文章目录
- 前言
- 一、安装AI模型软件stable-diffusion-webui
-
- 1.环境安装
- 2.配置中文包
- 二、配置算法模型
-
- 1.配置底模型
- 2.LoRA的使用
- 3.配置精准控图模型
- 三、Prompt的魔法
-
- 1.定向提升图画质量
- 总结
前言
最近随着ChatGPT的爆火,AI绘画也火得不行,这几天文心一言发布会,图片生成的梗都快被大家玩坏了,网上有不少Midjourney的使用分享,但是毕竟那个是商用网站,收费的,博主今天给大家发个福利!出一波免费使用AI绘画的教程:Stable-Diffusion本地化部署及使用!手把手教你如何使用AI绘画!如果对AIGC感兴趣的同学,欢迎私信我!有干货分享哦~
一、安装AI模型软件stable-diffusion-webui
1.环境安装
首先我们需要安装AI模型软件stable-diffusion-webui,在安装前需要完成基础依赖环境的安装工作【注意本博客实验环境是Windows】:
- 安装cuda库
- 安装cudnn加速库
- 安装git-bash(区分64位和32位)
- 安装python3.10
完成上述基础环境依赖的安装后,我们下载stable-diffusion-webui:找一个空间较大的磁盘新建文件夹MyProgram(文件名最好是英文,命名随意,你也可以命名为其他的),进去后,在空白的地方右键,点击git bash here:
然后在命令行中输入:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
等待下载,下载完成以后,在MyProgram文件夹中会出现stable-diffusion-webui文件夹,进入该文件夹中,双击webui.bat文件,该文件会自动创建所需要的各种环境(时间可能会比较长),环境安装完成以后,在窗口上会出现一个如下图所示的链接:

复制该链接到浏览器中打开,则进入UI界面,如下所示:
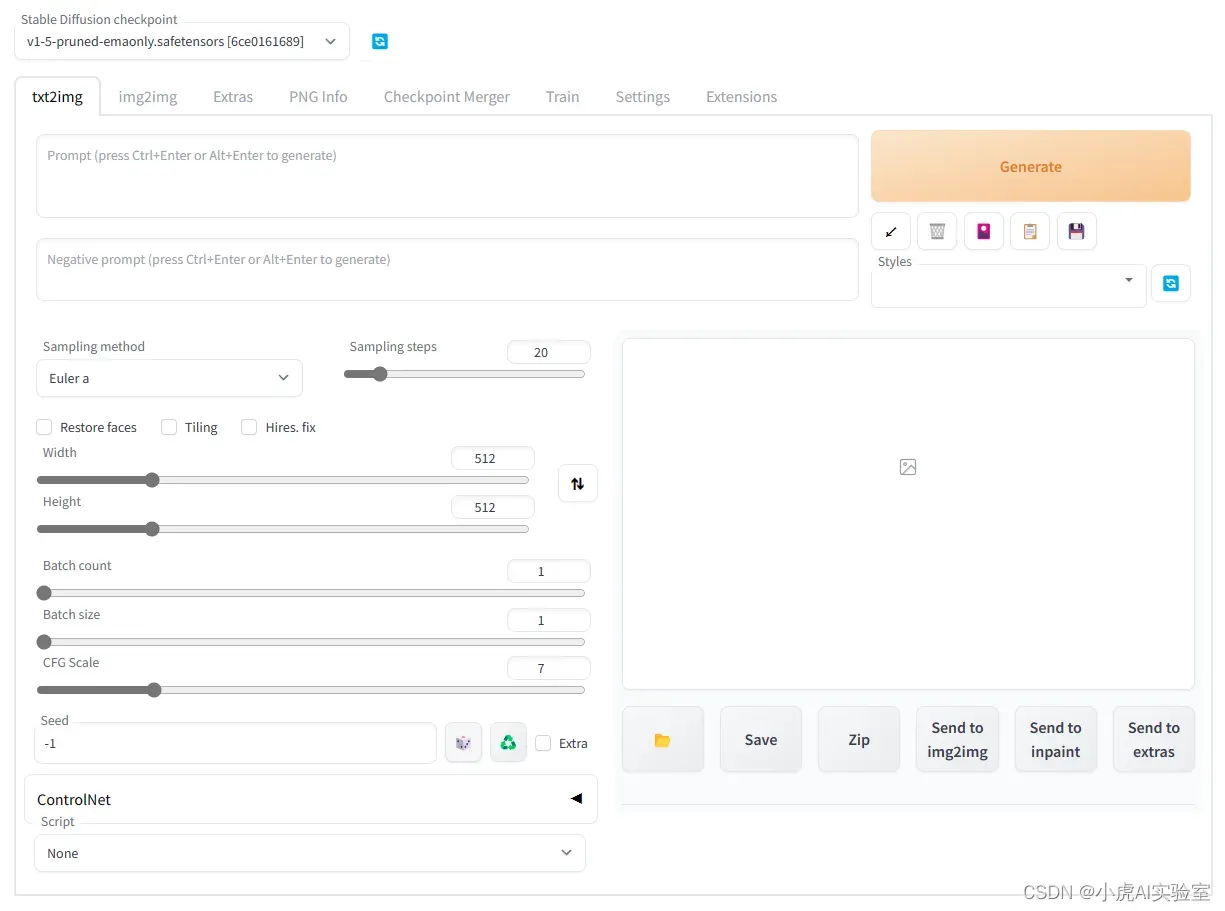
我们可以看到,在这个界面上有txt2img(文字生成图片), img2img(图片生成图片)等等。到这里为止, 我们已经可以快乐的玩耍了!自己去尝试生成属于自己的图吧!
2.配置中文包
如果你的英语还不错,就直接跳过这一步吧,如果你的英语和我一样稀烂,那么可以考虑设置一个中文包,具体步骤如下:
- 在界面上点击Extensions,点击取消localization,并如下图所示点击Load from
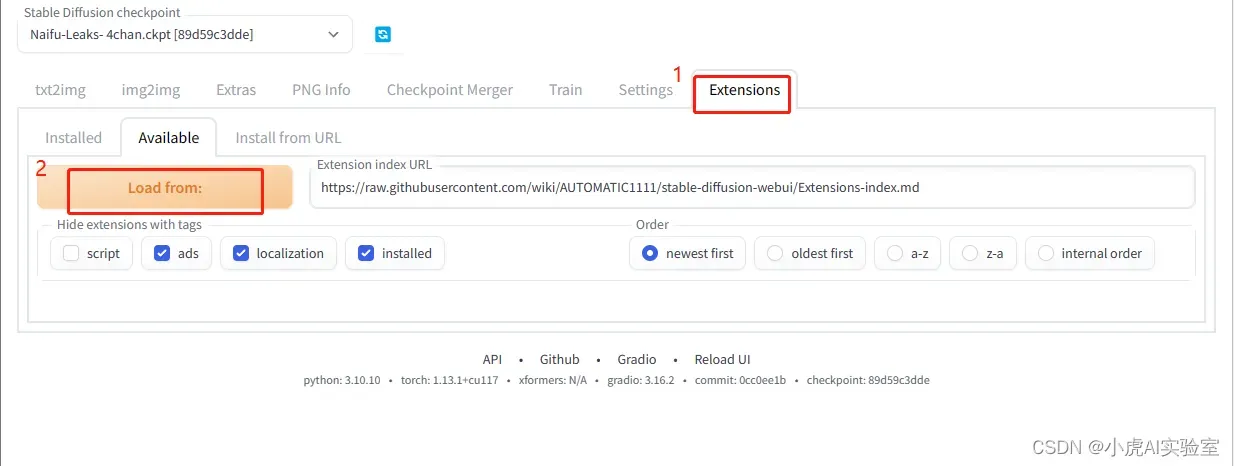
- 在出来的列表中找到 zh_CN Localization,然后点击后面的Install,等待安装完毕,点击下面所示的按钮:
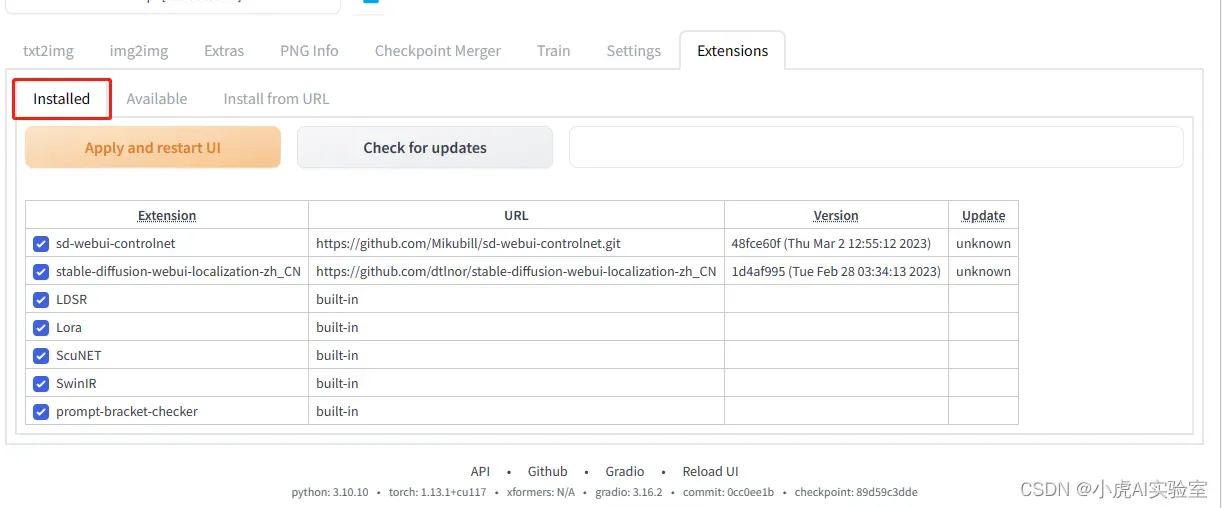
- 点击 Apply and restart UI按钮,等待重启页面(不要关闭页面,等待即可)
- 重启完毕以后,按照如下顺序点击:
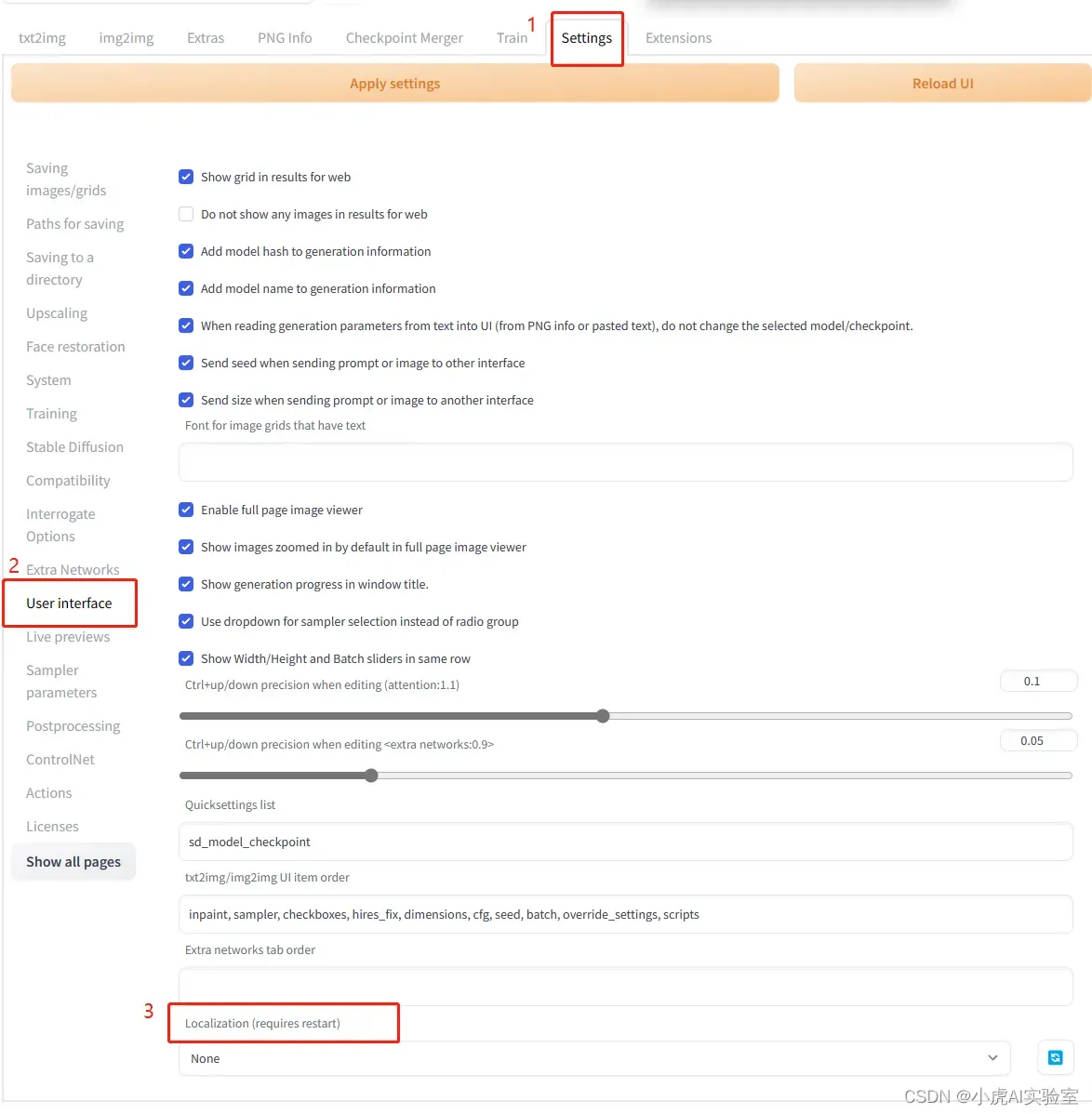 5. 选择zh_CN后,点击上面的Apply settings按钮,再按照如下顺序点击:
5. 选择zh_CN后,点击上面的Apply settings按钮,再按照如下顺序点击:
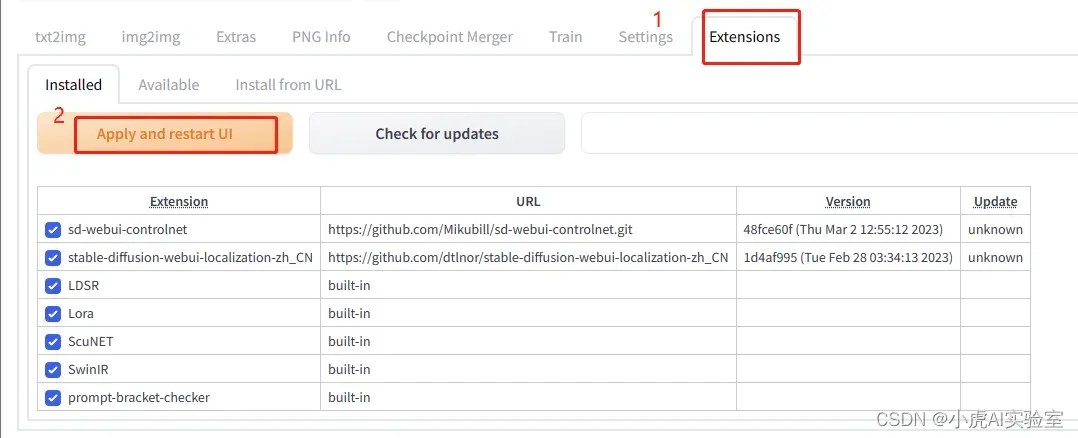
等待重启结束后即可。
二、配置算法模型
1.配置底模型
stable diffusion提供了一系列的模型:
- stable-diffusion-v1-4
- 擅长绘制风景类画,整体偏欧美风,具有划时代意义
- stable-diffusion-v1-5
- 同上,但生成的作品更具艺术性
- stable-diffusion-2
- 图像生成质量大幅提升,原生支持768×768等
- waifu-diffusion
- 设定随机种子后,每次将生成相同的图像,无随机性,可方便复现
下载上述模型,将模型放到目录下,如果UI(前面所述的软件界面)是打开的,可按照如下顺序点击生效:
2.LoRA的使用
-
安装
LoRA是一个微调模型,可以对基础模型提供更好的支撑,从而生成我们想要的风格。一般来说,我们可以下载我们想要的LORA模型,然后将模型拷贝到目录下,按照前面所说的方式,再次应用重启即可。 -
使用
在打开的UI界面上,点击右侧的扩展网络,然后点击出现界面中的Lora按钮:那么我们就可以看到我们添加的LoRA模型,在输入提示词的时候,点击LoRA模型,则会添加LoRA对应的提示词,进而实现风格的转换。如下是一组示例(下面的是使用LoRA生成的图像),通过使用了中国风的LoRA模型,我们生成的画面更有特色。

-
资源
如果你想使用别人生成的LoRA模型,可以考虑在hugging face上进行搜索,除此之外,CIVITAI也是一个非常好的选择。我们大概整理了下面一些不同类型的LoRA模型,感兴趣的可以自行下载。
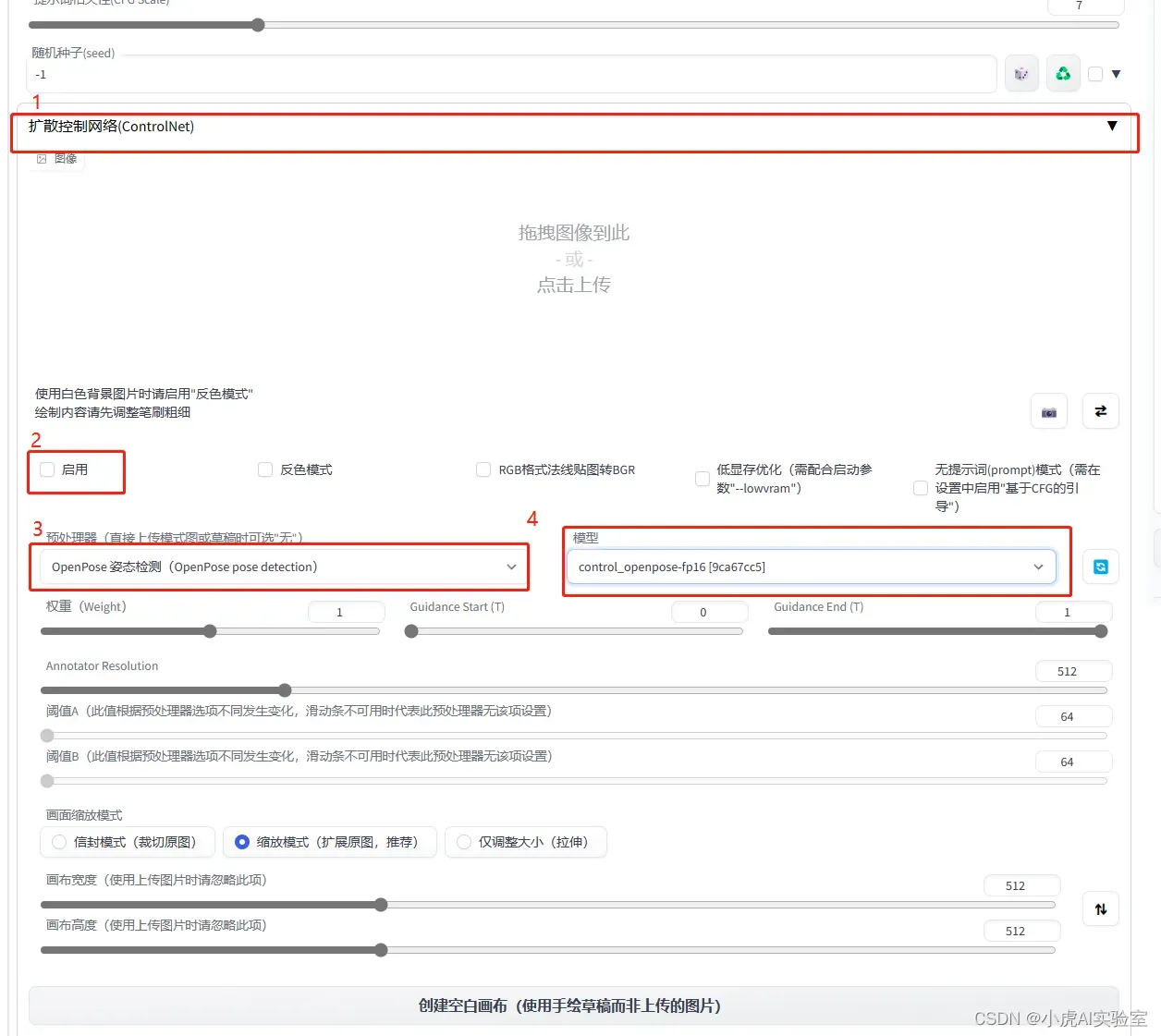
3.配置精准控图模型
-
安装
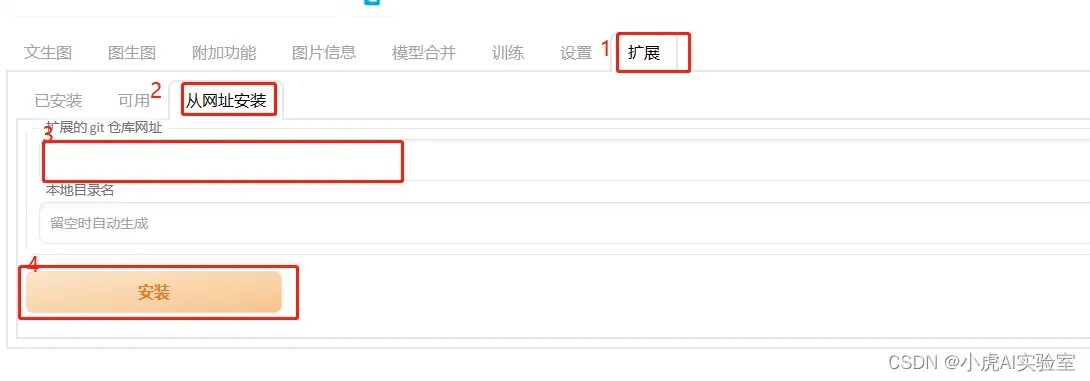
在UI界面中按照如下顺序先点击1和2,然后在3的位置输入地址,然后点击4,即可。安装完毕以后,按顺序点击已安装、应用并重启用户界面即可。
为了后面使用具体的应用, 我们需要下载一些ControlNet使用的模型,下面的链接是ControlNet的一些模型:地址,以人体姿态为例,我们下载模型,然后将下载的模型放在models/controlNet底下,然后应用并重启界面即可。 -
使用
在文生图界面按照如下顺序点击设置成人体姿态,中间空白处可以上传我们的目标姿态,我们生成的图将会根据这个目标姿态相似。
下面我们将展示怎么控制人物的姿态。以 a beautiful girl为提示词,不使用ControlNet生成的图如下(具体生成什么样的风格与你的底模型有关,也就是页面左上角Stable Diffusion模型处展示的模型):

为了过审拼了!想看原图的私信我!
而当我们设置以前辈其他任务为模板时,可以生成如下图片:
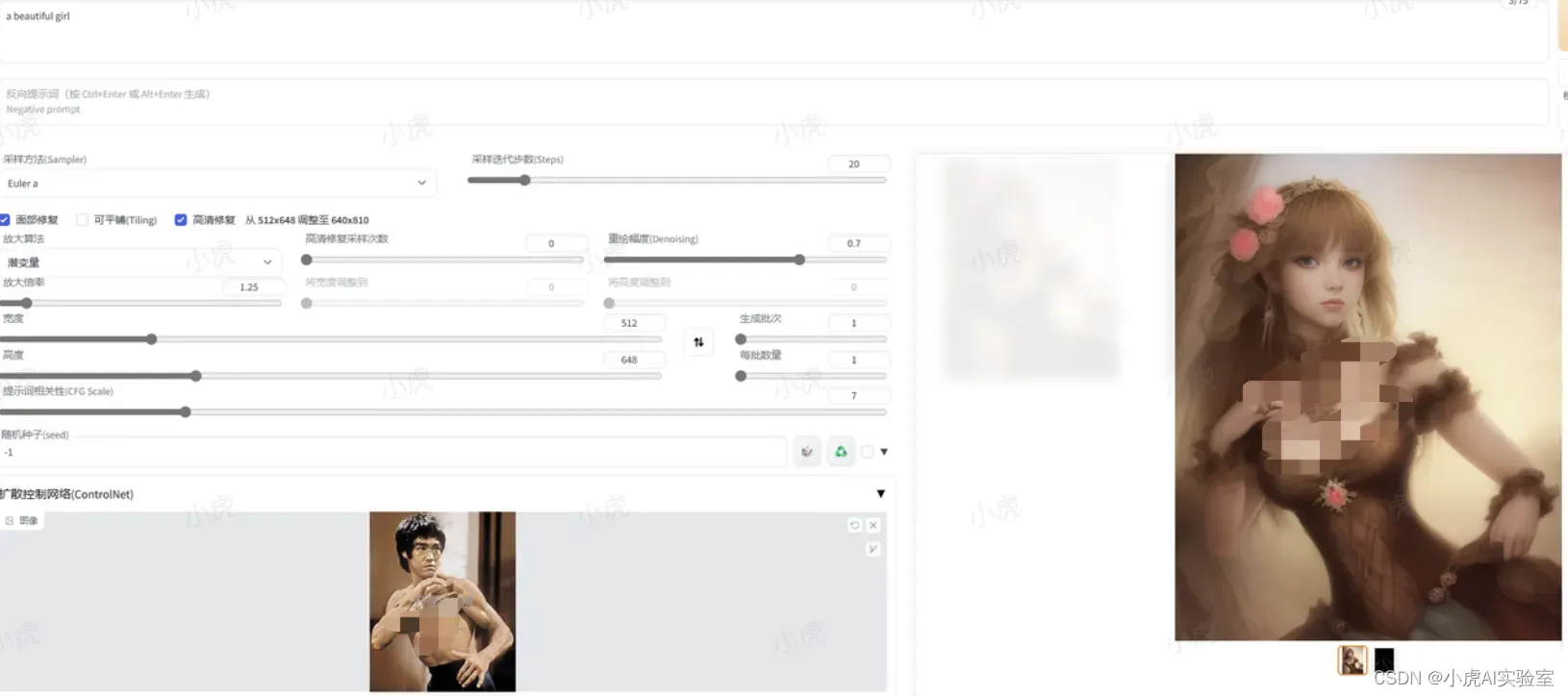
同学们凑活着看看吧,动作和形态是一致的😄。
三、Prompt的魔法
无论是ChatGPT还是StableDiffusion,目前知道的是,提示词(prompt)在这一类AIGC的任务中扮演着非常重要的角色,下面我们将对提示词进行讲解,主要内容包含提示词的语法、正反提示词、如何用提示词定向提升图画质量。想要进一步了解Prompt魔法,一些基础介绍可以看我的玩赚ChaGPT专栏。
1.定向提升图画质量

这一部分,我们将基于上面讲到的提示词基本语法,进行一次实际展示。我们还是基于文生图,底模型选择Perfect-world,ControlNet的设置与上面一样,我们首先输入提示词为:a beautiful realistic girl with oval face, tree, sea 。图片如上左所示,我们发现这个人的手有一点不正常,为了告诉AI我们希望这个手是正常的,我们可以在负提示词里面输入:bad fingers,那么我们将生成上右的图。如果我们希望她苗条一点,那么一种做法是在负提示词中加上fat,那么我们将得到下左的图画:

如果我们希望这是个男的呢?修改提示词里面的girl为boy,那么我们将得到上右的图画。
哈哈哈哈😄,好玩吧?如果想进一步了解AI绘画的知识,可以私信我拉你进交流群哦~
总结
文章最后博主想说点别点:ChatGPT所引发的这场科技革命,必然会在数十亿打工人中掀起狂风暴雨!科技创新必然会带来生产力的极大提高,可怕的是这个提高是指数级别增长的!从ChatGPT 到GPT-4再到百度文心一言发布,再到如今微软GPT-4 Office全家桶的重大发布,我既感到兴奋,又有一些忧虑:“当时代抛弃你时,连一声再见也不会说”!
版权声明:本文为博主作者:小虎AI实验室原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/u010665216/article/details/129694899