摘要:
注意机制允许模型保持可解释性,提升了NLP任务的表现。自我注意是目前广泛使用的一种注意类型,但由于存在大量的注意分布,其可解释性较差。最近的研究表明,模型表示可以受益于特定标签的信息,同时促进对预测的解释。因此作者引入标签注意层——一种新的自我注意形式,注意头代表标签。实验结果表明,作者的新模型在Penn Treebank (PTB)和Chinese Treebank上都获得了最先进的结果。此外,与现有的工作相比,作者的模型需要更少的self-attention层。最后,作者发现标签注意头学习句法类别之间的关系,并显示分析错误的路径。
相关代码链接[0]
一、简介:
1.1 作者发现的问题:
自注意力机制可解释,但多个注意力组合后作用的结果难以预测
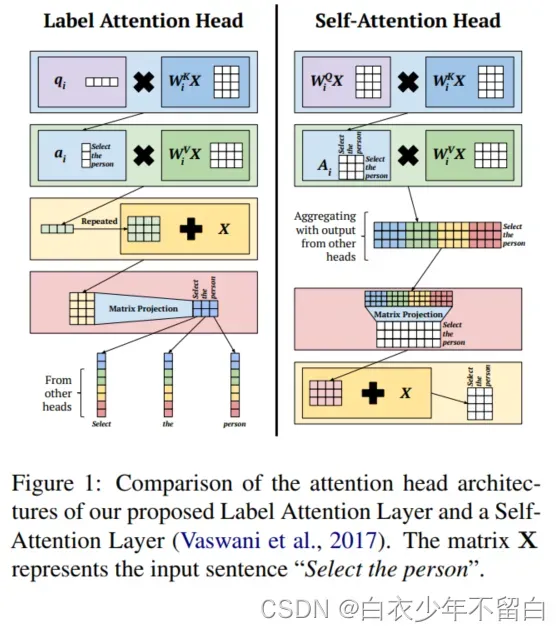
自注意力机制提供了可解释的注意力分布,有助于解释预测,比如在机器翻译领域预测。同样,在Transformer架构里,自我注意头产生从输入词到相同输入词的注意分布。(如图1所示)但是,自注意力机制有多个头,使得组合后的输出难以预测。
1.2、作者提出的解决方案
1.2.1、Label Attention Layer
最近的工作显示label-specific representations不仅效率高和,而且可解释性好。作者引入the Label Attention Layer(自注意机制的改进版本,其中每个分类标签对应一个或多个注意头。)作者在注意力头级别研究输出,而不是在聚集所有输出之后。这样做的目的是留头部特定信息的来源,从而允许作者将标签与头部匹配。
1.2.2、LAL-Parser
为了验证所提出的Label Attention Layer,作者在Head-Driven phrase structure grammar所提出的parser基础上,新建一个能处理中文和英文的结构成分语法分析和依存语法分析的句法分析器。
二、Label Attention Layer
自注意力机制实现了句子单词间信息的传递,每个输出的单词表示(词向量)都包含了考虑过整个句子后的注意力权重。作者假设在自注意力获得信息的基础上,对于同一个句子,从不同注意力加权角度来看,一个单词的词向量表示有多种,那么这个个单词的词向量表示就可以得到加强。比如同一个句子,我用成分语法分析,再用依存句法分析,那么句中单词词向量表示更加丰富。(刚才是我对作者的观点的理解,原话是We hypothesize that a word representation can be enhanced by including each label’s attention-weighted view of the sentence, on top of the information obtained from self-attention )
Label Attention Layer(LAL)是一种新颖的、改进的自我注意形式,每个注意头只需要一个查询向量。每个分类标签都由一个或多个注意头表示,这允许模型学习输入句子的特定标签视图。图1显示了Label Attention Layer和self-attention之间的高级比较。
作者将通过解析的示例应用程序解释作者提议的Label Attention Layer背后的架构和直觉。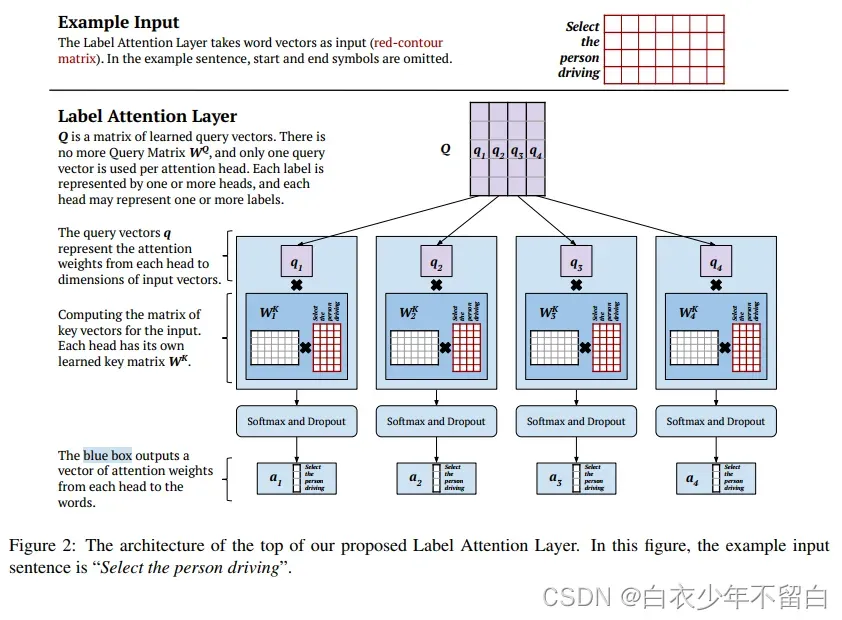
图2显示了标签注意机制和自我注意之间的一个主要区别:查询矩阵的缺失;相反,作者有一个学习过的矩阵
,由表示每个头的查询向量组成。更正式说,对于注意力头
和输入词向量矩阵
,我们如下(式子1)计算相关注意力权重向量
:
这里d为查询向量和关键向量的维数,是关键向量的矩阵,给定一个已知的头部特定的键矩阵
,我们计算
如下(式2):
在Label Attention 层,每个注意力头都有一个注意力向量,取代了之前自注意力机制的注意力矩阵。因此,作者这得到的不是向量的矩阵,而是包含特定于头部的上下文信息的单个向量。这个上下文向量对应于图3中的绿色向量。我们计算头的上下文向量
如下(式3):
这里是方程式(1)中的注意力权重向量,
是值向量矩阵,给定一个已知的头部特定的键矩阵
,我们计算
如下(式4):
上下文向量被添加到每个单独的输入向量—使得每个头有一个剩余连接,而不是所有头都有一个剩余连接,如图3中的黄色框中所示。在normalizing之前,我们将单词向量的结果矩阵投影到低维。然后,我们分配由每个标签注意头计算的向量,如图4所示。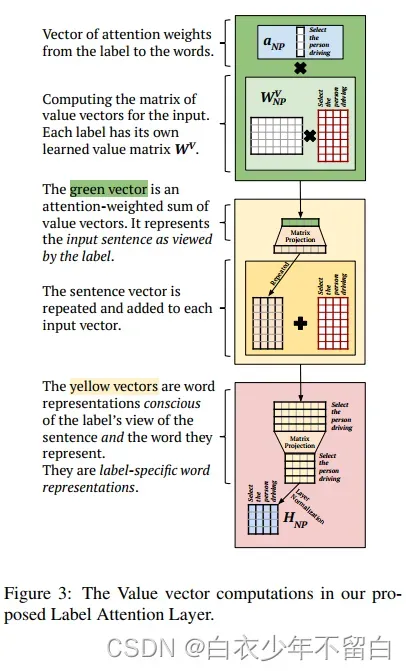
位置前馈层的激活函数使得跟踪贡献的路径变得困难。因此,我们可以去掉位置前馈层,并计算每个标签的贡献。我们在图6中提供了一个示例,其中使用标准化和平均来计算贡献。在这种情况下,我们计算每个头对空间向量的贡献。“person”的跨度表示按照Gaddy等人(2018)和Kitaev和Klein(2018)的方法计算。然而,前向表示和后向表示不是通过在中间分割整个单词向量来形成的,而是通过在中间分割每个特定于头部的单词向量来形成的。
在图6的示例中,我们将平均作为计算贡献的一种方式,可以使用其他功能,如softmax。另一种解释预测的方法是看从头到尾的注意力分布,这是图2中计算的输出向量。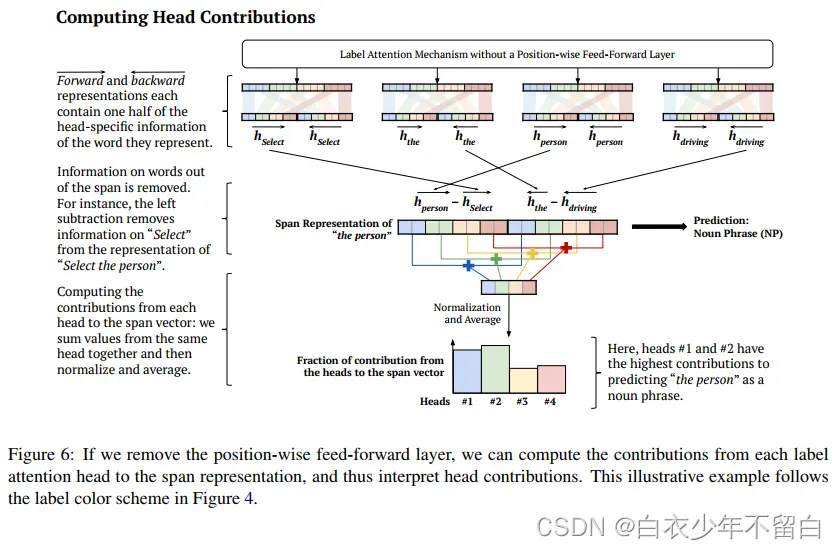
三、Syntactic Parsing Model
3.1、Encoder
我们的解析器是一个编码器-解码器模型。编码器有自我注意层,在标签注意层之前。我们遵循Kitaev和Klein的注意力划分,他们表明将内容嵌入与位置嵌入分离可以提高性能。
句子在周和赵(2019)之后进行预处理。树使用简化的头部驱动短语结构语法(HPSG)表示(Pollard和Sag, 1994)。Zhou和Zhao(2019)提出了两种跨度表示:划分跨度和联合跨度。我们选择关节跨度表示,因为它是他们的实验中表现最好的一个。图5显示了图2中的示例句子是如何表示的。
我们模型的令牌表示是内容和位置嵌入的串联。内容嵌入是词嵌入和词性嵌入的总和。
3.2、Constituency Parsing
我这里不注意,先忽略。
3.3、Dependency Parsing
我们使用biaffine注意机制(计算每个单词的依赖头的概率分布)。第j个单词作为第i个单词头的child-parent得分如下(式10):
其中为第
个单词的依存表示向量,是将其词向量
通过单层感知机得到的。同样,
为第
个单词的依存表示向量,是将其词向量
通过一个单独的单层感知机得到的。矩阵
是学习参数。该模型通过最小化正确依存树的负似然函数来训练依赖解析。损失函数为交叉熵,如下(式11):
其中是
的正确的核心词(head),
是
是
的核心词的概率,
是孩子-父亲关系对
正确的依存标签(label)
的概率。
3.4、Decoder
该模型通过最小化成分句法分析和依存分析损失的总和来联合训练成分句法分析和依存句法分析,如下(式12):
解码器是一种cky型算法,由Zhou和Zhao(2019)改进,包括依存句法评分。
4. 实验
我们在英国的Penn Treebank (PTB)和中国的CTB (CTB)上评估了我们的模型。我们使用Stanford标签器(Toutanova et al., 2003)来预测词性标签并遵循标准的数据分割。
按照标准实践,我们使用EVALB算法(Sekine and Collins, 1997)进行成分句法分析,报告结果时不使用标点符号进行依存句法分析。
4.1、Setup
在作者的英语实验中,标签注意层有112个正面:每个句法类别一个。然而,这是一个实验性的选择,因为该模型并没有设计为注意头和句法类别之间的一对一对应。中文树库是一个较小的数据集,因此作者在汉语实验中使用了64个头,尽管汉语句法类别的数量要高得多。两种语言的查询向量、键向量、值向量以及每个标签注意头的输出向量均为128维,这是通过短时间的参数调优实验确定的。对于依赖性和跨度评分,作者使用与Zhou和Zhao(2019)相同的超参数。在英语实验中,作者使用大型预训练XLNet作为嵌入模型,在汉语实验中使用基本的预训练BERT作为嵌入模型。
作者尝试使用2、3、4、6、8、12和16个自我注意层的英语分析器。作者有3个和4个自我注意层的解析器根据F1分数和UAS和LAS分数的总和进行捆绑。作者的微调实验结果在附录中。为了降低计算复杂度,作者决定在接下来的所有实验中使用3个自我注意层。
4.2、Ablation Study
如图6所示,作者认为只有在没有位置前馈层的情况下,才能计算标签注意头的贡献。自我注意的剩余缺失适用于所有head的聚合输出。在标签注意中,剩余dropout分别应用于每个注意力头的输出,因此可以抵消部分注意力头的贡献。作者研究了从LAL中去除这两种成分的影响。
表1显示了我们在PTB数据集上对残差和位置前馈层进行ablation study的结果。我们使用与Zhou和Zhao(2019)相同的残差退出概率。当去掉位置前馈层并保持剩余dropout时,我们观察到整体性能仅略有下降,如第二行所示。因此,没有显著的性能损失来交换可解释性的注意头。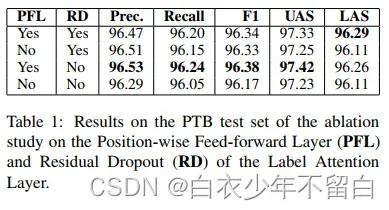
最后,移除位置前馈层和残余损失会显着降低性能。我们继续我们的实验,没有残留的辍学。
4.3 Comparison with Self-Attention
作者提出的标签注意力层的两个主要架构创新是:使用学习到的查询向量来表示标签和替换自注意力中的查询矩阵;在自我注意中使用连接每个注意头的输出而不是矩阵投影。
在本小节中,作者将评估我作者提出的架构创新是否会带来性能改进。为此,作者建立了一项消融研究来比较标签注意和自我注意。作者基于我们最好的解析器提出了三个额外的模型架构:所有模型都有3个自我注意层和一个包含112个注意头的改进标签注意层。三种修改后的标签注意层如下:(1)去除查询向量:第一个模型(图7左边)有一个像self-attention一样的查询矩阵,并连接像Label Attention一样的注意头输出。(2)去除拼接:第二个模型(图7右侧)有一个类似Label Attention的Query Vector,并对所有头部输出(如self-attention)应用矩阵投影。(3)去除查询向量和拼接:第三种模型(图1右侧)有112个头部的自我注意层。
实验结果见表2。第二行显示,即使查询矩阵比查询向量使用更多的参数和计算,用查询矩阵代替查询向量会降低性能。当删除连接时,性能也会有类似的下降,如最后一行所示。这表明作者的标签注意层在它的查询向量中学习有意义的表示,并且比起查询矩阵和单词到单词的注意分布,单词到单词的注意分布对性能更有帮助。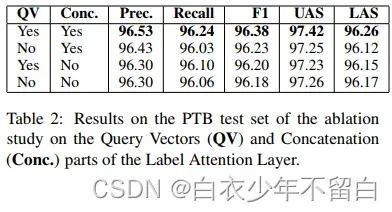
4.4、English and Chinese Results
作者表现最好的英语解析器没有剩余的dropout,但有一个位置的前馈层。作者使用相同的配置来训练中文解析器。中文树库有两个数据分割用于培训、开发和测试集:一个用于选区(Liu和Zhang, 2017b),一个用于依赖解析(Zhang和Clark, 2008)。
最后,作者将作者的结果与中英两种语言的选区分析和依存关系分析的最新进展进行比较。表3显示了成分句法解析结果,表4显示了依存句法解析结果。作者的LAL解析器在两种语言中都建立了最先进的结果,显著改善了依赖性解析。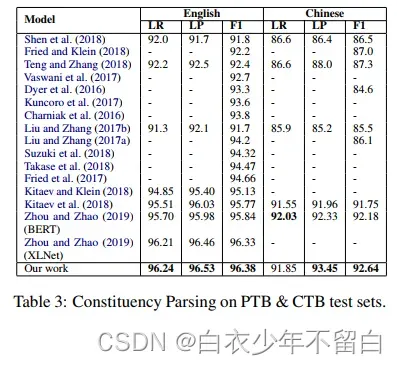
五、Related Work
只是回顾历史。
六,结论
在本文中,作者引入了一种新的自我注意形式:标签注意层。在作者提出的架构中,注意头代表标签。我们将我们的Label Attention Layer纳入HPSG解析器(Zhou and Zhao, 2019),并在Penn Treebank和Chinese Treebank上获得最新的研究结果。在英语中,我们的结果显示,选区解析为96.38 F1,依赖性解析为97.42 uas和96.26 LAS。在中文中,我们的模型实现了92.64 F1, 94.56 UAS和89.28 LAS。
作者进行了消融研究,表明作者的标签注意层学习的查询向量优于自注意查询矩阵。因为我们只有一个学习向量作为查询而不是矩阵,所以我们可以显着减少每个注意力头的参数数量。最后,作者的标签注意力头学习句法类别之间的关系,正如作者通过计算每个注意力头对跨度向量的贡献所展示的那样。作者展示了头部如何帮助分析预测错误并提出纠正方法
文章出处登录后可见!