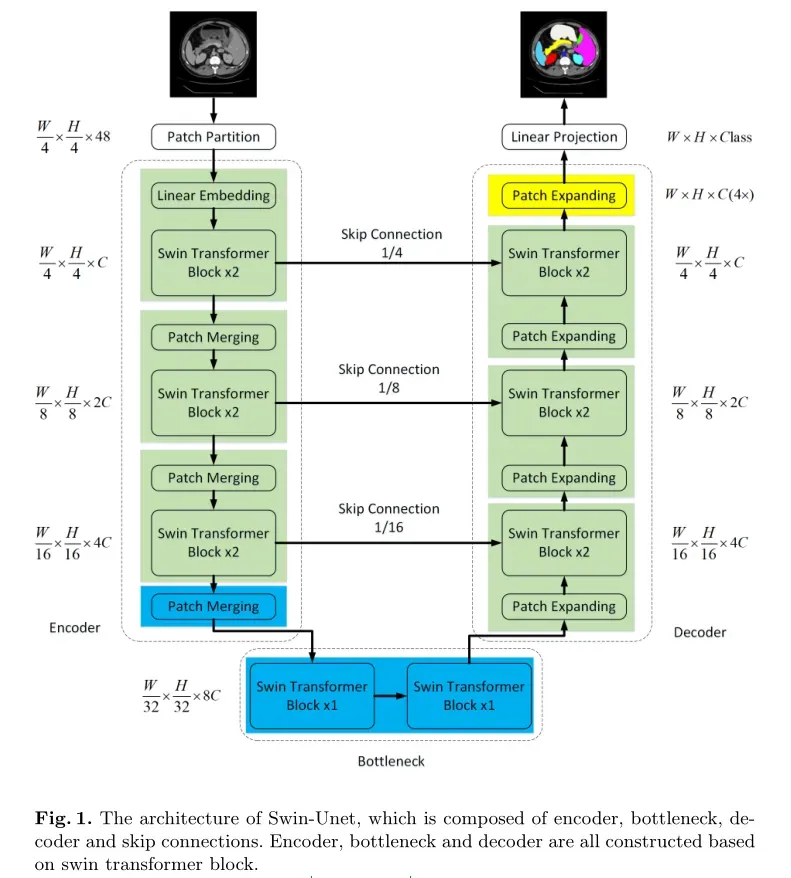
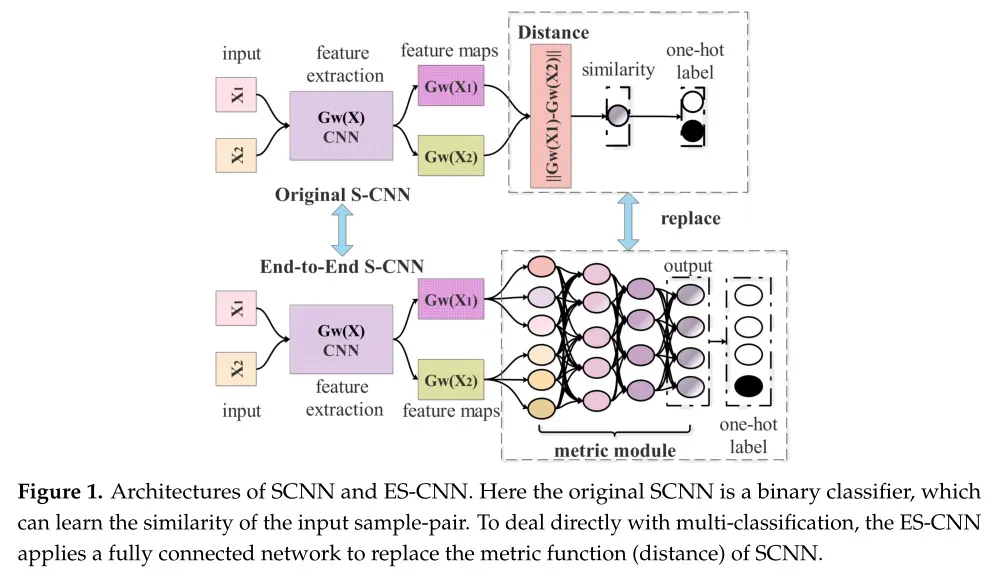
Swin Unet的总体架构如图所示。

编辑
Swin Unet由编码器、瓶颈、解码器和跳跃连接组成。Swin Unet的基本单元是Swin Transformer模块。对于编码器,为了将输入转换为序列嵌入,将医学图像分割为不重叠的patches,patches大小为4×4。通过这种分区方法,每个patches的特征维数变为4×4×3=48。变换后的patch tokens通过几个Swin Transformer块和patch merging层来生成分层特征表示。具体来说,patch merging层负责下采样和增加维度,Swin Transformer块负责特征表示学习。受U-Net的启发,作者设计了一种基于Transformer的对称解码器。解码器由Swin Transformer块和patch expanding层组成。提取的上下文特征通过跳跃连接与来自编码器的多尺度特征融合,以补充下采样导致的空间信息损失。与patch merging层不同,patch expanding层用于执行上采样。patch expanding层将相邻维度的特征图重塑为分辨率为2倍上采样的大特征图。最后,最后一个patch expanding层用于执行4×上采样,以将特征图的分辨率恢复到输入分辨率(W×H),然后在这些上采样的特征上应用线性投影层以输出像素级分割预测。
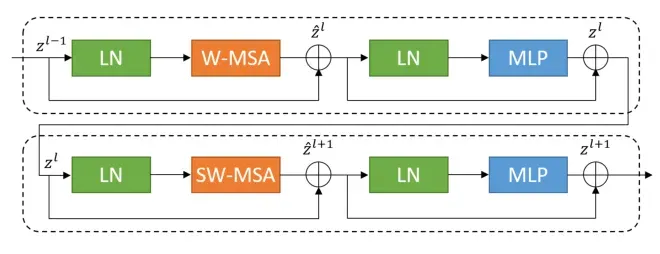
Swin Transformer block:

编辑
Encoder:
在编码器中,分辨率为H/4×W/4的C维tokens输入到两个连续的Swin Transformer块中执行特征学习,其中特征维度和分辨率保持不变。同时,patch merging 层将减少tokens的数量(2×下采样),并将特征维度增加到原始维度的2×。此过程将在编码器中重复三次。
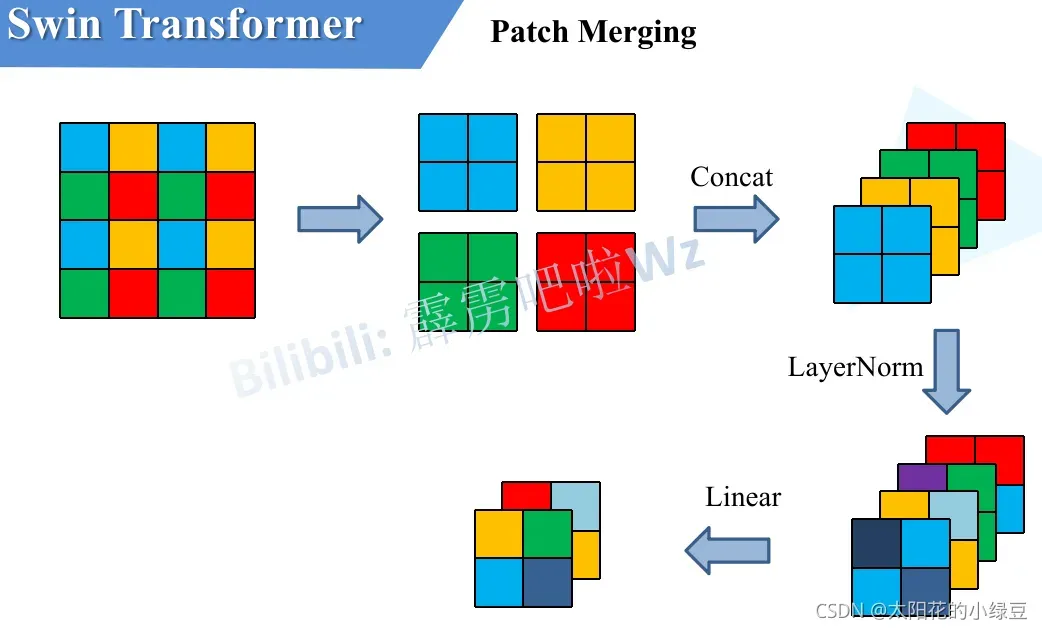
patch merging 层:原文链接:Swin-Transformer网络结构详解_swin transformer_太阳花的小绿豆的博客-CSDN博客
如下图所示,假设输入Patch Merging的是一个4×4大小的单通道特征图(feature map),Patch Merging会将每个2×2的相邻像素划分为一个patch,然后将每个patch中相同位置(同一颜色)像素给拼在一起就得到了4个feature map。接着将这四个feature map在深度方向进行concat拼接,然后在通过一个LayerNorm层。最后通过一个全连接层在feature map的深度方向做线性变化,将feature map的深度由C变成C/2。通过这个简单的例子可以看出,通过Patch Merging层后,feature map的高和宽会减半,深度会翻倍。

编辑
Bottleneck:
由于Transformer太深,无法收敛,因此使用两个连续的Swin Transformer块来构建瓶颈模块,以学习深度特征表示。在瓶颈模块中,特征尺寸和分辨率保持不变。
Decoder:
与编码器相对应,基于Swin Transformer块构建了对称解码器。为此,与编码器中使用的patch merging层不同,在解码器中使用patch expanding层对提取的深度特征进行上采样。patch expanding层将相邻维度的特征图重塑为更高分辨率的特征图(2×上采样),并相应地将特征维度降低到原始维度的一半。
Patch expanding 层:
以第一个patch expanding层为例,在上采样之前,在输入特征(W/32×H/32×8C)上应用线性层,以将特征维度增加到原始维度(W/32 x H/32×16C)的2倍。然后,使用rearrange操作将输入特征的分辨率扩展到输入分辨率的2倍,并将特征维数减小到输入维数的四分之一(W/32×H/32×16C→ W/16×H/16×4C)。
Skip connection:
与U-Net类似,跳跃连接用于将编码器的多尺度特征与上采样特征融合。作者将浅层特征和深层特征连接在一起,以减少下采样导致的空间信息损失。
2、S3Net: Spectral–Spatial Siamese Network for Few-Shot Hyperspectral Image Classification
本文针对的问题:过拟合
本文解决方法:
首先,提出了一种由一维和二维卷积组成的轻量级光谱空间网络(SSN)来提取光谱空间特征;
其次,S3Net由双分支中的两个ssn构成,通过向每个分支中输入样本对来扩充训练集,从而增强模型的可分离性。为了为模型提供更多的特征,在每个分支中输入差异化的patch,其中随机选择负样本以避免冗余。
最后,设计加权对比损失函数,通过关注难以识别的样本对来促进模型向正确的方向拟合。此外,还提出了另一种自适应交叉熵损失来学习两个分支的融合比。
相关工作
孪生网络是一个双分支结构,由于孪生网络的输入是一对样本(即样本对),可以通过样本配对来实现数据增强,学习样本之间的差异。传统的孪生网络是用两个共享权值的子网络来判断两个样本是否匹配,不能区分样本对属于哪一类。在训练过程中,如果样本对被匹配,模型会缩小它们特征之间的距离。当样本对不匹配时,模型会增加距离。在测试过程中,测试样本通过计算特征相似度来验证样本是否匹配。如图1(a)所示,每对样本包含两个样本,Feature 1由模型a提取,Feature 2由模型b提取。根据这两个特征计算对比损失(Lctr)来训练模型,如下式所示:
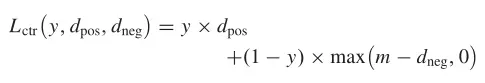
其中y表示两个样本是否属于同一类。如果他们在同一个班级,y=1;否则,y=0。属于同一类的样本对之间的距离用表示,属于不同类的样本对之间的距离用表示。边界参数m是过大时防止负样本恶化模型的阈值。
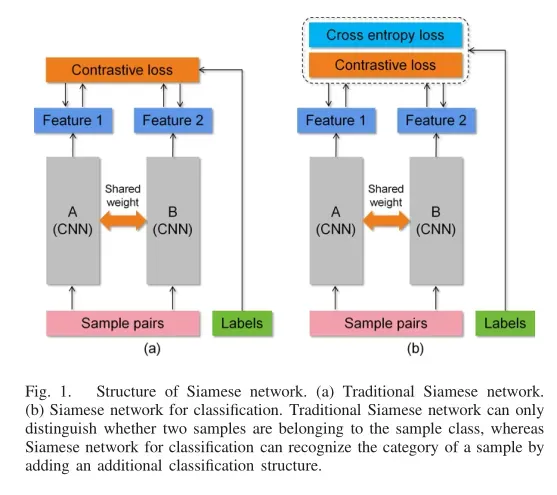
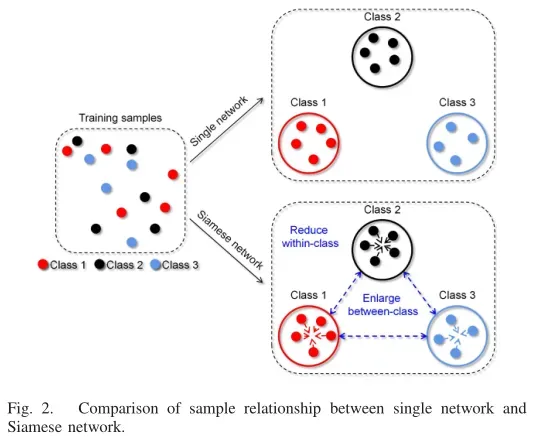
传统的孪生网络属于度量模型,没有分类能力。为了实现用于分类的孪生网络,可以进行两种调整。第一种方法是使用标签策略。在训练阶段,如果样本对属于同一类,则样本对标签与单个样本相同。当样本对来自不同的类时,它们的标签设为0。在测试阶段,可以根据输出特征向量直接预测测试样本。第二种方法是在孪生网络中添加一个分类结构,计算每个单个样本的交叉熵损失,并训练网络进行分类。在测试阶段,单个测试样本可以直接通过分类结构进行分类。如图1(b)所示,本文使用第二种方法进行分类,该方法产生了类概率,具有更强的鲁棒性。此外,具有分类结构的孪生网络可以很好地融合分类和度量学习,从而更好地提高模型的判别能力。单个网络只对单个样本进行分类,缺乏样本之间的联系,如图2右上方框所示。相反,Siamese网络可以通过配对的方式将不同样本进行关联,这样可以减小类内样本的距离,增大类间样本的距离,从而提高模型的分类效果,如图2右下角框所示。
在此背景下,本文的工作与其他相关工作的主要区别如下:
1)构建了一个独特的由1-D和2-D卷积组成的轻量级子网络,而现有的相关方法主要基于3-D架构,这些方法更深入、更复杂,容易在有限的训练样本下陷入过拟合。
2)设计了一种差异化的输入策略,将不同大小的patches输入到孪生网络的双分支中,从而为模型提供更多的特征,而现有的大多数相关方法都使用相同的patches大小。
3)提出了加权对比损失函数和自适应交叉熵损失函数,可以提高辨别能力,而现有的相关方法很少利用损失函数。
本文方法
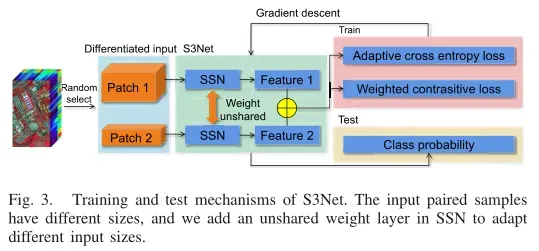
首先构建了一个少参数的轻量级网络(SSN)来提取HSI数据的光谱空间信息。在此基础上,构建了一个基于SSN的S3Net网络框架。最后,设计了加权对比损失函数和自适应交叉熵损失函数。S3Net的训练和测试机制如图3所示。在数据预处理中,将样本分为训练子集和测试子集,每个样本将生成两个不同大小的patch。在训练阶段,每个大的patch样本将与所有小的patch样本配对,配对后的样本将馈送到S3Net的两个分支中,计算加权对比损失。此外,如果样本对以同一像素为中心,则将用于计算额外的自适应交叉熵损失。在测试阶段,每个大的patch样本将与其小的patch样本进行配对,并将两个分支获得的特征相加进行预测。
A. Spatial–Spectral Network
设计了一种由一维卷积和二维卷积组成的轻型SSN。在这种情况下,网络参数将比三维卷积减少2/3,这也有利于削弱小样本下的过拟合问题。SSN的结构如图4所示,表I给出了SSN不同层的具体维数,其中C为进行主成分分析(PCA)后处理的patch维数,K为类数,W × H为patch大小,W为patch的宽,H为patch的高。
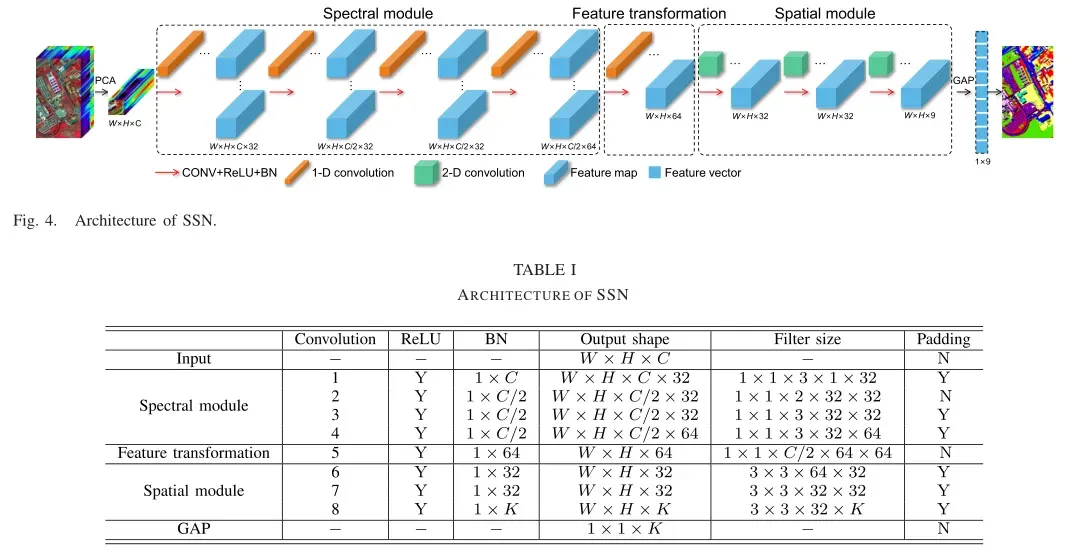
1)光谱模块:该模块通过一维卷积提取输入的局部光谱特征。输入X经过4个1-D卷积层,每个卷积层后ReLU与BN连接。本文将第二卷积层的步长设置为2,以降低特征图的维数。经过四层卷积,特征图的维数为X∈(64张特征图,维数为W×H ×C/2)。
2)特征变换:该模块将光谱模块获得的通道信息整合成特征图。使用1-D卷积提取全局光谱信息,得到的输出被重组。
3)空间模块:该模块提取特征转换模块获得的特征图的空间信息。特征图X经过3个二维卷积层提取空间信息,每层后连接ReLU和BN,特征图维数由64降为K。每个特征映射代表一个类。在整个空间模块中使用padding,中心特征向量仍然是由整个patch获得的,边缘特征向量不是由整个像素组成的;因此可以保留一些局部特征。在这种情况下,我们认为特征图可以使用填充来保留全局和局部特征。此外,padding可以使边缘像素多次参与卷积,这样网络就不会丢失边界信息。
4)分类:空间模块获得的特征图已经包含了类信息,即特征图的不同层代表不同的类。使用GAP代替全连通层来获取特征向量。
B. S3Net
基于两个ssn,本文构建了一个孪生网络框架,即S3Net,其模型架构如图5所示,其中W1 × H1表示大patch,W2 × H2表示小patch。在该框架中,通过配对扩展样本,并通过度量学习增强可分离性。首先,将HSI生成为两个不同大小的patch,然后将其输入到两个ssn中得到特征向量。其次,利用特征向量计算加权对比损失和自适应交叉熵损失,用于训练模型。最后,通过两个特征向量的相加来预测测试样本的标签。
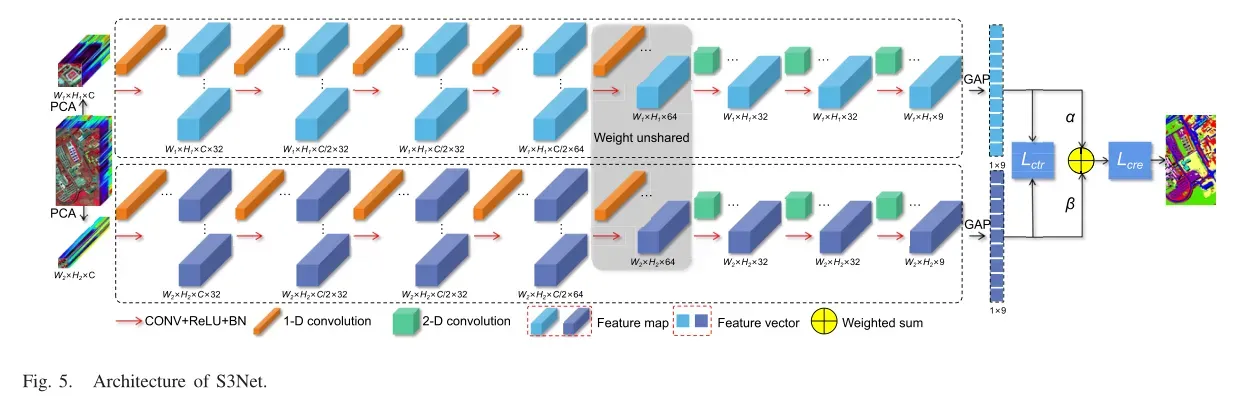
1)差异化输入:在S3Net的两个分支使用两个不同大小的输入,与传统的孪生网络使用相同大小的输入不同。在该策略中,每个像素生成两个大小的patch样本,每个样本对由一个大的和一个小的patch样本组成。不同的样本具有不同的特征分布,这意味着它们可以为模型提供更多的特征来增强识别能力。为了提高两个子网络对不同输入的适应性,在特征转换模块中使用非共享权值,在其他层中使用共享权值。
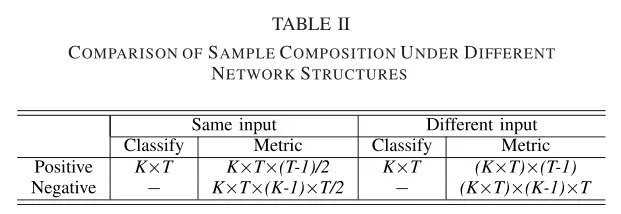
2) RS for Negative Pairs: 孪生网络在训练过程中通过样本配对实现数据增强。当使用相同的输入时,两个样本只能形成一个样本对。相反,在差异化输入策略中,相同的两个样本可以形成两个大小组合样本对。然而,孪生网络框架的正、负样本比例存在严重的不平衡问题。具体的样本组成如表II所示,其中T为每类样本的数量。结果表明,正负样本之比约为1:(K−1)。
过多的负样本会消耗大量的训练时间,甚至会恶化网络。为了提高收敛速度和弱化过拟合问题,作者在每个epoch中随机选择与正样本相等的负样本,不进行替换。
C.损失函数
在S3Net的框架中,每个训练epoch有两个损失函数。最终损失为L = + 。使用Adam优化器对L的网络进行优化。
1) weight contrast Loss:
对于孪生网络,大距离的正样本和小距离的负样本被视为硬样本,在训练中更为重要。而在传统的孪生网络中,样本对的标签是稳定的。为了增加训练中硬样本的比例,作者设计了对比损失权重,重点关注这些硬样本。
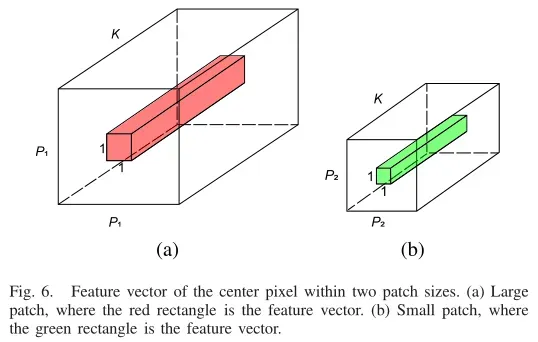
作者从两个特征图中取中心向量(如图6所示),计算样本对之间的余弦距离w为
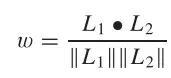
然后,将(1-w)和w分别乘以正样本和负样本,如下式所示:
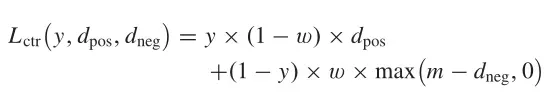
其中,当两个样本属于同一类时,样本特征之间的距离为,当两个样本属于不同类时,样本特征之间的距离为。加权对比损失可以通过w的设计更加关注硬样本,从而促使模型拟合到正确的方向。
2)Adaptive Cross-Entropy Loss:
首先使用两个自适应参数(α和β)融合从双分支学习到的两个特征向量。然后用融合向量定义自适应交叉熵损失来训练网络
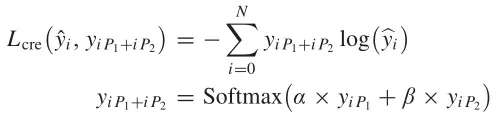
其中和是第i个样本的两个特征向量。两个参数α和β是初始值为0.5的1 × K维向量,在训练过程中学习。所提议的S3Net方法的伪代码如算法1所示。

3、Hyperspectral Image Analysis using Principal Component Analysis and Siamese Network
本文针对问题:样本有限
本文解决办法:提出了一种高光谱数据集的监督模型,采用主成分分析降维,混合像元数据增强来增加训练样本,并使用Siamese网络进行测试,最后使用CNN进行分类。
网络框架如图所示
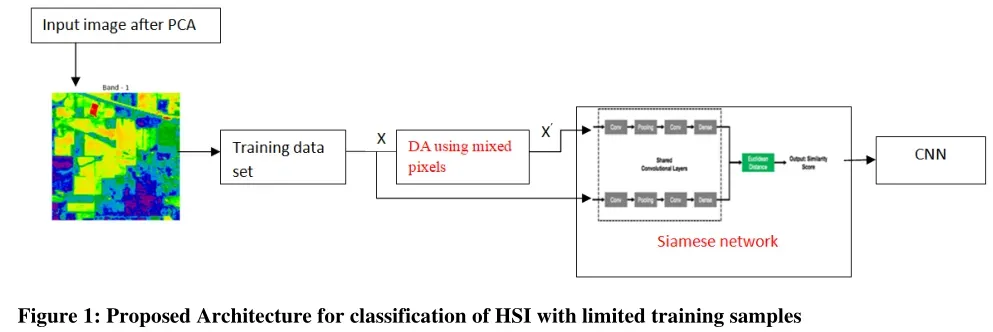

a.数据增强
为了提供更好的性能,使用混合像素技术生成新的数据。图像区域的图像边界上的像素是混合像素。因此,对于每个类通过识别25%的标签,并与其余类配对,以创建混合像素。对于给定的类别,丰度值始终高于56%,以确保混合物是给定类别的大多数。利用不同的混合比例提供更多的训练数据。
b.孪生网络
孪生网络架构用于检查给定的两张图像是否相似。孪生网络的输入是成对的,称为像素对,然后经过一系列卷积、平均池化和全连通层后,编码为特征向量f1和f2。使用反向传播训练网络,使得具有相同标签的两个相似输入的特征向量的欧几里得距离趋于减小,而不同图像的距离趋于增大。这有助于我们根据特征向量之间的距离来学习图像之间的相似性。卷积后的欧氏距离由下式计算。
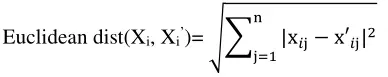

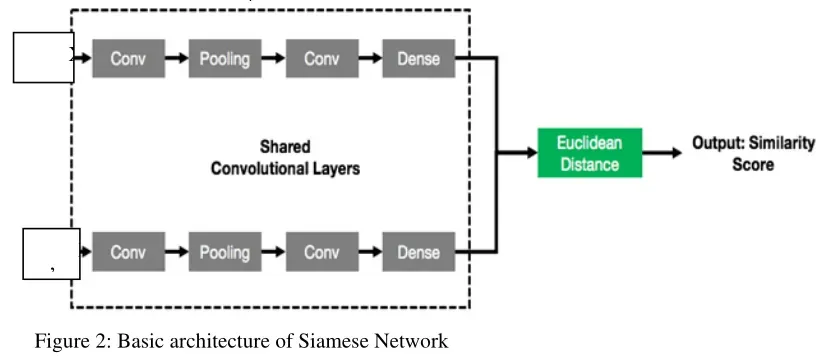
作者在这里用来训练模型的损失函数是最大边际对比损失。损失函数的方程为:
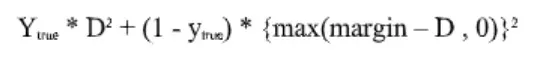
这里,D是两个特征向量f1和f2之间的欧几里得距离。
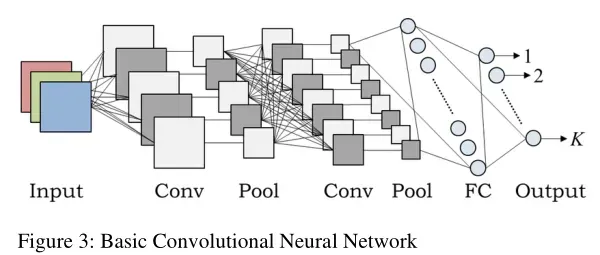
C.卷积神经网络
CNN模型通过卷积层的序列来训练和测试每个输入图像→池化层→全连接层。最后,应用softmax激活功能。

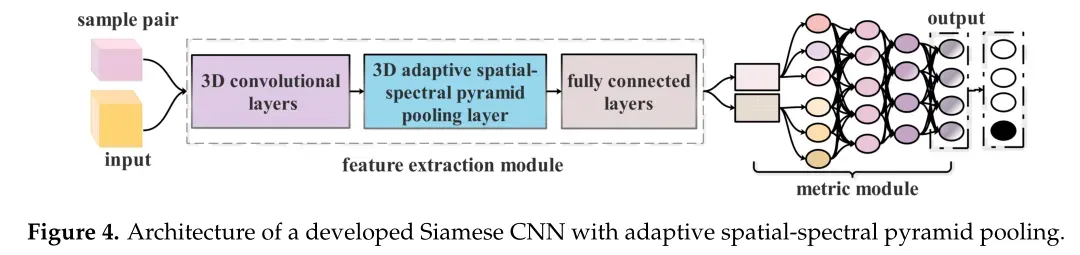
4、A Developed Siamese CNN with 3D Adaptive Spatial-Spectral Pyramid Pooling for Hyperspectral Image Classification
本文针对问题:样本有限、迁移学习
本文解决方法:作者提出了一种具有三维自适应空间-光谱金字塔池化(ASSP)层的孪生CNN,称为ASSP-SCNN,它以不同大小的3D样本对作为输入。通过为网络配备SPP层,无论输入大小如何,网络都可以生成固定长度的表示。
相关工作
样本对的标记策略
考虑一个具有M个三维标记样本的高光谱数据集,表示为X={ ![]() },X⊆
},X⊆![]() ,其中d表示波段数,w×w表示样本的空间大小。三维样本的类标号表示为∈1,2…C, 它等于中心像素的标签(C代表类的数量)。设
,其中d表示波段数,w×w表示样本的空间大小。三维样本的类标号表示为∈1,2…C, 它等于中心像素的标签(C代表类的数量)。设![]() 表示第l类中可用标记样本的数量,从X中随机选择两个3D样本和
表示第l类中可用标记样本的数量,从X中随机选择两个3D样本和![]() ,
,![]() 形成一个样本对
形成一个样本对![]() = (
= (![]() ,
,![]() )。然后,
)。然后, ![]() 的标记策略是:如果两个样本、属于同一类,则的标签与相同。否则,的标签是C+1。该公式由以下等式表示。
的标记策略是:如果两个样本、属于同一类,则的标签与相同。否则,的标签是C+1。该公式由以下等式表示。
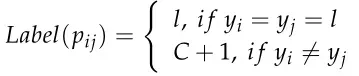
根据上述样本对的标记策略,标记的样本对集包含C+1类,其大小是X的M倍。具体地说,从X中随机选择两次,得到两个样本![]() ,
,![]() ,如果
,如果![]()
![]()
![]() ,则(
,则(![]() ,
,![]() )
)![]() (
(![]() ,
,![]() )。因此,标记样本对集合P的大小是
)。因此,标记样本对集合P的大小是![]() 。
。
端到端的孪生卷积神经网络
通过样本对的标记策略标记样本对集后,标记的样本对集比原始训练集多包含一个类。具体地说,如果训练集包含C个类,则标记的样本对集包含C+1个类,并且额外的第(C+1)个类标记指示样本对的这两个样本不属于任何相同的类。
由于ES-CNN的输入是一个样本对,应用邻域投票策略来最终确定中心像素的类标签。该策略假设中心像素与相邻像素属于同一类的概率很高。假设选择了一个3×3的邻域,下图说明了投票策略。
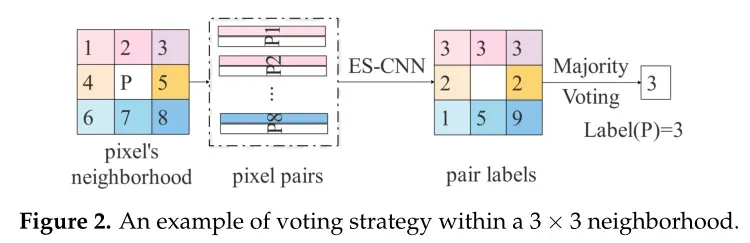
具体来说,对于要分类的像素,首先选择该像素的5×5邻域来获得24个像素对。然后,将这些像素对输入到经过训练的网络中,以预测它们的标签。给定预测的标签,首先排除不属于同一类的像素对,然后选择具有最高有效票数的标签作为中心像素的类标签。
由于ES-CNN的输出包含多个神经元,方程(2)和(3)提出了新的交叉熵损失函数。
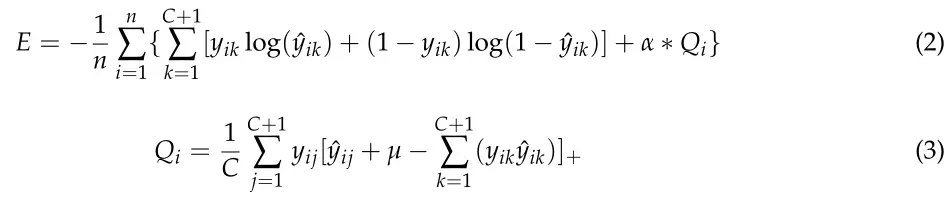
其中n是批量大小,µ是介于0和1之间的小数。![]() =max(z,0)。
=max(z,0)。![]() 是第i个像素对的标签,(
是第i个像素对的标签,(![]() ,…,
,…,![]() ,…,
,…,![]() )是的一个热独标签。
)是的一个热独标签。![]() 是第i个像素对的预测值,并且(
是第i个像素对的预测值,并且(![]() ,…,
,…,![]() ,…
,…![]() )是
)是![]() 的一个热独标签。是一种正则化方法,可以保证HSI分类的准确性。α是权重系数。
的一个热独标签。是一种正则化方法,可以保证HSI分类的准确性。α是权重系数。
空间金字塔池化和自适应池化
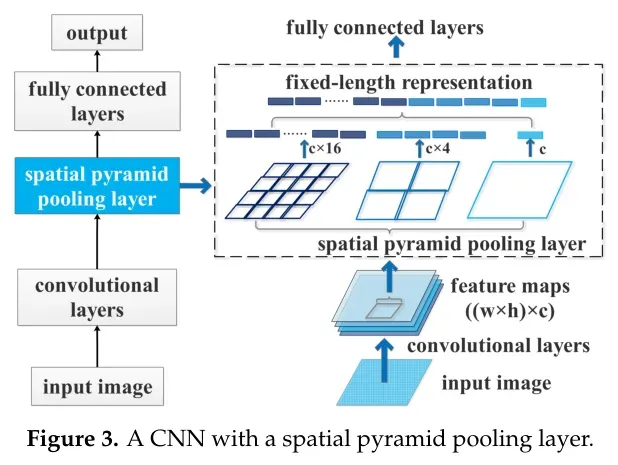
为网络配备空间金字塔池化,以消除深度CNN需要固定大小输入的要求。固定大小的约束仅来自全连接层,而卷积层不需要固定大小的输入,可以生成任何大小的特征图。换句话说,对于基于CNN的分类方法,如果生成固定大小/长度的输出以送到全连接层中,就可以去除网络的固定大小约束。空间金字塔池化层和自适应池化层可以汇集特征以从任意大小的输入生成固定大小的表示。
根据不同的池化操作,自适应池化有两种具体的实现方式:自适应最大池化和自适应平均池化。自适应池化的特殊性在于,只要给出自适应池化的输入数据和输出大小,它就可以自动计算核大小、填充和步长。具体来说,考虑自适应池化的输入大小为w×w,我们希望在池化后生成n×n个特征,那么相应池化层的参数可以由以下方程(4)决定。

在实践中,使用自适应池化层来生成固定大小的表示是方便的,因为它的参数只包括输出的大小。空间金字塔池化技术可以生成固定长度的输出,而不考虑输入大小,并使用多级空间仓来生成对对象变形的鲁棒输出。下图显示了具有空间金字塔池化层的CNN的结构。CNN在卷积层和全连接层之间配备了空间金字塔池化层。将空间金字塔池化输出生成的固定大小/长度表示分别连接为c×4×4、c×2×2和c×1×1。这里,c是在空间金字塔池化之前的卷积层的滤波器数目。因此,通过配备空间金字塔池化层,CNN可以生成多层次特征,以提高CNN的尺度不变性。
本文网络框架
本文提出了一种具有三维自适应空间-光谱金字塔池化的孪生CNN,称为ASSP-SCNN,用于有限标记样本的HSI分类。下图展示了ASSP-SCNN的结构,它由输入、特征提取模块、度量模块和输出四个部分组成。
ASSP-SCNN的特征提取包含一个三维自适应金字塔池化层,它允许在训练过程中输入不同大小或尺度的样本,并提取固定大小的多层次特征。
ASSP-SCNN的度量模块由四个全连接层组成,以三维样本对的特征作为输入,其输出层包含多个神经元。利用该度量模块,ASSP-SCNN不仅可以测量样本对的相似度,还可以直接处理HSI多重分类。
三维自适应空间光谱金字塔池化层
三维自适应空间光谱金字塔池化层的CNN结构示例如下图所示。
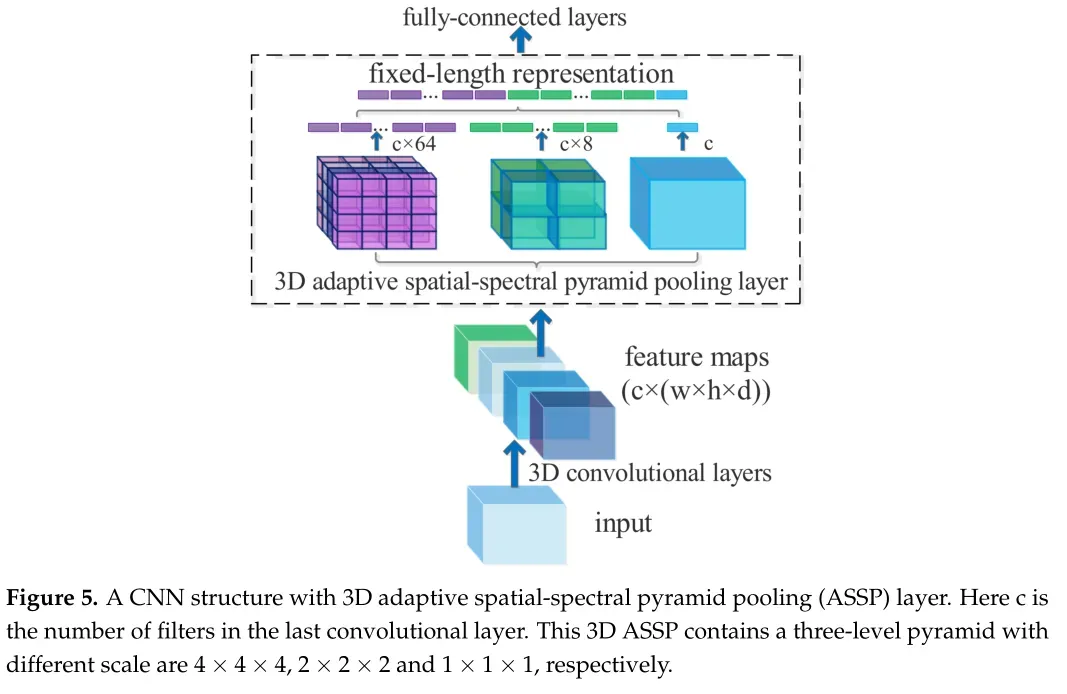
自适应金字塔池化层包含多级金字塔,可生成多个空间光谱仓。自适应金字塔池化层的输入是最后一个卷积层的输出,大小为c × (w × h × d),其中c为最后一个卷积层的滤波器数量,该滤波器的每个特征图的输出大小为w × h × d。自适应金字塔池化层的输出是一个固定维向量,大小为c × M,其中M为空间光谱仓的数量。固定维向量是全连通层的输入。
在实验中,作者分别用5×5×5、3×3×3和1×1×1尺度的滤波器构建了一个三层金字塔。为了便于应用自适应池化,作者分别应用一个三维自适应平均池化层对每一层的自适应金字塔池化输入进行池化。此外,作者将三级3D自适应平均池化层的输出尺寸分别设置为5×5×5、3×3×3和1×1×1。因此,我们将这些自适应池化层的输出压扁为一维向量,并将它们连接在一起,得到153(= 125 + 27 + 1)个空间光谱仓。
带有3D自适应空间光谱金字塔池化层的孪生CNN
构建样本对
考虑一个HSI数据集,在像素空间中包含N个标记的像素,标记为X={ ![]() },X⊆
},X⊆![]() ,其中d表示波段数。设∈1,2…C, 是的类标签。作者将数据集X分割为训练集Xtrain和测试集Xtest,这两个集之间没有交集。对于任意像素,将其作为中心像素,截取一个大小为w × w的空间邻域作为三维样本。这里
,其中d表示波段数。设∈1,2…C, 是的类标签。作者将数据集X分割为训练集Xtrain和测试集Xtest,这两个集之间没有交集。对于任意像素,将其作为中心像素,截取一个大小为w × w的空间邻域作为三维样本。这里![]() 的大小为d × w × w,标签为
的大小为d × w × w,标签为![]() 。
。
在训练阶段,首先从训练集Xtrain中随机选择两个像素![]() 和
和![]() 。取这两个像素分别截取两个三维样本
。取这两个像素分别截取两个三维样本![]() 和
和![]() ,形成三维样本对
,形成三维样本对![]() 。ASSP-SCNN可以在训练过程中输入不同大小的样本。因此,对于选定的两个像素
。ASSP-SCNN可以在训练过程中输入不同大小的样本。因此,对于选定的两个像素![]() 和
和![]() ,可以根据不同的空间窗口大小生成多个样本对。考虑K个不同的空间窗口大小,训练ASSP-SNN的样本对集如式(5)所示。
,可以根据不同的空间窗口大小生成多个样本对。考虑K个不同的空间窗口大小,训练ASSP-SNN的样本对集如式(5)所示。

在测试阶段,对于测试集Xtest的每个像素,以它为中心截取一个三维样本,生成一个样本对。检验样本对集如式(6)所示:
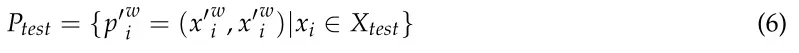
其中集合包含||Ptest|| = ||Xtest||样本对,的类标签与相同。
特征提取
在样本对构建完成后,将样本对输入到特征提取中,提取样本对的多层次空间-光谱特征。特征提取是带有自适应空间光谱金字塔池化层的3D-CNN。图6展示了特征提取模块的架构,它由四个卷积块、一个3D ASSP层和三个全连接层组成。对于给定的包含两个三维样本,和的样本对,将这两个样本输入到特征提取中,生成两个大小相同的特征。
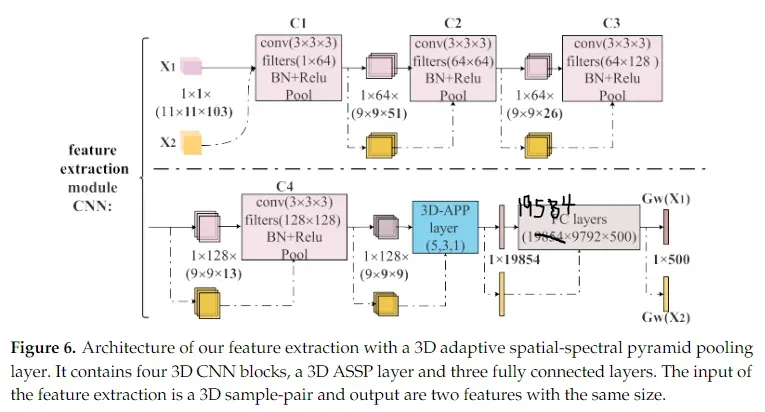
如图6所示,输入每个样本的大小为b×1×w×w×d = 1×1×11×11×103,其中b为输入的批次大小,w × w为样本的空间窗口大小,d为样本的频带数。特征提取由四个三维CNN块、一个三维ASSP层和三个全连接层组成。每个3D CNN块是卷积层、批处理归一层、ReLU激活层和池化层的拼接。更具体地说,第一个3D CNN包含大小为3 × 3 × 3的1 × 64个3D卷积滤波器,然后是批量归一化层、ReLU激活层和步幅为1 × 1 × 2的3 × 3 × 3最大池化层。
首先,将一个3D样本输入到第一个3D CNN块(C1)中,生成一个大小为1 × 64 × 9 × 9 × 51的张量,(51=(103−3 + 1)/2 + 1)。将C1的输出张量输入到第二个3D CNN块(C2)中,通过这种块到块的特征提取,最终得到了第四个3D CNN块(C4)的输出,其大小为1 × 128 × 9 × 9 × 9。然后将C4的输出输入到三维ASSP层中,该ASSP层包含一个三层金字塔,输出大小分别为5 × 5 × 5,3 × 3 × 3和1 × 1 × 1。因此,三维ASSP层的输出尺寸为1 × 19,584 (19,584 = 128 ×(125 + 27 + 1))。最后,将3D ASSP层的输出输入到全连接层,得到一个大小为1 × 500的特征。
度量模块
通过特征提取的样本对输入到全连接网络中,该网络不仅可以测量输入特征的相似度,还可以生成样本对属于每个类的概率值。下图7展示了度量模块的架构,其输入是特征提取后样本对的特征之间的连接。输出层包含C+1个神经元节点,其中第一个C节点表示样本对属于类t的概率,t∈{1,…C}, C + 1节点值表示样本对中两个样本不相似的概率。
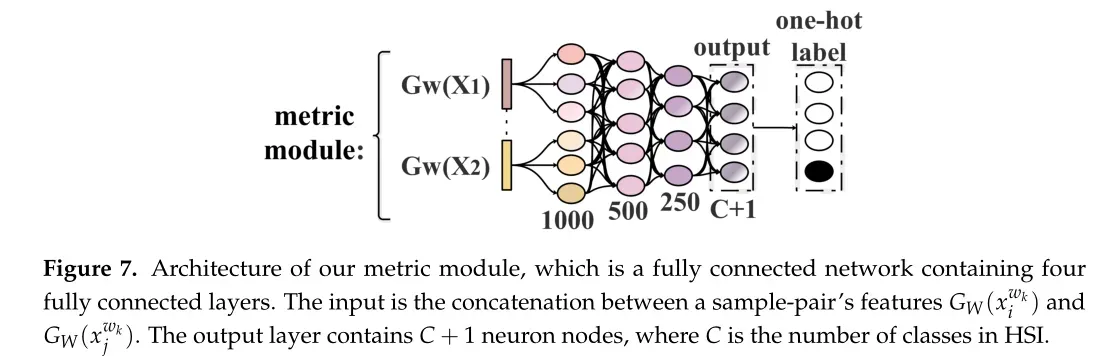
由图6可知,特征提取的输出是一个大小为1 × 500的张量。因此,度量模块的第一个完全连接层包含1000个神经元,如图7所示。除了配备Softmax激活功能的输出层外,所有全连接层都配备了ReLU激活功能。
基于APP-SCNN的迁移学习
为了验证ASSP-SCNN的泛化性,作者提出了一个基于ASSP-SCNN的HSI分类迁移学习框架。迁移学习框架流程图如下图8所示,包括两个部分:预训练部分和微调部分。
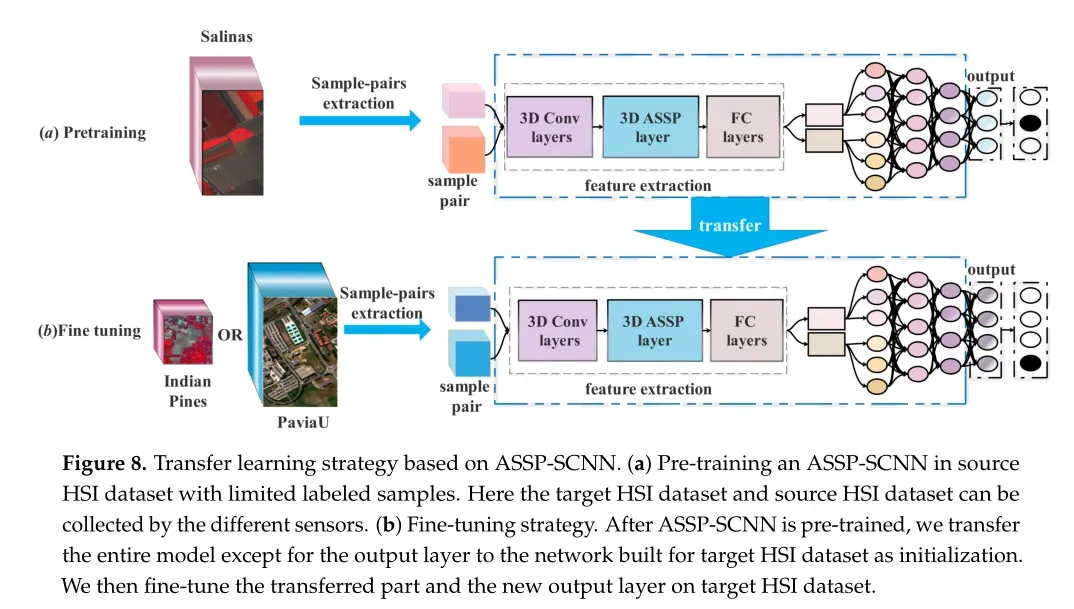
预训练策略
预训练由多个3D-CNN层、一个ASSP层和多个全连接层组成。从源HSI数据集构建训练样本对集来训练ASSP-SCNN。然后ASSP-SCNN生成一个大小为c+1的输出,它表示输入样本对属于每个类的概率值。
迁移学习实验包括来自同一个传感器的用于预训练的源数据集和用于微调的目标数据集,以及来自不同传感器的数据集。在样本对构建阶段,不需要统一源数据集和目标数据集样本中包含的波段数。为了将源数据集上的预训练模型转移到不同频带数的目标数据集上,通常选择在构建样本对阶段统一源数据集和目标数据集的频带数。这样的解决方案在样本对构建过程中有丢失有用光谱信息的风险。为了解决上述问题,作者为孪生CNN配备了3D ASSP层,以适应不同尺寸的3D样本对作为输入。因此,样本对的频带数可以与原始HSI保持一致,进行预训练或微调。
微调策略
作者将除输出层外的整个预训练模型传递给为目标HSI数据集构建的网络作为初始化模型。然后对目标HSI数据集上传输的部分和新的输出层进行微调。在进行微调时应注意以下两个关键点。
预训练模型的最后一层(输出层)参数不传递。由于源数据集和目标数据集可能包含不同数量的类,因此需要改变预训练模型输出层的神经元数量来实现目标数据集的多分类。在这种情况下,只替换预训练模型的输出层,为目标数据集生成一个新的ASSP-SCNN。因此,将除输出层外的整个预训练模型传递给为目标HSI数据集构建的网络作为初始化。(为目标HSI随机初始化ASSP-SCNN的输出层。)
在调优过程中,使用Adam优化器以相同的学习率对转移部分和新的输出层进行训练。在基于ASSP-SCNN的迁移学习的微调阶段,应采用统一的学习率对目标HSI进行全网微调。
5、3D convolutional siamese network for few-shot hyperspectral classification
本文针对问题:对标记数据的强烈需求
本文解决办法:作者提出了一种由三维卷积神经网络组成的连体网络,命名为3DCSN。
训练过程
首先在光谱维度上对形状为h × w × c的高光谱图像进行PCA预处理。图像的形状变成h × w × k。然后在处理后的图像上使用25 × 25滑动窗口将图像分割成patch来训练3DCSN。每个像素对应一个patch,边缘像素使用零填充来构建。因此得到了形状为25 × 25 × k的patch。令X={ ![]() ,
,![]() ,…,
,…,![]() }(X∈
}(X∈![]() )为patch,Y={
)为patch,Y={ ![]() ,
,![]() ,…,
,…,![]() } (
} (![]() ∈N)是patch的标签。3DCSN的主体部分为编码器,编码器用函数f表示,投影头用函数g表示,线性分类器用函数h表示。z是编码器的输出,z=f(x).(
∈N)是patch的标签。3DCSN的主体部分为编码器,编码器用函数f表示,投影头用函数g表示,线性分类器用函数h表示。z是编码器的输出,z=f(x).(![]() ,
,![]() )是由X中随机选择的两个patch组成的一对数据,
)是由X中随机选择的两个patch组成的一对数据,![]() 是这对数据的标签:
是这对数据的标签:
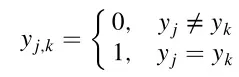
训练过程包括两个阶段。第一阶段为对比学习阶段,第二阶段为分类阶段。在对比学习阶段,θ通过式下式更新。
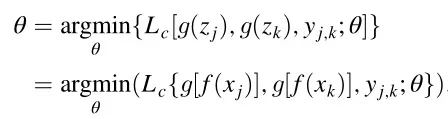
![]() 为对比损失函数,margin为常数,其典型值为1.25。通过最小化对比损失函数,编码器可以将patch映射到具有较小的类内距离和较大的类间距离的潜在空间:
为对比损失函数,margin为常数,其典型值为1.25。通过最小化对比损失函数,编码器可以将patch映射到具有较小的类内距离和较大的类间距离的潜在空间:
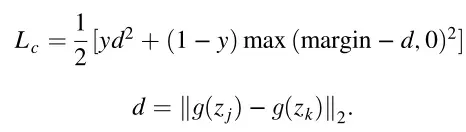
在分类阶段,每次只从X中随机选择一个样本![]() 。交叉熵损失函数用于指导θ的训练。
。交叉熵损失函数用于指导θ的训练。![]() 表示第i个样本的真实标签,
表示第i个样本的真实标签,![]() 表示第i个样本的预测标签。因此θ由下式更新:
表示第i个样本的预测标签。因此θ由下式更新:
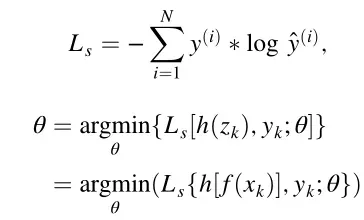
通过这两个阶段联合训练3DCSN,通过对比学习,学习到的信息可以将分布p(z|x)引导到一个容易划分不同类别的潜在空间。这样,3DCSN可以获得比其他典型方法更好的分类性能。
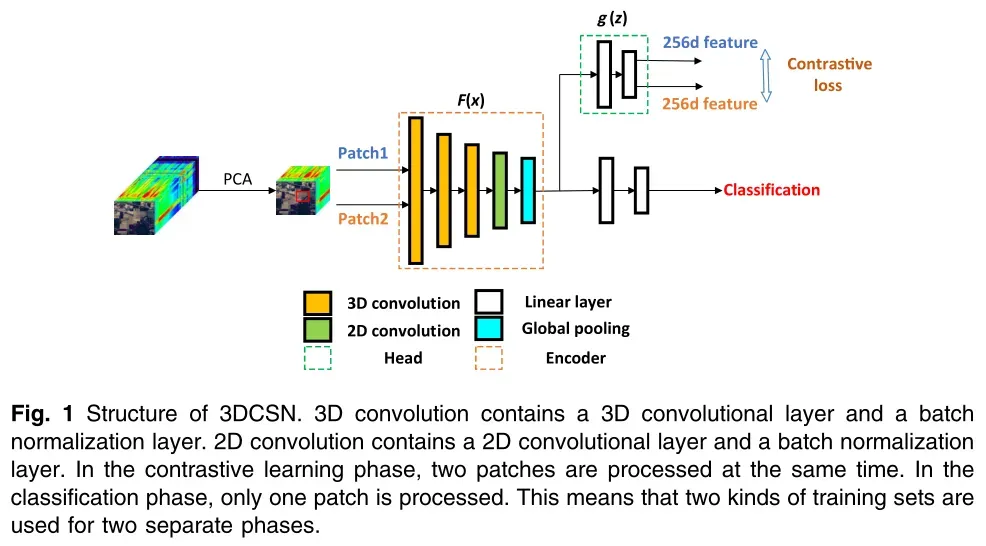
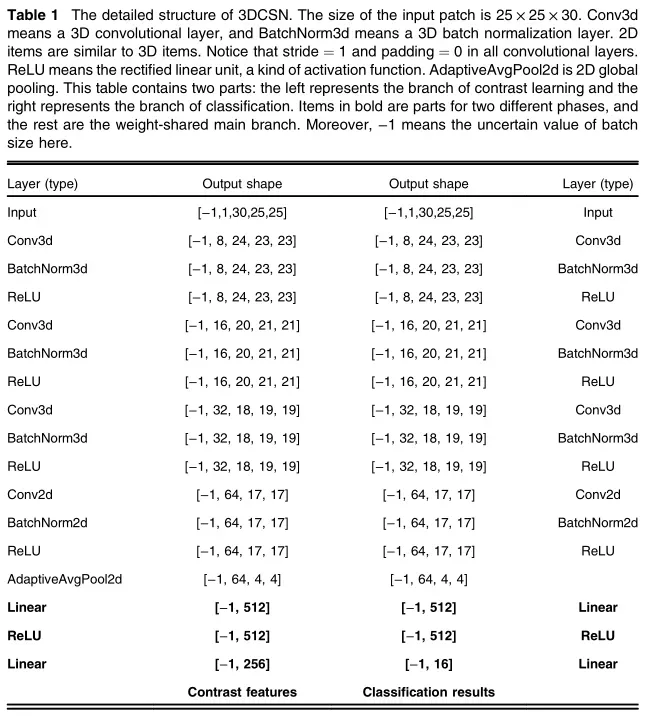
3DCSN的结构
3DCSN的结构如下图1所示。3DCSN的编码器部分来源于hybridSN。光谱特征提取和空间特征提取分别采用3个三维卷积层和1个二维卷积层。但是3DCSN和hybridSN是有区别的。HybridSN使用dropout layer,而3DCSN使用batch normalization layer来避免过拟合。在3DCSN中,每个卷积层与BN层结合为一个卷积单元。在卷积层之后,全局池化层用于固定特性映射的大小。
Data增强
在数据不足的场景下,适当的数据增强可能有助于提高模型的性能。在本文的方法中,作者使用了孪生网络。作者开发了一种数据增强算法来生成足够的数据对。
为方便起见,以每个类有三个标记样本为例。
假设训练集X={ ![]() ,
,![]() ,…,
,…,![]() },(k∈3
},(k∈3![]() c, c是数据集中的类数)和标签集Y={
c, c是数据集中的类数)和标签集Y={ ![]() ,
,![]() ,…,
,…,![]() }。对于某一个样本
}。对于某一个样本![]() (1≤i≤k),它可以与任意另一个样本
(1≤i≤k),它可以与任意另一个样本![]() (1≤i≤k且j≠i)组合成一个样本对,因此有k
(1≤i≤k且j≠i)组合成一个样本对,因此有k ![]() (k−1)个样本对可供选择。对于每个样本对,其标签可由下式确定,这样可以大大增加用于对比学习的训练样本,但在实际中,并不会全部使用。随机选择n个样本对进行对比学习,其中n=min[k
(k−1)个样本对可供选择。对于每个样本对,其标签可由下式确定,这样可以大大增加用于对比学习的训练样本,但在实际中,并不会全部使用。随机选择n个样本对进行对比学习,其中n=min[k ![]() (k−1),M],M为控制训练集大小的预设值;通常设置为10,000。
(k−1),M],M为控制训练集大小的预设值;通常设置为10,000。
文章出处登录后可见!