这门课和另一门课内容都差不多,可以参考七、决策树算法和集成算法该篇博文。
一、决策树相关概念
逻辑回归本质
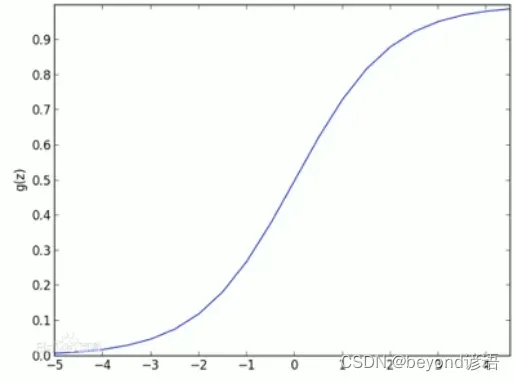
逻辑回归:线性有监督分类模型。常用求解二分类问题,要么是A类别要么是B类别,一般会以0.5作为划分阈值,因为一般逻辑回归的激活函数使用的是sigmoid函数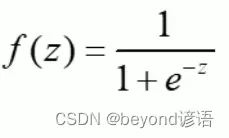
例如:一条数据中有六个特征
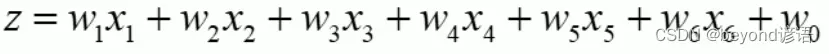
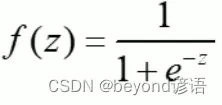
逻辑回归会将0.5作为划分的阈值,例如:
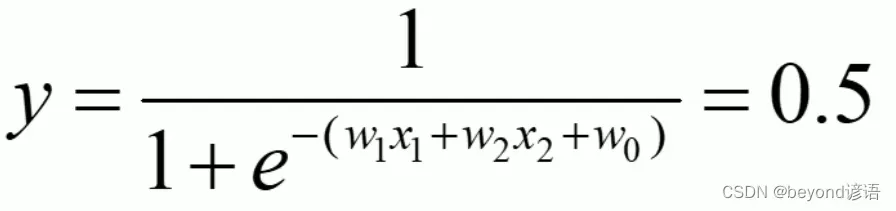
化简可得: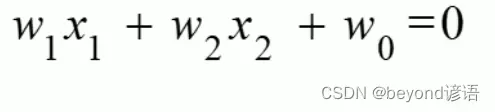
其实这也就找到了一条分界线,这里只考虑两个维度,x1和x2。
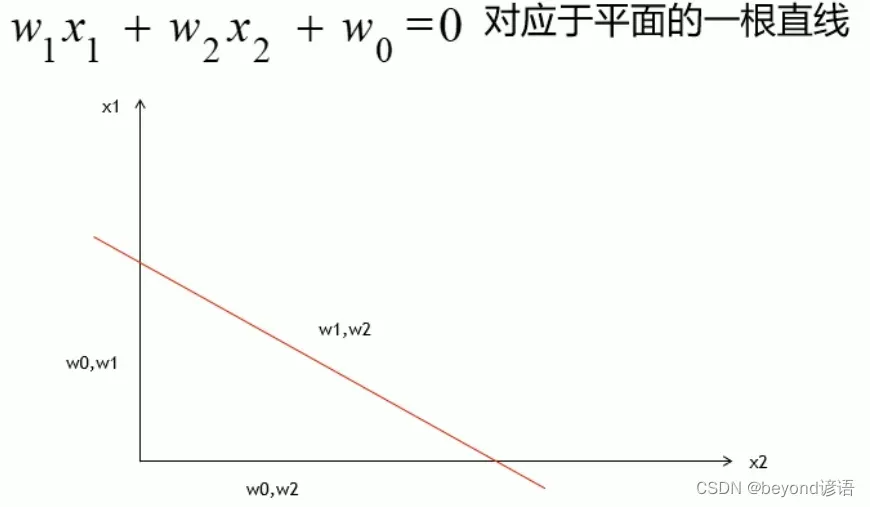
决策树本质
决策树:非线性有监督分类模型。
拟合:多元线性回归
分类:逻辑回归(线性的)
为了使得这些线性的模型去拟合那些非线性的数据,一般使用Polynomial多项式回归,对data数据进行转换,把非线性的数据转换为线性的数据,这样就可以使用线性的模型去拟合线性的数据。
二、决策树案例分析
决策树必须要求数据离散化
例如:数据信息包括性别、天气、是否有风等,就得把男1女0进行分开、晴天0多云1雨天2等分开、有风1无风0分开
Ⅰ,数据如何进行离散化
1,离散数据
动物:猫、狗、猪,如何离散化?把猫标记为0,狗为1,猪为2?俩狗等于猪?是不是多少有点不合适,这时候引入了one-hot编码,通俗一点就是猫001,狗010,猪100,没有谁大谁小区分。
离散数据还需要指明数量2^M种分割方式,M为数据的维度,也就是有几类。
这里有3个维度类别,故有2^3=8种分割方式
2,连续数据
成绩:不及格[0-60)、良好[60-90)、优秀[90-100]
连续数据也需要指明数量M+1种分割方式,M为数据的维度,也就是有几类。
这里有3个维度类别,故有4种分割方式
Ⅱ,为啥要进行离散化
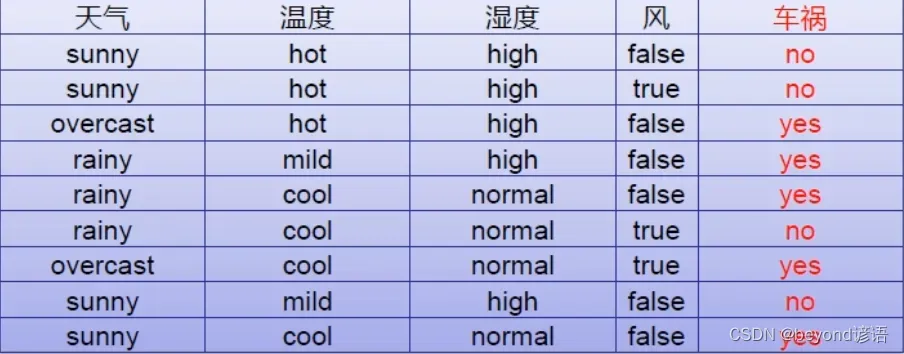
将数据集中的数据进行离散化之后就可以很好的进行构建树了,有数据训练出树(模型),最终预测是否会发生车祸
决策树是通过固定的条件来对类别进行判断
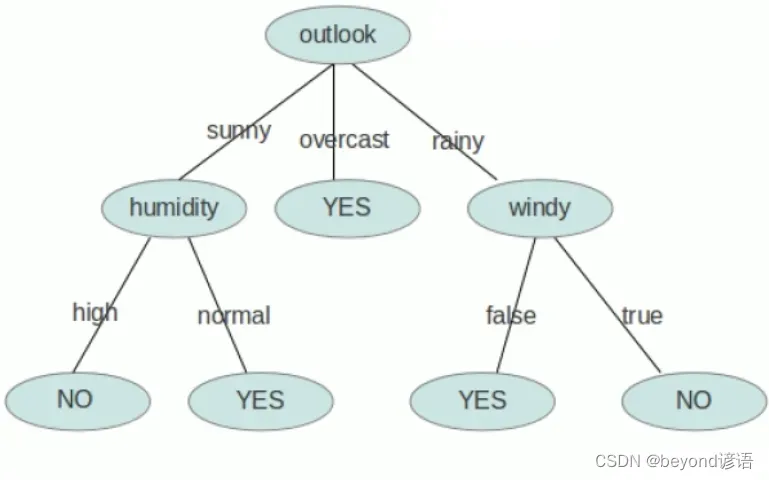
Ⅲ,决策树的生成
数据不断的分类递归的过程,每一次的分裂,尽可能让类别一样的数据放在树的一边,当树的叶子节点的数据都是一类的时候,就停止分类。
Ⅳ,决策树的评判标准
上面样本中,天气、温度、湿度、风,这些因素都会导致车祸的发生,但是在进行决策树分类的时候,分成几类?先从哪进行划分?这就成了一个问题,也就是哪个因素是引起车祸的主要原因这一点需要思考,评判。
决策树会将所有的因素排列组合都进行代入运算,然后将所分割的结果进行标准评分,求出所有的结果然后取最优解
决策树的主旨就是尽可能的将一类分到一边,何为一类?这就需要一个标准,下面为三个主要的标准,也是较为常用的指标

第一个是基尼系数,这个概念来源于经济学,也就是贫富差距,数越大,贫富差距越大,越不是一类。
第二个是熵,熵是衡量数据不确定性
第三个是方差,方差很简单,就是看这些数据是否差不多
前两个常用于分类任务,最后一个常用于回归任务
三、决策树的缺点及解决方法
缺点:①运算量大,需要一次加载所有的数据进入内存,并且寻找分割条件,这是一个极耗资源的过程。
②训练样本中出现异常的数据时,会对决策树产生很大的影响,决策树的抗干扰能力很差。因为需要加载所有的数据,对数据的准确性很是依赖,故导致抗干扰能力很差。
逻辑回归的抗干扰能力很强,其如何抗干扰,也就是线性回归的抗干扰能力如何体现?
答:通过L1和L2正则,利用惩罚性来进行增强模型的泛化能力。L1、L2正则
其实在面对线性不可分的情况下,主要有两种处理办法:
①升维,若在二维平面线性不可分可以通过升维(第三个维度一般为x1*x2),到三维空间之后就可以很容易通过一个平面来将数据进行分割划分
②使用非线性模型来处理,比如决策树、随机森林等
逻辑回归可以得出一个0-1之间的概率值,人为可以设置一个阈值例如0.5,来进行分类;而决策树只能得出一个分类号0或1
解决方法:①减少决策树所需训练的样本数(训练模型本来就需要大量的数据,你这一来数据量少了,模型相对来说并不会太准确)
②随机采样,降低异常数据的干扰(得靠运气,万一随机采样都是干扰点傻脸了)
这时候需要用到随机森林了
四、代码实现
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris#导入鸢尾花数据集
from sklearn.tree import DecisionTreeClassifier#用决策树做分类
from sklearn.tree import export_graphviz
from sklearn.tree import DecisionTreeRegressor#用决策树做回归
from sklearn.model_selection import train_test_split#将数据集进行设置训练集和测试集的比例
from sklearn.metrics import accuracy_score#评估分类的准确率
import matplotlib.pyplot as plt#可视化图像
import matplotlib as mpl
iris = load_iris()#导入鸢尾花数据集
data = pd.DataFrame(iris.data)#将数据集转换为DataFrame格式
data.columns = iris.feature_names#往数据中加载特征名,也就是花萼的长宽、花瓣的长宽等特征
data['Species'] = load_iris().target#对数据集的结果y起个名称
# print(data)
x = data.iloc[:, :2] # 花萼长度和宽度
y = data.iloc[:, -1]
# y = pd.Categorical(data[4]).codes
# print(x)
# print(y)
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.75, random_state=42)#将数据集进行划分
tree_clf = DecisionTreeClassifier(max_depth=8, criterion='entropy')#设置决策树的深度8;使用entropy熵进行评判
tree_clf.fit(x_train, y_train)
y_test_hat = tree_clf.predict(x_test)
print("acc score:", accuracy_score(y_test, y_test_hat))
"""
export_graphviz(
tree_clf,
out_file="./iris_tree.dot",
feature_names=iris.feature_names[:2],
class_names=iris.target_names,
rounded=True,
filled=True
)
# ./dot -Tpng ~/PycharmProjects/mlstudy/bjsxt/iris_tree.dot -o ~/PycharmProjects/mlstudy/bjsxt/iris_tree.png
"""
print(tree_clf.predict_proba([[5, 1.5]]))#指定 花萼长度、宽度 来进行预测
print(tree_clf.predict([[5, 1.5]]))#返回最终的分类号
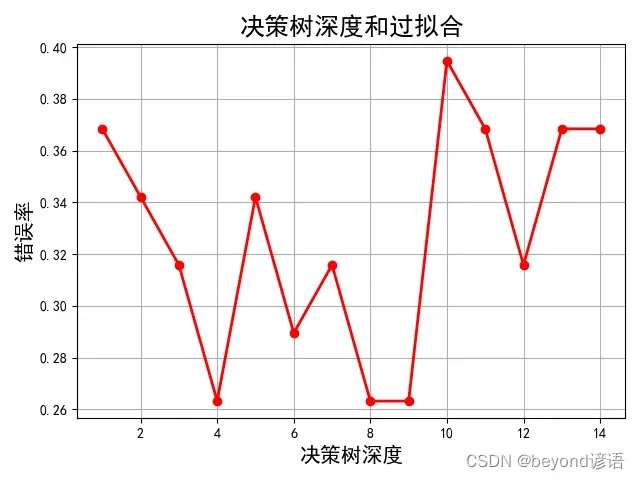
depth = np.arange(1, 15)
err_list = []
for d in depth:
clf = DecisionTreeClassifier(criterion='entropy', max_depth=d)#深度从1-15依次进行遍历
clf.fit(x_train, y_train)
y_test_hat = clf.predict(x_test)
result = (y_test_hat == y_test)
if d == 1:
print(result)
err = 1 - np.mean(result)
print(100 * err)
err_list.append(err)
print(d, 'error rate:%.2f%%' % (100 * err))
mpl.rcParams['font.sans-serif'] = ['SimHei']#设置字体为SimHei
plt.figure(facecolor='w')#图的底色为白色
plt.plot(depth, err_list, 'ro-', lw=2)#横坐标为树的深度,纵坐标为错误率
plt.xlabel('决策树深度', fontsize=15)
plt.ylabel('错误率', fontsize=15)
plt.title('决策树深度和过拟合', fontsize=18)
plt.grid(True)
plt.show()
# tree_reg = DecisionTreeRegressor(max_depth=2)
# tree_reg.fit(X, y)
"""
acc score: 0.7368421052631579
[[0. 1. 0.]]
[1]
73 False
18 False
118 True
78 False
76 False
31 True
64 False
141 True
68 False
82 False
110 True
12 True
36 False
9 True
19 True
56 False
104 True
69 False
55 False
132 True
29 True
127 True
26 True
128 True
131 True
145 True
108 True
143 True
45 True
30 True
22 True
15 False
65 False
11 True
42 True
146 True
51 False
27 True
Name: Species, dtype: bool
36.8421052631579
1 error rate:36.84%
34.210526315789465
2 error rate:34.21%
31.57894736842105
3 error rate:31.58%
26.315789473684216
4 error rate:26.32%
34.210526315789465
5 error rate:34.21%
28.947368421052634
6 error rate:28.95%
31.57894736842105
7 error rate:31.58%
26.315789473684216
8 error rate:26.32%
26.315789473684216
9 error rate:26.32%
39.473684210526315
10 error rate:39.47%
36.8421052631579
11 error rate:36.84%
31.57894736842105
12 error rate:31.58%
36.8421052631579
13 error rate:36.84%
36.8421052631579
14 error rate:36.84%
Process finished with exit code 0
"""
五、随机森林
决策树不行,那就多来点,三个臭皮匠顶个诸葛亮,来个随机森林
森林:多棵决策树
随机:生成树的数据都是从数据加粗样式集中随机进行选取的
并行思路
Ⅰ随机森林相关概念
一个大的决策树的建立需要一个很大的服务器去支撑,但是若分成多个小的决策树呢?每棵树都互不影响,可以并行执行,这就体现了分布式的优势所在了。
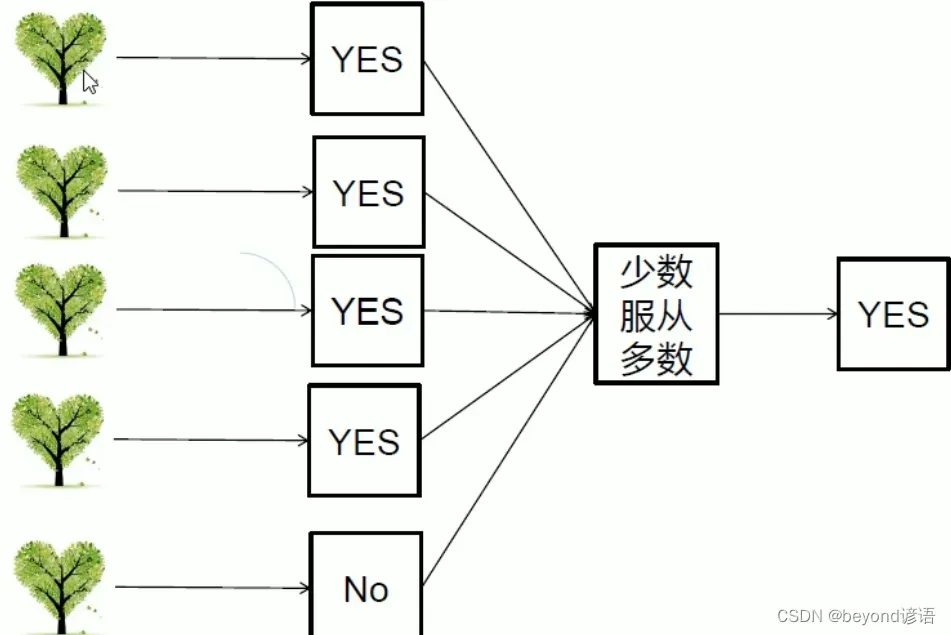
决策树可以看成一个人,森林可以看成多个人,你去问路,2个人给你说路口左转,8个人给你说路口右转,你到路口之后你会左转还是右转?正常人都会右转,你要是头铁非得左转也行。
即使有的树出问题了受到干扰点的影响了,但绝大多数的决策树还正常最终仍然可以得到正确的结果,这就是集体智慧的真实写照
Ⅱ随机森林优点
①当数据集很大的时候,可以随机选取数据集的一部分,生产一棵树,重复这些过程,可以生成多棵互不相同的树,这些树搁一块就形成了森林。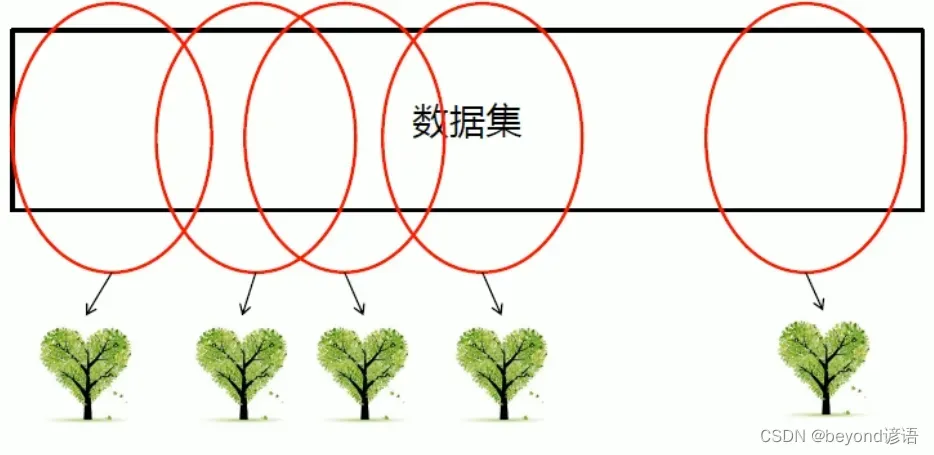
②对每一棵树都进行判断,得到的结果少数服从多数,最终确定出正确的结果
Ⅳ逻辑回归和随机森林对比
| 逻辑回归 | 随机森林 |
|---|---|
| 软分类 | 硬分类 |
| 线性模型 | 非线性模型 |
| 输出为概率值,有实际意义 | 输出为样本号,无实际意义 |
| 抗干扰能力强 | 抗干扰能力弱 |
对于逻辑回归的软分类:之所以是软分类是因为阈值可以改变
比如:①A得癌症了,但是误判没得、②B没得癌症,但是误判得了。
你觉得哪个更难受?应该是①,因为②的话是虚惊一场,而①是蒙蔽双眼
所以有必要为了避免①的误判情况的发生,应该相应的修改阈值。因为可以修改阈值,故分类情况也在随时的发生改变,因此成为软分类
随机森林中的每一棵决策树的数据都是随机来源于数据集中的数据,若需要提高纯度,就需要叶子节点个数很多,才能保证每个类别的纯度特别纯,极端情况下会将每个数据都单独分为一类,每个叶子节点是一类,纯度百分百,但是分的过于细碎也不是好事,会产生过拟合!!!训练集的数据分的很好,每个都是一类,但是未来做预测的时候,拿到新数据的时候就傻脸了。
随机森林出现了多个叶子节点,分类纯度很高,但会出现过拟合,此时就需要就行剪枝来避免过拟合现象。
六、代码实现
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split#随机森林分类器
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris
iris = load_iris()#导入鸢尾花数据集
X = iris.data[:, :2] # 花萼长度和宽度,取其他特征也行
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)#设置训练集和测试集的比例
rnd_clf = RandomForestClassifier(n_estimators=15, max_leaf_nodes=16, n_jobs=1)#随机森林分类器;n_estimators 500棵小决策树构成森林
rnd_clf.fit(X_train, y_train)
#rnd_clf和bag_clf是等价的,用谁都可以,都是在创建随机森林
bag_clf = BaggingClassifier(
DecisionTreeClassifier(splitter="random", max_leaf_nodes=16),
n_estimators=15, max_samples=1.0, bootstrap=True, n_jobs=1
)#Bagging是一个思想,一个并行运算处理的思想
bag_clf.fit(X_train, y_train)
y_pred_rf = rnd_clf.predict(X_test)
y_pred_bag = bag_clf.predict(X_test)
print(accuracy_score(y_test, y_pred_rf))
print(accuracy_score(y_test, y_pred_bag))
# Feature Importance 特征的重要性
iris = load_iris()
rnd_clf = RandomForestClassifier(n_estimators=500, n_jobs=-1)
rnd_clf.fit(iris["data"], iris['target'])
for name, score in zip(iris['feature_names'], rnd_clf.feature_importances_):
print(name, score)
七、提取重要特征的常用方法
①Pearson相关性来找重要的特征
②正则,例如Lasso Regression、Ridge Regression(岭回归)等
③树
八、剪枝
所谓的剪枝就是将随机森林或者决策树的一些分支进行裁剪,防止过拟合现象的出现。
Ⅰ预剪枝
当树还没有长成的时候,也就是模型还没训练好的时候,或者是还没有分裂的时候提前设置一些条件,当分裂到这种情况的时候,就不再分裂了。
树的模型也就这样了,已经规定好了
预剪枝常用,当模型进行构建封装的时候,需要用户提供一些超参数,这些超参数就是用来控制树的规模,从而达到预剪枝的目的和效果
Ⅱ预剪枝方式
①可以设置层次,即控制分裂的层数,例如最多只能分裂两层,到了两层就不会再分了
②可以控制样本数量,即每个节点包含的样本个数。例如设定样本个数为5,有8个样本在上一个节点里,大于规定的样本数量5,需要分裂,假如分成4和4,这两个节点的样本个数小于5,故不会再进行分裂了
Ⅲ后剪枝
随便分裂吧,分裂完之后,或者说模型训练完成之后,再人为的将一些细枝末节的地方进行去掉
这就需要模型算法师来进行优化处理,比如有的节点可以合并,那就进行合并,将俩叶子节点合并成一个
九、Bagging
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
#创建三个独立的分类模型
log_clf = LogisticRegression()
rnd_clf = RandomForestClassifier()
svm_clf = SVC()
#投票分类器,硬分类,少数服从多数
voting_clf = VotingClassifier(
estimators=[('lr', log_clf), ('rf', rnd_clf), ('svc', svm_clf)],
voting='hard'
)
iris = load_iris()
X = iris.data[:, :2] # 花萼长度和宽度
y = iris.target
# X, y = make_moons()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
voting_clf.fit(X, y)
for clf in (log_clf, rnd_clf, svm_clf, voting_clf):
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(clf.__class__.__name__, accuracy_score(y_test, y_pred))
bag_clf = BaggingClassifier(
DecisionTreeClassifier(), n_estimators=500,
max_samples=1.0, bootstrap=True, n_jobs=1
)
bag_clf.fit(X_train, y_train)
y_pred = bag_clf.predict(X_test)
print(y_pred)
y_pred_proba = bag_clf.predict_proba(X_test)
print(y_pred_proba)
print(accuracy_score(y_test, y_pred))
# oob
bag_clf = BaggingClassifier(
DecisionTreeClassifier(), n_estimators=500,
bootstrap=True, n_jobs=1, oob_score=True
)
bag_clf.fit(X_train, y_train)
print(bag_clf.oob_score_)
y_pred = bag_clf.predict(X_test)
print(accuracy_score(y_test, y_pred))
print(bag_clf.oob_decision_function_)
"""
LogisticRegression 0.82
RandomForestClassifier 0.76
SVC 0.78
VotingClassifier 0.8
[1 0 2 1 1 0 1 2 1 1 2 0 1 0 0 2 2 1 1 2 0 1 0 2 2 1 1 2 0 0 0 0 2 0 0 1 2
0 0 0 1 2 2 0 0 1 2 2 2 2]
[[0. 0.8205 0.1795 ]
[0.718 0.213 0.069 ]
[0. 0.224 0.776 ]
[0. 0.58936667 0.41063333]
[0. 0.53300476 0.46699524]
[0.806 0.178 0.016 ]
[0.002 0.92333333 0.07466667]
[0. 0.46225714 0.53774286]
[0. 0.65855238 0.34144762]
[0. 0.50667619 0.49332381]
[0. 0.074 0.926 ]
[0.956 0.012 0.032 ]
[0.438 0.484 0.078 ]
[0.994 0.002 0.004 ]
[1. 0. 0. ]
[0.002 0.01 0.988 ]
[0. 0.114 0.886 ]
[0. 0.654 0.346 ]
[0. 0.77733333 0.22266667]
[0. 0.404 0.596 ]
[1. 0. 0. ]
[0. 0.76036667 0.23963333]
[1. 0. 0. ]
[0. 0.404 0.596 ]
[0.04 0.02933333 0.93066667]
[0. 0.6612 0.3388 ]
[0. 0.8012 0.1988 ]
[0. 0.11613333 0.88386667]
[0.956 0.012 0.032 ]
[0.994 0.002 0.004 ]
[1. 0. 0. ]
[0.756 0.195 0.049 ]
[0. 0.22566667 0.77433333]
[1. 0. 0. ]
[1. 0. 0. ]
[0. 0.8 0.2 ]
[0. 0.072 0.928 ]
[0.982 0.01 0.008 ]
[1. 0. 0. ]
[0.998 0.002 0. ]
[0. 0.50667619 0.49332381]
[0.12 0.2925 0.5875 ]
[0. 0.22566667 0.77433333]
[0.982 0.018 0. ]
[0.974 0.02 0.006 ]
[0. 0.976 0.024 ]
[0. 0.15 0.85 ]
[0. 0.10003333 0.89996667]
[0. 0.31 0.69 ]
[0.008 0.03533333 0.95666667]]
0.76
0.64
0.76
[[0. 0.96039604 0.03960396]
[0. 0.00512821 0.99487179]
[0.02083333 0.82621528 0.15295139]
[1. 0. 0. ]
[0. 0.06748466 0.93251534]
[0. 0.23735955 0.76264045]
[0.92063492 0.07407407 0.00529101]
[1. 0. 0. ]
[1. 0. 0. ]
[0.07853403 0.84816754 0.07329843]
[0. 0.27387387 0.72612613]
[1. 0. 0. ]
[0.7797619 0.19642857 0.02380952]
[0.99386503 0.00613497 0. ]
[0. 0.51217617 0.48782383]
[1. 0. 0. ]
[0.01005025 0.91139028 0.07855946]
[0.12365591 0.05734767 0.81899642]
[1. 0. 0. ]
[0. 0.34530387 0.65469613]
[0. 0.98972973 0.01027027]
[0.51912568 0.38251366 0.09836066]
[0. 0.62020202 0.37979798]
[0. 0.84375 0.15625 ]
[0. 0.19949495 0.80050505]
[0.87878788 0.12121212 0. ]
[0.01657459 0.3038674 0.67955801]
[0.01197605 0.9251497 0.06287425]
[0.92432432 0.07567568 0. ]
[0.11627907 0.79651163 0.0872093 ]
[0. 0.46180556 0.53819444]
[0.99468085 0.00531915 0. ]
[0.9673913 0.0326087 0. ]
[0. 0.94252874 0.05747126]
[0. 0.04972376 0.95027624]
[0.98979592 0. 0.01020408]
[0. 0.64481715 0.35518285]
[1. 0. 0. ]
[1. 0. 0. ]
[0.07692308 0.33717949 0.58589744]
[0.03592814 0.7005988 0.26347305]
[0. 0.5469428 0.4530572 ]
[0. 0.39035088 0.60964912]
[0. 0.94313725 0.05686275]
[0. 0.00625 0.99375 ]
[0. 0.87640449 0.12359551]
[0.99404762 0.00595238 0. ]
[0.99470899 0.00529101 0. ]
[0. 0.86612022 0.13387978]
[0. 0.15008726 0.84991274]
[1. 0. 0. ]
[1. 0. 0. ]
[0.99375 0.00625 0. ]
[0. 0.46486486 0.53513514]
[0.00606061 0.02424242 0.96969697]
[1. 0. 0. ]
[0. 0.68693694 0.31306306]
[0.00515464 0.06701031 0.92783505]
[1. 0. 0. ]
[0. 0.88557214 0.11442786]
[0. 0.16315789 0.83684211]
[0. 0.76439791 0.23560209]
[0. 0.08242972 0.91757028]
[0. 0.22894737 0.77105263]
[1. 0. 0. ]
[0. 0.65789474 0.34210526]
[0.00549451 0.2032967 0.79120879]
[0. 0.30319149 0.69680851]
[0. 0.5923913 0.4076087 ]
[0.07368421 0.77368421 0.15263158]
[0. 0.38802682 0.61197318]
[0.07185629 0.71257485 0.21556886]
[0. 0.57954545 0.42045455]
[0. 0.97826087 0.02173913]
[0.96039604 0.02970297 0.00990099]
[0.02298851 0.80823755 0.16877395]
[0. 0.1878453 0.8121547 ]
[0.00564972 0.05649718 0.93785311]
[1. 0. 0. ]
[0.04060914 0.30964467 0.64974619]
[0.00540541 0.05405405 0.94054054]
[0. 0.02260638 0.97739362]
[1. 0. 0. ]
[0. 0.60706349 0.39293651]
[0.88268156 0.04469274 0.0726257 ]
[0. 0.02857143 0.97142857]
[0. 0.05472637 0.94527363]
[0. 0.82285714 0.17714286]
[0. 0.37244898 0.62755102]
[0. 0.285 0.715 ]
[0. 0.56686391 0.43313609]
[0. 0.1761658 0.8238342 ]
[0. 0.96756757 0.03243243]
[0.00558659 0.89385475 0.10055866]
[0.50520833 0.45833333 0.03645833]
[0. 0.36190476 0.63809524]
[0.04651163 0.95348837 0. ]
[0.26203209 0.34848485 0.38948307]
[0. 0.42791136 0.57208864]
[0. 0.53856383 0.46143617]]
Process finished with exit code 0
"""
十、决策树回归
决策树做分类就是将一个大的数据集分到多个小的叶子节点中去,例如,第一个特征在某个集合里面走左边,反之走右边。最后得到的数据的预测值是多少取决于最终叶子节点中的数值的平均值。
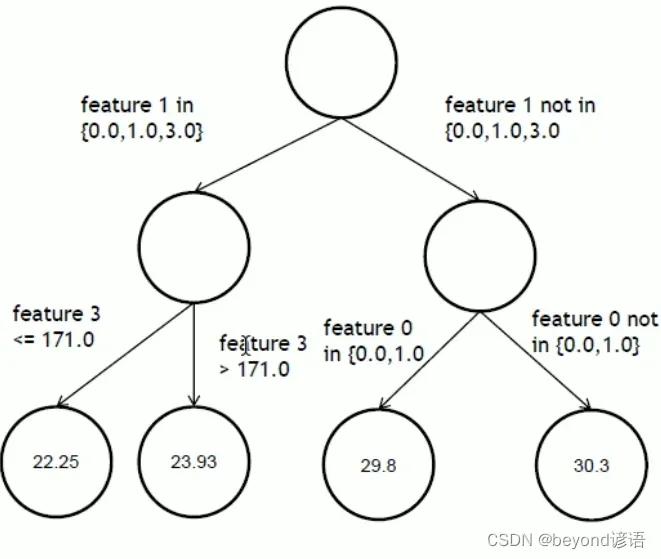
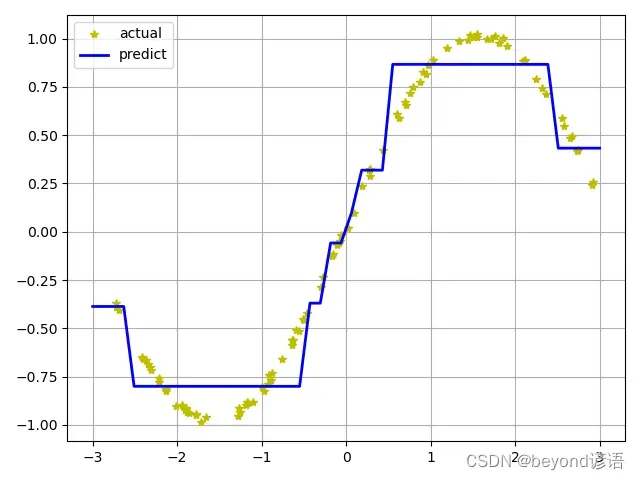
import numpy as np
from sklearn.tree import DecisionTreeRegressor
import matplotlib.pyplot as plt
N = 100
x = np.random.rand(N) * 6 - 3
x.sort()
y = np.sin(x) + np.random.rand(N) * 0.05#非线性变换 数据
print(y)
x = x.reshape(-1, 1)
print(x)
dt_reg = DecisionTreeRegressor(criterion='mse', max_depth=3)
dt_reg.fit(x, y)
x_test = np.linspace(-3, 3, 50).reshape(-1, 1)
y_hat = dt_reg.predict(x_test)
plt.plot(x, y, "y*", label="actual")
plt.plot(x_test, y_hat, "b-", linewidth=2, label="predict")
plt.legend(loc="upper left")
plt.grid()
plt.show()
# plt.savefig("./temp_decision_tree_regressor")
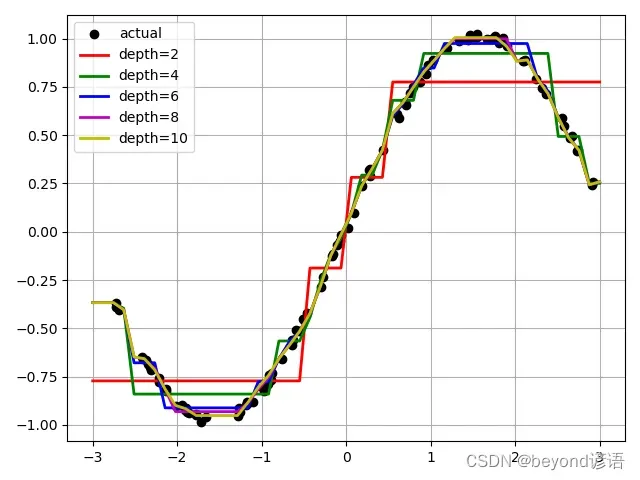
# 比较不同深度的决策树
depth = [2, 4, 6, 8, 10]
color = 'rgbmy'
dt_reg = DecisionTreeRegressor()
plt.plot(x, y, "ko", label="actual")
x_test = np.linspace(-3, 3, 50).reshape(-1, 1)
for d, c in zip(depth, color):
dt_reg.set_params(max_depth=d)
dt_reg.fit(x, y)
y_hat = dt_reg.predict(x_test)
plt.plot(x_test, y_hat, '-', color=c, linewidth=2, label="depth=%d" % d)
plt.legend(loc="upper left")
plt.grid(b=True)
plt.show()
# plt.savefig("./temp_compare_decision_tree_depth")
"""
[-0.36688907 -0.38930987 -0.40414606 -0.64806473 -0.65700912 -0.66248474
-0.6856528 -0.70139657 -0.71546988 -0.75949983 -0.77920805 -0.81452329
-0.8222279 -0.90006776 -0.89734011 -0.92172404 -0.91383193 -0.91458672
-0.91591471 -0.9307151 -0.93799345 -0.94902737 -0.94300522 -0.98441068
-0.95912561 -0.95615789 -0.9101952 -0.93302889 -0.89679762 -0.88337589
-0.88442261 -0.87954674 -0.80543953 -0.82610002 -0.78694966 -0.74295972
-0.76677754 -0.72940886 -0.65740021 -0.58807926 -0.55983806 -0.56213145
-0.50970546 -0.51535249 -0.45167804 -0.45721702 -0.42209345 -0.28375276
-0.23336102 -0.12528549 -0.11341364 -0.06689013 -0.05751791 -0.04824017
-0.01469778 0.02023206 0.09562457 0.23818302 0.32036025 0.2884832
0.32562788 0.42195215 0.61216689 0.58675132 0.66988573 0.65406328
0.71793552 0.74871883 0.77367746 0.82723622 0.81557531 0.86233753
0.88691045 0.94898301 0.98565776 0.99451228 1.01955382 1.00802102
1.00705746 1.02191846 0.99818839 1.0003569 1.01273956 0.97649639
1.00220468 0.9603402 0.88287074 0.88583015 0.88975818 0.79213884
0.7423791 0.71526646 0.59134944 0.5462042 0.48648846 0.49462238
0.42007109 0.4222635 0.24311189 0.25878365]
[[-2.72466555]
[-2.72226087]
[-2.68403246]
[-2.41254902]
[-2.39949207]
[-2.37147302]
[-2.34611684]
[-2.32081955]
[-2.31562513]
[-2.21292638]
[-2.21050926]
[-2.136452 ]
[-2.13037238]
[-2.01353511]
[-1.94177567]
[-1.91198378]
[-1.90590259]
[-1.8960628 ]
[-1.89140935]
[-1.87843641]
[-1.8589764 ]
[-1.78054242]
[-1.7792699 ]
[-1.72188473]
[-1.66002114]
[-1.28581879]
[-1.26540192]
[-1.2538425 ]
[-1.17999472]
[-1.17149249]
[-1.16311153]
[-1.1084779 ]
[-0.99671069]
[-0.97261305]
[-0.9253839 ]
[-0.91136908]
[-0.8857756 ]
[-0.8737135 ]
[-0.75420415]
[-0.64099704]
[-0.63742495]
[-0.63205098]
[-0.59173631]
[-0.56030877]
[-0.5152529 ]
[-0.50230676]
[-0.46816639]
[-0.29276163]
[-0.27334957]
[-0.1654072 ]
[-0.15476441]
[-0.10714786]
[-0.08879741]
[-0.07772982]
[-0.06149313]
[ 0.02008246]
[ 0.09340283]
[ 0.19048042]
[ 0.2754616 ]
[ 0.27809472]
[ 0.28520137]
[ 0.43450279]
[ 0.60262783]
[ 0.62416658]
[ 0.69830847]
[ 0.70433814]
[ 0.75158421]
[ 0.79467865]
[ 0.87619365]
[ 0.90570908]
[ 0.93894204]
[ 0.97296551]
[ 1.02672438]
[ 1.18810392]
[ 1.33863358]
[ 1.44490161]
[ 1.46442844]
[ 1.51606029]
[ 1.54505571]
[ 1.54514861]
[ 1.67111482]
[ 1.71420404]
[ 1.75846431]
[ 1.80892824]
[ 1.85273944]
[ 1.89965423]
[ 2.09460961]
[ 2.10921317]
[ 2.12111166]
[ 2.25236567]
[ 2.31865023]
[ 2.36767786]
[ 2.55649574]
[ 2.58114792]
[ 2.65451688]
[ 2.67623079]
[ 2.72668498]
[ 2.73827709]
[ 2.90997157]
[ 2.91823426]]
"""
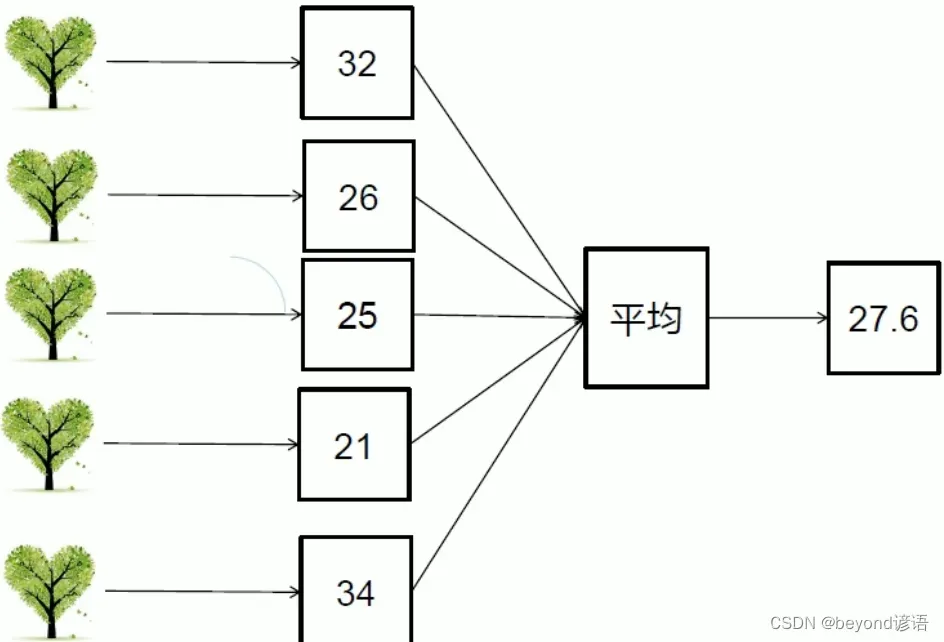
十一、随机森林回归
文章出处登录后可见!