1. 决策树
1.1 信息增益
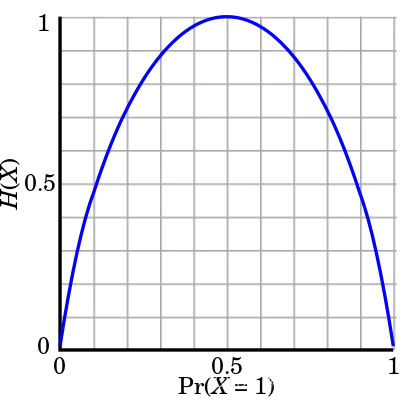
**熵:**衡量不确定程度。熵越大,随机变量不确定性越大。熵只依赖于随机变量X的分布,与X的取值无关。
当随机变量只有两个值0,1的时候,
熵随概率变化的曲线如下图,当p=0或p=1的时,H§=0,随机变量完全没有不确定性; 当p=0.5时,H§=1,随机变量不确定性最大(p=0.5相当于随机抽)
条件熵: H(Y|X),给定条件X之后随机变量Y的不确定性
信息增益:已知特征X的信息对Y的不确定性减少的程度; 表示为。
example:
- 样本量N=15,9个正样本,6个负样本;
- 特征X1:年龄{‘青年’:{正:2,负:3};‘中年’:{正:3,负:2};‘老年’:{正:4,负:1}}
信息增益:已知特征X的信息对Y的不确定性减少的程度; 表示为。
**信息增益比:**在以信息增益为准则划分特征时,偏向类别较多的特征,增益比可以纠正这个问题
1.2 基尼指数
从数据集D中随机抽取2个样本,类别标记不一致的概率。基尼指数越小,数据集的纯度越高
对于二元分类问题:
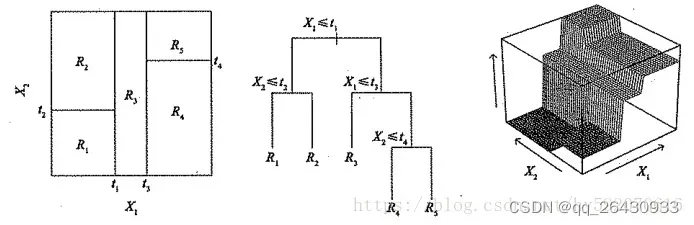
1.3 决策树的生成
1.4 特征为连续值
C4.5决策树采用的方法:二分法,特征所有取值的中位数作为划分点。
example:
假设特征X1为学生的成绩,,排序后变成
,取中位数作为划分点
,然后分别计算这些划分点对应的信息增益,选择其中信息增益最大的划分点。
1.5 回归树
构建回归树的过程大致可以分为两个步骤:
- 将特征空间
的可能取值构成的集合分割成J 个互不重叠的区域
- 对落入区域
的每个观测值进行相同的预测,预测值等于
比如,在第一步中得到两个区域和
,
,若
,则给出的预测值为10;若
,则给出的预测值为20。
所以,决策树分类算法的关键在于如何构建区域划分。事实上,区域的形状是可以为任意形状的,但出于模型简化和增强可解释性的考虑,这里将预测变量空间划分成高维矩形,我们称这些区域为称盒子。划分区域的目标是找到使模型的残差平方和RSS最小的矩形区域
。RSS的定义为:
在执行递归二又分裂时,先选择预测变量和分割点s,将预测变量空间分为两个区域
和
,使RSS尽可能地减小。更详细地,定义一对半平面:
找到 和
以最小化以下内容:
生成region后,就可以确定给定的测试数据所属的区域,并将该区域的训练集中每个样本的值的算术平均值作为预测的测试。
2. 集成学习 ensemble learning
集成学习是一种将弱学习器组合成强学习器的方法。它有两个优点。首先,找到弱学习者比找到强学习者要容易得多。其次,组合学习器可以提高模型的泛化性能。
考虑二分类问题,假设分类器的错误率为,真实函数为
,对于每个基分类器
我们有
如果T个基分类器中超过半数投票正确,则认为集成分类正确,假设T个基分类器的错误率相互独立.则有Hoeffding不等式可知,集成分类器的错误率如下,公式中个表示基分类器正确的个数,
表示基分类器正确率。
上式显示,随着分类器数目T的增大,集成错误率指数下降。
通常选择个别学习者的标准是:
- 个体学习器必须有一定的准确率,预测能力不能太差。个体学习者之间
- 存在多样性,即学习者之间存在差异。
2.1 Boosting
2.1.1 AdaBoost
**如何将弱分类器组合成强分类器
- 增加错误分类样本的权重;
- 基分类器对错误率的权重较高; **

2.1.2 Addictive model
AdaBoost 算法可以认为是:模型为加法模型、损失函数为指数函数、学习算法为前向分步算法的二类分类学习方法。
forward-step-by-step算法解决这个优化问题的思路是:因为学习是一个加法模型,如果每一步都可以从前到后学习上一步的残差,则优化目标函数可以逐渐逼近,优化的复杂度可以简化。
梯度提升树过程:
2.2 Bagging
为得到泛化性能强的集成模型,基学习器应该尽可能相互独立,独立无法在现实中做到,但可以设法让基学习器间尽可能有较大的差异。Bagging方法通过对样本有放回的抽样实现,采样出T个包含m个训练样本的数据集,并训练得到基学习器,再将这写学习器组合。T个基学习器对分类任务通常使用简单投票法,对回归任务使用平均法。
2.1.1 随机森林
RF不仅通过样本扰动,还通过属性扰动(随机抽取特征),来实现基学习器的多样性。
2.3 Stacking 待补充
2.4 Boosting和Bagging比较
- 关于样本选择:
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。 - 样品重量:
Bagging:使用均匀取样,每个样例的权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。 - 预测功能:
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
从偏差-方差分解的角度来看: - variance-bias:
Bagging主要关注降低方差,它能平滑强学习器的方差。因此它在非剪枝决策树、神经网络等容易受到样本扰动的学习器上效果更为明显。
Boosting 主要关注降低偏差,它能将一些弱学习器提升为强学习器。因此它在SVM 、knn 等不容易受到样本扰动的学习器上效果更为明显。
3 参考
文章出处登录后可见!