想查看其他题的真题及题解的同学可以前往查看:CCF-CSP真题附题解大全
| 试题编号: | 202305-3 |
| 试题名称: | 解压缩 |
| 时间限制: | 5.0s |
| 内存限制: | 512.0MB |
| 问题描述: |
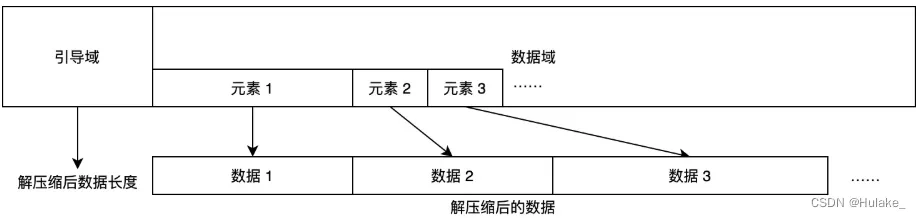
题目背景西西艾弗岛运营公司是一家负责维护和运营岛上基础设施的大型企业。在公司内,有许多分管不同业务的部门都需要使用到服务器设施。为了便于管理,同时降低公司运行成本, 日志服务器收集到的日志都是纯文本,且高度格式化。这意味着日志数据可以被压缩得非常小。但是日志数据量非常大,且对处理效率的要求较高,因此可以牺牲一定的压缩率,使用高效的压缩算法来压缩日志数据。 问题描述这种压缩算法产生的数据流,可以被视为是一系列的元素。元素分为两种:字面量和回溯引用。字面量包含一系列的字节,对其进行解压缩时,直接将这些字节输出即可。 被压缩的数据格式分为两部分:导引域和数据域。其中导引域保存了原始数据的长度。设原始数据长度为 n。则 n 可以表示为 ∑k=0dck×128k,其中 0≤ck<128,且
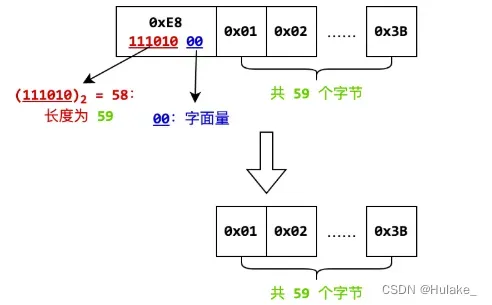
数据域保存了被压缩后的数据,是连续存储的元素的序列。每个元素的第一个字节的最低两位表示了元素的类型。当最低两位为 0 时,表示这是一个字面量。如果字面量包含的字节个数为 l,且 l≤60,
当元素首字节的最低两位是
例如,字节
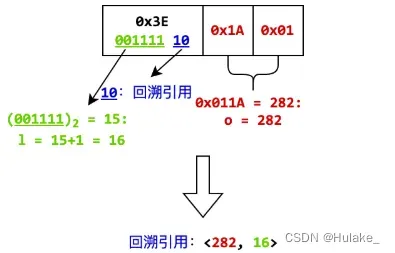
当元素首字节的最低两位是
我们规定,元素的首字节的最低两位不允许是 压缩后的数据为合法的,当且仅当以下条件都满足:
输入格式从标准输入读入数据。 输入包含有若干行,第一行是一个正整数 s,表示输入被解压缩数据的字节数。 接下来有 ⌈s8⌉ 行,表示输入的被解压缩的数据。每行只含有数字或字母 输出格式输出到标准输出中。 输出解压缩后的数据,每行连续输出 8 个字节,每个字节由两位十六进制数字(数字或字母 样例输入
样例输出
样例说明上述输入数据可以整理为:
首先读入第一字节 然后继续读入字节 然后继续读入字节 然后继续读入字节 然后继续读入字节 此时,输入已经处理完成,共输出了 10+61+50+7=128 字节,与从引导区中读入的原始数据长度一致,因此解压缩成功。 子任务对于 10% 的输入,解压缩后的数据长度不超过 127 字节,且仅含有字面量,每个字面量元素所含数据的长度不超过 60 字节; 对于 20% 的输入,解压缩后的数据长度不超过 1024 字节,且仅含有字面量,每个字面量元素所含数据的长度不超过 60 字节; 对于 40% 的输入,解压缩后的数据长度不超过 1024 字节,且仅含有字面量; 对于 60% 的输入,解压缩后的数据长度不超过 1024 字节,且包含的回溯引用的首字节的最低两位都是 对于 80% 的输入,解压缩后的数据长度不超过 4096 字节; 对于 100% 的输入,解压缩后的数据长度不超过 2MiB(2×220 字节),且 s≤2×106,且保证是合法的压缩数据。 |
真题来源:解压缩
感兴趣的同学可以如此编码进去进行练习提交
题目理解:
给你一段压缩过的代码,可以拆分为引导域和数据域,引导域决定了解压缩后的数据长度,数据域也是可以分段的,每一段由其第一个字节的最低两位决定,若为00,则是字面量,若为01或10,则为回溯引用。输出解压缩后的数据,8字节为一行,最后一行允许不到8个字节。
思路分析:
由于要多次读取字节,所以最好封装一个函数来 读取字节 ,记录当前读到的位置。由于要进行小端序调整字符串,可以考虑封装一个函数来 按小端序调整字符串 。由于01和10结尾都要回溯引用,也可以封装一个函数来 填充字符串 。由于用字节处理太麻烦了,可以使用 stoi()——有符号整型 或者 stoul——无符号整型 来进行进制转换。
c++满分题解:
#include <bits/stdc++.h>
using namespace std;
const int N = 2e6 + 10;
int n, idx, p; // 当前已经解压缩了 p 字节,下一个读的是第 idx 下标的字符
string res; // 解压后的数据
string readBytes(int num)
{
char byte[2 * num];
for (int i = 0; i < 2 * num; i ++) cin >> byte[i];
idx += num * 2;
return string(byte, 2 * num);
}
void trackBack(int o, int l)
{
int start = res.length() - o * 2;
int len = o * 2;
string back_track_string = res.substr(start, len);
int cnt = 0;
while (cnt < l * 2 - l * 2 % len)
{
res += back_track_string;
cnt += len;
}
res += back_track_string.substr(0, l * 2 % len);
}
int main()
{
cin >> n;
string bts;
vector<int> c;
int v_c;
// 读入字节 直到最高位为0
while ((bts = readBytes(1)) >= "80")
{
v_c = stoi(bts, nullptr, 16);
v_c -= 128;
c.push_back(v_c);
}
// 最高位为0时,直接保存到c里
v_c = stoi(bts, nullptr, 16);
c.push_back(v_c);
// 引导区结束,计算原始数据长度
int length = 0;
for (int i = 0; i < c.size(); i ++) length += c[i] * pow(128, i);
while (idx < n * 2)
{
// 接下来是数据域
// 读入一个字节
bts = readBytes(1);
string string_to_binary = bitset<8>(stoi(bts, nullptr, 16)).to_string();
string lowest_two_digits = string_to_binary.substr(6, 2);
if (lowest_two_digits == "00")
{
string high_six_digits = string_to_binary.substr(0, 6);
int ll = stoi(high_six_digits, nullptr, 2);
// l <= 60,高六位 ll 表示 l - 1
if (ll <= 59)
res += readBytes(ll + 1);
else
{
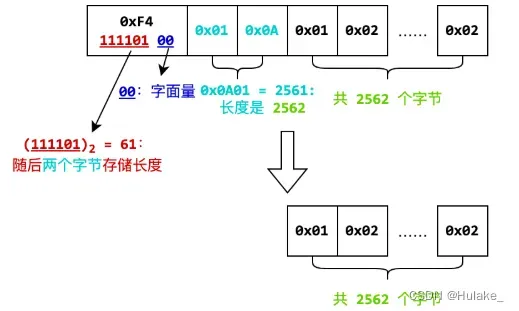
// 第一个字节的高六位存储的值为 60、61、62 或 63 时,分别代表 l - 1 用 1、2、3 或 4 个字节表示
int literal_length = ll - 59;
// 按照小端序重组字符串 0x01 0x0A => 0x0A01
string string1 = readBytes(literal_length);
string string2;
// 字符串每两位反转
for (int i = string1.length() - 2; i >= 0; i -= 2)
string2 += string1.substr(i, 2);
int l = 1 + stoi(string2, nullptr, 16); // 字面量长度
res += readBytes(l);
}
}
else if (lowest_two_digits == "01")
{
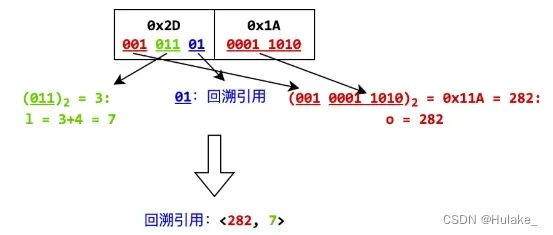
// 第 2 ~ 4 位即 从下标 3 开始的三位 001 011 01
string two_to_four_digits = string_to_binary.substr(3, 3);
// l - 4 占 3 位,存储于首字节的 2 至 4 位中
int l = stoi(two_to_four_digits, nullptr, 2) + 4;
// o 占 11 位,其低 8 位存储于随后的字节中,高 3 位存储于首字节的高 3 位中
string high_three_digits = string_to_binary.substr(0, 3);
string next_byte_binary = bitset<8>(stoi(readBytes(1), nullptr, 16)).to_string();
int o = stoi(high_three_digits + next_byte_binary, nullptr, 2);
// 回溯引用
trackBack(o, l);
}
else if (lowest_two_digits == "10")
{
string high_six_digits = string_to_binary.substr(0, 6);
// l 占 6 位,存储于首字节的高 6 位中
int l = stoi(high_six_digits, nullptr, 2) + 1;
// o 占 16 位,以小端序存储于随后的两个字节中
string string1 = readBytes(2);
string string2;
// 字符串每两位反转
for (int i = string1.length() - 2; i >= 0; i -= 2)
string2 += string1.substr(i, 2);
int o = stoi(string2, nullptr, 16);
// 回溯引用
trackBack(o, l);
}
}
for (int i = 0; i < res.length(); i ++)
{
cout << res[i];
// 输出,每16个字符加一个换行
if ((i + 1) % 16 == 0) cout << endl;
}
// 若最后一行不能凑8个,则补一个换行
if (res.length() % 16) cout << endl;
return 0;
}
运行结果:

文章出处登录后可见!