前言:基础知识,但如果不看后面就不知道在干什么的基础知识。哎看太久i了。
状态估计问题
1.1 批量状态估计和最大后验估计
运动方程: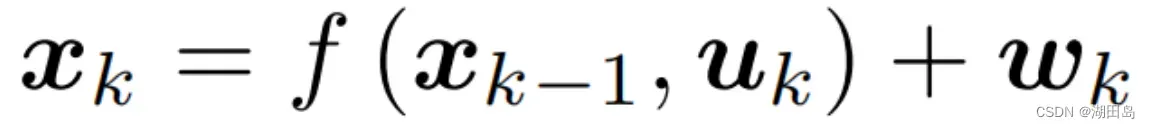 观测方程:
观测方程:
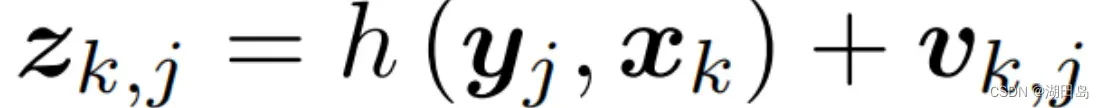 观测方程由针孔模型给定,对应到图像上的像素位置,观测方程可以写成(from ch5):
观测方程由针孔模型给定,对应到图像上的像素位置,观测方程可以写成(from ch5):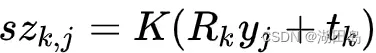 其中,K为相机内参,s为像素点的距离,xk是相机的位姿,yj是路标。w和v都是噪声分量,满足0均值的高斯分量:
其中,K为相机内参,s为像素点的距离,xk是相机的位姿,yj是路标。w和v都是噪声分量,满足0均值的高斯分量:
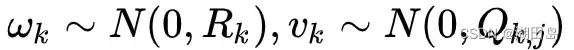 在噪声的影响下,通过带噪声的数据z和u推断位姿x和地图y(以及概率分布),即状态估计问题。
在噪声的影响下,通过带噪声的数据z和u推断位姿x和地图y(以及概率分布),即状态估计问题。
处理状态贵问题有两种方法:滤波器(渐进式/增量式),非线性优化(批量式),SLAM使用得是滑动窗口估计法,对当前时刻附近的一些轨迹进行优化。
后验分布P(x,y|z,u): 已知输入数据u(所有时刻的输入), z(所有时刻的观测数据), 求状态x, y的条件概率分布。
贝叶斯法则: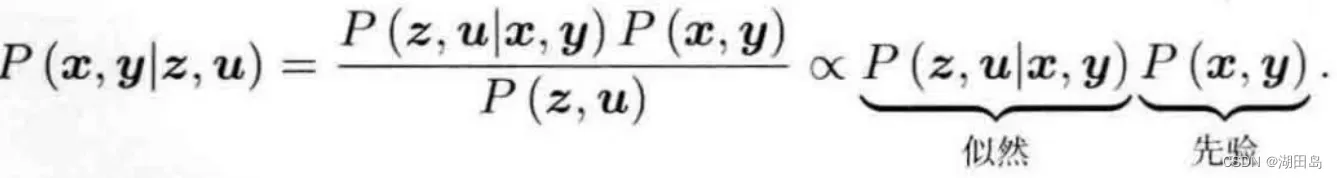 直接求解后验概率是非常困难的。该方法是最大化似然和先验的乘积,从而最大化后验概率,从而得到某个状态的最优估计。 (我理解最可能的状态)
直接求解后验概率是非常困难的。该方法是最大化似然和先验的乘积,从而最大化后验概率,从而得到某个状态的最优估计。 (我理解最可能的状态)
补充:argmax f(x,y)是指当f(x,y)取得最大值时,变量x,y的取值
最大后验估计: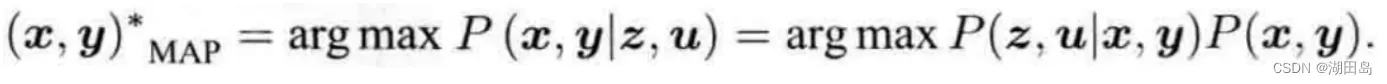
1.2 最小二乘法的引出
这里用到了两个知识点:
①由于z, u相互独立可以将式子分解;
②用数学推导求解;
首先讨论P(z|x, y):
考虑高斯分布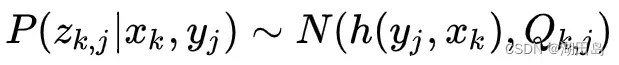 经过一些数学推导:
经过一些数学推导: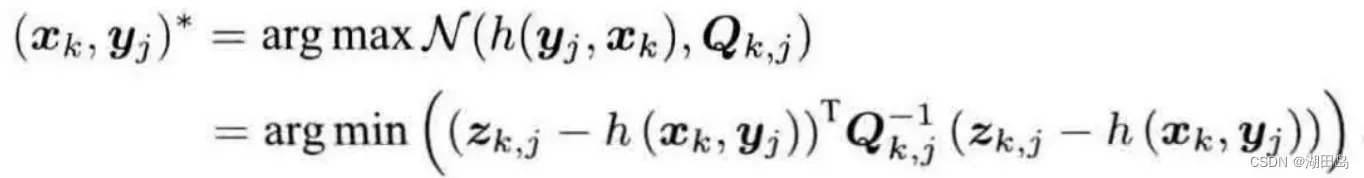 等价于最小化噪声项(重投影误差)的二次形式。 (二次形式称为马氏距离)
等价于最小化噪声项(重投影误差)的二次形式。 (二次形式称为马氏距离)
据此引出并推导P(z, u | x, y):
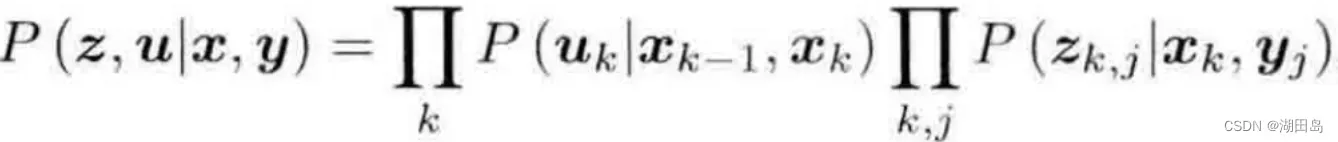 注意右侧第一项没y,是因为运动方程本身就没y。
注意右侧第一项没y,是因为运动方程本身就没y。
关于u的最大似然和关于z的最大似然是类似的,得到P(z, u | x, y)最大似然估计方法: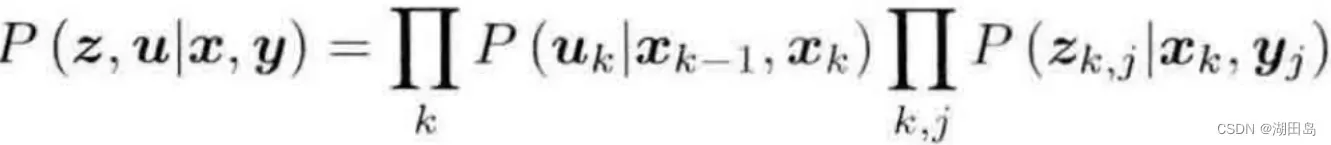 即把最大似然估计转化为最小二乘问题。
即把最大似然估计转化为最小二乘问题。
理解:当视觉里程计得到x和y,带入运动模型和观测模型时不会完美成立(存在误差),所做工作的目的是对数据进行调整,进而使得误差变小,也得到整体数据的最大似然估计。
1.3 举个例子
离散时间系统: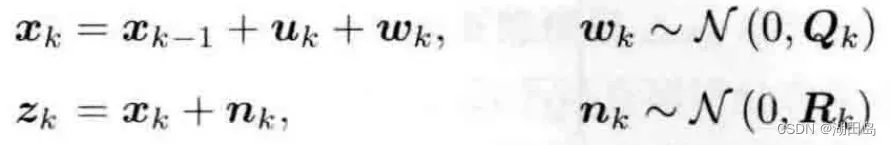 根据以上推导,最终的最小二乘目标函数为:
根据以上推导,最终的最小二乘目标函数为: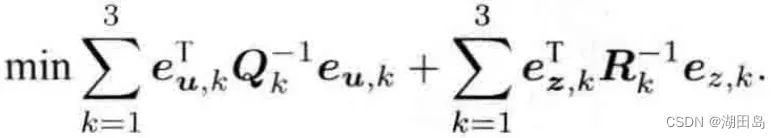
该系统是一个线性系统,可以用向量的形式求解。
2.非线性最小二乘
上一节是将SLAM问题转换成最大似然估计问题,然后又转换成最小二乘问题。本节来学习如何求解最小二乘问题。
求解某个函数的最小值,高考教我们求导数,然后带进去看哪个最小。当然,现在不是高考题,这个题不是那个题。
首先来看个normal的迭代方法: 我的理解是就是找个增量让F(x)不断下降。
我的理解是就是找个增量让F(x)不断下降。
2.1 一阶和二阶梯度法
虽然我没学过数值分析,但把F(x) Taylor展开:
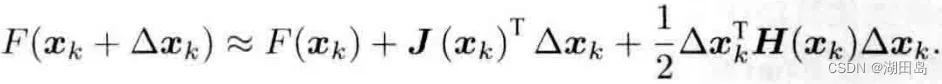 一阶梯度法(最速下降法):发现如果直接取增量x的方向为-J方向,就可以令其趋于最小;
一阶梯度法(最速下降法):发现如果直接取增量x的方向为-J方向,就可以令其趋于最小;
二阶梯度法(牛顿法):二阶导数保留:J + Hx = 0 –> Hx = -J。
这两种算法不得行,主要原因:最速下降法太贪心,反而容易增加迭代次数,收敛变慢;牛顿法得求出H,难度大。
所以有以下两种算法。
2.2 高斯牛顿法
上个是把F(x)展开,这个是把f(x)Taylor展开,再取范数的平方:
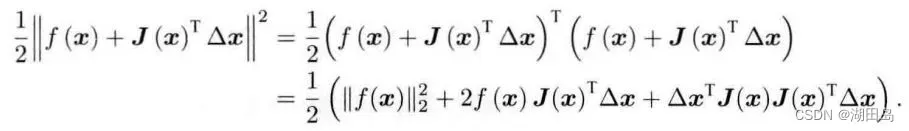 后和牛顿法一样,再对增量x求导,其实我觉得不需要展开也能求导,是这样的:
后和牛顿法一样,再对增量x求导,其实我觉得不需要展开也能求导,是这样的:
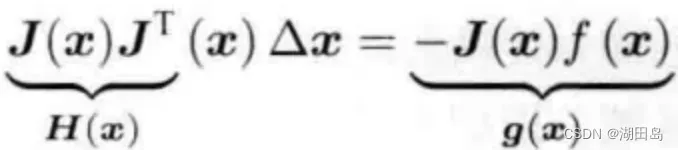 这里的H可不是海塞矩阵啦,是一阶导数雅可比矩阵的近似矩阵(也不晓得为啥整得名差不多)。然后不断迭代,和牛顿法类似。
这里的H可不是海塞矩阵啦,是一阶导数雅可比矩阵的近似矩阵(也不晓得为啥整得名差不多)。然后不断迭代,和牛顿法类似。
缺点:还是需要求H的逆,但这个H能不能逆都不一定,即便能求出来,这个增量x也太大了。
2.3 列文伯格-马夸尔特方法(LM方法)
补充:Taylor展开只在离展开点近得地方近似比较好,于是划分出一个“信赖区域”,不让他跑到近似性不好的区域。
该近似值通过以下方式判断:
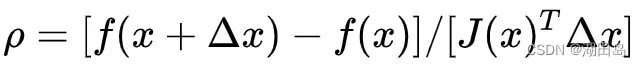 我的理解是p是J(x)的真实程度,若p是1,则说明很真,很近似,很好;若p小于1, 则说明实际减小的值少于近似减小的值,需要缩小近似范围(以实际为准),反之,p比较大,实际比预计的大,则扩大近似范围。
我的理解是p是J(x)的真实程度,若p是1,则说明很真,很近似,很好;若p小于1, 则说明实际减小的值少于近似减小的值,需要缩小近似范围(以实际为准),反之,p比较大,实际比预计的大,则扩大近似范围。
 说明:上述阈值是经验值。列文伯格把D取为单位阵I,直接把增量x约束在秋内,马夸尔特把D取成非负对角阵(实际通常是J * J^T的对角元素平方根),这使得在梯度小的维度上约束范围大些。
说明:上述阈值是经验值。列文伯格把D取为单位阵I,直接把增量x约束在秋内,马夸尔特把D取成非负对角阵(实际通常是J * J^T的对角元素平方根),这使得在梯度小的维度上约束范围大些。
步骤2中的公式右侧有一个不等式约束,即使用拉格朗日乘子将约束项置于目标函数中:
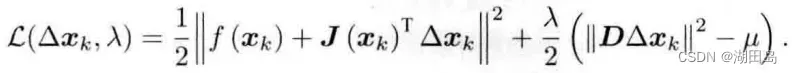 求导,导数为0,得:
求导,导数为0,得:
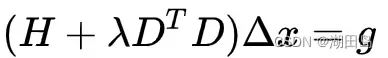 说明:这个H和高斯牛顿法的H是一样的,不是海塞矩阵哦。
说明:这个H和高斯牛顿法的H是一样的,不是海塞矩阵哦。
增量x的系数矩阵比单纯H矩阵有更强的正定性,H在这个系数的占比权重越大,二阶近似效果越好,越接近高斯牛顿法;H在这个系数的占比权重越小,二阶近似差,越接近一阶(快速)牛顿法。(D^T * D 在列文伯格这等于I)
SLAM问题中,通常选择高斯牛顿或者列文伯格-马夸尔特方法中的一个,问题性质好就用高斯牛顿法,问题太病态了就用后者。
三、总结
1、科学问题的初值提供很重要,视觉SLAM主要用ICP,PnP之类的算法提供优化初始值;
2、求解线性增量方程,一般将矩阵分解,像之前ch3提到的QR和Cholesky等方法。
4.令人兴奋的英文符号
4.1 手写高斯牛顿
回一下高斯牛顿过程:将f(x)Taylor展开令导数为0,写出增量方程不断迭代。
待拟合的曲线: y = exp(ax^2 + bx + c) + w, 已知x, y,估计a, b, c,w是噪声。
step:
① 给定初始值[2, -1, 5];
② 为了迭代求出雅可比矩阵和噪声误差(比较简单不需要Ceres / g2o);
③ 求解增量方程,得到增量x;
④ 迭代直到次数达到上限或者增量x达到理想值。
这里有一点需要注意。这里状态估计中使用的范数是作为内积的信息矩阵。具体推导见这篇文章。我认为这很容易理解。增量方程如下: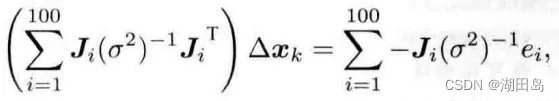
代码部分:
我和书里写得不太一样,主要是对M^{-1}的定义上,我只用一个inv,书里用了inv * inv。但结果一样。奇怪[0]
int main(int argc, char **argv) {
double aa = 1.0, ba = 2.0, ca = 3.0;//真实参数值
double ae = 2.0, be = -1.0, ce = 5.0;//估计参数值
int N = 100; //数据点
double w_sigma = 1.0;
double inv_sigma = 1.0 / w_sigma; //set 1/Sigma = W^{-1}
cv::RNG rng;
//prepare data
vector<double> x, y;
for(int i = 0; i < N; i++){
double temp = i / 100.0;
x.push_back(temp);
y.push_back(exp(aa * temp * temp + ba * temp + ca) + rng.gaussian(w_sigma));
}
//Gauss-Newton
int iteration = 100; //time
double cost = 0, lastCost = 0; // 本次迭代的cost和上一次迭代的cost
chrono::steady_clock::time_point t1 = chrono::steady_clock::now();
for(int i = 0; i < iteration; i++) {
Matrix3d H = Matrix3d::Zero(); // H = J^T * W^{-1} * J
Vector3d g = Vector3d::Zero(); // g = -J^T * W^{-1} * w
cost = 0;
for(int j = 0; j < N; j++){
double xi = x[j], yi = y[j];
double error = yi - exp(ae * xi * xi + be * xi + ce);
Vector3d J;
J[0] = -xi * xi * exp(ae * xi * xi + be * xi + ce); // de/da
J[1] = -xi * exp(ae * xi * xi + be * xi + ce); // de/db
J[2] = -exp(ae * xi * xi + be * xi + ce); // de/dc
H += inv_sigma * J * J.transpose();
g += -inv_sigma * error * J;
cost += error * error;
}
Vector3d dx = H.ldlt().solve(g);
if(isnan(dx[0])) {
cout<<"result is nan!"<<endl;
break;
}
if(i > 0 && cost >= lastCost){
cout << "cost: " << cost << ">= last cost: " << lastCost << ", break." << endl;
break;
}//notice that i > 0
ae += dx[0];
be += dx[1];
ce += dx[2];
lastCost = cost;
cout << "total cost: " << cost << ", \t\tupdate: " << dx.transpose() <<
"\t\testimated params: " << ae << "," << be << "," << ce << endl;
}
chrono::steady_clock::time_point t2 = chrono::steady_clock::now();
chrono::duration<double> time_used = chrono::duration_cast<chrono::duration<double>>(t2 - t1);
cout << "solve time cost = " << time_used.count() << " seconds. " << endl;
cout << "estimated abc = " << ae << ", " << be << ", " << ce << endl;
return 0;
}
result:
xdhu@ubuntu:~/Downloads/slambook2-master/ch6/build$ ./gaussNewton
total cost: 3.19575e+06, update: 0.0455771 0.078164 -0.985329 estimated params: 2.04558,-0.921836,4.01467
total cost: 376785, update: 0.065762 0.224972 -0.962521 estimated params: 2.11134,-0.696864,3.05215
total cost: 35673.6, update: -0.0670241 0.617616 -0.907497 estimated params: 2.04432,-0.0792484,2.14465
total cost: 2195.01, update: -0.522767 1.19192 -0.756452 estimated params: 1.52155,1.11267,1.3882
total cost: 174.853, update: -0.537502 0.909933 -0.386395 estimated params: 0.984045,2.0226,1.00181
total cost: 102.78, update: -0.0919666 0.147331 -0.0573675 estimated params: 0.892079,2.16994,0.944438
total cost: 101.937, update: -0.00117081 0.00196749 -0.00081055 estimated params: 0.890908,2.1719,0.943628
total cost: 101.937, update: 3.4312e-06 -4.28555e-06 1.08348e-06 estimated params: 0.890912,2.1719,0.943629
total cost: 101.937, update: -2.01204e-08 2.68928e-08 -7.86602e-09 estimated params: 0.890912,2.1719,0.943629
cost: 101.937>= last cost: 101.937, break.
solve time cost = 0.000277778 seconds.
estimated abc = 0.890912, 2.1719, 0.943629
文章出处登录后可见!