一、决策树的原理
决策树思想的来源非常朴素,程序设计中的条件分支结构就是if-then结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法 。
二、决策树的现实案例
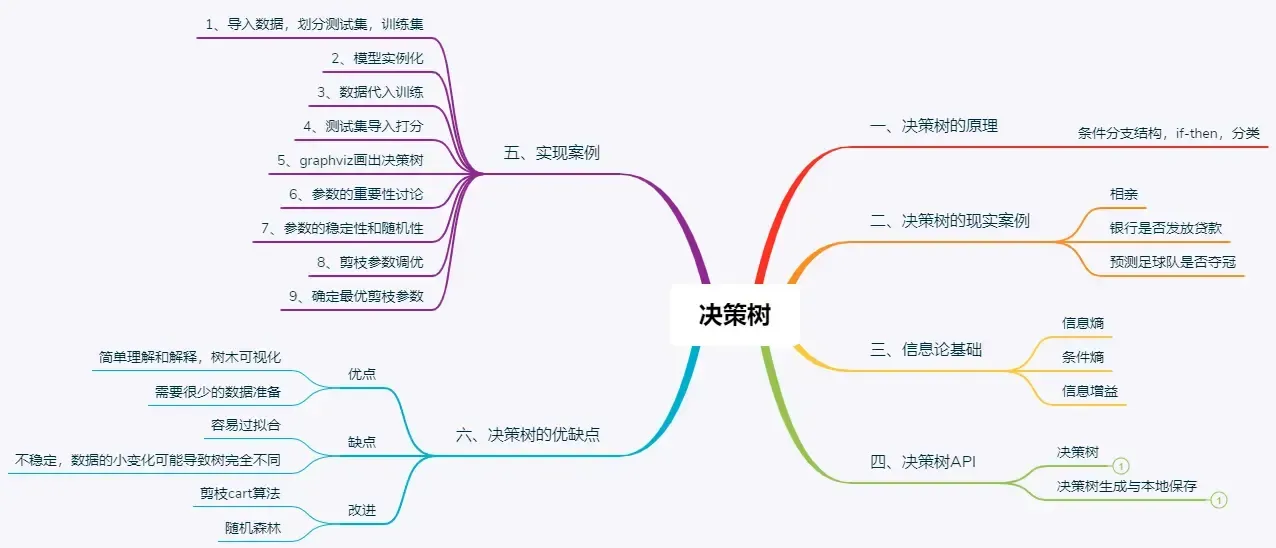
相亲
女儿:多大年纪了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
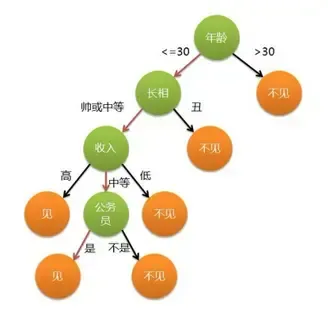
银行是否发放贷款
行长:是否有自己的房子?
职员:有。
行长:可以考虑放贷。
职员:如果没有自己的房子呢?
行长:是否有稳定工作?
职员:有。
行长:可以考虑放贷。
职员:那如果没有呢?
行长:既没有自己的房子,也没有稳定工作,那咱还放啥贷款?
职员:懂了。
预测足球队是否夺冠

三、信息论基础
信息熵:
假如我们竞猜32只足球队谁是冠军?我可以把球编上号,从1到32,然后提问:冠 军在1-16号吗?依次进行二分法询问,只需要五次,就可以知道结果。
32支球队,问询了5次,信息量定义为5比特,log32=5比特。比特就是表示信息的单位。
假如有64支球队的话,那么我们需要二分法问询6次,信息量就是6比特,log64=6比特。
问询了多少次,专业术语称之为信息熵,单位为比特。
公式为:
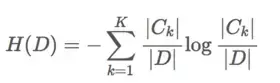
信息熵的作用:
决策树生成的过程中,信息熵大的作为根节点,信息熵小的作为叶子节点,按照信息熵的从大到小原则,生成决策树。
条件熵:
条件熵H(D|A)表示在已知随机变量A的条件下随机变量D的不确定性。
公式为:
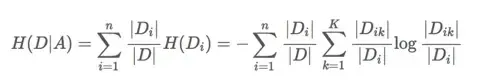
通俗来讲就是,知道A情况下,D的信息量。
信息增益:
特征A对训练数据集D的信息增益g(D,A),定义为集合D的信息熵H(D)与特征A给定条件下D的信息条件熵H(D|A)之差。
公式为:
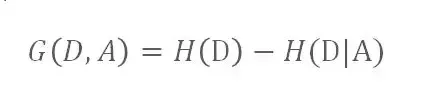
怎么理解信息增益呢?信息增益表示得知特征X的信息而使得类Y的信息的不确定性减少的程度。简单讲,就是知道的增多,使得不知道的(不确定的)就减少。
四、 决策树API
决策树:
sklearn.tree.DecisionTreeClassifier
class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, max_depth=None,random_state=None)
决策树分类器
criterion:默认是’gini’系数,也可以选择信息增益的熵’entropy’
max_depth:树的深度大小
random_state:随机数种子
method:
dec.fit(X,y): 根据数据集(X,y)建立决策树分类器
dec.apply(X): 返回每个样本被预测为的叶子的索引。
dec.cost_complexity_pruning_path(X,y): 在最小成本复杂性修剪期间计算修剪路径。
dec.decision_path(X): 返回树中的决策路径
dec.get_depth(): 返回树的深度
dec.get_n_leaves(): 返回决策树的叶子节点
dec.get_params(): 返回评估器的参数
dec.predict(X): 预测X的类或回归值
dec.predict_log_proba(X): 预测X的类的log值
dec.predict_proba(X): 预测X分类的概率值
dec.score(X,y): 测试数据X和标签值y之间的平均准确率
dec.set_params(min_samples_split=3): 设置评估器的参数
X 表示训练集,y表示特征值
决策树的生成与本地保存:
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
li = load_iris()
dec = DecisionTreeClassifier()
# 根据训练集(X,y)建立决策树分类器
dec.fit(li.data,li.target)
# 预测X的类或回归值
dec.predict(li.data)
# 测试数据X和标签值y之间的平均准确率
dec.score(li.data,li.target)
# 保存树文件 tree.dot
tree.export_graphviz(dec,out_file='tree.dot')
tree.dot 保存结果:
digraph Tree {
node [shape=box] ;
0 [label="X[2] <= 2.45\ngini = 0.667\nsamples = 150\nvalue = [50, 50, 50]"] ;
1 [label="gini = 0.0\nsamples = 50\nvalue = [50, 0, 0]"] ;
.....
五、实现案例
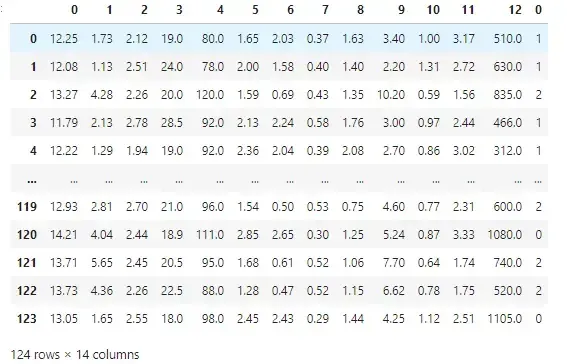
1、导入数据,划分测试集,训练集
from sklearn import tree
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
import graphviz
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
import pylab as mpl #导入中文字体,避免显示乱码
mpl.rcParams['font.sans-serif']=['SimHei'] #设置为黑体字
data = load_wine()
dataFrame = pd.concat([pd.DataFrame(X_train),pd.DataFrame(y_train)],axis=1)
print(dataFrame)
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.3, random_state=30)
2、模型实例化
clf = tree.DecisionTreeClassifier(criterion='gini'
,max_depth=None
,min_samples_leaf=1
,min_samples_split=2
,random_state=0
,splitter='best'
)
3、数据代入训练
clf = clf.fit(X_train,y_train)
4、测试集导入打分
score = clf.score(X_test,y_test)
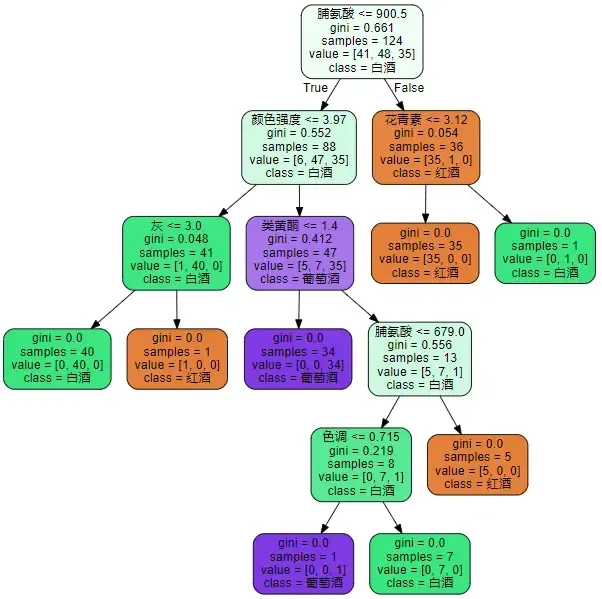
5、graphviz画出决策树
feature_name = ['酒精','苹果酸','灰','灰的碱性','镁','总酚','类黄酮','非黄烷类酚类','花青素','颜色强度','色调','od280/od315稀释葡萄酒','脯氨酸']
dot_data = tree.export_graphviz(clf
,out_file=None
,feature_names=feature_name
,class_names=["红酒","白酒","葡萄酒"] #别名
,filled=True
,rounded=True
)
graph = graphviz.Source(dot_data)
6、参数的重要性讨论
clf.feature_importances_
[*zip(feature_name,clf.feature_importances_)]
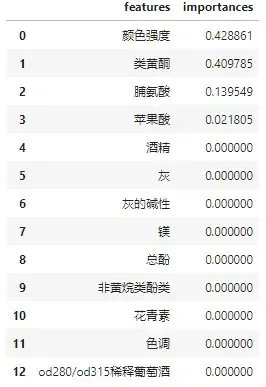
[(‘酒精’, 0.0),
(‘苹果酸’, 0.0),
(‘灰’, 0.023800041266200594),
(‘灰的碱性’, 0.0),
(‘镁’, 0.0),
(‘总酚’, 0.0),
(‘类黄酮’, 0.14796731056604398),
(‘非黄烷类酚类’, 0.0),
(‘花青素’, 0.023717402234026283),
(‘颜色强度’, 0.3324466124446747),
(‘色调’, 0.021345662010623646),
(‘od280/od315稀释葡萄酒’, 0.0),
(‘脯氨酸’, 0.45072297147843077)]
将重要性排序:
df = pd.DataFrame([*zip(features, clf.feature_importances_)])
df.columns = ['features','importances']
df = df.sort_values(by='importances',ascending=False)
df.index = range(df.shape[0])
df
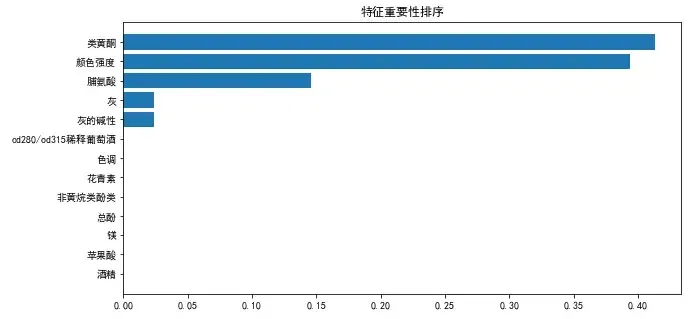
将重要性可视化:
plt.figure(figsize=(10,5))
plt.barh(df['features'],df['importances'])
plt.title('特征重要性排序')
plt.show()
7、参数的稳定性和随机性
问题:为什么大家对同一份数据进行执行,结果分数会不一样呢?同一个人执行同一份数据,每次的分数结果也会不一样?
答:是因为训练数据集在模型里每次都是随机划分的,所以执行的结果会不稳定,那么要怎么才会稳定呢?参数random_state就是用来干这个事情的,只要给random_state设置了值,那么每次执行的结果就都会是一样的了。具体设置多少呢?是不一定的,从0到n可以自己尝试,哪个值得到的score高就用哪个。
clf = tree.DecisionTreeClassifier(criterion="entropy",random_state=30)
clf = clf.fit(X_train, y_train)
score = clf.score(X_test, y_test) #返回预测的准确度
8、剪枝参数调优
为什么要剪枝?
剪枝参数的默认值会让树无限增长,这些树在某些数据集中可能非常巨大,非常消耗内存。其次,决策树的无限增长会造成过拟合线性,导致模型在训练集中表现很好,但是在测试集中表现一般。之所以在训练集中表现很好,是包括了训练集中的噪音在里面,造成了过拟合现象。所以,我们要对决策树进行剪枝参数调优。
常用的参数主要有:
min_samples_leaf: 叶子的最小样本量,如果少于设定的值,则停止分枝;太小引起过拟合,太大阻止模型学习数据;建议从5开始;
min_samples_split: 分枝节点的样本量,如果少于设定的值,那么就停止分枝。
max_depth:树的深度,超过深度的树枝会被剪掉,建议从3开始,看效果决定是否要增加深度;如果3的准确率只有50%,那增加深度,如果3的准确率80%,90%,那考虑限定深度,不用再增加深度了,节省计算空间。
clf = tree.DecisionTreeClassifier(min_samples_leaf=10
, min_samples_split=20
, max_depth=3)
clf.fit(X_train, y_train)
dot_data = tree.export_graphviz(clf
,feature_names=feature_name
,class_names=["红酒","白酒","葡萄酒"] #别名
,filled=True
,rounded=True)
graphviz.Source(dot_data)
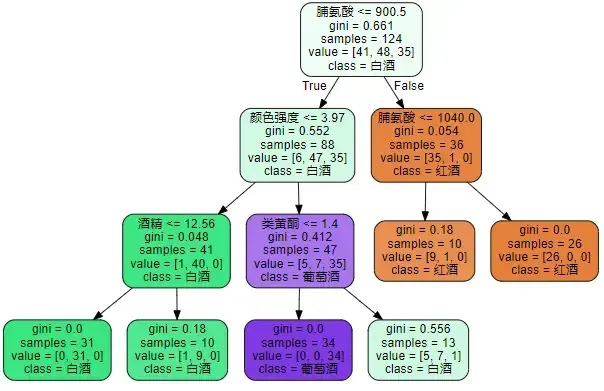
9、确定最优剪枝参数
import matplotlib.pyplot as plt
score_list = []
for i in range(1,11):
clf = tree.DecisionTreeClassifier(max_depth=i
,criterion="entropy"
,random_state=30
,splitter="random")
clf.fit(Xtrain, Ytrain)
score = clf.score(Xtest, Ytest)
score_list.append(score)
plt.plot(range(1,11),score_list,color="red",label="max_depth",linewidth=2)
plt.legend()
plt.show()
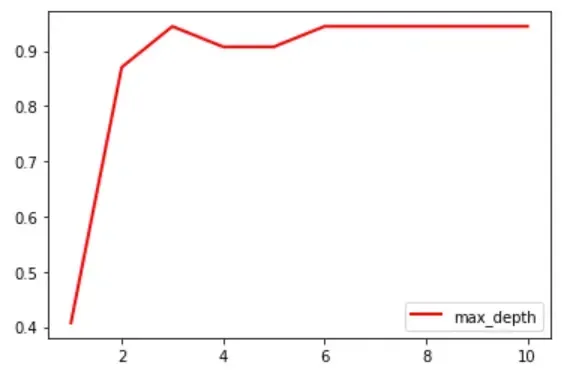
可以看到,max_depth在=3的时候,score已经达到了最高,再增加深度,则会增加过拟合的风险。
六、 决策树的优缺点
优点
- 简单的理解和解释,树木可视化。
- 需要很少的数据准备,其他技术通常需要数据归一化。
缺点
- 决策树学习者可以创建不能很好地推广数据的过于复杂的树,被称为过拟合。
- 决策树可能不稳定,因为数据的小变化可能会导致完全不同的树
被生成。
改进
- 减枝cart算法
- 随机森林
文章出处登录后可见!