跟踪数据如何帮助我持续锻炼了 2 年
自由复制 R 代码,开始跟踪并通过个人项目扩展您的数据科学组合,同时变得更健康。
用詹姆斯·克利尔的话说,你所采取的日常行动为你的身份提供了证据。多亏了跟踪,我几乎改变了我的身份。定期锻炼现在是我生活中不可或缺的一部分。
本文适用于所有希望开始一个新的个人数据科学项目来跟踪他们的锻炼的人。所有代码都可以在 Github 上免费获得,您可以复制和改编。[0]
如果您是一位经验丰富的程序员,即使您有不同的设备(您需要进行适当的调整),您也可以轻松地跟随。如果您是初学者,几乎没有或没有编程经验,您仍然可以使用 Fitbit 数据实现您看到的所有内容。
这是我从 2020 年 4 月 1 日到 2022 年 5 月 31 日的 2 年旅程的总结。开始日期是大流行的开始。这恰逢我们迎来一个女婴来到这个世界的时候。由于国内的所有不确定性和重大变化,我担心这会在个人和专业方面造成重大损失。两年过去了,感谢数据科学和跟踪,我对进步感到满意!
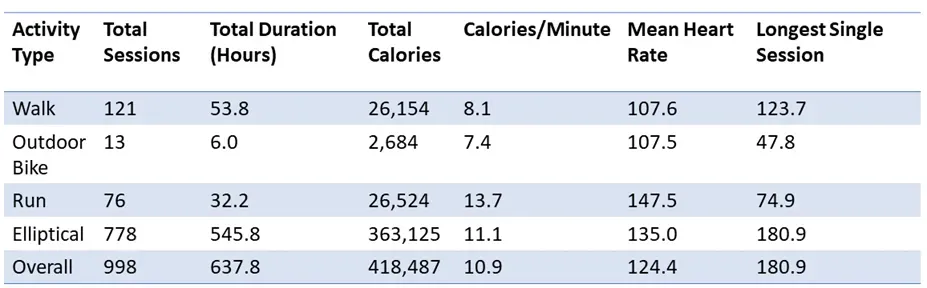
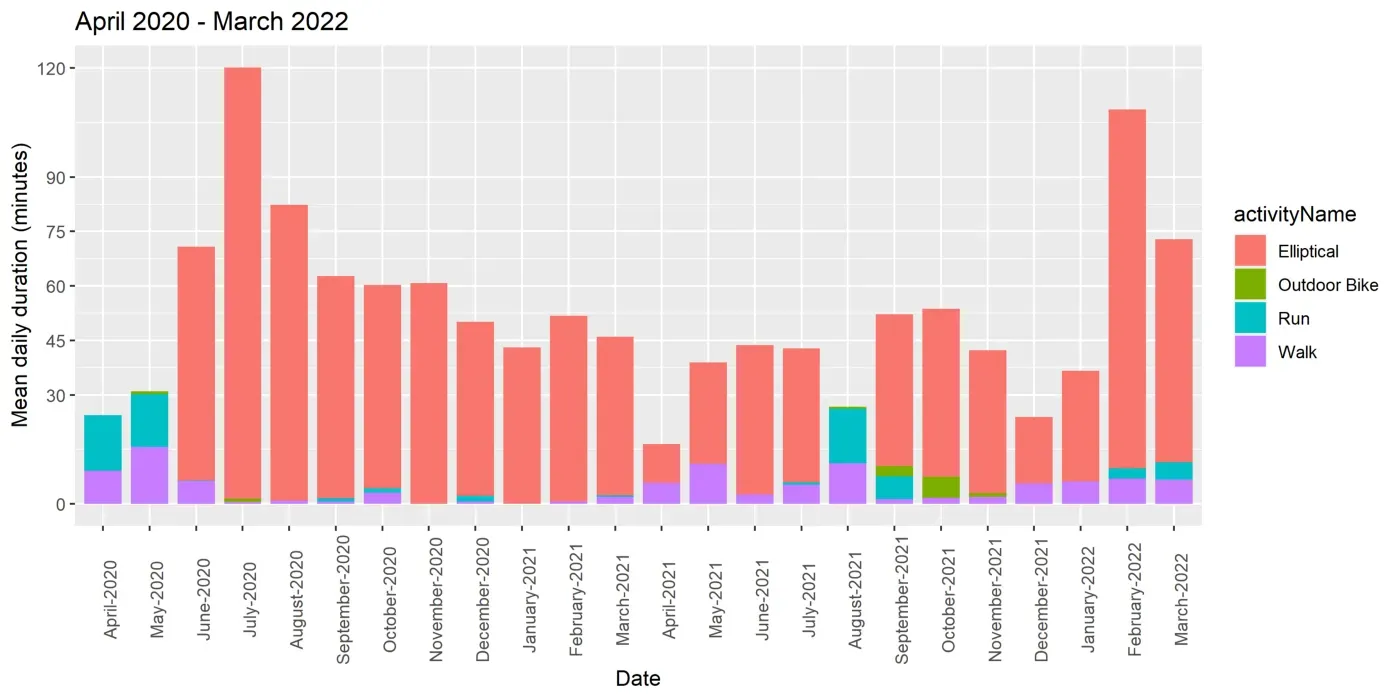
我总共进行了 998 节课,相当于锻炼了 638 小时。我的大部分运动都是由椭圆训练组成的。总的来说,这相当于在两年内每天坚持锻炼 48 分钟。
该数据还证实(在活动类型中)跑步是燃烧卡路里最省时的方法(每分钟燃烧 13.7 卡路里)。但是,总体而言,交叉训练器的效果要好得多,因为您更有可能进行更多次和更长的训练。
Fitbit 分析深潜演练
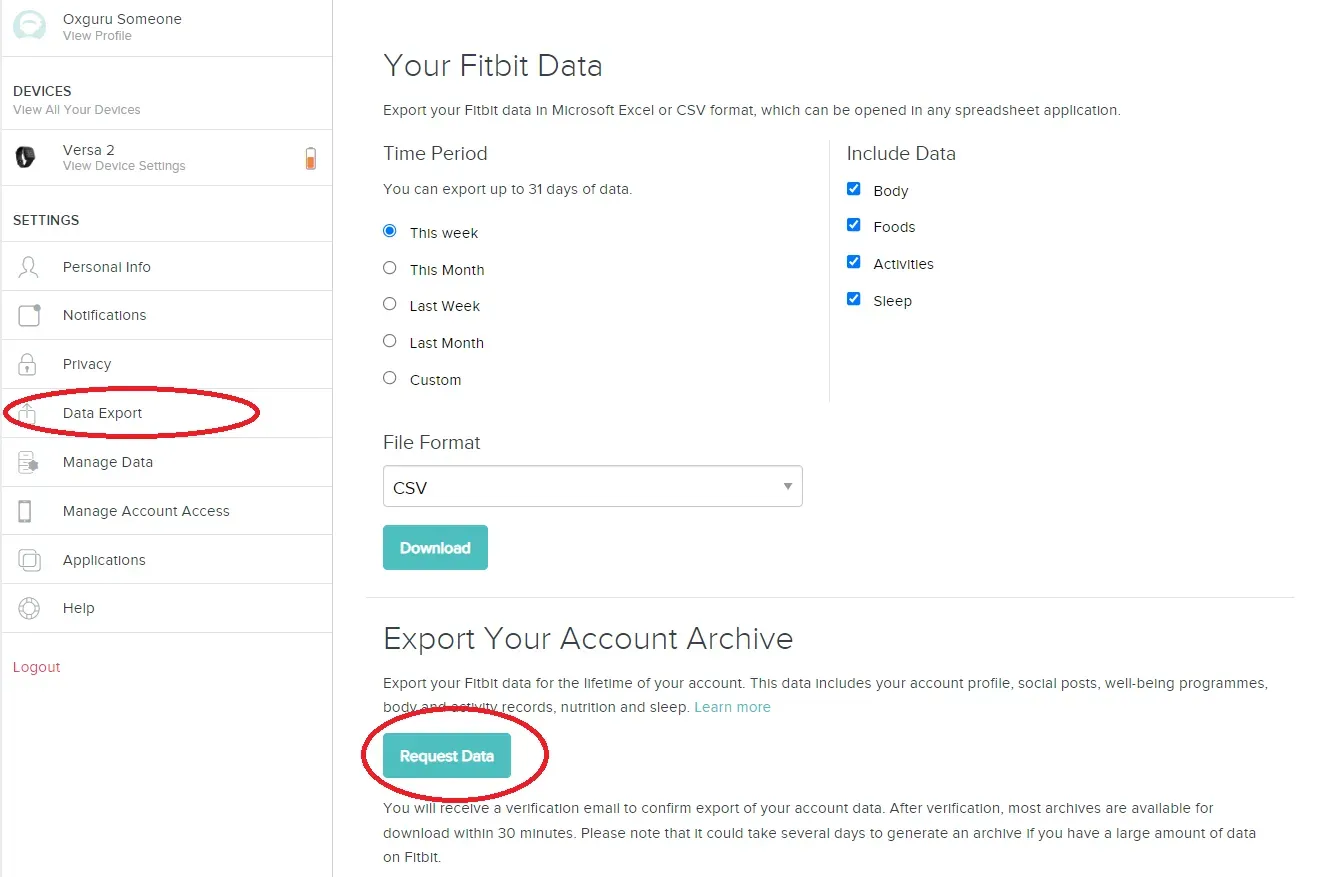
如果您已经拥有一台 Fitbit 设备,那么您需要做的第一件事就是下载所有 Fitbit 数据。每个国家/地区都有自己的司法管辖区,但通常,根据法律,您有权访问您的数据并且可以请求完全访问。以下是您登录 Fitbit 帐户并请求下载所有数据的方法。
首先,访问 https://accounts.fitbit.com/login 并使用您的帐户详细信息登录。单击右上角的设置齿轮图标(如下所示)。[0]

进入“设置”后,单击“数据导出”并选择“请求数据”,然后将下载 Fitbit 保存的所有数据(如下所示)。
按照指示,它将触发来自 Fitbit 的自动电子邮件(下面的屏幕截图)。
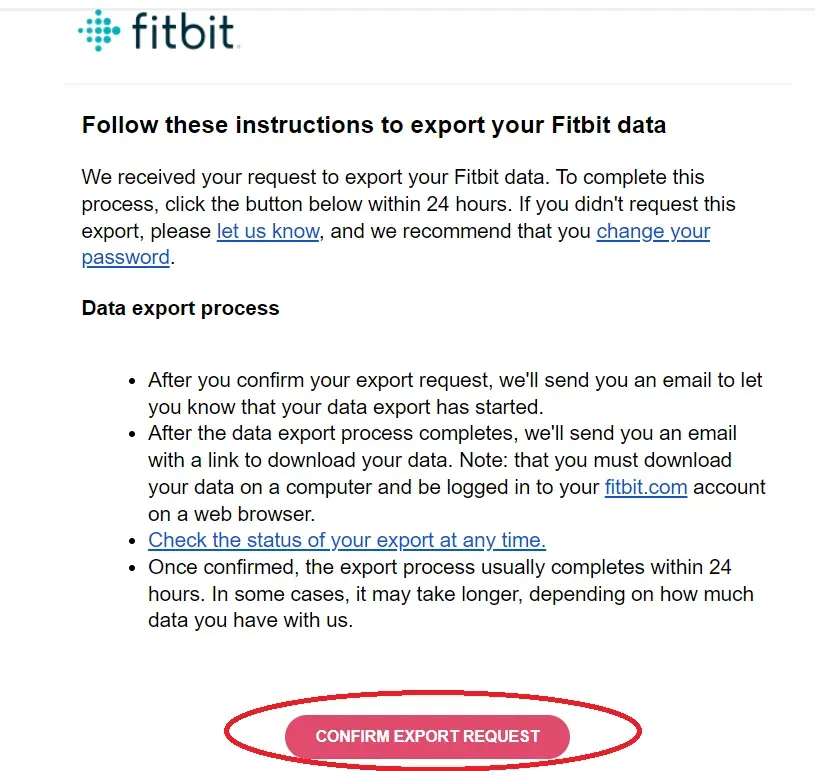
一旦您确认您确实发起了请求,数据生成过程将开始。
Fitbit的数据结构
从 Fitbit 下载的数据将以单个 zip 文件的形式提供。解压缩后,它将有 12 个不同的文件夹。您可以在每个文件夹中找到的相关自述文件中找到有关每个文件夹内容的更多信息。根据设备的使用情况,许多文件夹可能只是空的(这很好!)。
出于本文的目的,我们将重点关注名为“体育活动”文件夹中的选定文件。该文件夹包含几乎所有与身体活动有关的数据,包括以下数据:
-Active Zone Minutes(每个月一个文件,CSV 格式)
– 锻炼类型和持续时间(每 100 个会话一个文件,JSON 格式)
– 心率(JSON 格式每天一个文件)
-VO2 Max 数据(以 JSON 格式存储)
– 不同心率区的持续时间(JSON 格式,每天一个文件)
如您所见,大多数数据都以 JSON 格式存储。
JSON Lite 库和 JSON 数据格式
JavaScript Object Notation(简称 JSON)是一种用于存储结构化数据的开放标准文件格式。该格式是人类可读的,由属性值对和数组组成。 JSON 文件格式以扩展名“.json”存储。现在的设备以 JSON 格式存储数据是很常见的。这种格式与语言无关,您使用的大多数软件可能包含现有代码库以生成和读取(解析)JSON 文件。
以下是您可以在体育活动文件夹中找到的 JSON 文件 (run_vo2_max-date) 的示例。

在分析 Fitbit 数据之前,我们需要将其读入 R。我们将使用 R 免费提供的“jsonlite”库。如果您以前没有使用过该库,请先从 RStudio 中安装它。安装后,加载库。
我们将使用的其他三个库是 lubridate、dplyr 和 ggplot2。 dplyr 和 ggplot2 是 tidyverse 生态系统的一部分,一旦您加载“tidyverse”,它们就会自动加载。
rm(list=ls())
library(jsonlite)
library(tidyverse)
library(lubridate)dplyr 用于数据整理,ggplot2 用于数据可视化,而 lubridate 是用于操作日期的便捷库。您很快就会看到帮助跟踪锻炼数据的实际示例!
导入数据并存储在 DataFrame 中
现在让我们来看看实际的代码。您可以从 GitHub 下载所有这些代码。[0]
我们将查看位于“体育活动”文件夹中的练习文件。 Fitbit 会在每个锻炼文件中自动存储 100 个会话。您可以直观地查看文件名以识别您拥有的总练习文件。就我而言,我总共有 1400 多个会话。
folder_path <- 'D:/Personal/My-2Year-Review/OxguruSomeone/'
folder_name <- 'Physical Activity/'
file_name_part_start <- 'exercise-'
file_name_part_end <- seq (from = 0, to=1400, by=100)
file_extension <-'.json'下面的 for 循环遍历文件总数,然后一一加载。最后,您会得到一个包含所有练习课程的数据框。
for (k_part in file_name_part_end){
file_selected <- paste0(folder_path,folder_name,file_name_part_start,k_part,file_extension)
data_loaded<-fromJSON(file_selected)
if(k_part == file_name_part_end[1])
{
data_loaded<-data_loaded%>%
select(all_of(sel_names))
data_all <- data_loaded
rm(data_loaded)
}
else
{
data_loaded<-data_loaded%>%
select(all_of(sel_names))
data_all<-rbind(data_all,data_loaded)
rm(data_loaded)
}
}生成汇总表
我们现在可以使用数据框来获取练习会话的高级摘要。这可能包括每种运动类型的总训练次数、总持续时间和卡路里燃烧率。
time_start=ymd('2020-04-1')
time_end=ymd('2022-03-31')
activity_type=c('Elliptical','Run','Walk','Outdoor Bike')data_selected<-data_all%>%
filter(activityName %in% activity_type)%>%
mutate(startTime=mdy_hms(startTime))%>%
filter(startTime>=time_start)%>%
filter(startTime<=time_end)%>%
arrange(startTime)data_summary<-data_selected%>%
group_by(activityName)%>%
mutate(total_duration=sum(duration)/(1000*60*60))%>%
mutate(total_sessions=n())%>%
mutate(longest_session=max(duration)/(1000*60))%>%
mutate(shortest_session=min(duration)/(1000*60))%>%
mutate(total_calories=sum(calories))%>%
mutate(mean_heartRate=mean(averageHeartRate))%>%
select(-averageHeartRate,-calories,-startTime)%>%
filter(row_number()==1)
堆积条形图,每天一条
让我们绘制一个堆积条形图,显示整两年的每日总锻炼时间。这样的图表可以帮助您了解您的锻炼程序。查看此类图表时,您可以轻松识别非常活跃的时期和安静的时期。
为了生成这样的图表,我首先将 dplyr 函数与 lubridate 结合使用,为现有数据框 (data_all) 创建额外的列。由于一天可能有多个会话,我们需要总结一天所有练习的持续时间。我们通过创建一个新列(四舍五入到最近的“单位”)然后在这个新创建的列上使用 group_by 来实现这一点(参见下面的相关片段)。
data_activity<-data_all%>%
filter(activityName %in% activity_type)%>%
mutate(startTime=mdy_hms(startTime))%>%
filter(startTime>=time_start & startTime<=time_end)%>%
mutate(startTime_round=round(startTime,unit="day"))%>%
group_by(startTime_round,activityName)%>%
mutate(duration_per_day=sum(duration/(1000*60)))%>%
mutate(total_calories=sum(calories))%>%
mutate(mean_heartRate=mean(averageHeartRate))%>%
filter(row_number()==1)这是显示每日锻炼持续时间的堆积条形图。
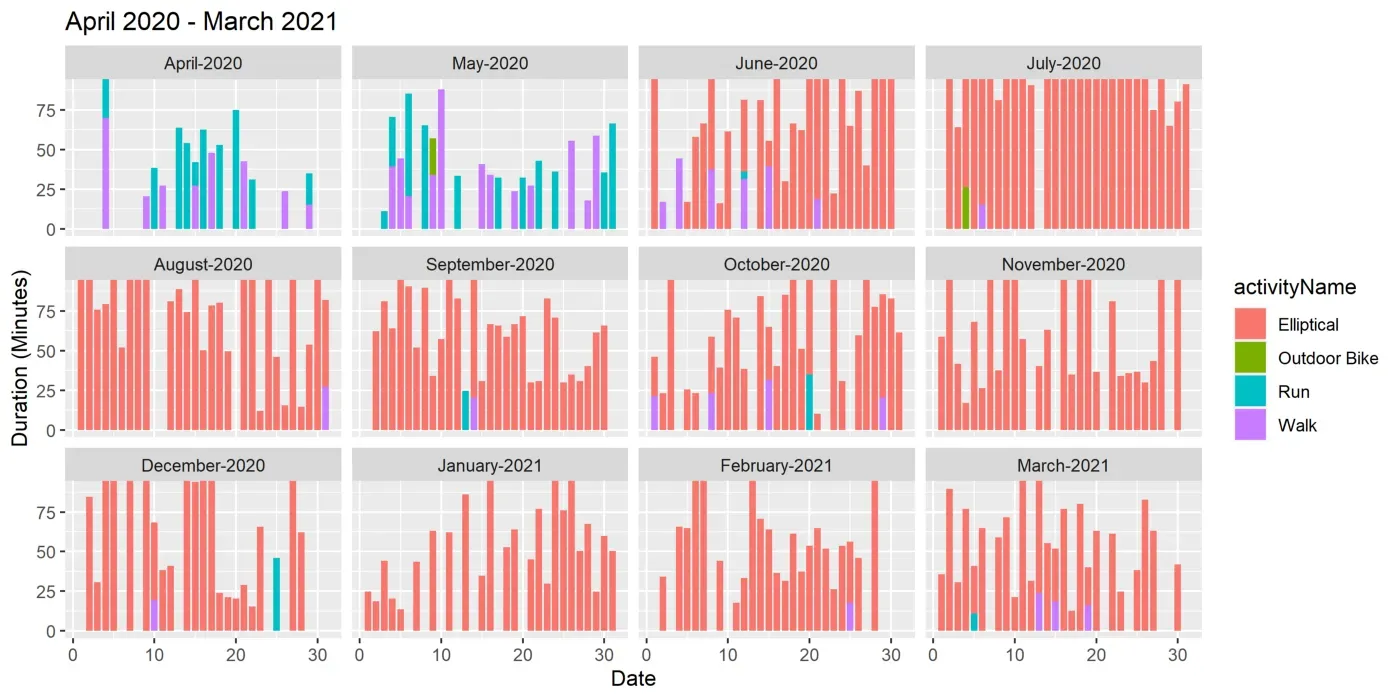
当然,您可以获得类似的卡路里和心率图。
堆积条形图,每月一个
每日堆积条形图有助于了解您的最大每日容量。然而,获得更全面的衡量标准以更好地了解我们在更长时间内的能力也是值得的。
下图显示了 2 年内每月的总持续时间。我在 2020 年 6 月得到了一名交叉训练师,接下来的一个月,我在一个月内锻炼了 60 个小时。这显然是不可持续的,然后我逐渐减少了每月的持续时间。
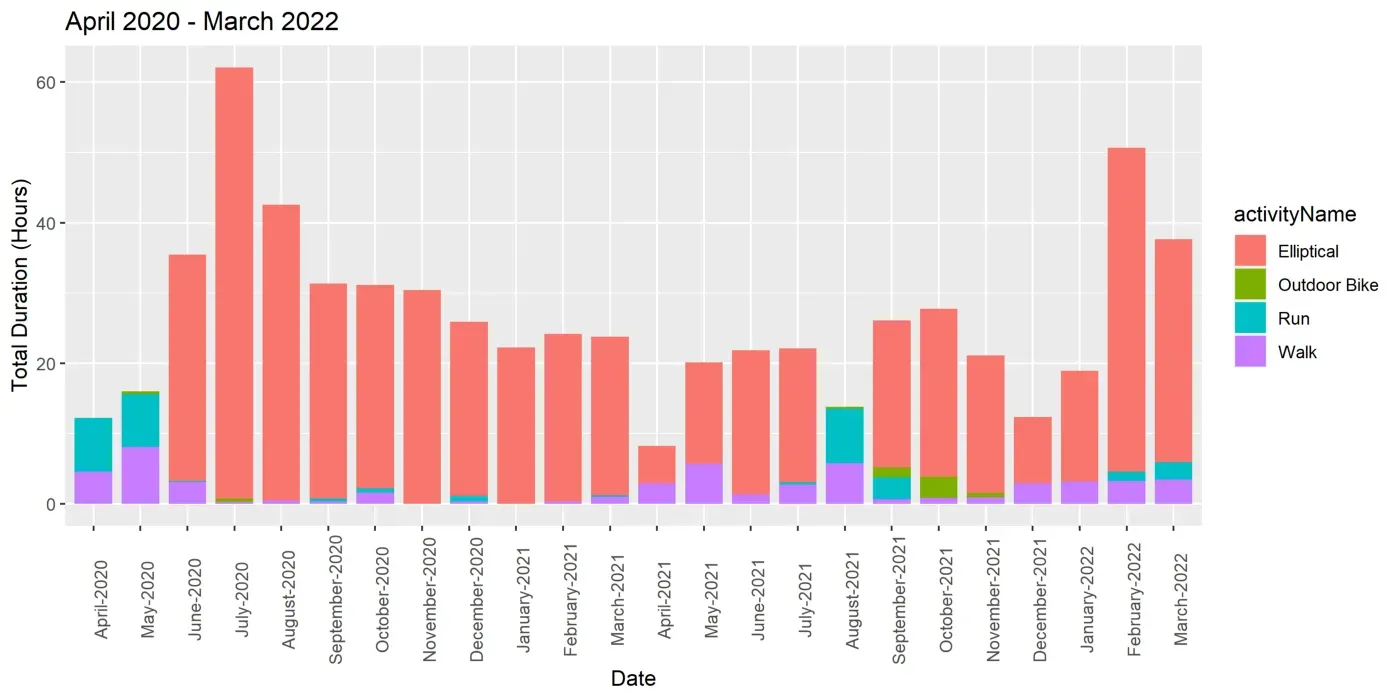
除了每个月的总时长,我们还可以计算日平均值(如下所示)。从图中可以看出,我在 2 年的时间里连续 8 个月超过了日均 60 分钟,而且我几乎总是超过了日均 30 分钟。
确定运动时间的极坐标图
为了更好地了解您更有可能锻炼的时间,您可以绘制一个统计每小时总锻炼次数的直方图。如果与 60 分钟的单个会话相比,将 2 个短会话(例如每个 10 分钟)显示为一个高条,那将没有多大意义。为了解决这个问题,您可以轻松地使用颜色/阴影按长度对会话进行分类。
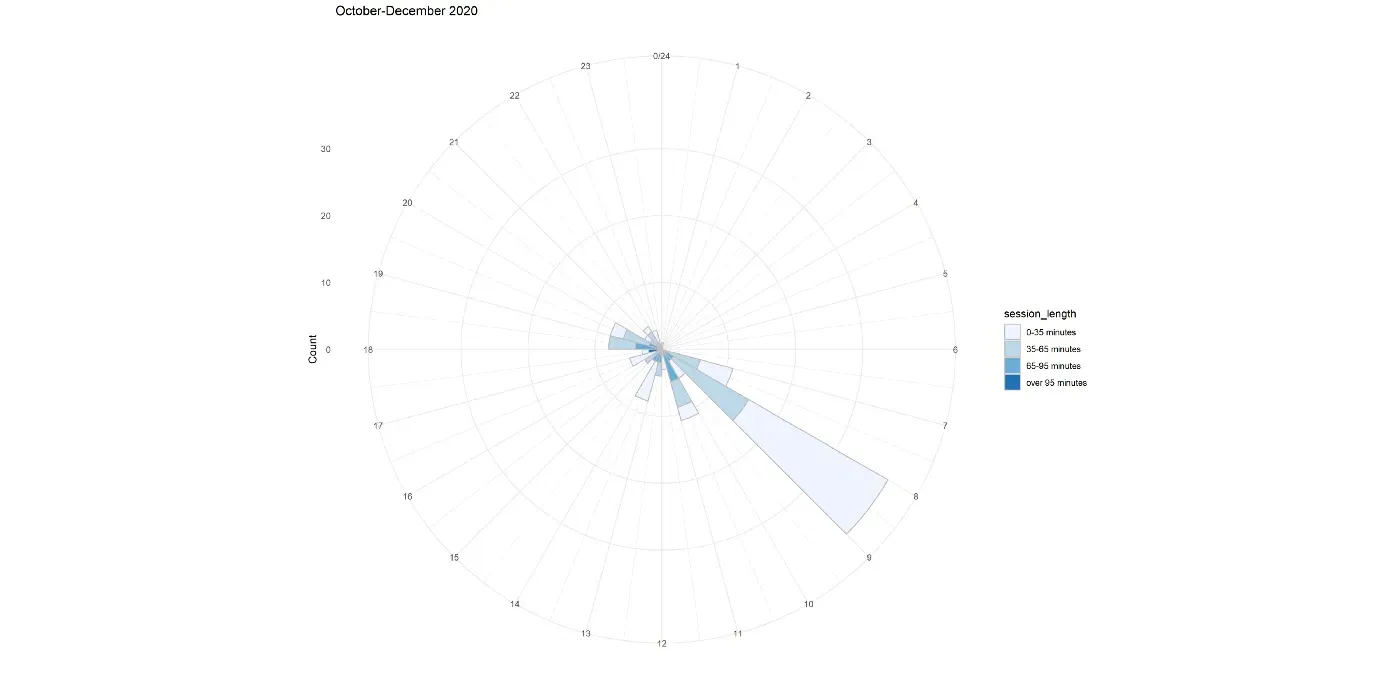
下面显示了一个 10 周期间的直方图,其中会话按持续时间分类。直方图以极坐标显示,我觉得更直观。
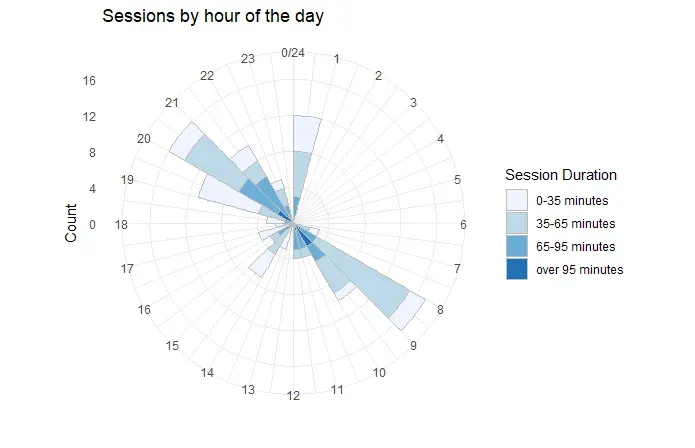
从图中,我可以看到我的大部分会话发生在清晨或晚上。上图涵盖了 2020 年 6 月期间,我平均每天约 2 小时。这也是我在午夜时分进行了相当多的会议的地方。这显然是不可持续的,我后来默认采用更可持续的方式(如下所示)。我的大部分课程都在早上。
Correlation Plots
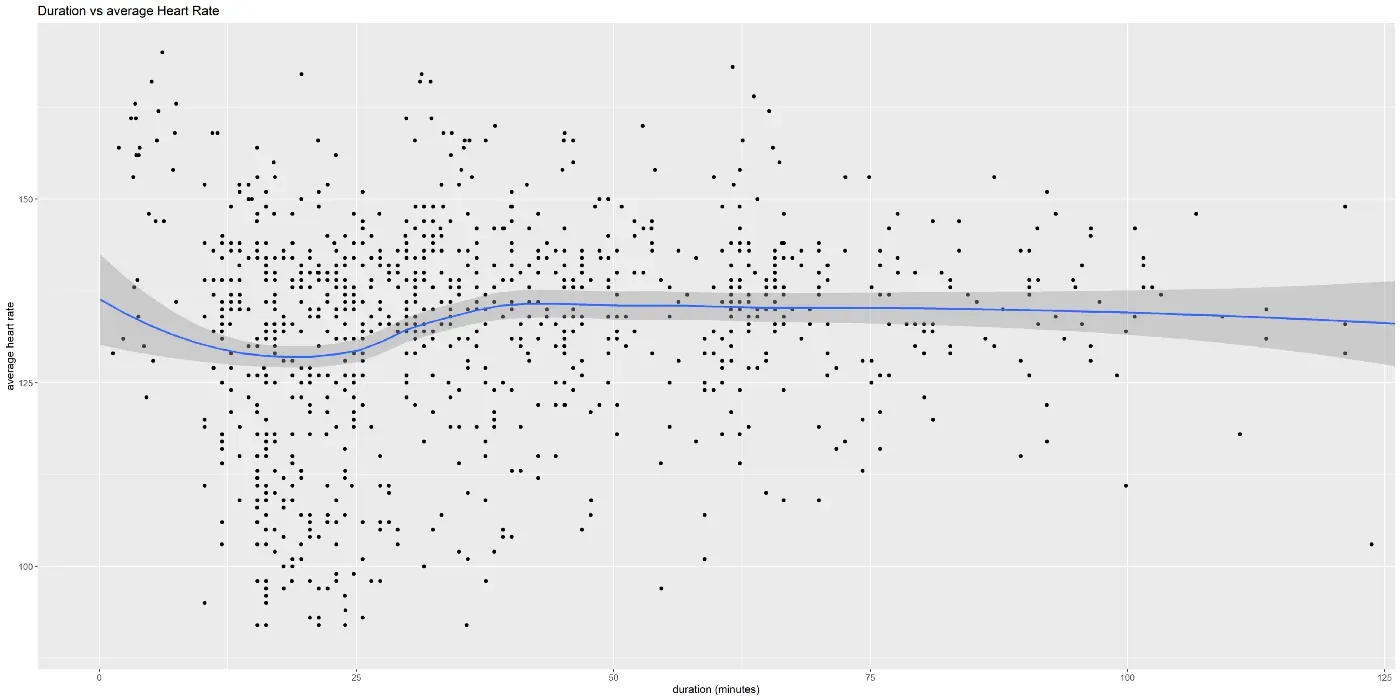
这里有一些额外的图表可以帮助回答更多问题。下图调查了每个会话的持续时间和平均心率之间的相关性。缺乏相关性表明您可以长时间维持相同的强度,长达约 60 分钟。
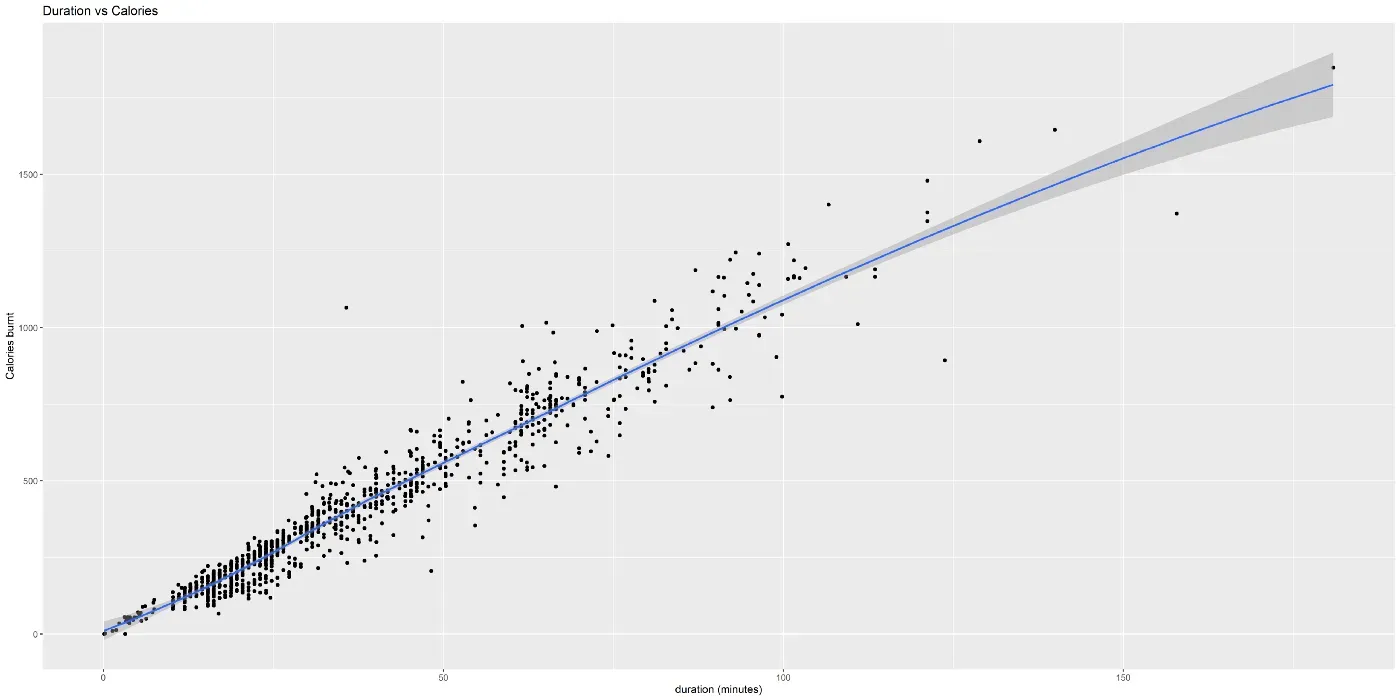
下图调查了卡路里和持续时间之间的相关性。有很强的相关性。也许并不奇怪,你锻炼的时间越长,你燃烧的卡路里就越多。
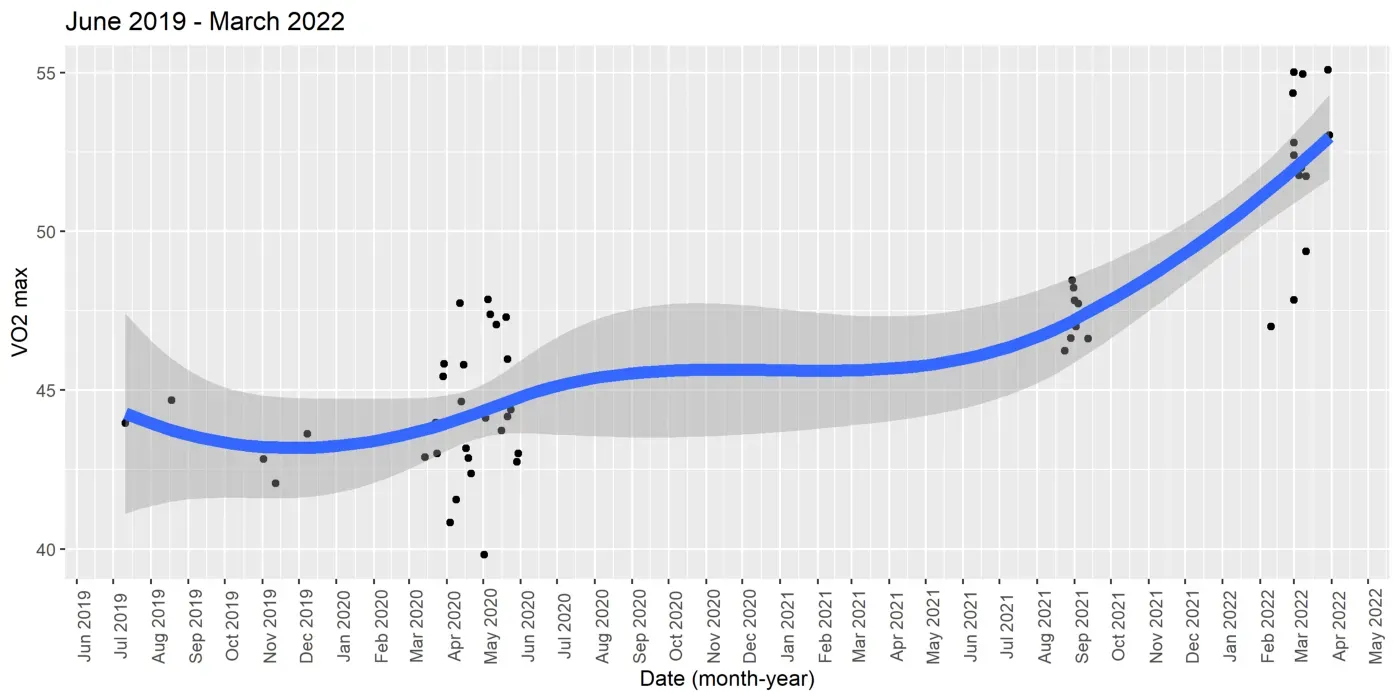
下图绘制了 2 年期间的 VO2 最大值。最大摄氧量是衡量您的心血管健康状况的指标,它衡量我们在剧烈运动时身体消耗氧气的程度。 Fitbit 设备根据配速和心率之间的关系估算此测量值。由于仅在您在户外跑步时才估算此测量值,因此我有很长一段时间没有数据点。尽管如此,即使您进行了除跑步以外的其他活动,您的体能得分仍然会提高。下图清楚地证明了这一点。
Final Thoughts
本文中的分析并不详尽。还有更多数据我没有在这里展示(例如每分钟的心率和睡眠跟踪数据)。
您实际上不需要知道可以先验地进行的所有可能的分析类型。您可以开始跟踪自己的数据,让自己的环境和好奇心驱动和塑造这个项目。
2009 年(当时我还是 20 出头),我的室友出去跑步。我满怀改变生活的动力,加入了他,并决定开始定期锻炼。 5 分钟后,我气喘吁吁,我只是停下来,得出结论,定期、持续的锻炼对我来说是不可能的。那时,我很无知,对自己的能力没有自我意识。 13 年后,跟踪了超过一千多个会话,我是一个不同的人。
一旦您开始跟踪您的会话,随着时间的推移,您将敏锐地意识到自己的能力。您将知道一天、一周、一个月和一年可以锻炼多少。您还将知道一天中的哪些时间可以进行适合您的日常锻炼,以及您喜欢的锻炼类型。您将能够更好地设定现实的、可实现的目标来维持或发展。
文章出处登录后可见!