特征选择
从所有提取的特征中选择一些特征作为训练集特征。特征可以在选择前后改变值,但是选择后的特征维度肯定比选择前要小。毕竟,我们只选择了特征的一部分。
主要方法(三大武器):Filter(过滤式):VarianceThreshold
Embedded(嵌入式):正则化、决策树
Wrapper(包裹式)
特征选择原因:
冗余:一些特征高度相关,容易消耗计算性能
噪声:某些特征对预测结果有负面影响
sklearn特征选择API
sklearn.feature_selection.VarianceThreshold


数据降维(PCA主成分分析)
本质:PCA是一种分析、简化数据集的技术
目的:压缩数据维度,尽可能降低原始数据的维度(复杂度),损失少量信息。
作用:可以减少回归分析或聚类分析中的特征数量
数据降维API
sklearn. decomposition


机器学习基础
(1)核心和基础
算法是核心,数据和计算是基础
(2)找准定位
大多数复杂模型的算法设计都是由算法工程师完成的,我们
分析大量数据
分析具体业务
应用常用算法
特征工程、调优、优化
(3)数据类型:
离散数据:记录不同类别的个体数量得到的数据,也称为计数数据,所以这些数据都是整数,其准确性不能再细分或进一步提高。
连续数据:变量可以取一定范围内的任意数字,即变量的值可以是连续的,比如长度、时间质量等。这类整数通常是非整数,包含小数部分;
备注:离散型在区间内不可分,连续型在区间内可分
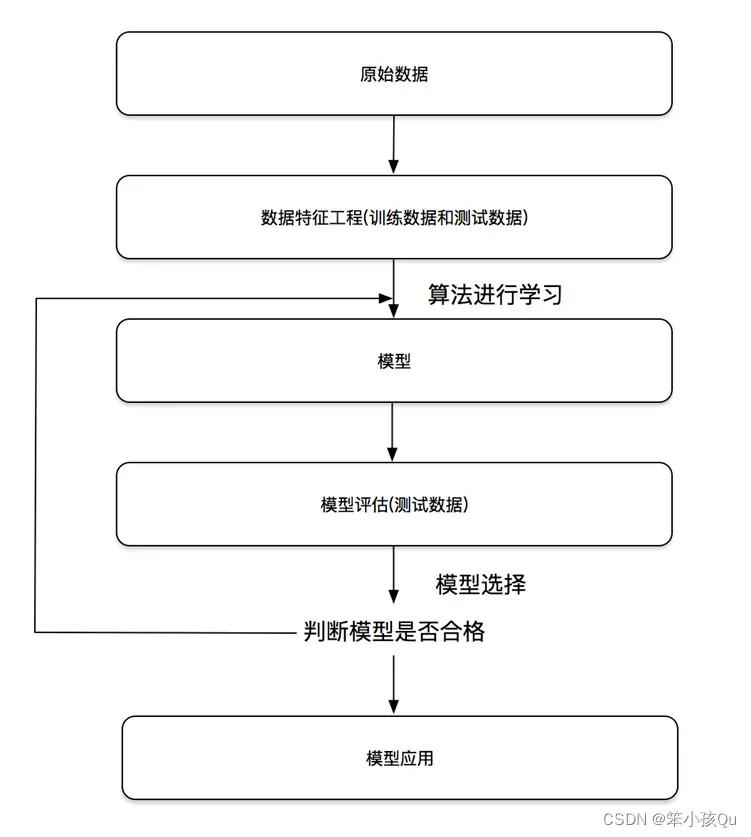
机器学习开发流程
 机器学习模型(算法+数据)
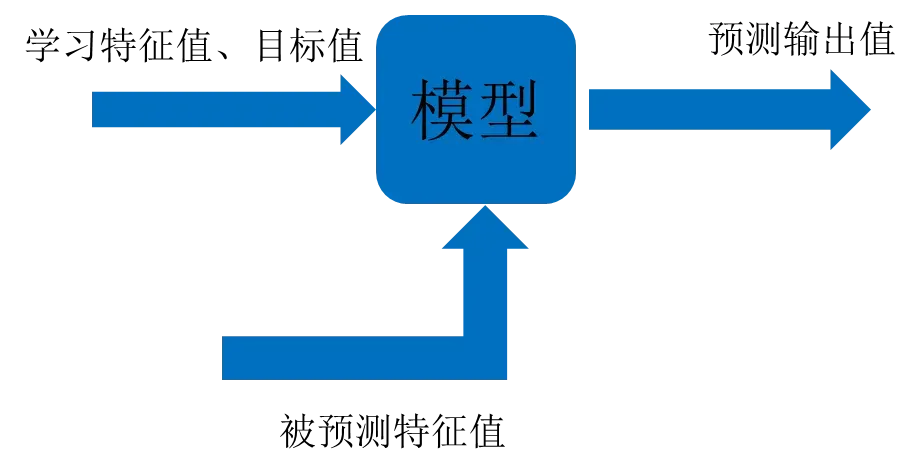
机器学习模型(算法+数据)
定义:输入值通过映射关系到输出值
机器学习算法的分类
监督学习(特征值+目标值)
监督学习(英语:Supervised learning),可以由输入数据中学到或建立一个模型,并依此模式推测新的结果。输入数据是由输入特征值和目标值所组成。函数的输出可以是一个连续的值(称为回归),或是输出是有限个离散值(称作分类)。
分类 (离散型): k-近邻算法、贝叶斯分类、决策树与随机森林、逻辑回归、神经网络
概念:分类是监督学习的核心问题。在监督学习中,当输出变量取有限个离散值时,预测问题就变成了分类问题。最基本的是二分类问题,即判断对错,选择二分类之一作为预测结果;
应用:分类就是根据数据的特点对数据进行“分类”,因此在很多领域都有广泛的应用
回归(连续):线性回归、岭回归
概念:回归是监督学习中的另一个重要问题。回归用于预测输入变量和输出变量之间的关系,输出是一个连续值。
应用:回归在很多领域也有广泛的应用
标签:隐马尔可夫模型(非必需)
无监督学习(特征值)
无监督学习(英语:Supervised learning),可以由输入数据中学到或建立一个模型,并依此模式推测新的结果。输入数据是由输入特征值所组成。
聚类 : k-means
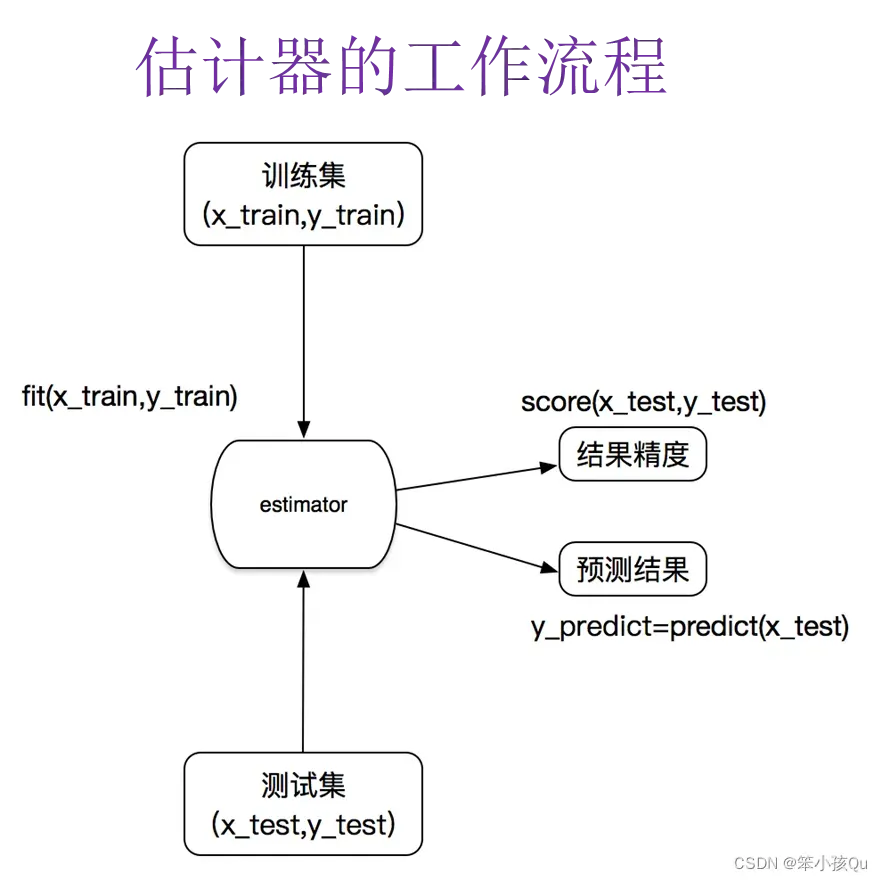
sklearn数据集与估计器
数据集分区
机器学习一般的数据集会划分为训练集、测试集(分配比例:75% : 25%):
训练集:用于训练、建立模型
测试集:在模型测试时用来评估模型是否有效
sklearn数据集接口
数据集划分API:sklearn.model_selection.train_test_split


sklearn分类数据集



sklearn回归数据集

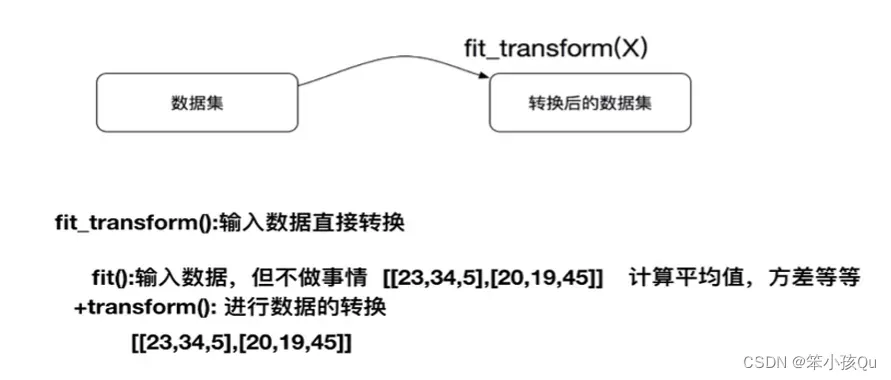
转换器和估算器
sklearn机器学习算法的实现-转换器

文章出处登录后可见!