申明此篇博文是以AlexNet为网络架构(其需要输入的图像大小为227x227x3),CIFAR10为数据集,SGD为梯度下降函数举例。
运行此程序时,文件的结构:
/content/drive/MyDrive/coder/Simple-CV-Pytorch-master
|
|
|
|----AlexNet----train.py(train_adjust_learning_rate.py,train_MultiStepLR.py等等)
|
|
|
|----tensorboard(保存tensorboard的文件夹)
|
|
|
|----checkpoint(保存模型的文件夹)
|
|
|
|----data(数据集所在文件夹)
|
|
|
|----run.ipynb(运行.ipynb文件)
首先,我们设置的学习率在一定时候可能无法使我们当前的损失下降,所以此时需要重新调节学习率,如果是使用Pytorch编程,则这个时候就会用到Pytorch中的scheduler。
scheduler机制(策略)位于torch.optim.lr_scheduler.XX中
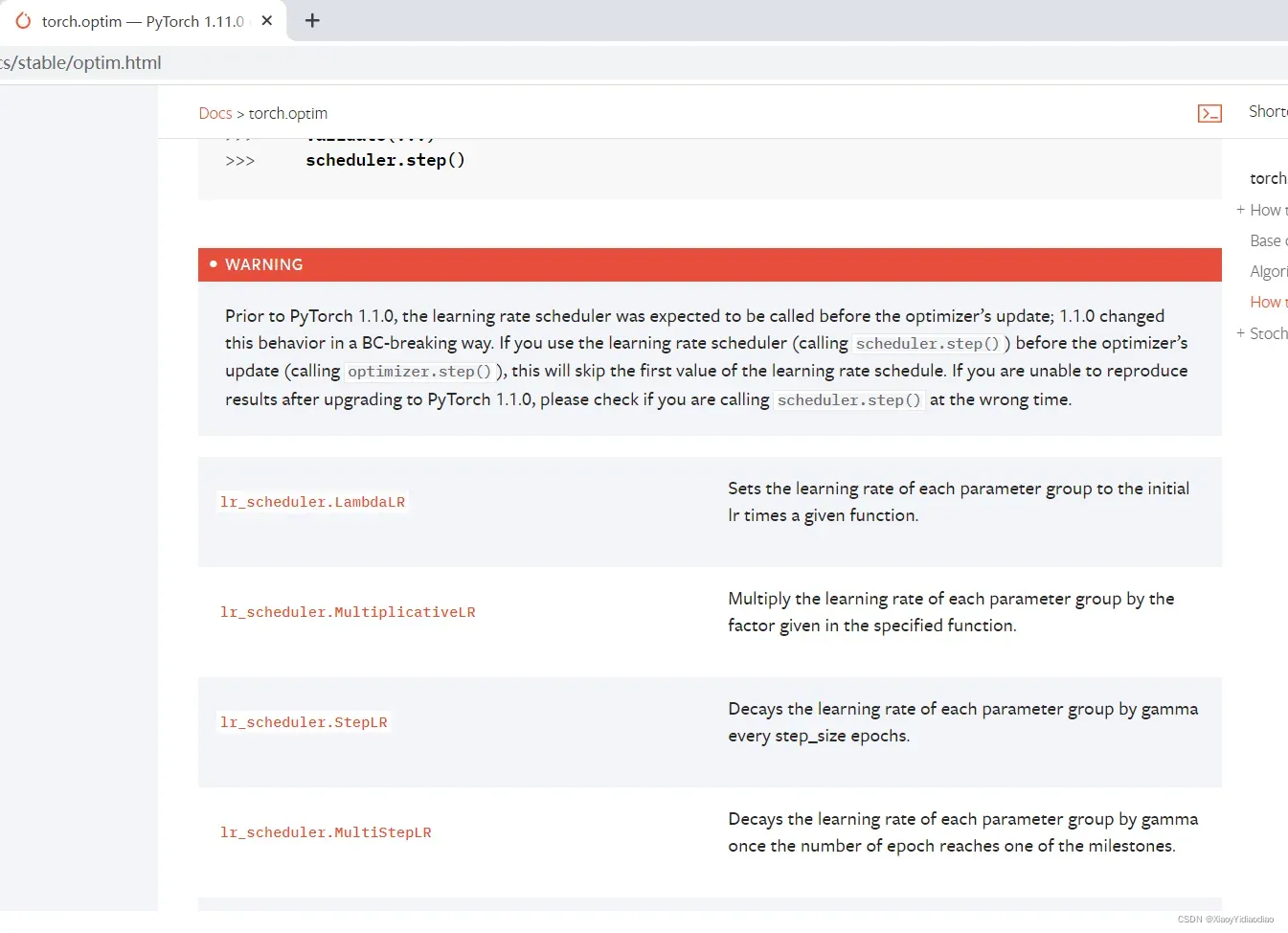

 如果不使用任何机制(策略)直接修改学习率
如果不使用任何机制(策略)直接修改学习率
for param_group in optim.param_groups:
param_group['lr'] = lrscheduler机制(策略)常用的大致有七种形式,我们逐一介绍,并给出代码,为更好理解将其可视化:
1.自定义衰减学习率:adjust_learning_rate()
(作者写的)函数讲解:分段,每隔几(2)段个epoch,第一个epoch为序号0不计,使学习率变乘以0.1的epoch次方数
def adjust_learning_rate(optim, epoch, size=2, gamma=0.1):
if (epoch + 1) % size == 0:
pow = (epoch + 1) // size
lr = learning_rate * np.power(gamma, pow)
for param_group in optim.param_groups:
param_group['lr'] = lr若想知道训练代码如何理解可看我往期博文:
19.初识Pytorch之完整的模型套路-整理后的代码![]() https://blog.csdn.net/XiaoyYidiaodiao/article/details/122720320?spm=1001.2014.3001.5501注意:此段代码无比简陋,仅为我平时书写代码的雏形,不符合规范,大致能理解尚可!
https://blog.csdn.net/XiaoyYidiaodiao/article/details/122720320?spm=1001.2014.3001.5501注意:此段代码无比简陋,仅为我平时书写代码的雏形,不符合规范,大致能理解尚可!
代码:
from torch.utils.data import DataLoader
from torchvision.models import AlexNet
from torchvision import transforms
import torchvision
import torch
from torch import nn
from torch.utils.tensorboard import SummaryWriter
import time
import numpy as np
def adjust_learning_rate(optim, epoch, size=2, gamma=0.1):
if (epoch + 1) % size == 0:
pow = (epoch + 1) // size
lr = learning_rate * np.power(gamma, pow)
for param_group in optim.param_groups:
param_group['lr'] = lr
# 1.Create SummaryWriter
writer = SummaryWriter("../tensorboard")
# 2.Ready dataset
train_dataset = torchvision.datasets.CIFAR10(root="../data", train=True, transform=transforms.Compose(
[transforms.Resize(227), transforms.ToTensor()]), download=True)
print('CUDA available: {}'.format(torch.cuda.is_available()))
# 3.Length
train_dataset_size = len(train_dataset)
print("the train dataset size is {}".format(train_dataset_size))
# 4.DataLoader
train_dataloader = DataLoader(dataset=train_dataset, batch_size=64)
# 5.Create model
model = AlexNet()
if torch.cuda.is_available():
model = model.cuda()
model = torch.nn.DataParallel(model).cuda()
else:
model = torch.nn.DataParallel(model)
# 6.Create loss
cross_entropy_loss = nn.CrossEntropyLoss()
# 7.Optimizer
lr = learning_rate = 1e-3
optim = torch.optim.SGD(model.parameters(), lr=learning_rate)
# 8. Set some parameters to control loop
# epoch
epoch = 20
iter = 0
t0 = time.time()
for i in range(epoch):
t1 = time.time()
print(" -----------------the {} number of training epoch --------------".format(i))
model.train()
for data in train_dataloader:
imgs, targets = data
if torch.cuda.is_available():
cross_entropy_loss = cross_entropy_loss.cuda()
imgs, targets = imgs.cuda(), targets.cuda()
outputs = model(imgs)
loss_train = cross_entropy_loss(outputs, targets)
writer.add_scalar("train_loss", loss_train.item(), iter)
optim.zero_grad()
loss_train.backward()
optim.step()
iter = iter + 1
if iter % 100 == 0:
print(
"Epoch: {} | Iteration: {} | lr: {} | loss: {} | np.mean(loss): {} "
.format(i, iter, optim.param_groups[0]['lr'], loss_train.item(),
np.mean(loss_train.item())))
writer.add_scalar("lr", optim.param_groups[0]['lr'], i)
adjust_learning_rate(optim, i)
t2 = time.time()
h = (t2 - t1) // 3600
m = ((t2 - t1) % 3600) // 60
s = ((t2 - t1) % 3600) % 60
print("epoch {} is finished, and time is {}h{}m{}s".format(i, int(h), int(m), int(s)))
if i % 1 == 0:
print("Save state, iter: {} ".format(i))
torch.save(model.state_dict(), "../checkpoint/AlexNet_{}.pth".format(i))
torch.save(model.state_dict(), "../checkpoint/AlexNet.pth")
t3 = time.time()
h_t = (t3 - t0) // 3600
m_t = ((t3 - t0) % 3600) // 60
s_t = ((t3 - t0) % 3600) // 60
print("The finished time is {}h{}m{}s".format(int(h_t), int(m_t), int(s_t)))
writer.close()注意:以上程序直接使用Pycharm上运行。
我们的train.py文件在AlexNet文件夹里,文件夹data、tensorboard、checkpoint与AlexNet文件夹平级,所以使用data、tensorboard、checkpoint在前面加入返回上一级../data、../tensorboard、../checkpoint。
运行结果:
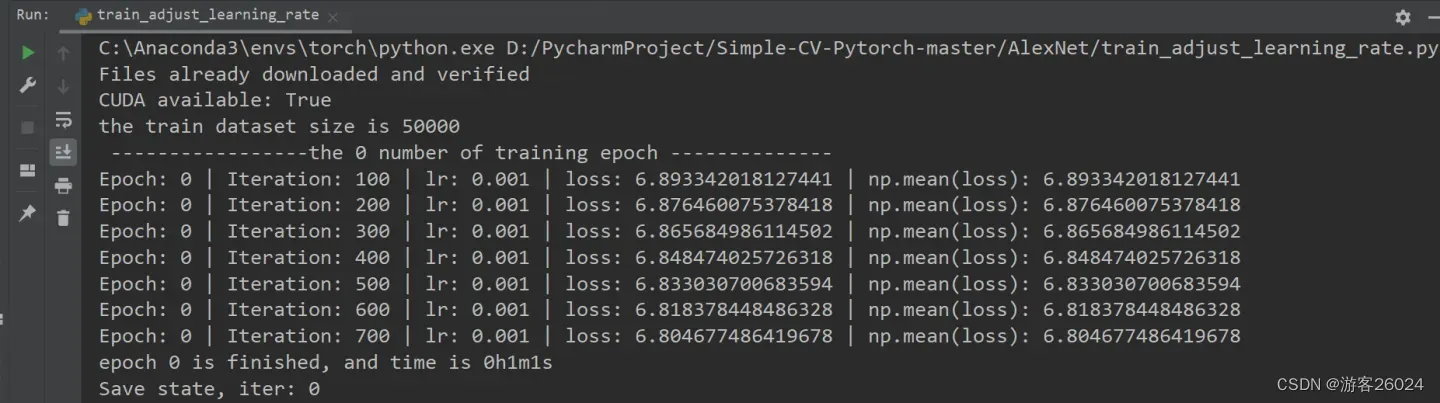
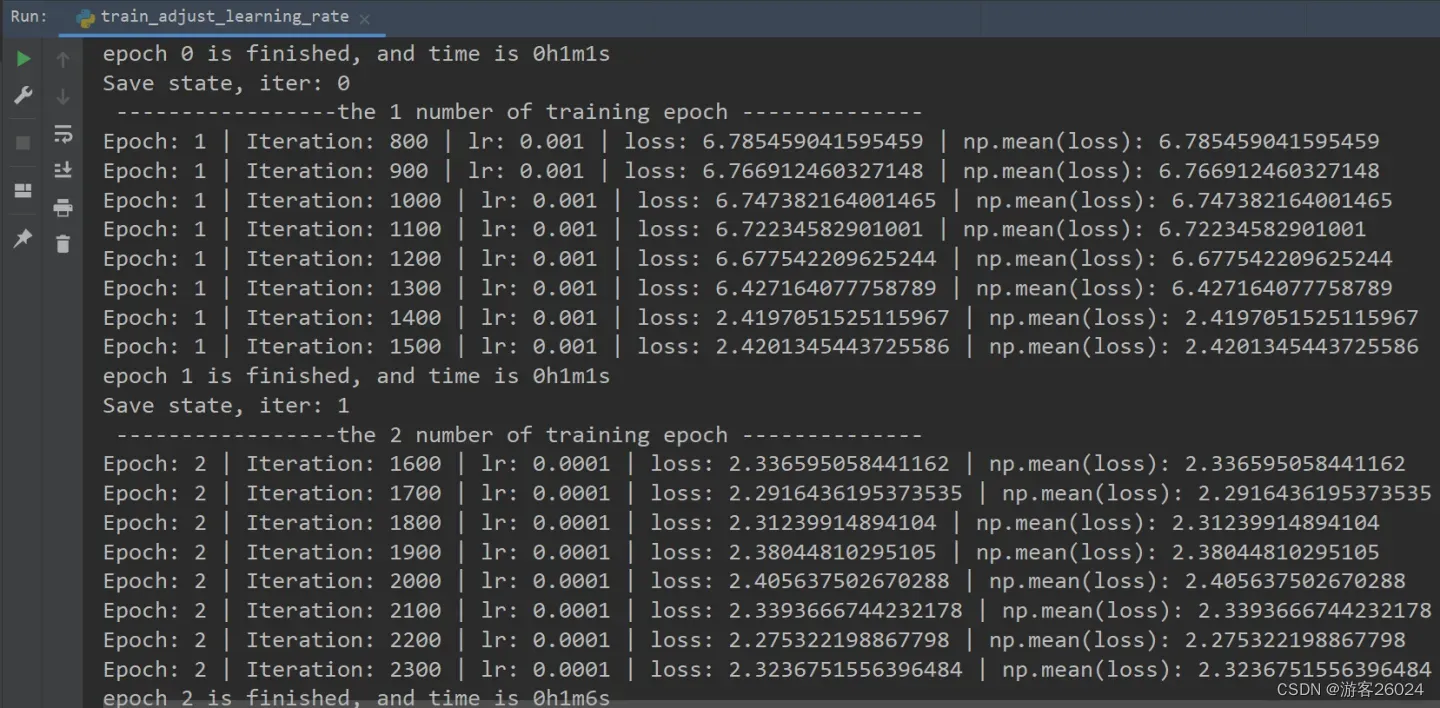
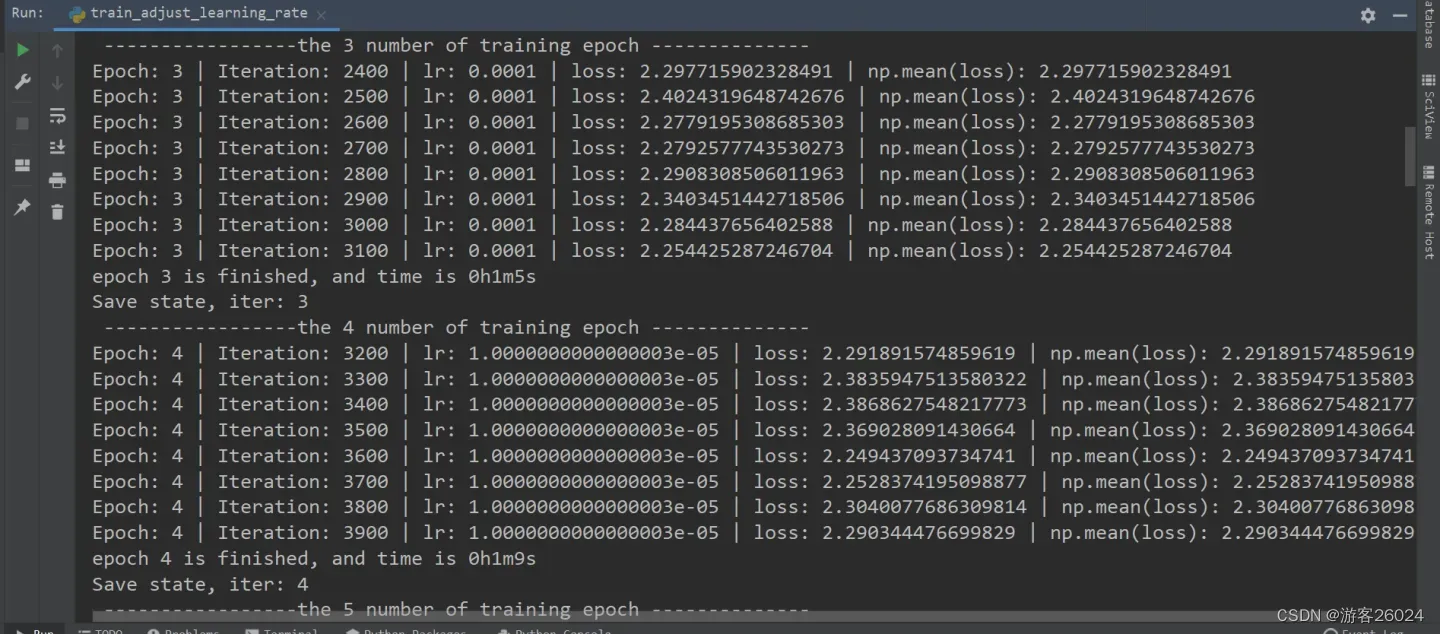
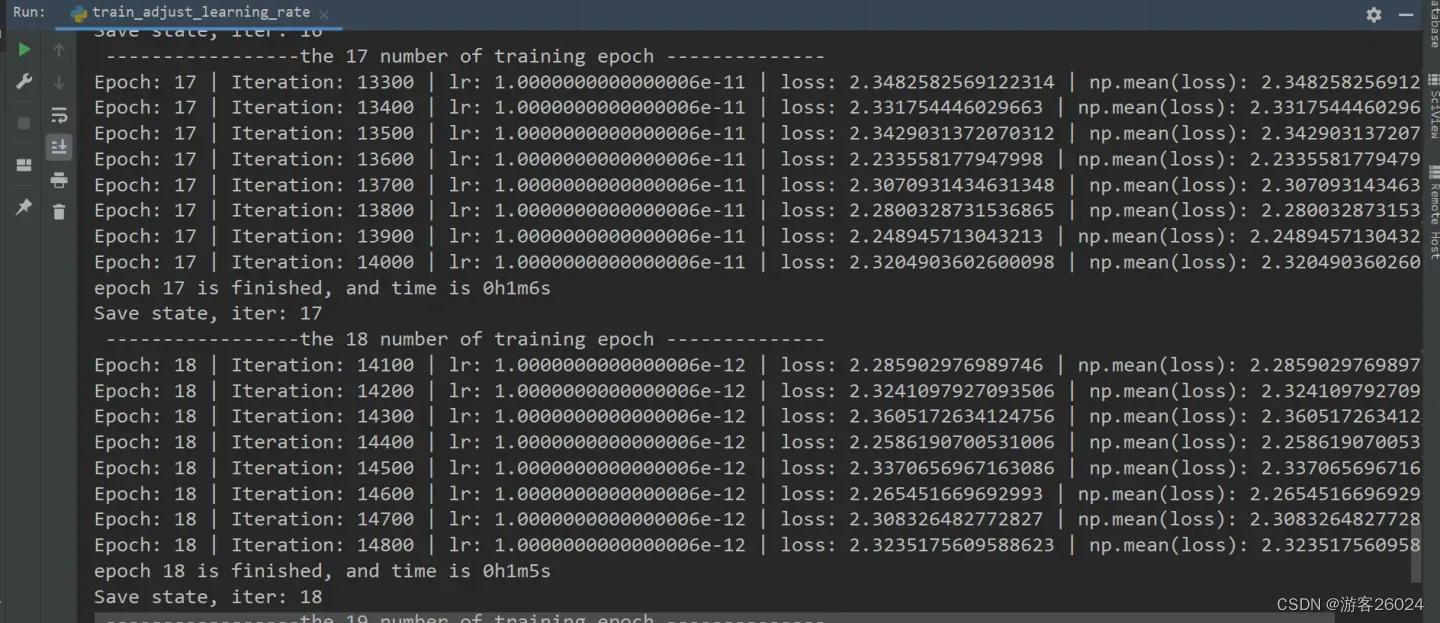
可视化lr与loss: lr(看橙色透明线条)
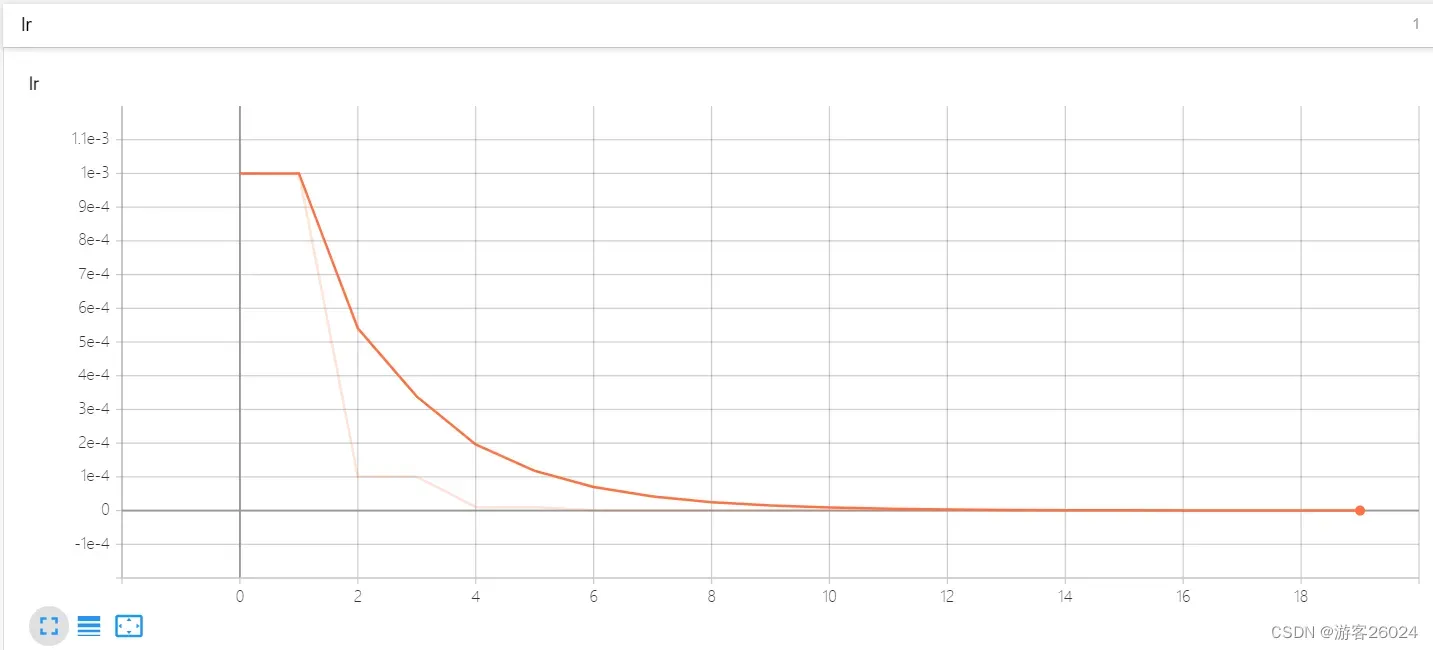
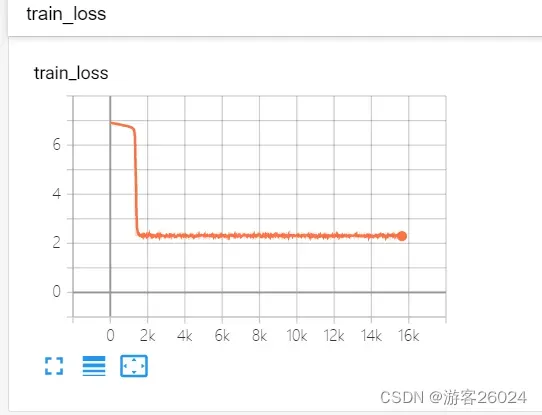
分析:
(1) 从0-1 epoch时,lr为0.001;
(2) 从2-3 epoch时,lr为0.0001;
(3) 从4-5 epoch时,lr为1.0000000000000003e-05;
(4) 从6-7 epoch时,lr为1.0000000000000002e-06;
(5) 从8-9 epoch时,lr为1.0000000000000002e-07;
(6) 从10-11 epoch时,lr为1.0000000000000004e-08;
(7) 从12-13 epoch时,lr为1.0000000000000005e-09;
(8) 从14-15 epoch时,lr为1.0000000000000004e-10;
(9) 从16-17 epoch时,lr为1.0000000000000006e-11;
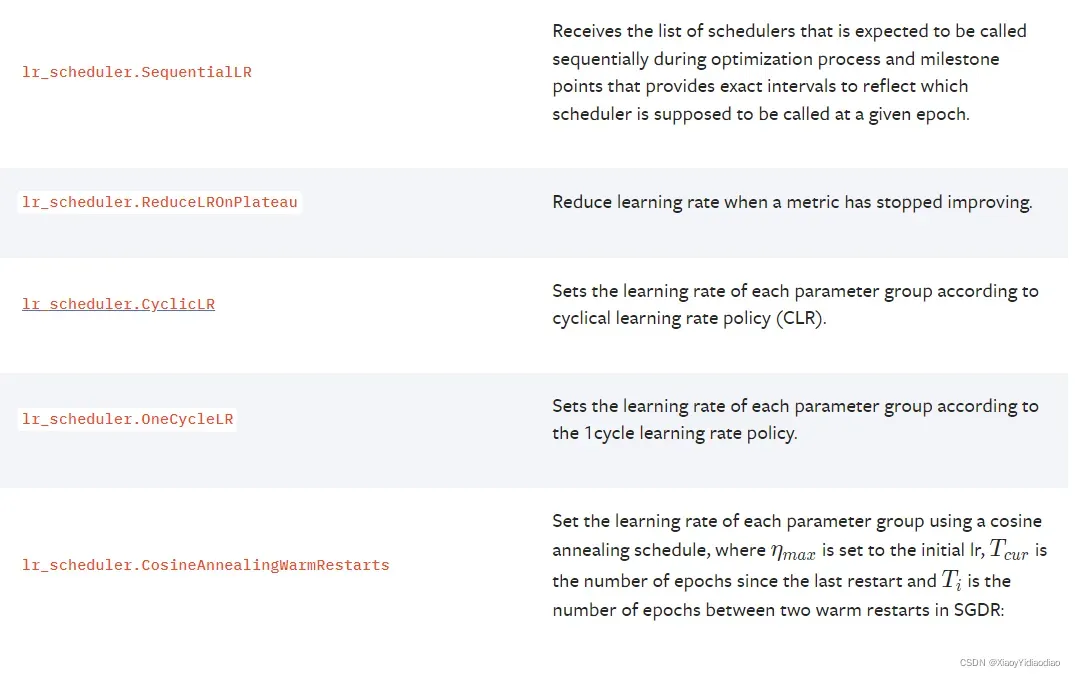
(10) 从18-19 epoch时,lr为1.0000000000000006e-12。2.分区间,分频率衰减学习率:MultiStepLR()
scheduler = torch.optim.lr_scheduler.MultiStepLR(optim, milestones=[5, 10, 15], gamma=0.1, verbose=True)其参数:
def __init__(self, optimizer, milestones, gamma=0.1, last_epoch=-1, verbose=False):optimizer: 需优化的变量
miestones: 分段区域
gamma: 到达分段点之后,乘以gamma
last_epoch=-1: 已经走了多少个epoch,下一个milestone减去last_epoch就是需要的epoch数, 最好别修改
verbose=False: 是否打印
例如
MultiStepLR(optim, milestones=[5, 10, 15], gamma=0.1, verbose=True)
lr=1e-3, len(epoch)=20, milestones=[5, 10, 15], gamma=0.1
epoch <=4, lr=1e-3
5<= epoch <=9, lr=1e-4
10<= epoch <=14, lr=1e-5
15<= epoch <20, lr=1e-6代码:
from torch.utils.data import DataLoader
from torchvision.models import AlexNet
from torchvision import transforms
import torchvision
import torch
from torch import nn
from torch.utils.tensorboard import SummaryWriter
import time
import numpy as np
# 1.Create SummaryWriter
writer = SummaryWriter("tensorboard")
# 2.Ready dataset
train_dataset = torchvision.datasets.CIFAR10(root="data", train=True, transform=transforms.Compose(
[transforms.Resize(227), transforms.ToTensor()]), download=True)
print('CUDA available: {}'.format(torch.cuda.is_available()))
# 3.Length
train_dataset_size = len(train_dataset)
print("the train dataset size is {}".format(train_dataset_size))
# 4.DataLoader
train_dataloader = DataLoader(dataset=train_dataset, batch_size=64)
# 5.Create model
model = AlexNet()
if torch.cuda.is_available():
model = model.cuda()
model = torch.nn.DataParallel(model).cuda()
else:
model = torch.nn.DataParallel(model)
# 6.Create loss
cross_entropy_loss = nn.CrossEntropyLoss()
# 7.Optimizer
learning_rate = 1e-3
optim = torch.optim.SGD(model.parameters(), lr=learning_rate)
scheduler = torch.optim.lr_scheduler.MultiStepLR(optim, milestones=[5, 10, 15], gamma=0.1, verbose=True)
# 8. Set some parameters to control loop
# epoch
epoch = 20
iter = 0
t0 = time.time()
for i in range(epoch):
t1 = time.time()
print(" -----------------the {} number of training epoch --------------".format(i))
model.train()
for data in train_dataloader:
imgs, targets = data
if torch.cuda.is_available():
cross_entropy_loss = cross_entropy_loss.cuda()
imgs, targets = imgs.cuda(), targets.cuda()
outputs = model(imgs)
loss_train = cross_entropy_loss(outputs, targets)
writer.add_scalar("train_loss", loss_train.item(), iter)
optim.zero_grad()
loss_train.backward()
optim.step()
iter = iter + 1
if iter % 100 == 0:
print(
"Epoch: {} | Iteration: {} | lr1: {} | lr2: {} |loss: {} | np.mean(loss): {} "
.format(i, iter, scheduler.get_lr()[0], scheduler.get_last_lr()[0], loss_train.item(),
np.mean(loss_train.item())))
writer.add_scalar("lr", scheduler.get_lr()[0], i)
writer.add_scalar("lr_last", scheduler.get_last_lr()[0], i)
scheduler.step()
t2 = time.time()
h = (t2 - t1) // 3600
m = ((t2 - t1) % 3600) // 60
s = ((t2 - t1) % 3600) % 60
print("epoch {} is finished, and time is {}h{}m{}s".format(i, int(h), int(m), int(s)))
if i % 1 == 0:
print("Save state, iter: {} ".format(i))
torch.save(model.state_dict(), "checkpoint/AlexNet_{}.pth".format(i))
torch.save(model.state_dict(), "checkpoint/AlexNet.pth")
t3 = time.time()
h_t = (t3 - t0) // 3600
m_t = ((t3 - t0) % 3600) // 60
s_t = ((t3 - t0) % 3600) // 60
print("The finished time is {}h{}m{}s".format(int(h_t), int(m_t), int(s_t)))
writer.close()
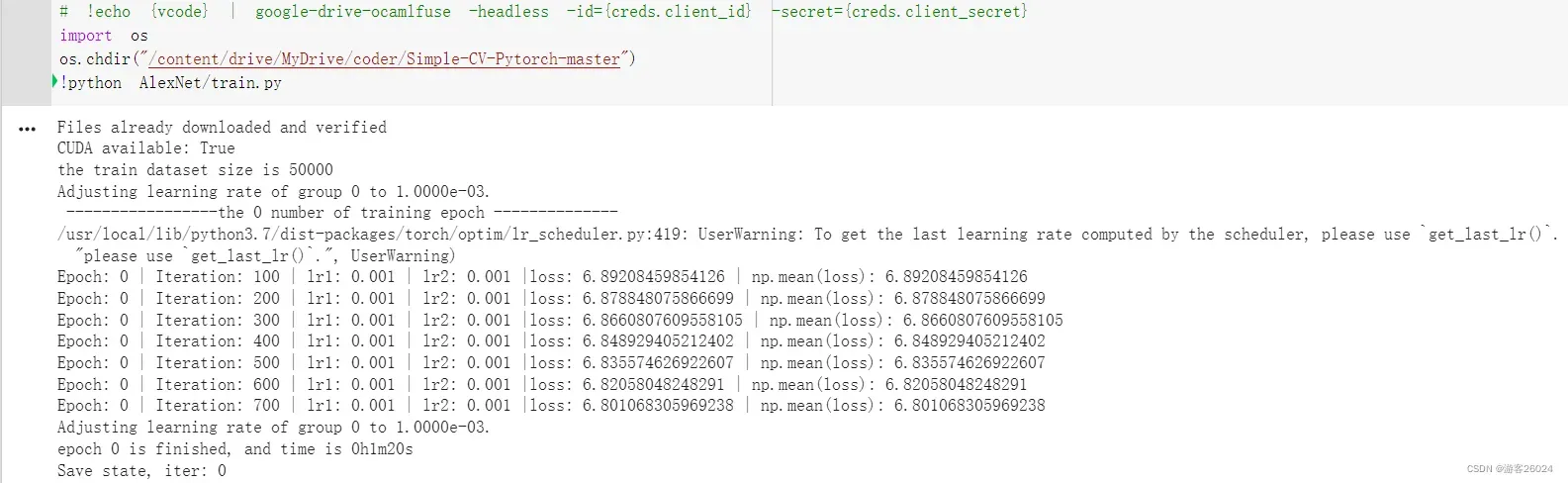
注意:以上程序的运行.ipynb文件为:
import os
os.chdir("/content/drive/MyDrive/coder/Simple-CV-Pytorch-master")
!python AlexNet/train.py也就是说,我们的train.py文件虽然在AlexNet文件夹里,但是此文件base_dir为 /content/drive/MyDrive/coder/Simple-CV-Pytorch-master,所以文件夹data、tensorboard、checkpoint直接使用data、tensorboard、checkpoint不在前面加入返回上一级../data、../tensorboard、../checkpoint。
若想知道如何白嫖谷歌的服务器可看我往期博客:
运行结果:
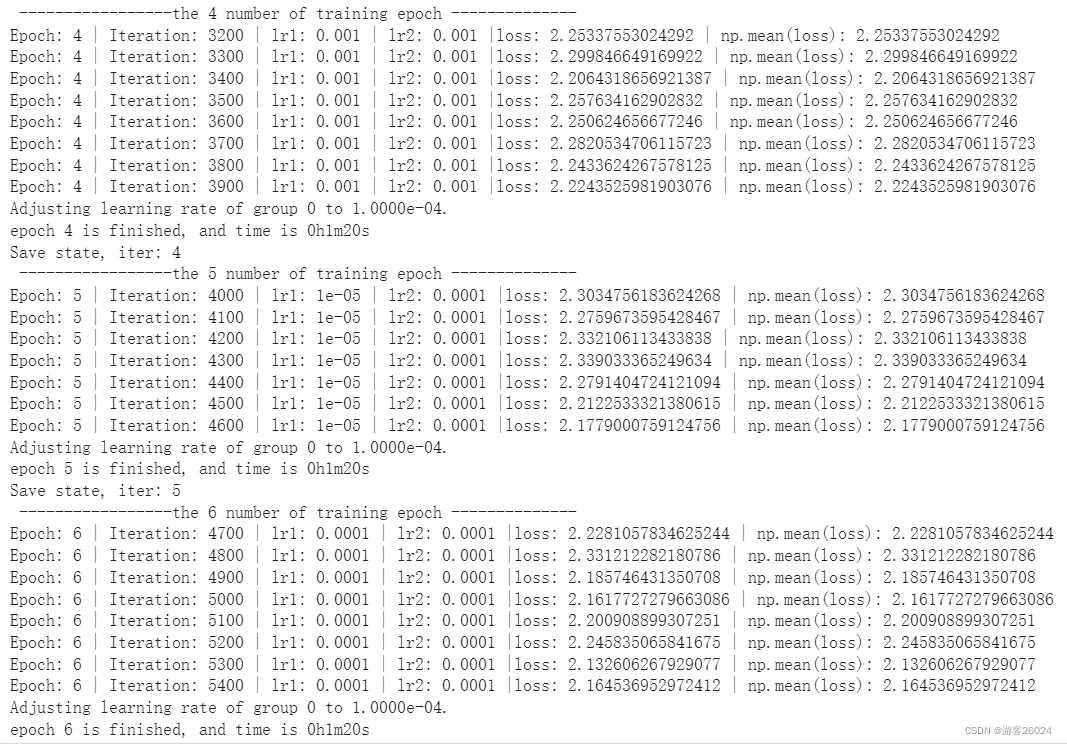


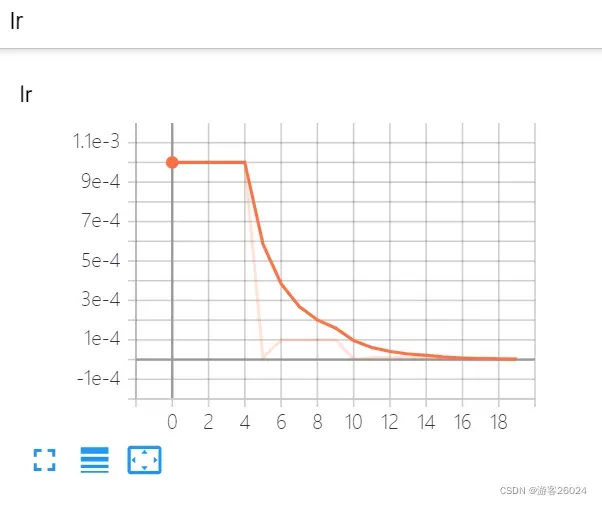
可视化lr与loss:lr(看橙色透明线条)
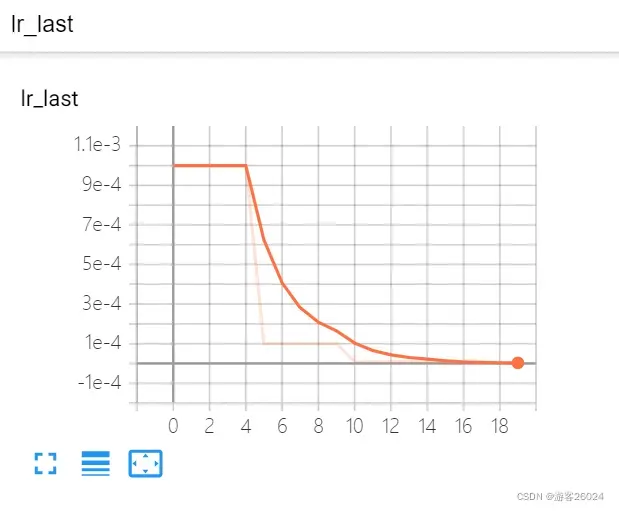
分析:
lr: scheduler.get_lr()[0]
(1) 从 0-4 epoch时,lr为1e-3;
(2) 5 epoch时,lr为1e-5;
(3) 从 6-9 epoch时,lr为1e-4;
(4) 10 epoch时,lr为1e-6;
(5) 从 11-14 epoch时,lr为1e-5;
(6) 15 epoch时,lr为1e-7;
(7) 从 16-19 epoch时,lr为1e-6。lr_last: scheduler.get_last_lr()[0]
(1) 从 0-4 epoch时,lr_last为1e-3;
(2) 从 5-9 epoch时,lr_last为1e-4;
(3) 从 10-14 epoch时,lr_last为1e-5;
(4) 从 15-19 epoch时,lr_last为1e-6;则证明我们真正的学习率显示为:scheduler.get_last_lr()[0]
3.分步长,衰减学习率:StepLR()
scheduler = torch.optim.lr_scheduler.StepLR(optim, step_size=5, gamma=0.2)其参数:
def __init__(self, optimizer, step_size, gamma=0.1, last_epoch=-1, verbose=False):optimizer: 需优化的变量
step_size: 衰减的步长
gamma: 到达此步长之后,乘以gamma
last_epoch=-1: 最好别修改
verbose=False: 是否打印
例如
StepLR(optim, step_size=5, gamma=0.2)
lr=1e-3, len(epoch)=20, step_size=5, gamma=0.2
epoch <5, lr=1e-3
5<= epoch <10, lr=2e-4
10<= epoch <15, lr=4e-5
15<= epoch <20, lr=8e-6代码:
from torch.utils.data import DataLoader
from torchvision.models import AlexNet
from torchvision import transforms
import torchvision
import torch
from torch import nn
from torch.utils.tensorboard import SummaryWriter
import time
import numpy as np
# 1.Create SummaryWriter
writer = SummaryWriter("../tensorboard")
# 2.Ready dataset
train_dataset = torchvision.datasets.CIFAR10(root="../data", train=True, transform=transforms.Compose(
[transforms.Resize(227), transforms.ToTensor()]), download=True)
print('CUDA available: {}'.format(torch.cuda.is_available()))
# 3.Length
train_dataset_size = len(train_dataset)
print("the train dataset size is {}".format(train_dataset_size))
# 4.DataLoader
train_dataloader = DataLoader(dataset=train_dataset, batch_size=64)
# 5.Create model
model = AlexNet()
if torch.cuda.is_available():
model = model.cuda()
model = torch.nn.DataParallel(model).cuda()
else:
model = torch.nn.DataParallel(model)
# 6.Create loss
cross_entropy_loss = nn.CrossEntropyLoss()
# 7.Optimizer
learning_rate = 1e-3
optim = torch.optim.SGD(model.parameters(), lr=learning_rate)
scheduler = torch.optim.lr_scheduler.StepLR(optim, step_size=5, gamma=0.2)
# 8. Set some parameters to control loop
# epoch
epoch = 20
iter = 0
t0 = time.time()
for i in range(epoch):
t1 = time.time()
print(" -----------------the {} number of training epoch --------------".format(i))
model.train()
for data in train_dataloader:
imgs, targets = data
if torch.cuda.is_available():
cross_entropy_loss = cross_entropy_loss.cuda()
imgs, targets = imgs.cuda(), targets.cuda()
outputs = model(imgs)
loss_train = cross_entropy_loss(outputs, targets)
writer.add_scalar("train_loss", loss_train.item(), iter)
optim.zero_grad()
loss_train.backward()
optim.step()
iter = iter + 1
if iter % 100 == 0:
print(
"Epoch: {} | Iteration: {} | lr: {} | loss: {} | np.mean(loss): {} "
.format(i, iter, scheduler.get_last_lr()[0], loss_train.item(),
np.mean(loss_train.item())))
writer.add_scalar("lr", scheduler.get_last_lr()[0], i)
scheduler.step()
t2 = time.time()
h = (t2 - t1) // 3600
m = ((t2 - t1) % 3600) // 60
s = ((t2 - t1) % 3600) % 60
print("epoch {} is finished, and time is {}h{}m{}s".format(i, int(h), int(m), int(s)))
if i % 1 == 0:
print("Save state, iter: {} ".format(i))
torch.save(model.state_dict(), "../checkpoint/AlexNet_{}.pth".format(i))
torch.save(model.state_dict(), "../checkpoint/AlexNet.pth")
t3 = time.time()
h_t = (t3 - t0) // 3600
m_t = ((t3 - t0) % 3600) // 60
s_t = ((t3 - t0) % 3600) // 60
print("The finished time is {}h{}m{}s".format(int(h_t), int(m_t), int(s_t)))
writer.close()注意:以上程序直接使用Pycharm上运行。(谷歌GPU服务器的时常用完了)
我们的train.py文件在AlexNet文件夹里,文件夹data、tensorboard、checkpoint与AlexNet文件夹平级,所以使用data、tensorboard、checkpoint在前面加入返回上一级../data、../tensorboard、../checkpoint。
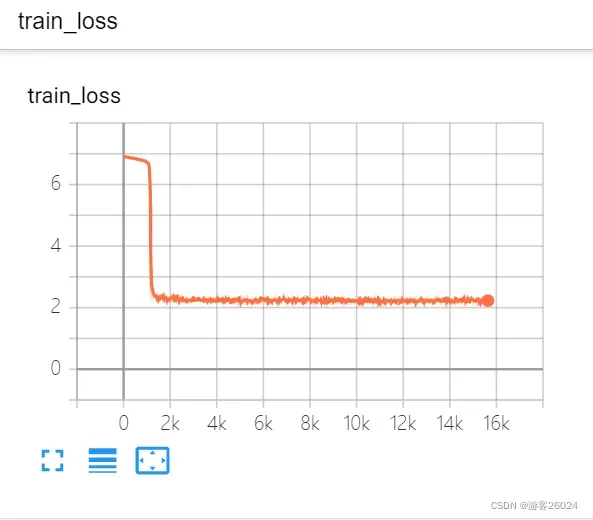
运行结果:
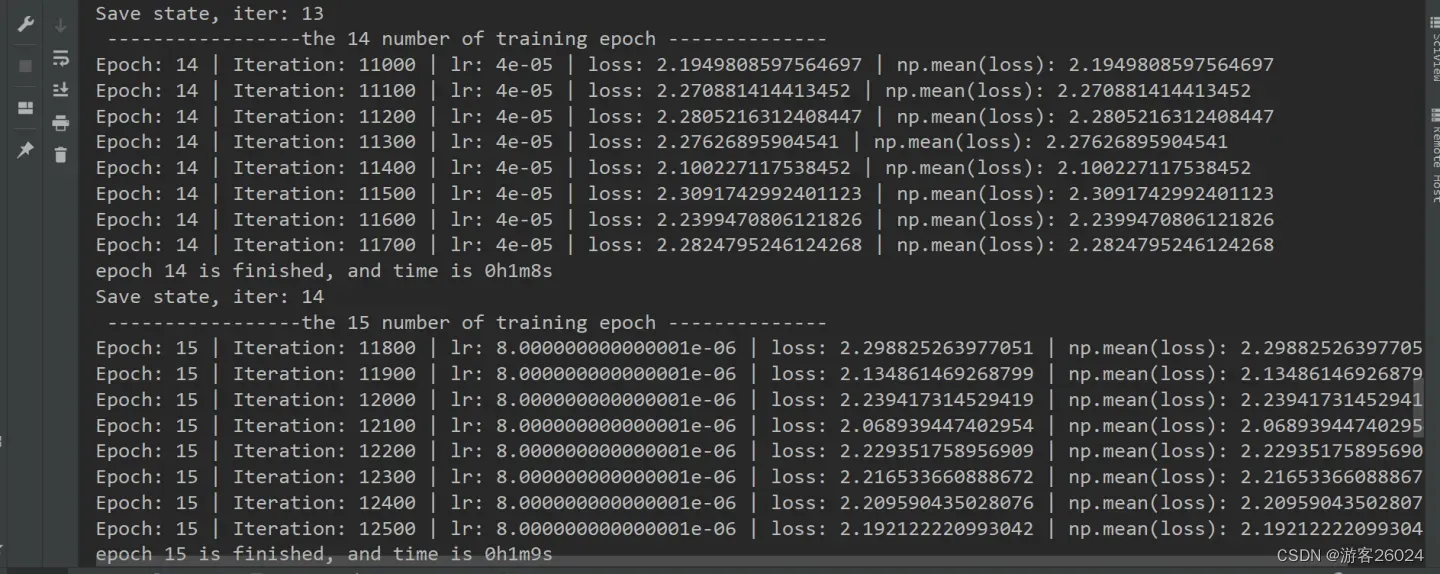
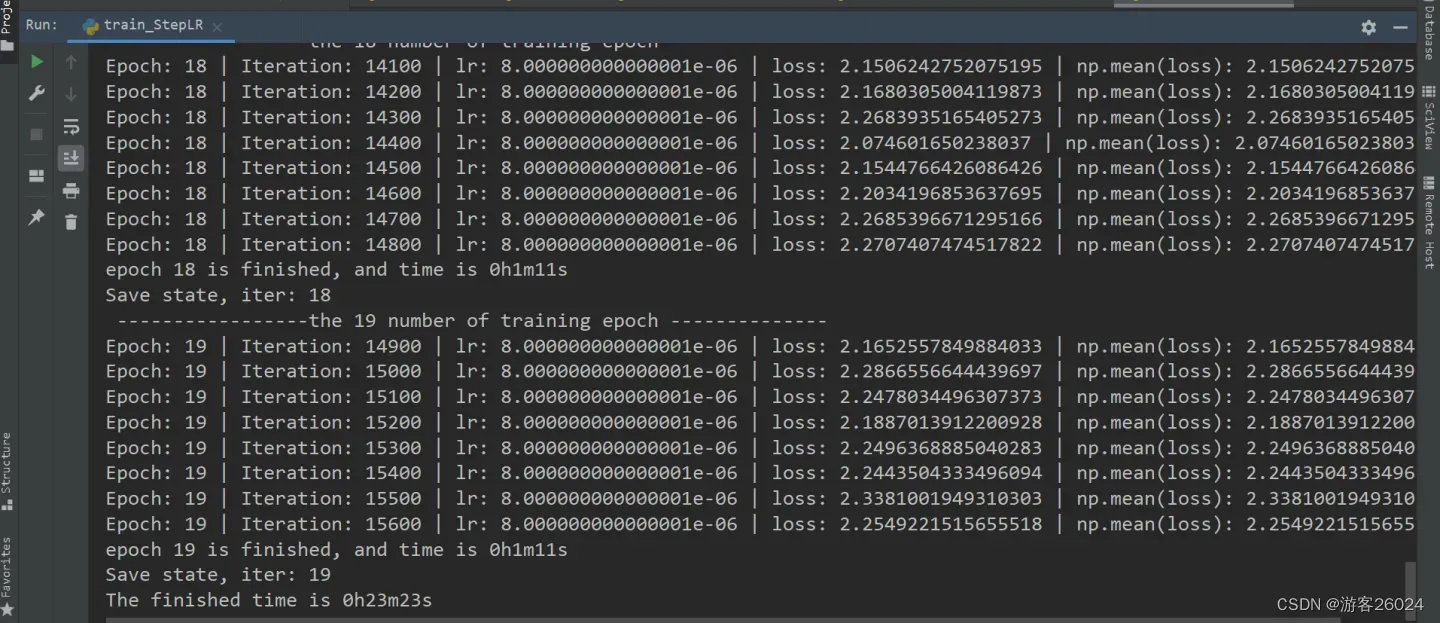
可视化lr与loss: lr(看橙色透明线条):
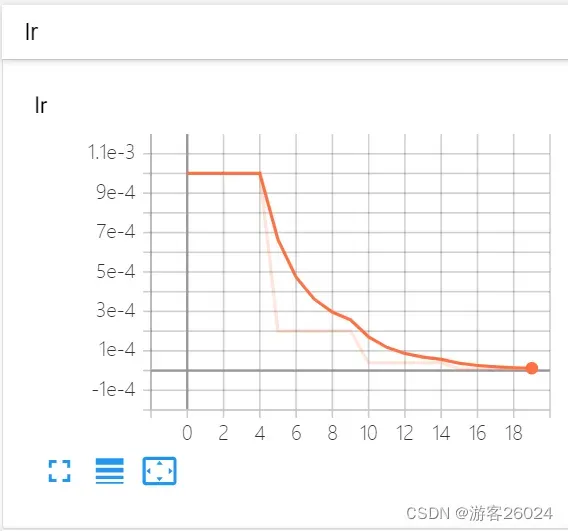
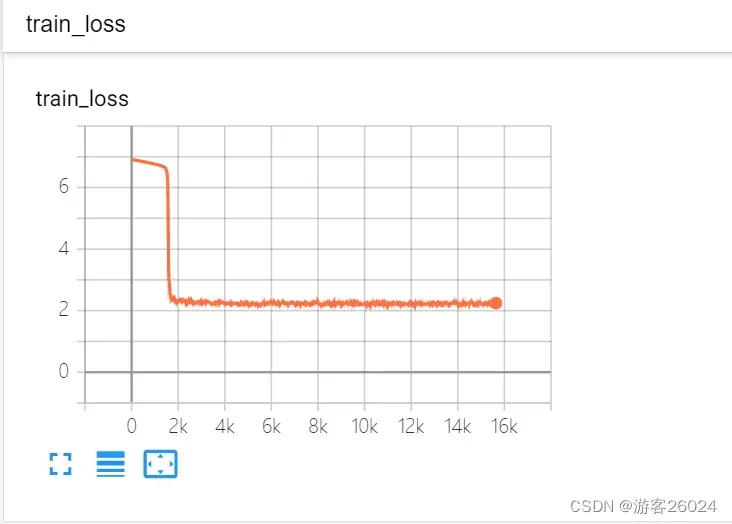
分析:
lr_last: scheduler.get_last_lr()[0]
(1) 从 0-4 epoch时,lr_last为1e-3;
(2) 从 5-9 epoch时,lr_last为2e-4;
(3) 从 10-14 epoch时,lr_last为4e-5;
(4) 从 15-19 epoch时,lr_last为8e-6;
4.匿名调整学习率:LambdaLR()
lambda1 = lambda epoch: (epoch) // 2
scheduler = torch.optim.lr_scheduler.LambdaLR(optim, lr_lambda=lambda1)其参数:
def __init__(self, optimizer, lr_lambda, last_epoch=-1, verbose=False):optimizer: 需优化的变量
lr_lambda: 函数或者函数列表
last_epoch=-1: 最好别修改
verbose=False: 是否打印
例如
new_lr=lr_lambda(epoch) * initial_lr
lambda1 = lambda epoch: epoch // 2
LambdaLR(optimizer, lr_lambda=lambda1, last_epoch=-1)
当epoch=0时,new_lr = (0 // 2) * 0.001 = 0 * 0.001 = 0
当epoch=1时,new_lr = (1 // 2) * 0.001 = 0 * 0.001 = 0
当epoch=2时,new_lr = (2 // 2) * 0.001 = 1 * 0.001 = 0.001
当epoch=3时,new_lr = (3 // 2) * 0.001 = 1 * 0.001 = 0.001
当epoch=4时,new_lr = (4 // 2) * 0.001 = 2 * 0.001 = 0.002
...代码:
from torch.utils.data import DataLoader
from torchvision.models import AlexNet
from torchvision import transforms
import torchvision
import torch
from torch import nn
from torch.utils.tensorboard import SummaryWriter
import time
import numpy as np
# 1.Create SummaryWriter
writer = SummaryWriter("../tensorboard")
# 2.Ready dataset
train_dataset = torchvision.datasets.CIFAR10(root="../data", train=True, transform=transforms.Compose(
[transforms.Resize(227), transforms.ToTensor()]), download=True)
print('CUDA available: {}'.format(torch.cuda.is_available()))
# 3.Length
train_dataset_size = len(train_dataset)
print("the train dataset size is {}".format(train_dataset_size))
# 4.DataLoader
train_dataloader = DataLoader(dataset=train_dataset, batch_size=64)
# 5.Create model
model = AlexNet()
if torch.cuda.is_available():
model = model.cuda()
model = torch.nn.DataParallel(model).cuda()
else:
model = torch.nn.DataParallel(model)
# 6.Create loss
cross_entropy_loss = nn.CrossEntropyLoss()
# 7.Optimizer
learning_rate = 1e-3
optim = torch.optim.SGD(model.parameters(), lr=learning_rate)
lambda1 = lambda epoch: (epoch) // 2
scheduler = torch.optim.lr_scheduler.LambdaLR(optim, lr_lambda=lambda1)
# 8. Set some parameters to control loop
# epoch
epoch = 20
iter = 0
t0 = time.time()
for i in range(epoch):
t1 = time.time()
print(" -----------------the {} number of training epoch --------------".format(i))
model.train()
for data in train_dataloader:
imgs, targets = data
if torch.cuda.is_available():
cross_entropy_loss = cross_entropy_loss.cuda()
imgs, targets = imgs.cuda(), targets.cuda()
outputs = model(imgs)
loss_train = cross_entropy_loss(outputs, targets)
writer.add_scalar("train_loss", loss_train.item(), iter)
optim.zero_grad()
loss_train.backward()
optim.step()
iter = iter + 1
if iter % 100 == 0:
print(
"Epoch: {} | Iteration: {} | lr: {} | loss: {} | np.mean(loss): {} "
.format(i, iter, optim.param_groups[0]['lr'], loss_train.item(),
np.mean(loss_train.item())))
writer.add_scalar("lr", optim.param_groups[0]['lr'], i)
scheduler.step()
t2 = time.time()
h = (t2 - t1) // 3600
m = ((t2 - t1) % 3600) // 60
s = ((t2 - t1) % 3600) % 60
print("epoch {} is finished, and time is {}h{}m{}s".format(i, int(h), int(m), int(s)))
if i % 1 == 0:
print("Save state, iter: {} ".format(i))
torch.save(model.state_dict(), "../checkpoint/AlexNet_{}.pth".format(i))
torch.save(model.state_dict(), "../checkpoint/AlexNet.pth")
t3 = time.time()
h_t = (t3 - t0) // 3600
m_t = ((t3 - t0) % 3600) // 60
s_t = ((t3 - t0) % 3600) // 60
print("The finished time is {}h{}m{}s".format(int(h_t), int(m_t), int(s_t)))
writer.close()运行结果:
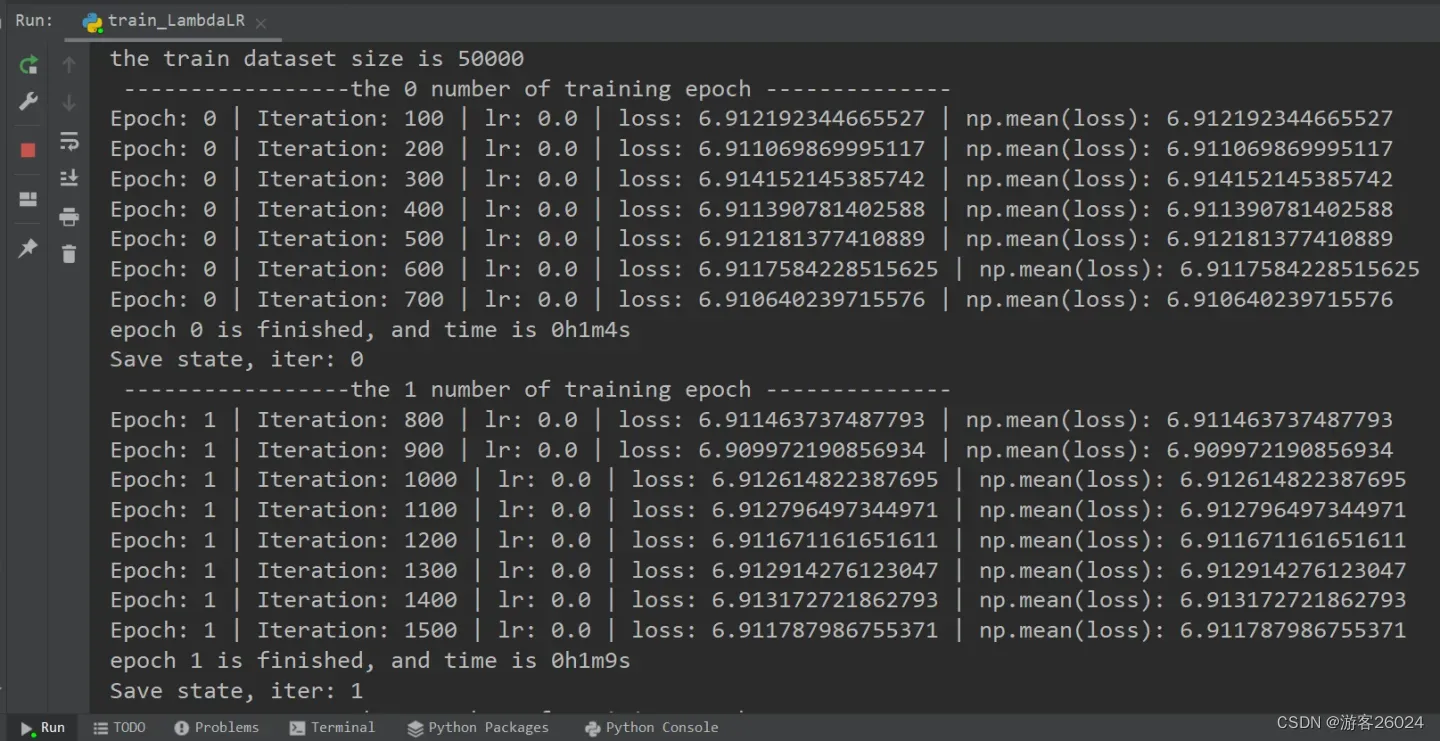
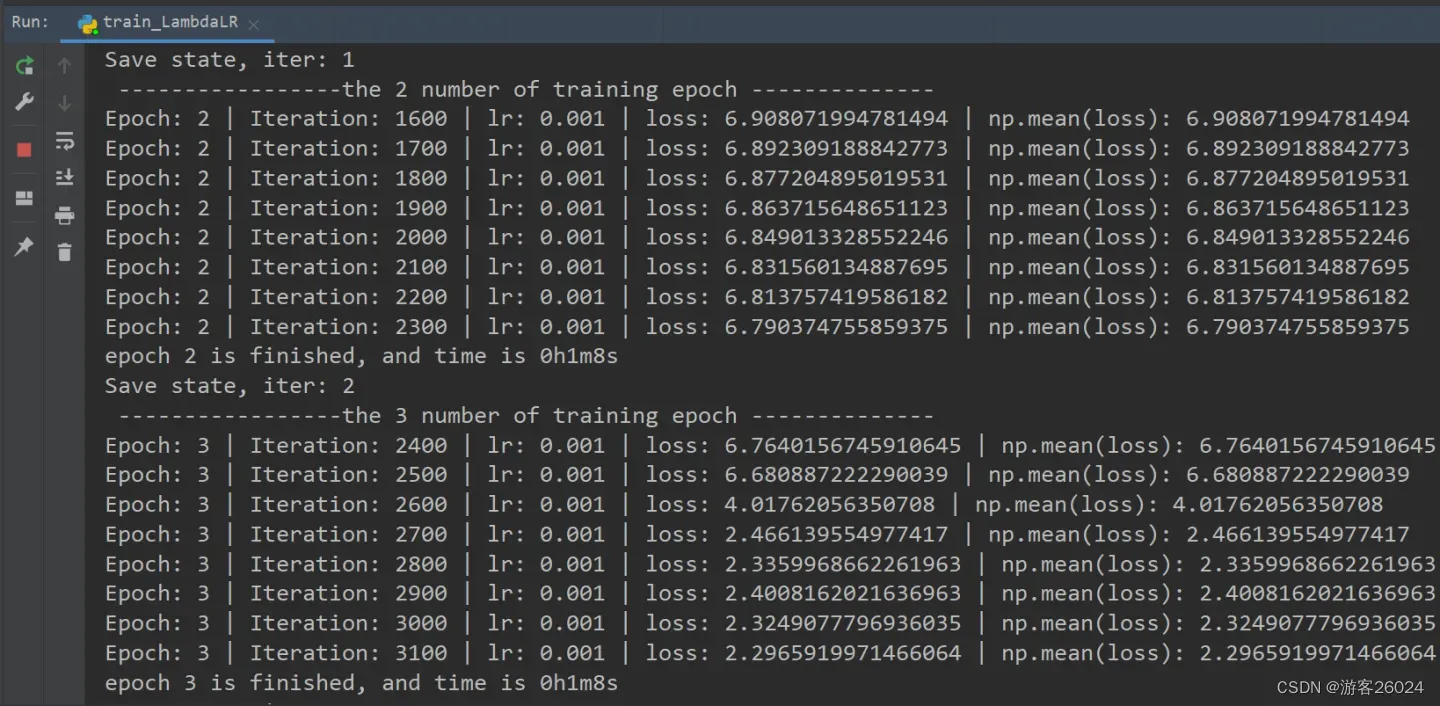
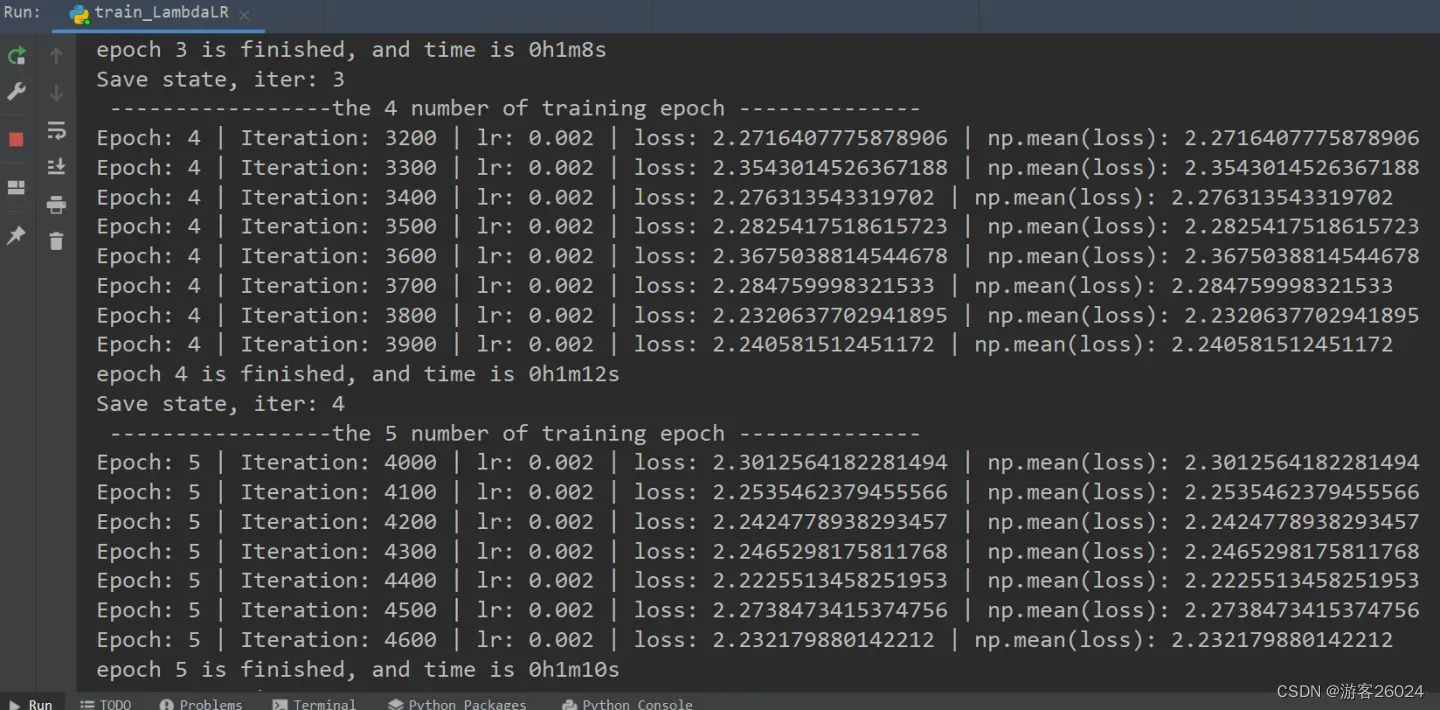
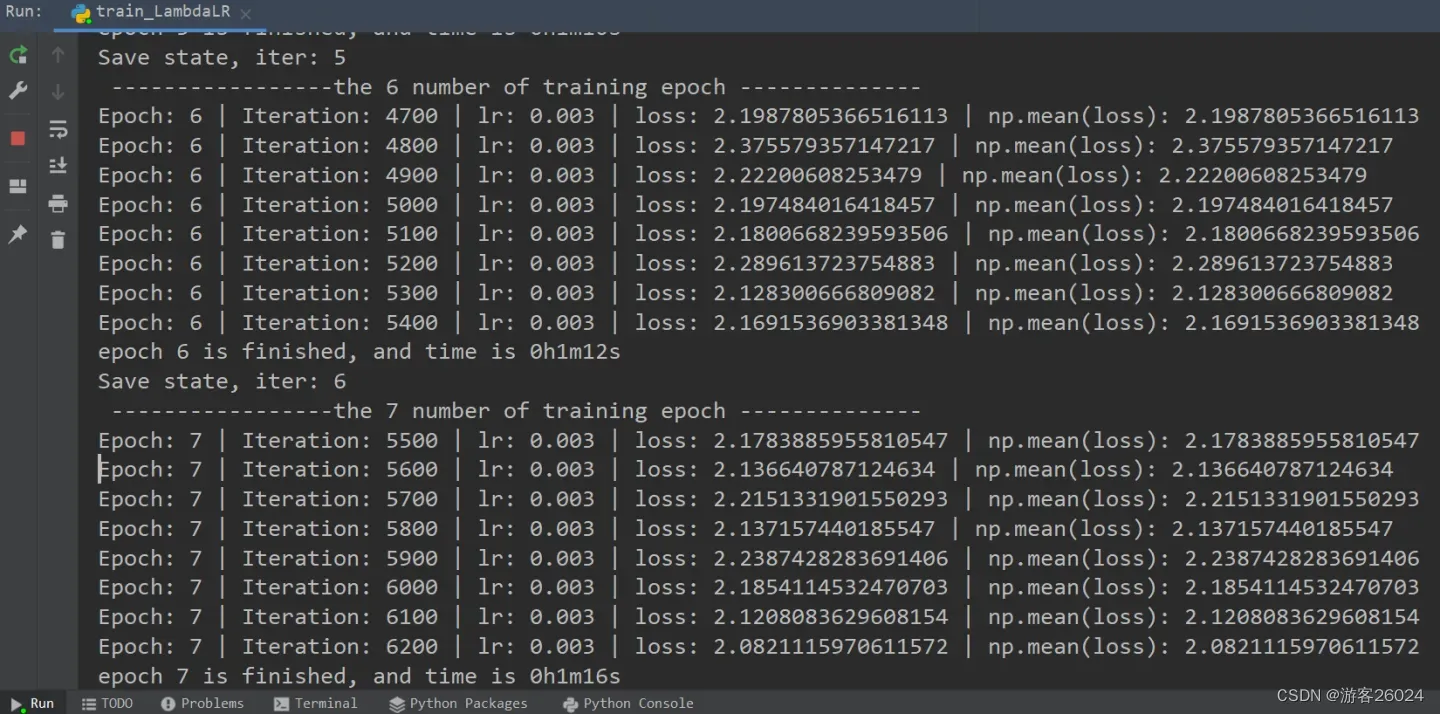

可视化lr与loss:
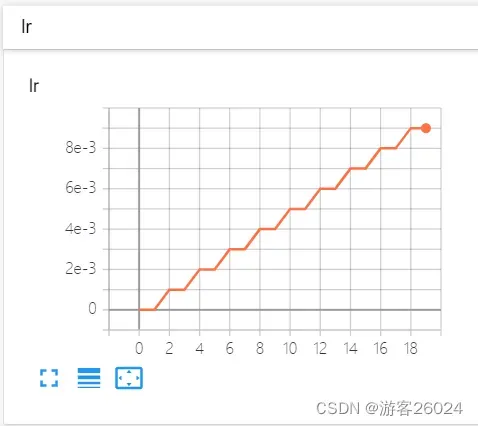
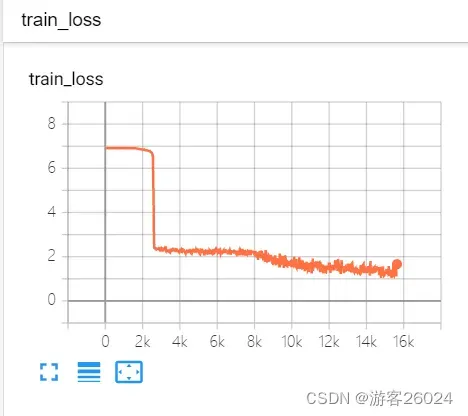
分析:
new_lr=lr_lambda(epoch) * initial_lr
lambda1 = lambda epoch: epoch // 2
LambdaLR(optimizer, lr_lambda=lambda1, last_epoch=-1)
当epoch=0时,new_lr = (0 // 2) * 0.001 = 0 * 0.001 = 0
当epoch=1时,new_lr = (1 // 2) * 0.001 = 0 * 0.001 = 0
当epoch=2时,new_lr = (2 // 2) * 0.001 = 1 * 0.001 = 0.001
当epoch=3时,new_lr = (3 // 2) * 0.001 = 1 * 0.001 = 0.001
当epoch=4时,new_lr = (4 // 2) * 0.001 = 2 * 0.001 = 0.002
当epoch=5时,new_lr = (5 // 2) * 0.001 = 2 * 0.001 = 0.002
当epoch=6时,new_lr = (6 // 2) * 0.001 = 3 * 0.001 = 0.003
当epoch=7时,new_lr = (7 // 2) * 0.001 = 3 * 0.001 = 0.003
当epoch=8时,new_lr = (8 // 2) * 0.001 = 4 * 0.001 = 0.004
当epoch=9时,new_lr = (9 // 2) * 0.001 = 4 * 0.001 = 0.004
当epoch=10时,new_lr = (10 // 2) * 0.001 = 5 * 0.001 = 0.005
当epoch=11时,new_lr = (11 // 2) * 0.001 = 5 * 0.001 = 0.005
当epoch=12时,new_lr = (12 // 2) * 0.001 = 6 * 0.001 = 0.006
当epoch=13时,new_lr = (13 // 2) * 0.001 = 6 * 0.001 = 0.006
当epoch=14时,new_lr = (14 // 2) * 0.001 = 7 * 0.001 = 0.007
当epoch=15时,new_lr = (15 // 2) * 0.001 = 7 * 0.001 = 0.007
当epoch=16时,new_lr = (16 // 2) * 0.001 = 8 * 0.001 = 0.008
当epoch=17时,new_lr = (17 // 2) * 0.001 = 8 * 0.001 = 0.008
当epoch=18时,new_lr = (18 // 2) * 0.001 = 9 * 0.001 = 0.009
当epoch=19时,new_lr = (19 // 2) * 0.001 = 9 * 0.001 = 0.0095.自适应调整学习率:ReduceLROnPlateau()
该策略能够读取模型的性能指标,当该指标停止改善时,持续关注(patience)几个epochs之后,自动减小学习率。
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optim, patience=3, verbose=True)
scheduler.step(np.mean(loss))其参数:
def __init__(self, optimizer, mode='min', factor=0.1, patience=10,
threshold=1e-4, threshold_mode='rel', cooldown=0,
min_lr=0, eps=1e-8, verbose=False):optimizer: 需优化的变量
mode: min表示指标不再减小(loss)时降低学习率,max表示指标不再增加(accuracy)时降低学习率
factor: 学习率改变的因子new_lr = lr * factor, 默认情况下为0.1
patience: 观察几个epoch之后降低学习率,默认情况下10个epoch降低学习率
threshold: 只关注超过阈值的显著变化,默认情况下为1e-4
threshold_mode: 有rel和abs两种阈值计算模式;
rel规则:max模式下如果超过best(1+threshold)为显著,min模式下如果低于best(1-threshold)为显著;
abs规则:max模式下如果超过best+threshold为显著,min模式下如果低于best-threshold为显著
cooldown: 触发一次条件后,等待一定epoch再进行检测,避免lr下降过速,默认情况下为0
min_lr=0: 学习率的下限,默认情况下为0
eps=1e-8: 新旧学习率之间的差异小于eps,则忽略更新,默认值情况下为1e-8
verbose=False: 是否打印
例如
ReduceLROnPlateau(optim, patience=3, verbose=True)
loss停止改善时,持续关注(patience)3个epochs之后,自动减小学习率代码:
from torch.utils.data import DataLoader
from torchvision.models import AlexNet
from torchvision import transforms
import torchvision
import torch
from torch import nn
from torch.utils.tensorboard import SummaryWriter
import time
import numpy as np
# 1.Create SummaryWriter
writer = SummaryWriter("../tensorboard")
# 2.Ready dataset
train_dataset = torchvision.datasets.CIFAR10(root="../data", train=True, transform=transforms.Compose(
[transforms.Resize(227), transforms.ToTensor()]), download=True)
print('CUDA available: {}'.format(torch.cuda.is_available()))
# 3.Length
train_dataset_size = len(train_dataset)
print("the train dataset size is {}".format(train_dataset_size))
# 4.DataLoader
train_dataloader = DataLoader(dataset=train_dataset, batch_size=64)
# 5.Create model
model = AlexNet()
if torch.cuda.is_available():
model = model.cuda()
model = torch.nn.DataParallel(model).cuda()
else:
model = torch.nn.DataParallel(model)
# 6.Create loss
cross_entropy_loss = nn.CrossEntropyLoss()
# 7.Optimizer
learning_rate = 1e-3
optim = torch.optim.SGD(model.parameters(), lr=learning_rate)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optim, patience=3, verbose=True)
# 8. Set some parameters to control loop
# epoch
epoch = 20
iter = 0
t0 = time.time()
for i in range(epoch):
t1 = time.time()
print(" -----------------the {} number of training epoch --------------".format(i))
model.train()
for data in train_dataloader:
loss = 0
imgs, targets = data
if torch.cuda.is_available():
cross_entropy_loss = cross_entropy_loss.cuda()
imgs, targets = imgs.cuda(), targets.cuda()
outputs = model(imgs)
loss_train = cross_entropy_loss(outputs, targets)
loss = loss_train.item() + loss
writer.add_scalar("train_loss", loss_train.item(), iter)
optim.zero_grad()
loss_train.backward()
optim.step()
iter = iter + 1
if iter % 100 == 0:
print(
"Epoch: {} | Iteration: {} | lr: {} | loss: {} | np.mean(loss): {} "
.format(i, iter, optim.param_groups[0]['lr'], loss_train.item(),
np.mean(loss)))
writer.add_scalar("lr", optim.param_groups[0]['lr'], i)
scheduler.step(np.mean(loss))
t2 = time.time()
h = (t2 - t1) // 3600
m = ((t2 - t1) % 3600) // 60
s = ((t2 - t1) % 3600) % 60
print("epoch {} is finished, and time is {}h{}m{}s".format(i, int(h), int(m), int(s)))
if i % 1 == 0:
print("Save state, iter: {} ".format(i))
torch.save(model.state_dict(), "../checkpoint/AlexNet_{}.pth".format(i))
torch.save(model.state_dict(), "../checkpoint/AlexNet.pth")
t3 = time.time()
h_t = (t3 - t0) // 3600
m_t = ((t3 - t0) % 3600) // 60
s_t = ((t3 - t0) % 3600) // 60
print("The finished time is {}h{}m{}s".format(int(h_t), int(m_t), int(s_t)))
writer.close()运行结果:
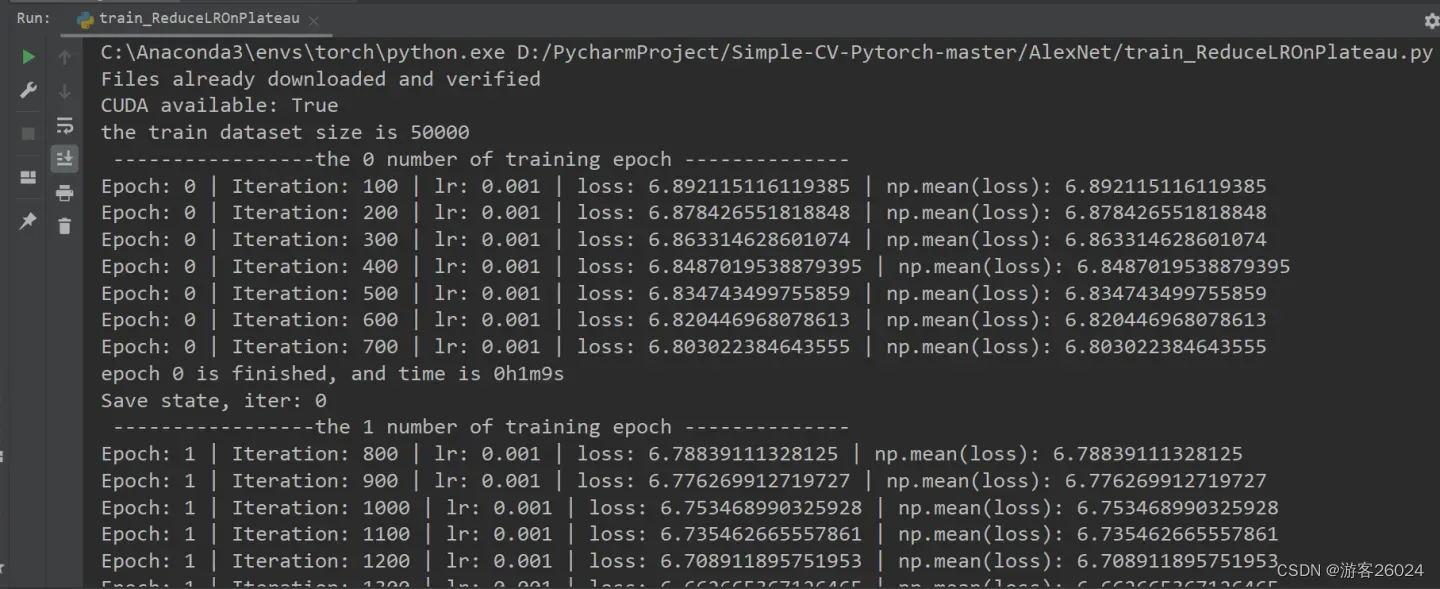
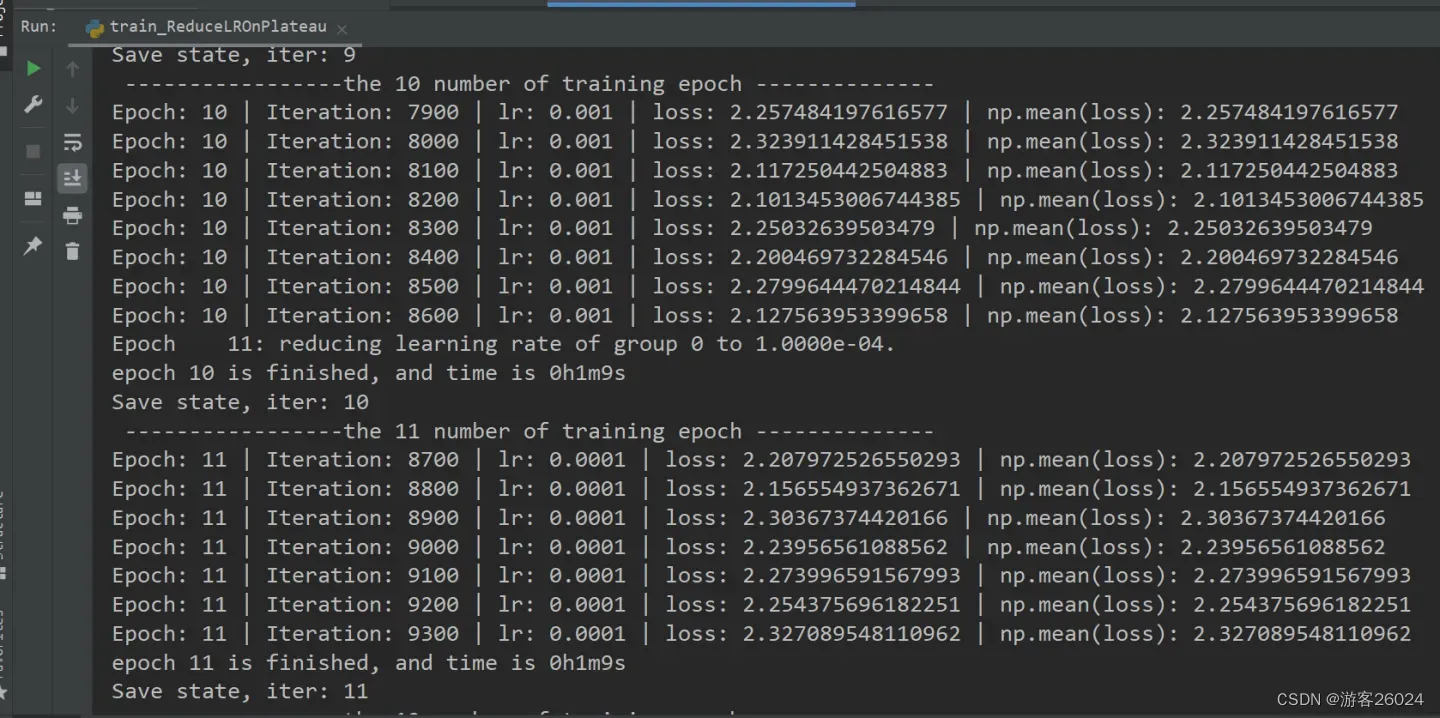
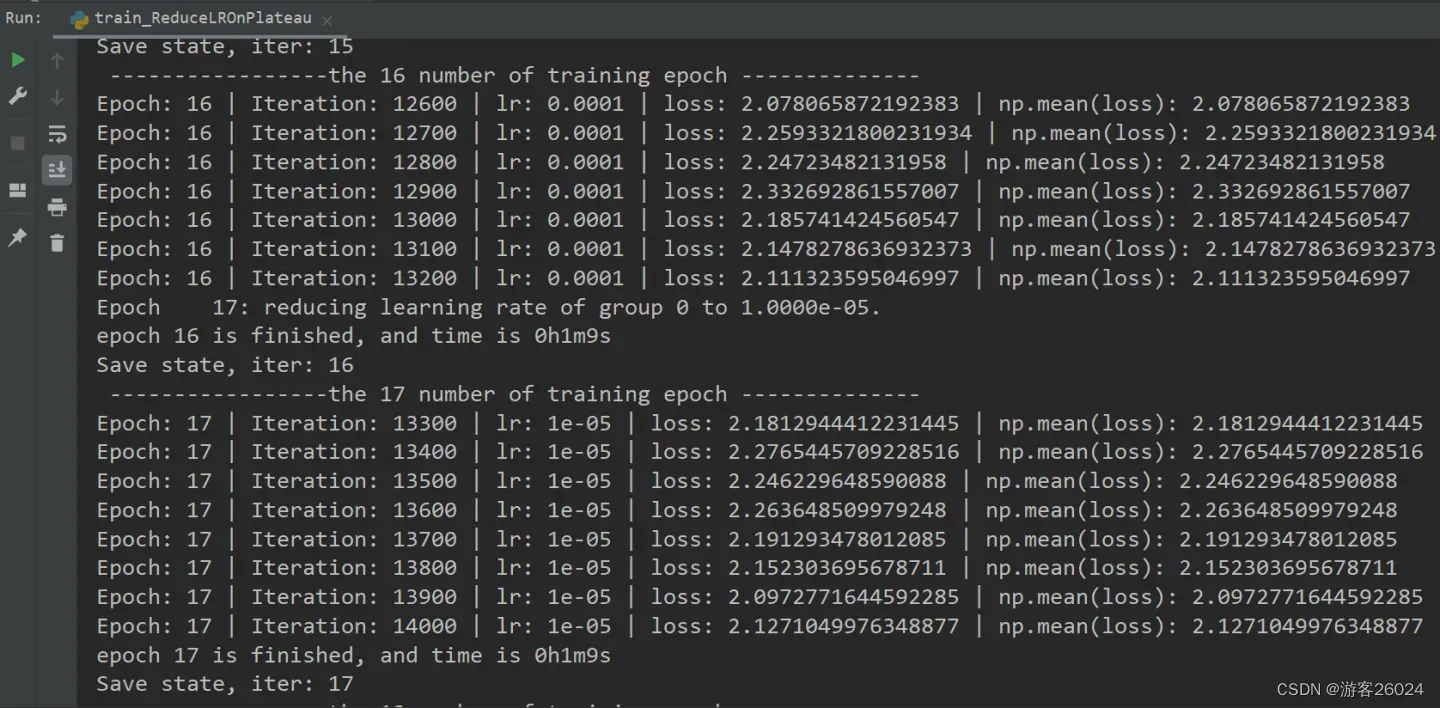
可视化lr与loss: lr(看橙色透明线条):
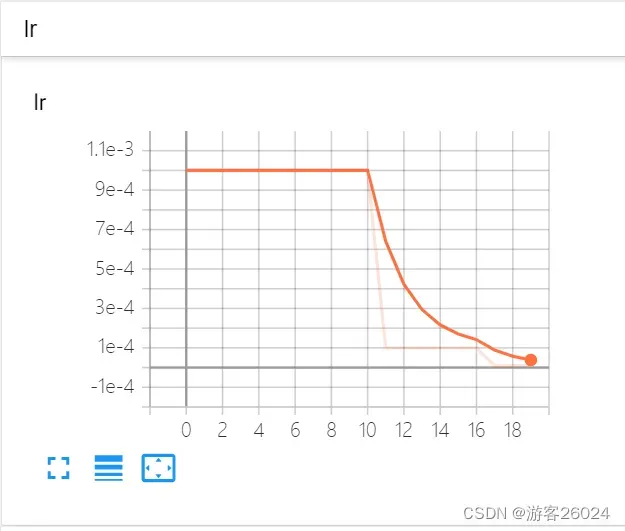
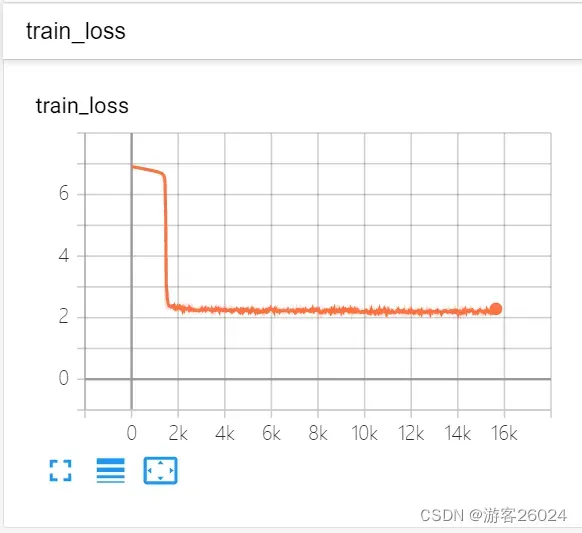
6.指数式调整学习率:ExponentialLR()
scheduler = torch.optim.lr_scheduler.ExponentialLR(optim, gamma=0.2)其参数:
def __init__(self, optimizer, gamma, last_epoch=-1, verbose=False):optimizer: 需优化的变量
gamma: 学习速率衰减的乘法因子
last_epoch=-1: 最好别修改
verbose=False: 是否打印
例如
lr=1e-3,ExponentialLR(optim, gamma=0.2)
new_lr = lr * gamma^(epoch)
当epoch=0时,new_lr = 0.001 * 0.2^0 = 0.001
当epoch=1时,new_lr = 0.001 * 0.2^1 = 0.0002
当epoch=2时,new_lr = 0.001 * 0.2^2 = 4e-5
...代码:
from torch.utils.data import DataLoader
from torchvision.models import AlexNet
from torchvision import transforms
import torchvision
import torch
from torch import nn
from torch.utils.tensorboard import SummaryWriter
import time
import numpy as np
# 1.Create SummaryWriter
writer = SummaryWriter("../tensorboard")
# 2.Ready dataset
train_dataset = torchvision.datasets.CIFAR10(root="../data", train=True, transform=transforms.Compose(
[transforms.Resize(227), transforms.ToTensor()]), download=True)
print('CUDA available: {}'.format(torch.cuda.is_available()))
# 3.Length
train_dataset_size = len(train_dataset)
print("the train dataset size is {}".format(train_dataset_size))
# 4.DataLoader
train_dataloader = DataLoader(dataset=train_dataset, batch_size=64)
# 5.Create model
model = AlexNet()
if torch.cuda.is_available():
model = model.cuda()
model = torch.nn.DataParallel(model).cuda()
else:
model = torch.nn.DataParallel(model)
# 6.Create loss
cross_entropy_loss = nn.CrossEntropyLoss()
# 7.Optimizer
learning_rate = 1e-3
optim = torch.optim.SGD(model.parameters(), lr=learning_rate)
scheduler = torch.optim.lr_scheduler.ExponentialLR(optim, gamma=0.2)
# 8. Set some parameters to control loop
# epoch
epoch = 20
iter = 0
t0 = time.time()
for i in range(epoch):
t1 = time.time()
print(" -----------------the {} number of training epoch --------------".format(i))
model.train()
for data in train_dataloader:
imgs, targets = data
if torch.cuda.is_available():
cross_entropy_loss = cross_entropy_loss.cuda()
imgs, targets = imgs.cuda(), targets.cuda()
outputs = model(imgs)
loss_train = cross_entropy_loss(outputs, targets)
writer.add_scalar("train_loss", loss_train.item(), iter)
optim.zero_grad()
loss_train.backward()
optim.step()
iter = iter + 1
if iter % 100 == 0:
print(
"Epoch: {} | Iteration: {} | lr: {} | loss: {} | np.mean(loss): {} "
.format(i, iter, optim.param_groups[0]['lr'], loss_train.item(),
np.mean(loss_train.item())))
writer.add_scalar("lr", optim.param_groups[0]['lr'], i)
scheduler.step()
t2 = time.time()
h = (t2 - t1) // 3600
m = ((t2 - t1) % 3600) // 60
s = ((t2 - t1) % 3600) % 60
print("epoch {} is finished, and time is {}h{}m{}s".format(i, int(h), int(m), int(s)))
if i % 1 == 0:
print("Save state, iter: {} ".format(i))
torch.save(model.state_dict(), "../checkpoint/AlexNet_{}.pth".format(i))
torch.save(model.state_dict(), "../checkpoint/AlexNet.pth")
t3 = time.time()
h_t = (t3 - t0) // 3600
m_t = ((t3 - t0) % 3600) // 60
s_t = ((t3 - t0) % 3600) // 60
print("The finished time is {}h{}m{}s".format(int(h_t), int(m_t), int(s_t)))
writer.close()运行结果:
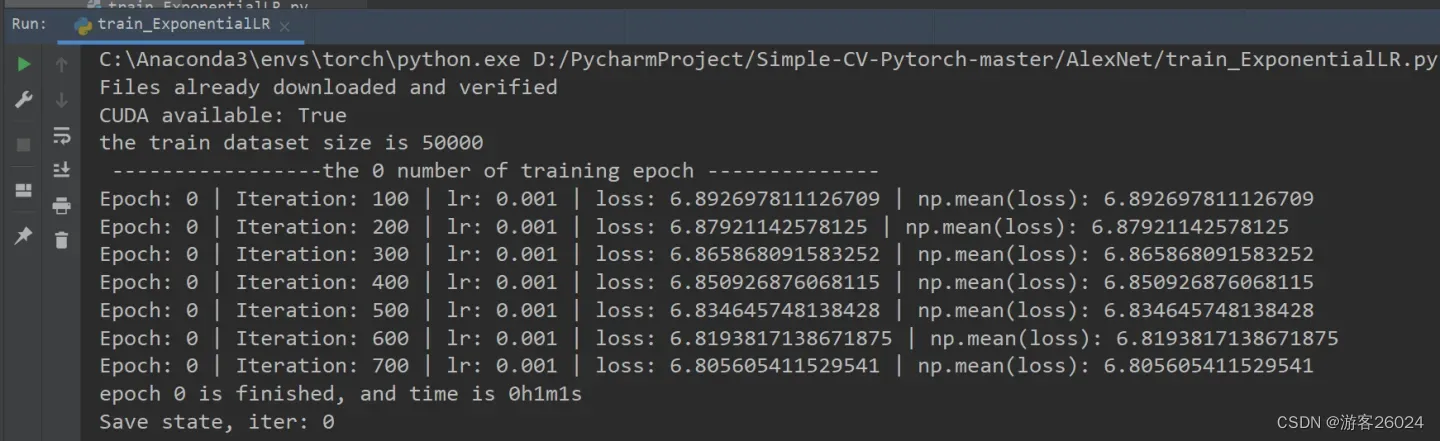
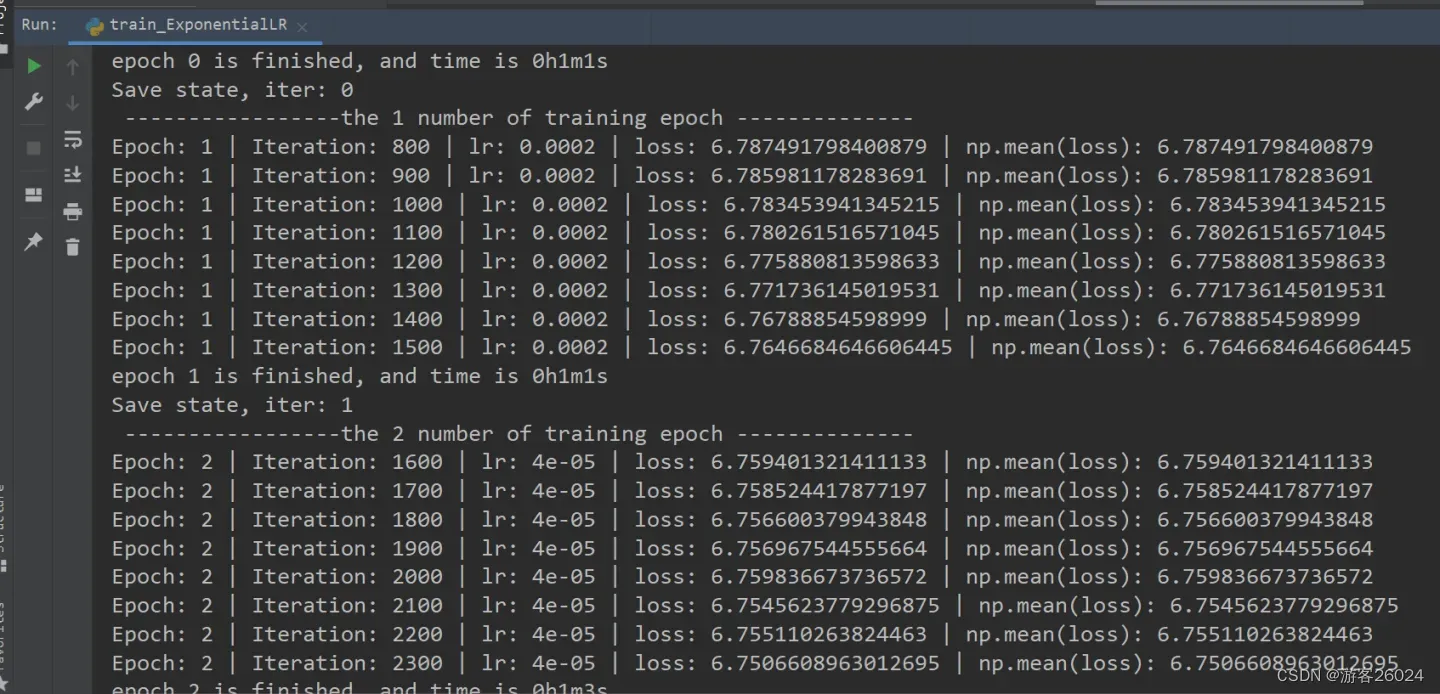
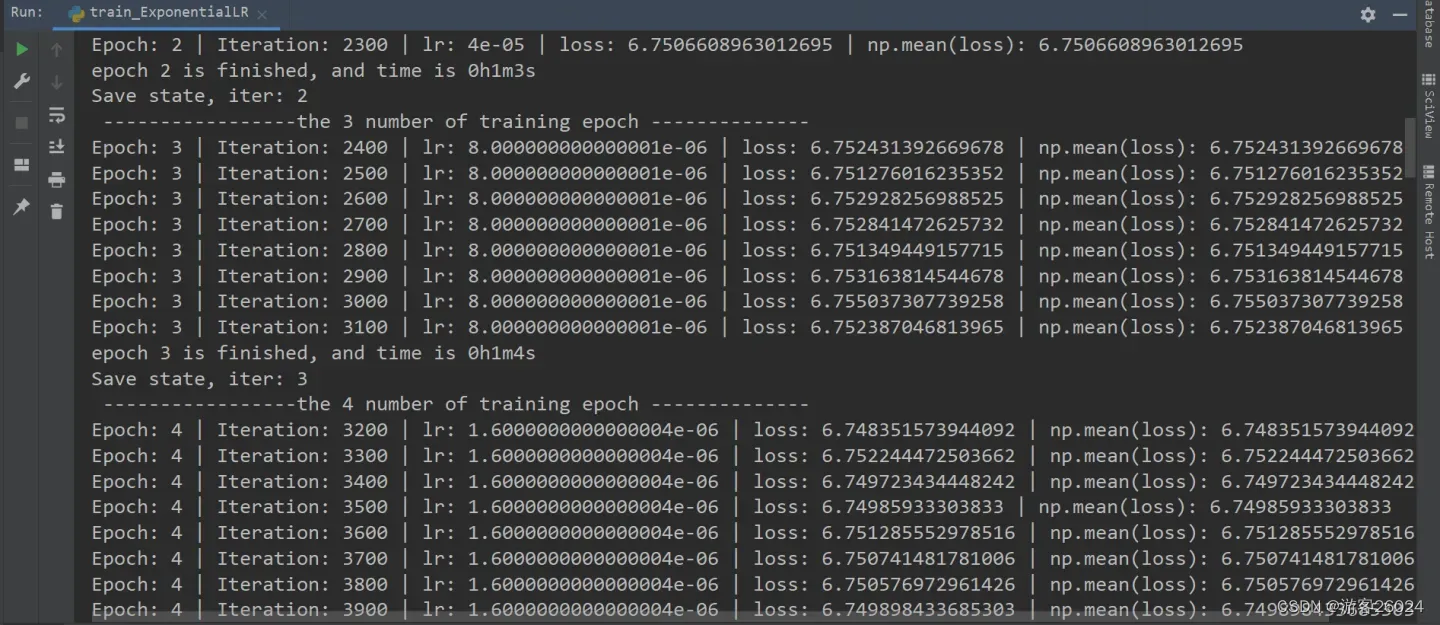
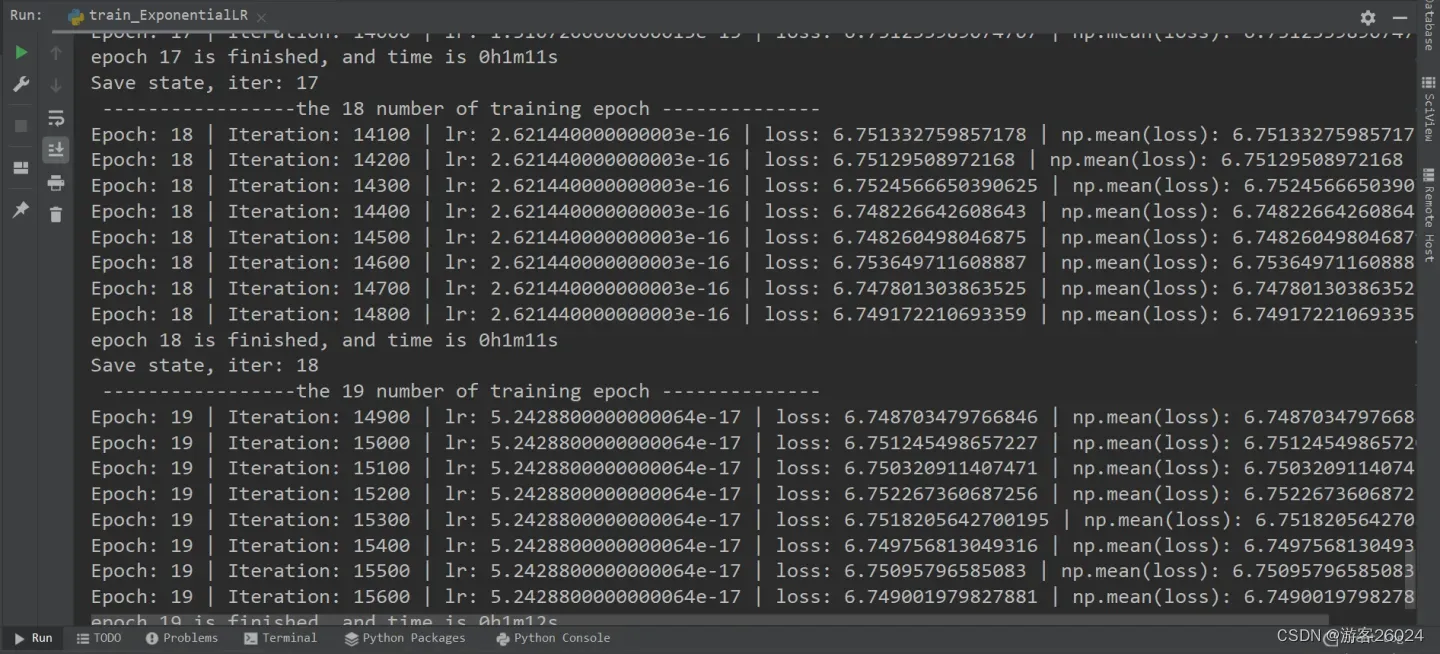
可视化lr与loss: lr(看橙色透明线条):
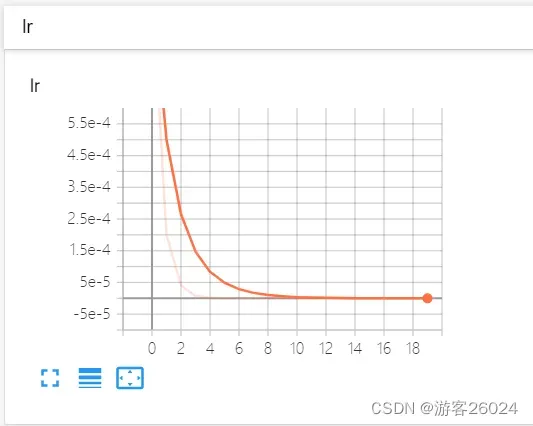
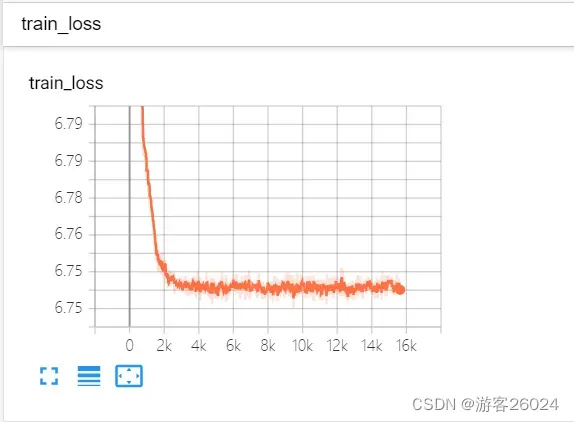
分析:
new_lr = lr * gamma^(epoch)
当epoch=0时,new_lr = 0.001 * 0.2^0 = 0.001
当epoch=1时,new_lr = 0.001 * 0.2^1 = 0.0002
当epoch=2时,new_lr = 0.001 * 0.2^2 = 4e-5
当epoch=3时,new_lr = 0.001 * 0.2^3 = 8e-6
当epoch=4时,new_lr = 0.001 * 0.2^4 = 1.6e-6
当epoch=5时,new_lr = 0.001 * 0.2^5 = 3.2e-7
当epoch=6时,new_lr = 0.001 * 0.2^6 = 6.4e-8
当epoch=7时,new_lr = 0.001 * 0.2^7 = 1.28e-8
当epoch=8时,new_lr = 0.001 * 0.2^8 = 2.56e-9
当epoch=9时,new_lr = 0.001 * 0.2^9 = 5.12e-10
当epoch=10时,new_lr = 0.001 * 0.2^10 = 1.024e-10
当epoch=11时,new_lr = 0.001 * 0.2^11 = 2.048e-11
当epoch=12时,new_lr = 0.001 * 0.2^12 = 4.096e-12
当epoch=13时,new_lr = 0.001 * 0.2^13 = 8.192e-13
当epoch=14时,new_lr = 0.001 * 0.2^14 = 1.6384e-13
当epoch=15时,new_lr = 0.001 * 0.2^15 = 3.2768e-14
当epoch=16时,new_lr = 0.001 * 0.2^16 = 6.5536e-15
当epoch=17时,new_lr = 0.001 * 0.2^17 = 1.31072e-15
当epoch=18时,new_lr = 0.001 * 0.2^18 = 2.62144e-16
当epoch=19时,new_lr = 0.001 * 0.2^19 = 5.24288e-177. 余弦退火调整学习率:CosineAnnealingLR()
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optim, T_max=5)其参数:
def __init__(self, optimizer, T_max, eta_min=0, last_epoch=-1, verbose=False):余弦退火学习率中LR的变化是周期性的
optimizer: 需优化的变量
T_max(int): 周期的1/2,一次学习率周期的迭代次数,即 T_max 个 epoch 之后重新设置学习率
eta_min(float): 最小学习率,即在一个周期中,学习率最小会下降到 eta_min,默认情况下为0
last_epoch=-1: 上一个epoch数,该变量表示学习率是否需要调整, 最好别修改
verbose=False: 是否打印
例如
CosineAnnealingLR(optim, T_max=5)
new_lr = eta_min + 0.5 * (initial_lr - eta_min) * (1 + cos(epoch / T_max * Π))
eta_min为最小学习率,T_max为cos周期的1/2代码:
from torch.utils.data import DataLoader
from torchvision.models import AlexNet
from torchvision import transforms
import torchvision
import torch
from torch import nn
from torch.utils.tensorboard import SummaryWriter
import time
import numpy as np
# 1.Create SummaryWriter
writer = SummaryWriter("../tensorboard")
# 2.Ready dataset
train_dataset = torchvision.datasets.CIFAR10(root="../data", train=True, transform=transforms.Compose(
[transforms.Resize(227), transforms.ToTensor()]), download=True)
print('CUDA available: {}'.format(torch.cuda.is_available()))
# 3.Length
train_dataset_size = len(train_dataset)
print("the train dataset size is {}".format(train_dataset_size))
# 4.DataLoader
train_dataloader = DataLoader(dataset=train_dataset, batch_size=64)
# 5.Create model
model = AlexNet()
if torch.cuda.is_available():
model = model.cuda()
model = torch.nn.DataParallel(model).cuda()
else:
model = torch.nn.DataParallel(model)
# 6.Create loss
cross_entropy_loss = nn.CrossEntropyLoss()
# 7.Optimizer
learning_rate = 1e-3
optim = torch.optim.SGD(model.parameters(), lr=learning_rate)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optim, T_max=5)
# 8. Set some parameters to control loop
# epoch
epoch = 20
iter = 0
t0 = time.time()
for i in range(epoch):
t1 = time.time()
print(" -----------------the {} number of training epoch --------------".format(i))
model.train()
for data in train_dataloader:
imgs, targets = data
if torch.cuda.is_available():
cross_entropy_loss = cross_entropy_loss.cuda()
imgs, targets = imgs.cuda(), targets.cuda()
outputs = model(imgs)
loss_train = cross_entropy_loss(outputs, targets)
writer.add_scalar("train_loss", loss_train.item(), iter)
optim.zero_grad()
loss_train.backward()
optim.step()
iter = iter + 1
if iter % 100 == 0:
print(
"Epoch: {} | Iteration: {} | lr: {} | loss: {} | np.mean(loss): {} "
.format(i, iter, optim.param_groups[0]['lr'], loss_train.item(),
np.mean(loss_train.item())))
writer.add_scalar("lr", optim.param_groups[0]['lr'], i)
scheduler.step()
t2 = time.time()
h = (t2 - t1) // 3600
m = ((t2 - t1) % 3600) // 60
s = ((t2 - t1) % 3600) % 60
print("epoch {} is finished, and time is {}h{}m{}s".format(i, int(h), int(m), int(s)))
if i % 1 == 0:
print("Save state, iter: {} ".format(i))
torch.save(model.state_dict(), "../checkpoint/AlexNet_{}.pth".format(i))
torch.save(model.state_dict(), "../checkpoint/AlexNet.pth")
t3 = time.time()
h_t = (t3 - t0) // 3600
m_t = ((t3 - t0) % 3600) // 60
s_t = ((t3 - t0) % 3600) // 60
print("The finished time is {}h{}m{}s".format(int(h_t), int(m_t), int(s_t)))
writer.close()运行结果:
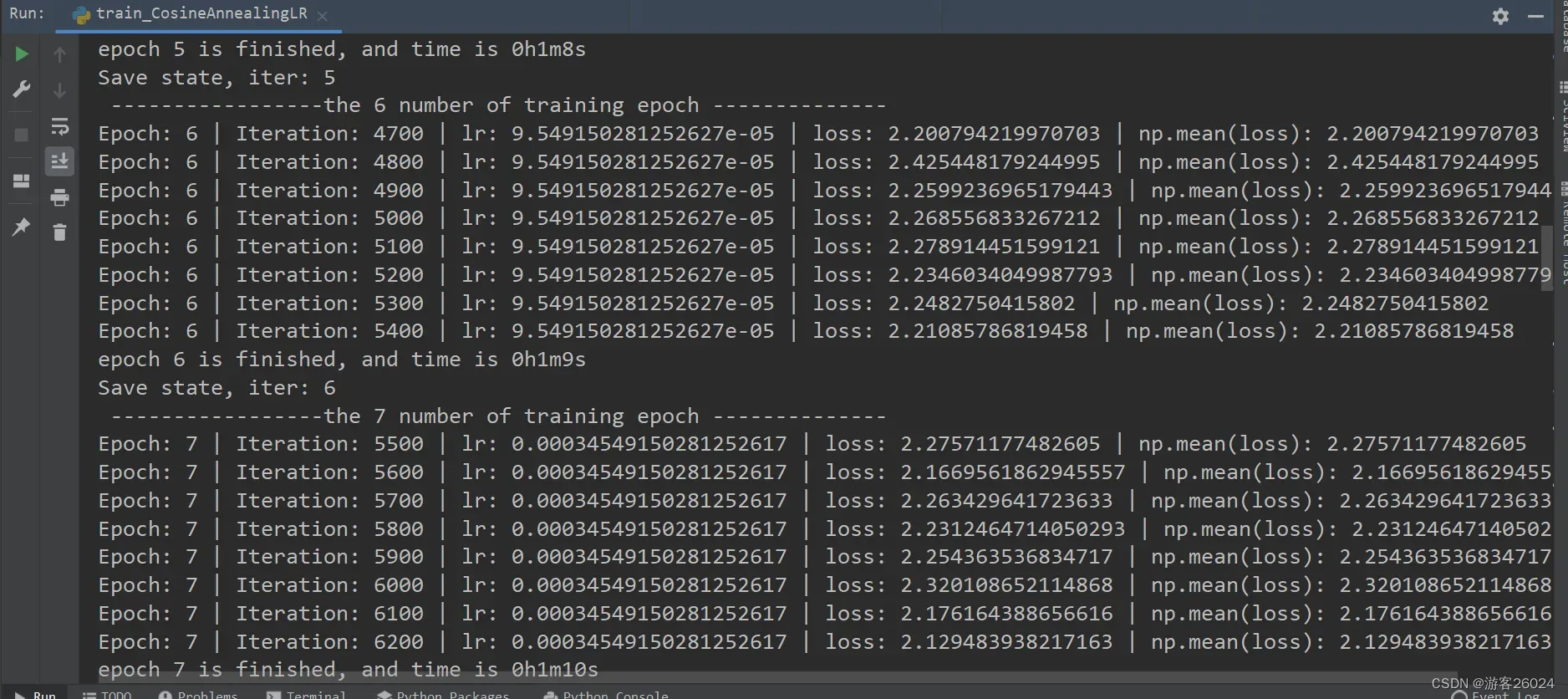
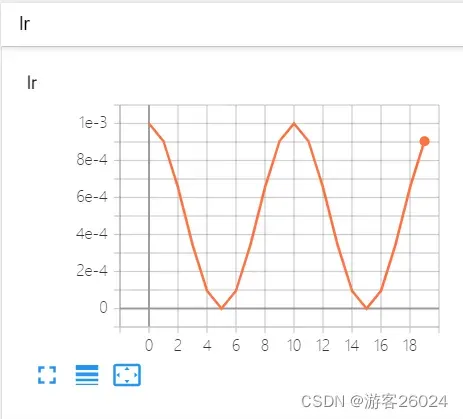
可视化lr与loss:

收工!
文章出处登录后可见!