前言:
gpt也好,国内的一众语言模型也罢,它们目前似乎都只注重最表层交互层的使用体验,也就是和人进行对话是非常顺畅丝滑的。但如果把这些AI模型,应用到数据底层,用以解析原文,用以生成数据等底层生产力工具的时候,就会出现太多太多坑了。本文就详细记载这一年来使用gpt等AI模型做底层数据支持的时候遇到的问题和解决办法。若想具体看哪个解决办法和源码算法的,可以留言告诉我哦~
正文:
一:gpt的回答总是废话很多
如标题所言,gpt等AI的回答的内容太长,真正有用的答案不到全部回答的一小半,人阅读起来会感觉不错,但让你的算法阅读起来就要麻烦了,各种无用的文案非常难以剔除。导致其这样的原因无外乎两个:
1. 更多的回答可以浪费更多的tokens,也就是需要你花费更多$。
2. AI学习的那些资料本就是这样的语境或者书面语,所以学成归来的AI也不会说话很简洁干脆。
举例:你问gpt 1+1等于几?
gpt回答:

解决方案:给问题的结尾加上 简洁精炼的强制要求,在你的底层代码中对每个问题都自动加上最后这句即可。
效果如下:

二:gpt的回答总是会擅自添加很多联想和无关信息。
如标题所言,举个例子:
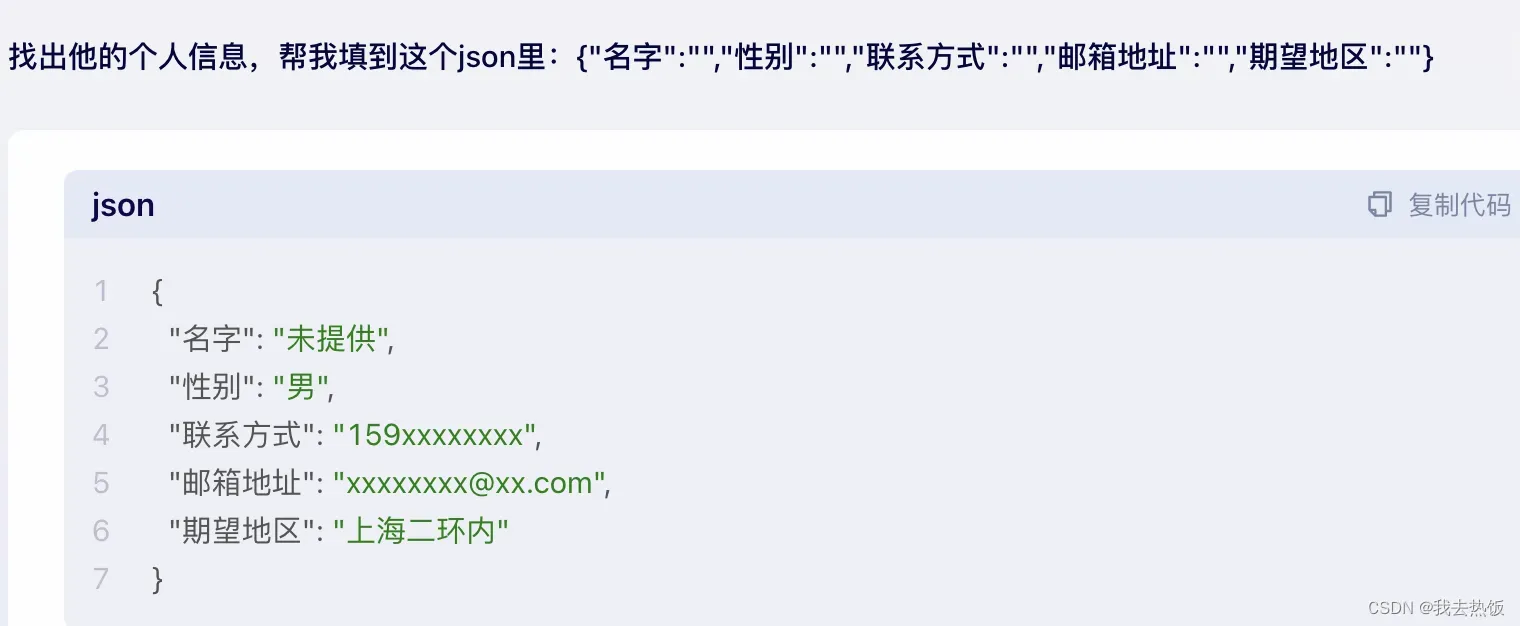
现在有一份简历提交给gpt,让其帮忙找出简历中应聘者的姓名,联系方式,地址三项。
但是结果往往是,gpt帮你找出了很多其他的你压根没要的信息,比如邮箱。因为在gpt的学习认知里,别人要解析简历信息的都是一次就要全了 姓名、联系方式、地址、邮箱。这还不算完,gpt甚至会给你展现出简历中不存在的信息,也就是虚假信息,这些信息是gpt自行推断猜测出来的。这样的随意结果,如果当成重要的底层数据,那将是一场灾难。
当然,一些好的模型是很少出现这个问题的,但为了保险起见,我觉得这种大文本的解析中,应该要至少对预期结果 和 实际结果 做一个比对验证层,在比对通过了之后,才能进行下一步。而这个比对包括以下几点:
1. 找出 实际结果中 缺少的 要求字段。
2. 删掉 实际结果中 额外的 非要求字段。
3. 验证 实际结果的每个字段是否真实(通过字符串词组在原文中的相似度得分来判断)。
4. 检查 实际结果中 缺少的字段 重新提问获取。
在这个对比层结束之后。如果答案质量不高,没有通过比对验证层,那我们就可以再次发问,这次在最后要加上:
“刚刚的答案要更加严格规范一点,不要加任何联想和推测,要依据客观事实”
然后gpt就会先给你个道歉,然后重新给你生成一次不错的回答了。
三:gpt的回答过于自然语言化,很难作为格式化数据解析提取并使用。
gpt出圈的原因,就在于其模仿人类一样的自然语言,流畅而合乎语境。但在我们提取的时候则遇到了麻烦,你的算法也好,正则也罢,都不可能百分百的解析一段纯自然话术。
比如这个例子:

哪怕是同一个问题,再次的回答也会有格式上的差异:注意看,前面的点·没了。 你再问还会有其他各种类型的答案。

面对这样不可控的回答,你怎么提取出来有效信息呢?或者说,本来原文就是一段自然语言,经过gpt的解析后结果仍然是一段自然语言,意义何在?
所以,解决方案就是,用json进行强制要求!
而我们解析json那是真的简单快速了就,起码代码不会频繁报错,也不用写复杂的解析算法正则等等了。

如果你不满意或者无法预料json答案的字段名,导致提取失败。那你可以强制要求字段的名称key,一开始就写好这个空的json,让gpt帮你添上。这样,数据的字段就是固定的,后面提取更精确了。
四:gpt的回答又贵又慢,导致开发调试过程成本太高。
其实一直以来,对这种第三方接口的返回值很慢很贵的情况,我们开发时候都会做一个Mock层:就是把某次的回答写死,来让接口不真的去请求第三方服务器,直接返回写死的返回值。
但是,gpt的接口回答,却不能这么简单。因为它每次回答的结果都很难保持一致。如果你用了其中某次的结果作为mock值,那么根据此你写的算法和代码,都没啥用了。因为下了mock后,你随便测试一下,就会发现报错,然后查询发现,gpt的回答和你mock的完全不一致,格式也好,正错也好,数量都出现了偏差,甚至很大很大。
小的偏差还好,但是大的偏差就很糟糕了。比如下面这个例子,同一个问题,问了两次,结果如下:

不但格式不同,就算是结果都不相同了,第一次失败,第二次成功。
这个原因在于AI模型的路线随机性所致,大家都知道,AI模型的基础结构一般分为三部分:
输入层 – 中间层 – 输出层。
输入层和输出层都是固定的,唯一变数就是中间层。
中间层会包含很多层,每个层会有很多个节点,每个节点代表某个因素。而这也就是随机的本质。
如果中间层只有2层,每层2个节点,那么理论上来讲,结果只会有2*2 = 4种,而且相邻如此近,这4种答案都几乎差不多,这种时候,我们随机用其中1种答案作为mock来开发调试没啥问题。
但实际上的gpt解析中,中间层可能有几百上千层,每层有成百上千个节点,这取决与你要问的问题是什么,要解析的原文有多长,有多少个tokens。
古人云:失之毫厘谬以千里 。 如果这条路线在最开始就走偏了,那么最终的结果可能和你预期的就相去甚远了。虽然有几乎百万种生成结果,但是大体分类上,可能只有十几种类别(相邻差不多的结果偶尔个别字不同无关大雅),而这种类别之间的区别就非常大了。就像上面的问题一样,甚至说一个成功,一个失败。
那针对这种情况,我们期望的结果,其实就是其中那1-2种结果罢了,当然,根据GPT用户不断的人为校对反馈,最终生成这预期1-2种结果的概率很大,甚至接近于90%。但总有那一丁点小概率,走了其他结果很糟糕的类别。这时候,你怎么办?你的代码只能是报错或者给了用户错误的结果产生误导,造成巨大损失。
那这样看来,我的解决办法就是做一个结果类别甄选层:通过一个大数字循环,收集所有可能的结果,每发现一个新的结果就将其存放到一个列表数组中,当连续上百次都无法发现新的结果的时候,就可以宣告99.99%的概率是列表中的几大结果类别了。然后如果要mock的话,则每次顺序或随机循环的取出这个列表数组的元素,作为mock值,方便我们后续代码可以每次调试都对所有可能情况进行验证,这其中,你还可以做一个过滤,把不符合要求的大多数类别直接pass掉。只保留那1-2种可接受的结果作为mock值。在之后代码正式运行时也是如此,一旦检测到结果不属于可接受结果,则直接pass掉,然后重新问,再问的时候,就要加上要求了以便gpt来矫正答案。
五:gpt写作的话术总是很正式,很官方的,让人没兴趣看下去。
在你用gpt生成一些故事或者概括,简介的时候。gpt生成的结果乍一看没毛病,但是等你真上线了并且观察埋点数据就会发现,用户基本不看。原因之一,就是gpt生成的文案看着没劲。
比如这个:

虽然说的全对,精准无比,总结到位。但就总少了那么一点耐人寻味,引人入胜,精神调味。
解决方案也很简单,对其进行要求即可。
 当然,这个具体要求就看你的尝试了,我目前用gpt做的工具里基本就是这样进行简介,效果是有提升的,后需还要继续探索出更好的问题技巧。
当然,这个具体要求就看你的尝试了,我目前用gpt做的工具里基本就是这样进行简介,效果是有提升的,后需还要继续探索出更好的问题技巧。
六:gpt应采用渐进式引入,前期轻度,中期养膘,后期重用。
我用gpt做底层的一些小工具中总结了这个方法论:
【前期轻度】:因为gpt作为公共语言模型的不稳定性,本地化专业化也不够,导致简历优化的最终结果非常差,可以说和预期相差太大。所以前期的时候,不要重用gpt,只需要轻轻引入即可,让其做一些简单的打下手的任务,重要的功能还是要我们自己写的算法来做。算法做出的预期结果更符合我们需求。然后最多让gpt优化一下成为自然语言即可。这样是最安全的。
【中期养膘】:gpt刚引入的时候就像一个蹒跚学步的孩童,我们虽不能委之大用,但也不能不指着gpt,在每次我们的算法+人工的运行下,结果都要喂给gpt,让其慢慢的学,慢慢的矫正,帮我们训练出一个针对公共模型的矫正层。随着时间推移,矫正层的数据慢慢变大,而公共大模型gpt进入矫正层后,出来的答案就会越来越符合我们的具体需求。可以帮我们的任务比例就会慢慢变大,总体程序也会越来越轻便快速和丝滑。
【后期重用】:在我们经过一段时间的抚养后,gpt慢慢的就长成了我们要求的样子,此时便可以停止喂养(毕竟喂养训练是有巨大成本的),停止我们人工维护,停止我们一开始的各种算法,来让gpt尝试独立去解决业务问题。当一段时间测试通过后,这个工具就算成了。此时,也算是形成了技术壁垒,别人想山寨你一时半会都山寨不出来了。
七:gpt要解析的原文越长,解析的效果越差。
这是我尝试使用gpt解析简历的时候发现的现象,当解析的简历只有1-2页的时候,一点问题没有。但是简历内容增加后,解析的效果直线下降。甚至本来能解析的内容也会解析错误,猜测是后续太多原文内容进行干扰导致。比如你就想查候选人的邮箱地址,一开始内容少,查的非常精准。但是随着内容增加,比如简历中候选人的某个项目经验,其中恰好就是负责一些邮箱的开发测试工作,那就很容易跟简历的个人基础信息中的邮箱地址产生干扰,让gpt出错。但就算没有干扰,gpt的结果也不行,猜测原因是因为原文过长导致中间节点过多,链路过长,让结果的可能性成倍增长,命中预期正确解析结果的概率就会大大降低。
【解决办法】是:设计一个分解层,对原文简历进行大块拆解,拆分成个人信息,教育信息,职业技能,工作经历,项目经验等几大块,然后对每一块再单独套用解析流程,可以极大的提升解析准确度!但这里有个问题,就是如何拆解成功,这里建议通过基础算法拆解,比如一些关键字如(项目经验,工作经历)来进行分割。或者干脆让gpt进行分割。无论怎么做,都可以成功把原文分成几大块,单独的进行解析效果是非常不错的!有什么不懂的评论区告诉我!
八:gpt的单对话次数限制问题。
目前,我用的这些gpt模型中,单次对话的次数总是有限制,多的十几次,少的几次。什么意思呢?就是gpt不会和你一直聊天聊下去,它只会记得你前面说的大概十个问题左右。你俩对话了十一句了,那么gpt就会忘掉你的第一句。这个对于长链的数据多次迭代很不友好。
就比如我一开始抛出一个简历,让gpt按照我的要求解析并优化,在对话了十几次之后,gpt突然反问了我一个问题,它问我:好的,我已经明白了你的要求,现在您的简历呢?
这个问题给我整一楞,然后查询原因发现,第一句我给它简历的那一句已经没了,被它彻底遗忘了。我觉得这个问题服务商是有办法控制的,可以加钱解决,突破次数限制。
但我仍然是用自己办法解决。
解决办法:我把前面要被遗忘的问题进行整合,始终让次数保持在允许范围内,哪怕单个问题内容越来越大,也没有再出现遗忘的情况。
九:gpt的接口调用,必须你一句,它一句,很容易受限。
目前,绝大部分接口的调用逻辑都强制规定为【一人一句】。如果你连续说俩句,或想让gpt连续回答两次,那都是会报错禁止。
解决办法:写一个算法,进行问题融合,如果检测到最后一句是和提问都是你个人身份,那么就进行合并。如果检测到最后一句和提问都是gpt,那就在最后一句后面自动加一句以你个人身份的问话,可以是很简单的语气词或者让gpt更完善简介的回答这种不影响大局的问题。
最后,给大家展示下我目前做的测试用例自动生成平台的第一版层级设计:

感兴趣的小伙伴请留言哦~
版权声明:本文为博主作者:我去热饭原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_22795513/article/details/135489860