相似性搜索的产品量化
如何使用非对称距离计算 (ADC) 在内存中压缩和拟合一组庞大的向量以进行相似性搜索

相似性搜索和最近邻搜索非常流行,并在许多领域得到广泛应用。它们用于推荐系统、支持产品图像搜索的在线商店和市场,或专门用于文档、媒体或对象匹配和检索的系统。
相似性搜索通常在大量对象嵌入上完成,通常以高维向量的形式。
在内存中拟合一组巨大的高维向量来执行相似性搜索是一个挑战,而乘积量化可以通过一些折衷来帮助克服这个问题。
什么是产品量化
乘积量化 (PQ) 是一种用于矢量压缩的技术。它在压缩高维向量以进行最近邻搜索非常有效。根据 Product Quantization for Nearest Neighbor Search [1] 的作者,[0]
“这个想法是将空间分解为低维子空间的笛卡尔积,并分别量化每个子空间。
一个向量由一个由其子空间量化索引组成的短代码表示。两个向量之间的欧几里得距离可以从它们的代码中有效地估计出来。非对称版本提高了精度,因为它计算了向量和代码之间的近似距离”。
请注意,乘积量化不是降维。[0]
乘积量化是矢量量化的一种形式,量化后矢量的个数保持不变。但是,压缩向量中的值现在被转换为短代码,因此它们是符号的,不再是数字的。使用这种表示,每个向量的大小都会大大减少。[0]
产品量化也是 Faiss(Facebook AI Similarity Search)中实现的众多索引类型之一,这是一个针对高效相似性搜索进行了高度优化的库。[0]
产品量化的工作原理
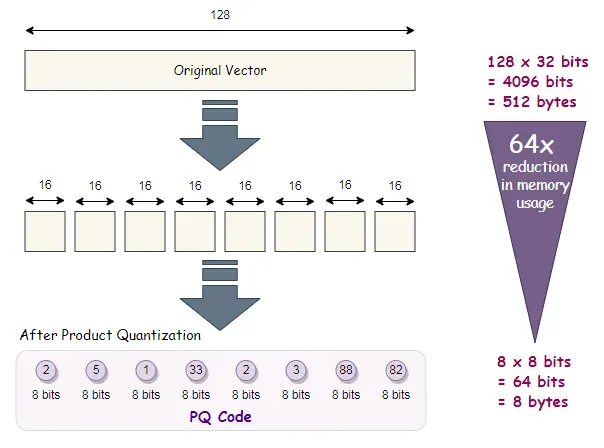
假设我们在数据库中有一组向量,每个向量的维度(或长度)为 128。这意味着一个向量的大小为 128 x 32 位 = 4096 位(相当于 512 个字节)。

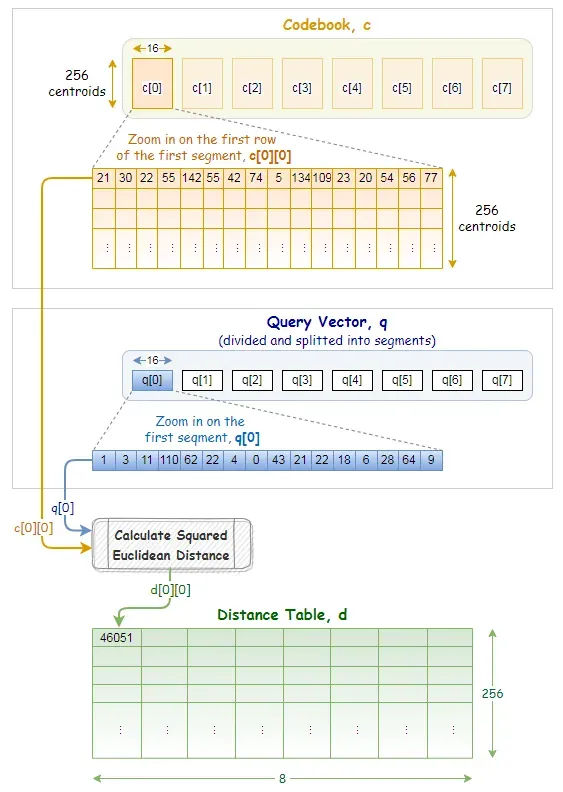
首先,我们将向量划分并分割成段。下图展示了向量被分成8段,每段长度为16。
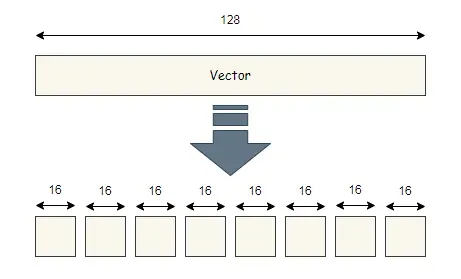
我们对每个向量都这样做,因此我们所做的本质上是将向量分成 8 个不同的子空间。如果我们在数据库中有 1000 个向量,那么每个子空间将包含 1000 个长度为 16 的段。
Training
接下来,我们通过在每个子空间上运行 k-means 聚类来继续训练我们的向量。根据我们选择的 k 值,k-means 聚类将在该子空间内生成 k 个质心(即聚类中心),并且这些质心与片段具有相同的长度。[0]
质心也称为再现值。这组质心称为码本,我们稍后会详细讨论。
例如,如果我们选择 k=256,我们最终将拥有总共 256 x 8 = 2048 个质心。
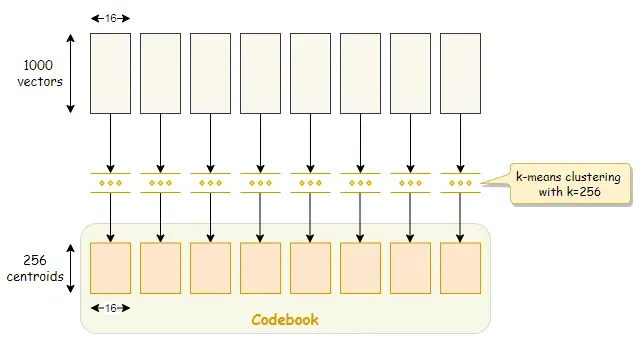
质心也称为再现值,因为它们可用于通过连接每个段的相应质心来近似重建矢量。然而,重建的向量不会与原始向量完全相同,因为乘积量化是一种有损压缩。[0]
对于训练,也可以使用不同的向量集或向量子集,只要它们与数据库向量具有相同的分布即可。
Encoding
训练完成后,对于数据库中的每一段向量,我们从各自的子空间中找到最近的质心。换句话说,对于向量的每一段,我们只需要从属于同一子空间的 256 个质心池中找到最近的质心。
对于每个段,在获得最近的质心后,我们将其替换为该质心的 ID。质心 ID 只不过是子空间内质心的索引(从 0 到 255 的数字)。
我们有了它们,它们是向量的压缩表示。这些是我们之前谈到的短代码,我们将它们称为 PQ 代码。
在此示例中,一个 PQ 代码由跨段的 8 个质心 ID 组成。我们在数据库中有 1000 个向量,因此将转换为 1000 个 PQ 代码。
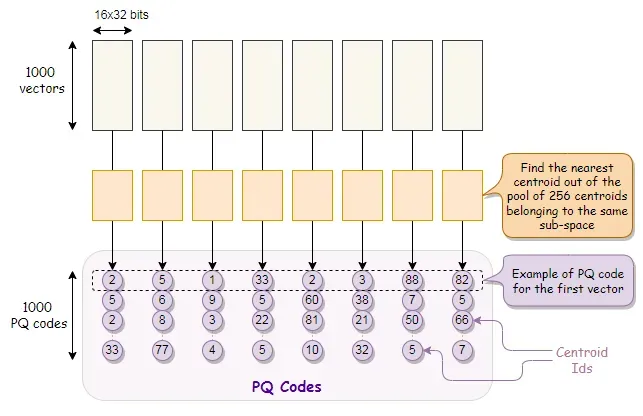
基本上我们所做的是用质心 ID 对原始向量进行编码,其中每个段都用 8 位编码。
每个向量有 8 个段,因此每个编码向量仅占用 8 x 8 位 = 8 字节的空间。与存储 512 字节的原始向量相比,这是一个巨大的空间节省。
如本例所示,我们的内存使用量大幅减少了 64 倍(从每个向量 512 字节减少到 8 字节),当我们处理数十万条记录时,这是一个很大的数字,如果不是数百万条!

k 的值通常是 2 的幂。
对于 M 个段,一个 PQ 代码的内存要求是 M*(log base 2 of k) 位。
Searching with Quantization
所以我们有效地使用了 8 个质心 ID 来表示一个向量。但是这种表示究竟如何用于相似性搜索呢?
答案在于码本,其中包含质心,即再现值。该过程解释如下。
给定一个查询向量 q,我们的目标是从数据库中的向量集合中找到与 q 非常相似的向量。
一个典型的过程是计算和比较查询向量与数据库中所有向量之间的距离,并返回距离最短的前 N 条记录。
但是,我们要做一些不同的事情。我们根本不会使用原始向量来计算距离。相反,我们将进行非对称距离计算 (ADC) 并使用矢量到质心的距离来估计距离。
我们首先将查询向量分成相同数量的段。
对于每个查询向量段,我们预先计算来自码本的同一段的所有质心的部分平方欧几里得距离。[0]
这些部分平方的欧几里得距离记录在距离表 d 中。在我们的示例中,如下所示,距离表由 256 行和 8 列组成。
现在我们有了距离表,我们可以很容易地通过查找部分距离并进行求和来获得每行 PQ 代码的距离。
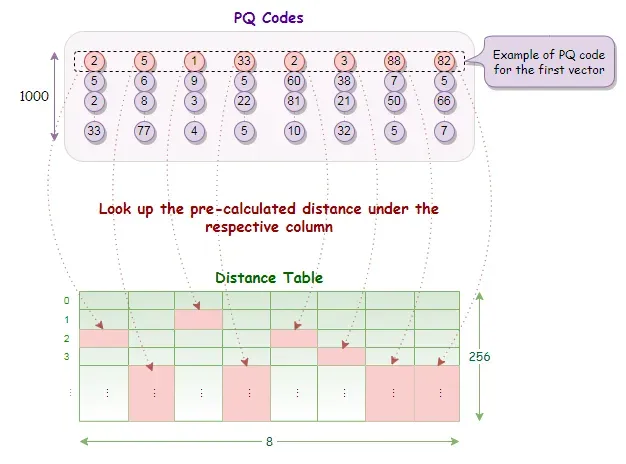
在获得所有PQ代码行的距离后,我们将它们按升序排序,并从顶部的结果(即距离最短的记录)中,从数据库中找到并返回相应的向量。
下图总结了相似度搜索的乘积量化过程。
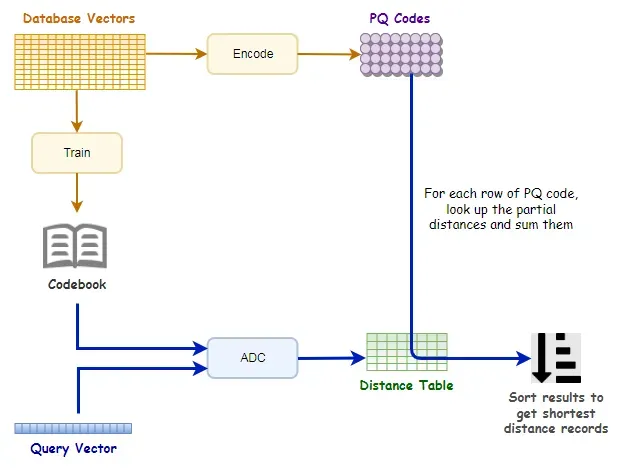
值得注意的是,通过乘积量化,搜索仍然是蛮力搜索,因为距离查找和求和是详尽的,需要对所有 PQ 代码行进行。
此外,由于我们正在比较向量到质心的距离,因此这些距离并不是精确的向量到向量距离。它们只是估计的距离,因此结果可能不太精确,并且可能并不总是真正的最近邻。
可以通过调整质心数或段数来提高搜索质量。更多的质心或段会导致更高的准确性和精度,但它们也会减慢搜索操作以及训练和编码所需的时间。除此之外,更多的质心可能会导致表示代码所需的位数增加,从而减少内存节省。
下面是乘积量化的简单 Python 实现的一瞥,灵感来自 nanopq。[0]
import numpy as np
from scipy.cluster.vq import kmeans2, vq
from scipy.spatial.distance import cdist
def PQ_train(vectors, M, k):
s = int(vectors.shape[1] / M) # Dimension (or length) of a segment.
codebook = np.empty((M, k, s), np.float32)
for m in range(M):
sub_vectors = vectors[:, m*s:(m+1)*s] # Sub-vectors for segment m.
codebook[m], label = kmeans2(sub_vectors, k) # Run k-means clustering for each segment.
return codebook
#-----------------------------------------------------------------------------------------------
def PQ_encode(vectors, codebook):
M, k, s = codebook.shape
PQ_code = np.empty((vectors.shape[0], M), np.uint8)
for m in range(M):
sub_vectors = vectors[:, m*s:(m+1)*s] # Sub-vectors for segment m.
centroid_ids, _ = vq(sub_vectors, codebook[m]) # vq returns the nearest centroid Ids.
PQ_code[:, m] = centroid_ids # Assign centroid Ids to PQ_code.
return PQ_code
#-----------------------------------------------------------------------------------------------
def PQ_search(query_vector, codebook, PQ_code):
M, k, s = codebook.shape
#=====================================================================
# Build the distance table.
#=====================================================================
distance_table = np.empty((M, k), np.float32) # Shape is (M, k)
for m in range(M):
query_segment = query_vector[m*s:(m+1)*s] # Query vector for segment m.
distance_table[m] = cdist([query_segment], codebook[m], "sqeuclidean")[0]
#=====================================================================
# Look up the partial distances from the distance table.
#=====================================================================
N, M = PQ_code.shape
distance_table = distance_table.T # Transpose the distance table to shape (k, M)
distances = np.zeros((N, )).astype(np.float32)
for n in range(N): # For each PQ Code, lookup the partial distances.
for m in range(M):
distances[n] += distance_table[PQ_code[n][m]][m] # Sum the partial distances from all the segments.
return distance_table, distances
#-----------------------------------------------------------------------------------------------
# Test case
M = 8 # Number of segments
k = 256 # Number of centroids per segment
vector_dim = 128 # Dimension (length) of a vector
total_vectors = 1000000 # Number of database vectors
# Generate random vectors
np.random.seed(2022)
vectors = np.random.random((total_vectors, vector_dim)).astype(np.float32) # Database vectors
q = np.random.random((vector_dim, )).astype(np.float32) # Query vector
# Train, encode and search with Product Quantization
codebook = PQ_train(vectors, M, k)
PQ_code = PQ_encode(vectors, codebook)
distance_table, distances = PQ_search(q, codebook, PQ_code)
# All the distances are returned, you may sort them to get the shortest distance.Summary
乘积量化将向量划分为段,对向量的每一段分别进行量化。
数据库中的每个向量都被转换为一个短代码(PQ 代码),这种表示对于近似最近邻搜索来说非常节省内存。
具有乘积量化的相似性搜索具有高度可扩展性,但我们用一些精度来换取内存空间。
以不太精确的搜索为代价,乘积量化实现了大规模搜索,否则这是不可能的。
由于单独的乘积量化并不是超大规模搜索的最有效方法,我们将在下一篇文章中看到如何实现更快的非穷举搜索方法。敬请关注!
Reference
[1] H. Jégou、M. Douze、C. Schmid,最近邻搜索的乘积量化 (2010)[0]
[2] C. McCormick,k-NN 教程第 1 部分的乘积量化器(2017 年)[0]
[3] J. Briggs,产品量化:将高维向量压缩 97%[0]
[4] 纳米产品量化(nanopq)[0]
Before You Go...Thank you for reading this post, and I hope you’ve enjoyed learning about product quantization for similarity search.If you like my post, don’t forget to hit Follow and Subscribe to get notified via email when I publish.Optionally, you may also sign up for a Medium membership to get full access to every story on Medium.📑 Visit this GitHub repo for all codes and notebooks that I shared in my posts.© 2022 All rights reserved.
有兴趣阅读我的其他数据科学文章吗?查看以下内容:
Peggy Chang[0]
掌握动态规划系列
View list2 stories

文章出处登录后可见!