content
foreword
数据科学不是在某一特定理论(如统计学、机器学习和数据可视化)的基础上发展起来的,而是数学与统计学相结合,与特定学科领域的理论相结合而形成的新兴学科。本文将简要介绍数据科学的理论基础(统计学、机器学习、数据可视化,以及某一领域的实践知识和经验)。
一、数据科学学科现状
从学科定位看,数据科学处于数学与统计知识、黑客精神与技能和领域实务知识三大区域的重叠之处,如图2所示。图2是Drew Conway首次提出数据科学韦恩图。图3是后来Jerry Overton提出的另一个版本。
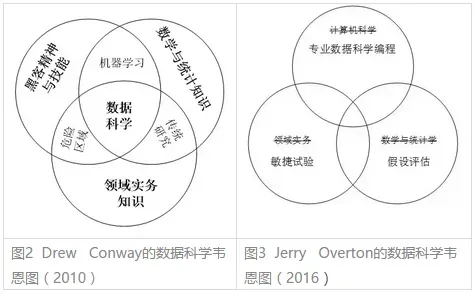
“数据与统计知识”是数据科学的主要理论基础之一,但数据科学不同于(传统)数学和统计学。主要区别如下:
- 数据学科中的“数据” != “数值” and “数据” != “数值”
- 数据科学中的“计算”!=“加减乘除等数学运算”,包括数据查询、挖掘、洞察、分析、可视化等
- 数据科学的问题!=“单学科”的问题还涉及多学科的研究范畴,强调跨学科视角
- 数据学科 != 纯理论研究 and 数据学科 != 领域实务知识,它关注和强调的是二者的结合。
“黑客精神和技能”是数据科学家的主要精神追求和技能要求——大胆创新、热爱挑战、追求完美、持续改进。
Tips : 此处涉及到黑客道德准则,感兴趣的朋友可以查阅史蒂夫 · 利维的代表作《黑客—计算机革命的英雄》。
“领域实践知识”是对数据科学家的特殊要求——不仅需要掌握数学和统计知识,具备黑客精神和技能,还需要精通特定领域的实践知识和经验。
2.统计
2.1 统计学与数据科学
数据科学的理论、方法、技术和工具往往来源于统计学。统计学是数据科学的主要理论基础之一。
2.2 数据科学中常用的统计学知识
从行为目的和思维方式来看,数据统计方法可分为描述性统计和推理性统计两大类。
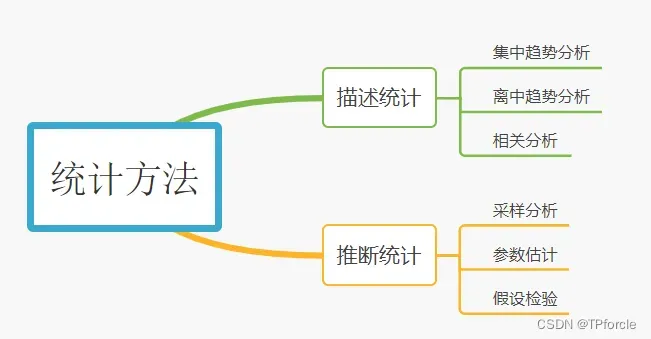
参数估计和假设检验的主要区别如下:

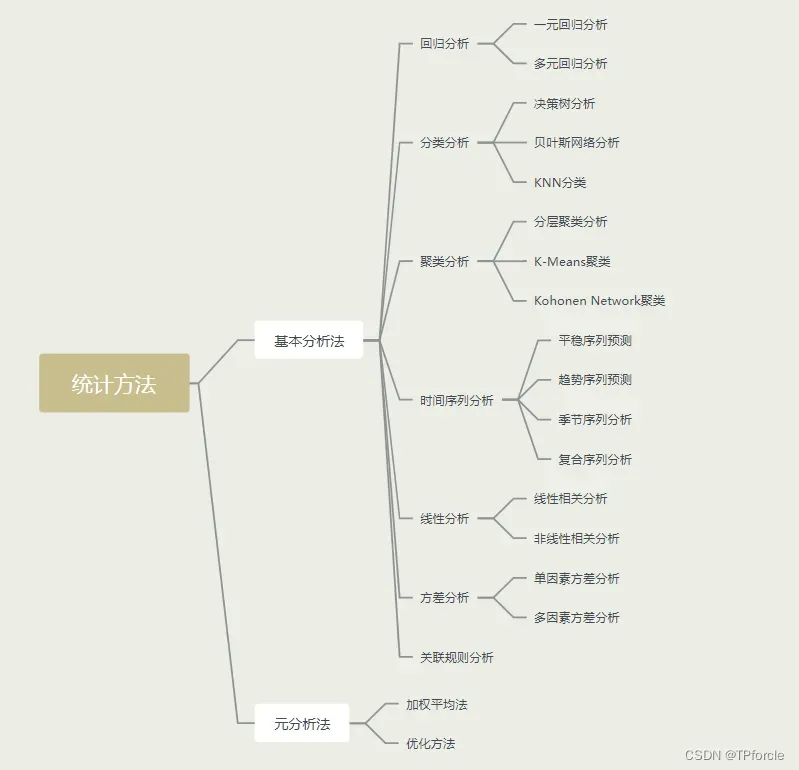
从方法论的角度来看,基于统计学的数据分析方法可以分为两个不同的层次——基础分析方法和元分析方法,如下图所示:
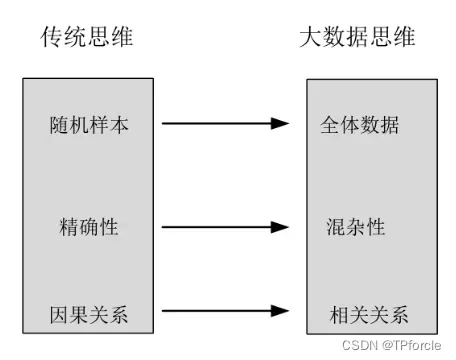
2.3 数据科学视角下的统计学
1.不是随机样本,而是全体数据
2.不是精确性,而是混杂性
3.不是因果关系,而是相关关系
3.机器学习
3.1 机器学习与数据科学
机器学习为数据科学充分发挥计算机的自动数据处理能力,拓展人类数据处理能力,实现人机协同数据处理提供了重要手段。
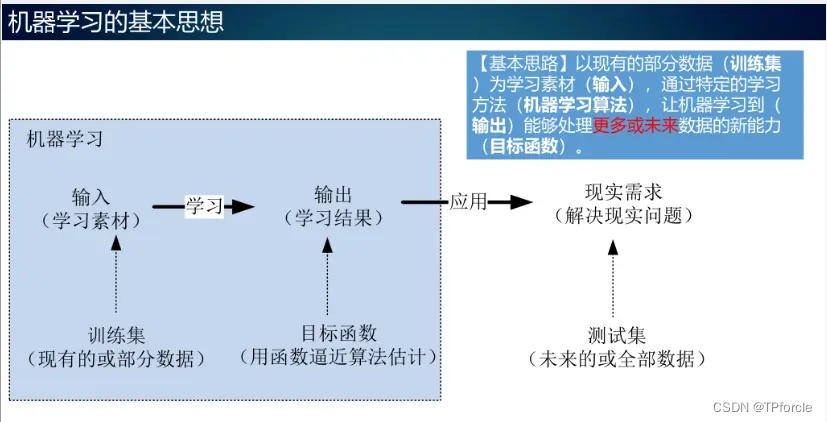
基本思想:以已有的部分数据(称为训练集)作为学习材料(输入),通过特定的学习方法(机器学习算法),让机器学习(输出)新的能力,可以处理更多或未来数据(称为目标函数)。
3.2 数据科学中常用的机器学习知识
1)基于实例学习
基本思想:预先存储训练样本,然后每当遇到新的查询实例时,学习系统都会分析新实例与之前存储的实例之间的关系,并据此为新的查询分配一个目标函数。添加实例。
常用方法:K近邻方法、局部加权回归法、基于案例的推理。
2)概念学习
本质:从布尔函数的输入和输出训练样本推断布尔函数。
具体方法:Find-S算法、候选消除算法等。
3)决策树学习
本质:逼近离散值目标函数的过程。它代表一个分类过程。
in:
根节点:代表分类的开始
叶节点:代表一个实例的结束
中间节点:表示对应实例的一个属性
节点间的边:代表一个属性的属性值
从根节点到叶节点的每条路径:代表一个特定的实例,同一路径上的所有属性之间存在“逻辑与”关系。
核心算法:ID3算法
(4)人工神经网络学习
人工神经元是人工神经网络最基本的组成部分。根据连接方式的不同,通常把人工神经网络分为无反馈的向前神经网络和相互连接型网络(反馈网络)。在人工神经网络中,实现人工神经元的方法有很多种,如感知器、线性单元和Sigmoid单元等。
特征学习方法:深度学习
(5)贝叶斯学习
定义:它是一种基于贝叶斯法则,以概率为手段进行学习的方法。常用方法:朴素贝叶斯分类器
(6)遗传算法
本质:主要研究“从候选假设空间中寻找最佳假设”。这里,“最佳假设”是指“适应度”指数最佳的假设。遗传算法借鉴的生物进化的三个基本原理:适者生存、有性繁殖和变异,分别对应遗传算法的三个基本算子:选择、交叉和变异。
遗传算法:GA算法
(7)分析学习
特征:使用先验知识分析或解释每个训练样本,以推断样本的哪些特征与目标函数相关或不相关。因此,这些假设使机器学习系统能够以比单独依赖数据更高的准确度进行泛化。
(8)增强学习
本质:主要研究的是如何协助自治Agent(机器人)的学习活动,进而达到选择最优动作的目的。基本思路:当Agent在其环境中做出某个动作时,施教者会提供奖赏或惩罚信息,以表示结果状态的正确与否。
根据学习任务的不同,机器学习算法分为:监督学习、无监督学习和半监督学习。
3.3 数据科学视角下的机器学习
机器学习领域面临的主要挑战是:
- overfitting
- 次元灾难
- 特征工程
- 算法可扩展性
- 模型集成
4.数据可视化
数据可视化在数据科学中的位置:
(1)视觉是人类获得信息的最主要的途径。
- 视觉感知是人脑的主要功能之一。
- 眼睛是人体感知信息能力最强的器官之一。
(2)相对于统计分析,数据可视化的主要优势为:
- 数据可视化可以提供对统计分析无法提供的结构和细节的洞察。
- 数据可视化处理结果的解读需要低水平的用户知识。
(3)可视化能够帮助人们提高理解与处理数据的效率。
五、总结
通过完成本章,我对数据科学、统计学、机器学习和数据可视化有了一定的了解,以后会花时间进行更深入的学习。
文章出处登录后可见!