本文继续刨刨代码背后的含义。
问题引入
我们在学习深度学习实战项目(比如Kaggle房价预测)时,会看到在定义完线性模型后,在定义训练方法时,看到这样的代码:
# net是一个331维输入,输出1维的单线性层模型,并已予参数初始化。
net = net.float()
这里net = net.float()是啥意思呢?
看字面意思是把net中的变量统一为float类型,于是我们查查pytorch的文档。
Module 的float()方法是对模型所有参数进行的float转换
net是一个Linear层对象,属于Module类型,我们查找torch.nn文档下Module类的说明,找到了下面的float方法:
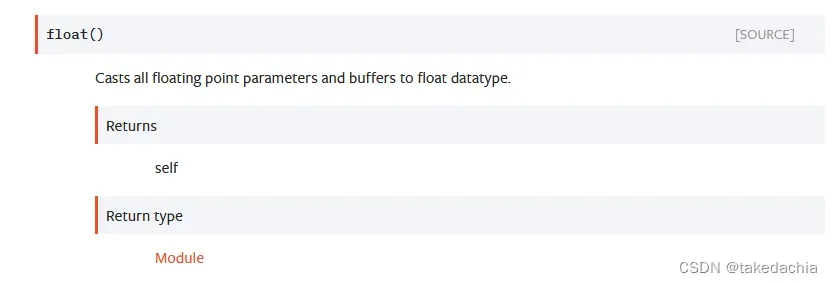
意思很简洁,就是把所有的 浮点型的参数和缓存(floating point parameters and buffers)转成 float类型的dtype。
看到这里已经可以大致解决代码的疑问了,就是一个方法,将Module中的parameters和buffers转成我们想要的float类型的dtype数据类型,即统一参数的数据类型。
但是我还有几个疑问:
- 什么是buffers?
- floating point parameters具体指代哪些数据类型?float dtype又是哪个float?
- 为什么这里要统一转成float型?
疑问解答
1 buffer是另一种模型参数
buffer也是一种参数,我参考的这篇文章。
简而言之,在Pytorch中,网络的参数会保存成OrderedDict(有序字典)的形式,这里的参数包括2种。
一种是模型中各种module含的参数,为nn.Parameter类;另外一种是buffer。前者每次optim.step会得到更新,但不会更新后者。
在后面的学习中还会碰到buffer和有序字典。
2 浮点型参数 指代 float64,float32,float16
问题2,我们点击右侧的SOURCE源码:
def float(self):
r"""Casts all floating point parameters and buffers to float datatype.
Returns:
Module: self
"""
return self._apply(lambda t: t.float() if t.is_floating_point() else t)
可以看到该方法对Module自身应用了一个_apply+lambda函数的方法,以达成对自身元素的更新。
这里可以查看Mudule中_apply和apply方法定义的源码,可以看到在私有方法_apply中传入的函数对parameters和buffers形成更新。
顺便,这个更新的方式本身是inplace形式的,所以net = net.float()也可以直接写成net.float()。
我们再看这个lambda函数lambda t: t.float() if t.is_floating_point() else t。
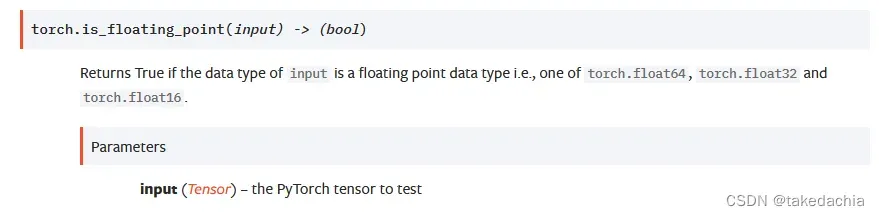
可以看到 is_floating_point() 方法定义了这个floating point,我们打开文档,可以看到is_floating_point可以判断一个tensor是否属于float64,float32,float16这三个类:
 t.float() 这里是对一个tensor使用了float()方法。目的是将float64,float32,float16转成float32(float)型的dtype。
t.float() 这里是对一个tensor使用了float()方法。目的是将float64,float32,float16转成float32(float)型的dtype。
小总结:Tensor的dtype类型转换
我们看看文档对tensor的float()的定义:
 tensor的float()方法意为将dtype类型转换为float32。float就指代float32。
tensor的float()方法意为将dtype类型转换为float32。float就指代float32。
同时,这里我们可以此总结出一个Tensor的dtype类型的转换方法:
- 对Tensor使用float()
- 直接使用等价的**to()**方法指定dtype类型进行转换
但是注意,这两种方法都不会替换原tensor,因此还需要赋值,即t = t.float()。这和Module.float()不同,注意避免踩坑。
同理,在Pytorch中,float指float32,half指float16,double指float64,int指int32等等。
因此我们同样可以对Tensor和Module使用类似的方法更改dtype类型,如 net0.double()、t0 = t0.half()等。
3 为什么要统一成float32
从上我们可以看到Pytorch将Tensor默认dtype设成了float32,即单精度浮点类型。
这个问题其实可以讲成为什么Pytorch偏向于float32的数据类型。
浮点计算能力是GPU的一个重要性能指标,同时数据的浮点精度面向不同的具体场景需求。
虽然无脑提高浮点精度对于高需求的业务场景来说肯定好处会多。
我参考了这篇文章。
对于常见的多媒体和图形处理计算、深度学习等领域,32位的单精度浮点计算足够了。对于要求精度更低的机器学习等一些应用来说,半精度16位浮点就已经够用了。对于需要处理的数字范围大且需要精确计算的领域比如计算化学,分子建模等,就要求采用64位双精度浮点数。
对于浮点计算,CPU可以同时支持不同精度的浮点运算,但在GPU里针对单精度和双精度需要各自独立的计算单元,一般在GPU里支持单精度运算的单精度ALU(算术逻辑单元)称之为FP32 core。多数GPU对于32fp有优化。
总结
- Module 的 float() 方法是对模型所有参数Tensor的dtype进行float32转换,包括parameters和buffers。
- 在Pytorch中,浮点型常见的有:float16(half)、float32(float)、float64(double)。可使用tensor的is_floating_point()方法判断是否是浮点型。
- 对Tensor 可以使用 float() 、to(torch.float) 等方法来转换dtype,转换后注意重新赋值。
同样 half、double、int、long 等都存在同名方法转换,对于Tensor和Module都适用。 - Pytorch默认统一使用float32和GPU浮点计算特性与优化有关。
文章出处登录后可见!